一种纯电动汽车行驶工况构建方法
文献发布时间:2023-06-19 12:19:35
技术领域
本发明属于交通技术领域,具体属于一种纯电动汽车行驶工况构建方法。
背景技术
车辆的行驶工况是代表特定交通环境、特定车辆行驶特征的速度-时间曲线。行驶工况是汽车工业一项共性的核心技术,可用于汽车的设计研发和评估测试等。
我国的各种车辆测试工况中普遍采用的是国际标准工况,目前中国工况作为参考标准正同步推进但尚未普及。由于电动汽车与传统燃油汽车行驶特征存在较大差异性,而中国轻型汽车试验工况(CLTC-P)代表的是轻型汽车的平均特性,因此有必要纯电动汽车构建针对性的测试工况以更准确地评估纯电动汽车能耗和续航里程、生命周期等方面性能。
目前的工况构建方法主要涉及短行程法和马尔科夫方法。由于马尔科夫方法具有高复杂性和不可重复性,而短行程法结构简单,计算速度快,使用更为广泛,但其构建精度很大程度依赖于聚类分析的精度以及用于工况合成的短行程片段是否具有代表性。并且现有的短行程构建工况方法中关于短行程片段划分原则不合理导致获得的工况不能更真实全面地反映电动汽车的实际行驶特征。传统短行程方法中对于工况构建的评价标准单一,通过主成分分析和聚类分析只能合成一条工况曲线,不能完全保证最终构建的工况曲线具有代表性。
发明内容
为了解决现有技术中存在的问题,本发明提供一种纯电动汽车行驶工况构建方法。
为实现上述目的,本发明提供如下技术方案:
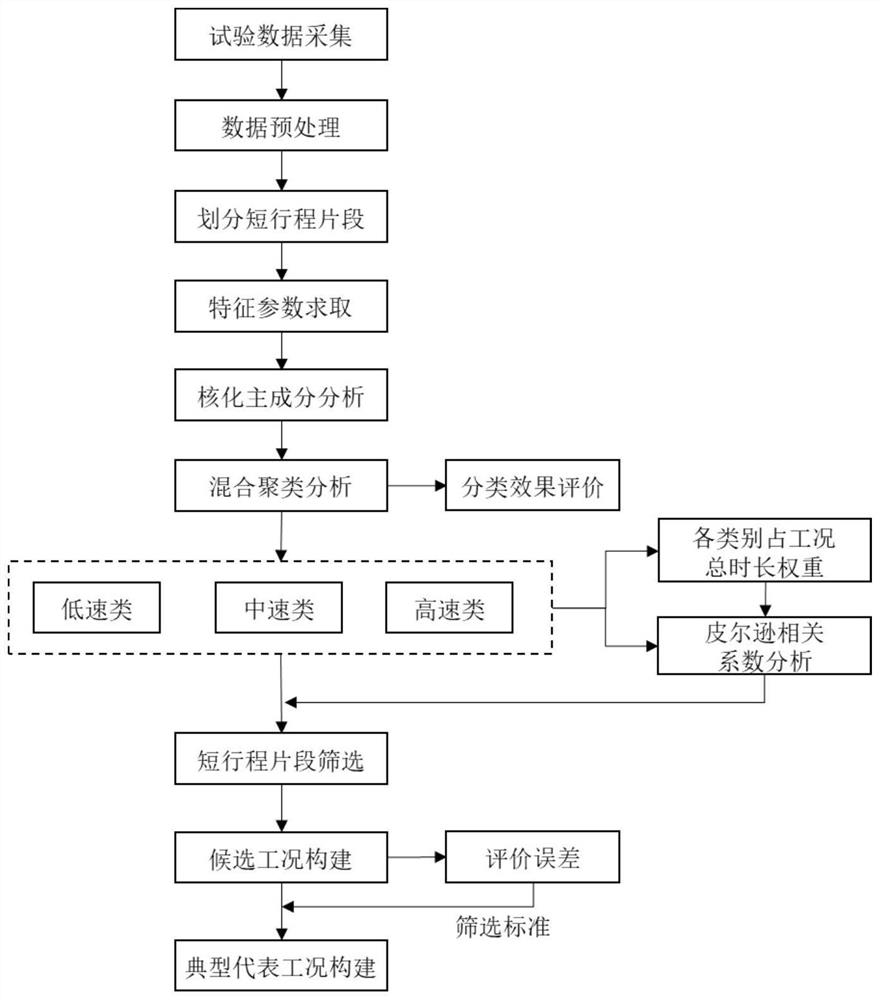
一种纯电动汽车行驶工况构建方法,包括以下过程,对纯电动汽车行驶工况进行数据采集,将试验路线划分为若干个短行程片段,从若干个短行程片段中获取纯电动汽车行驶工况的特征参数;
对纯电动汽车行驶工况的特征参数通过核化主成分分析进行非线性降维,通过混合聚类方法对非线性降维后的特征参数进行分类,依据分类结果结合各类别占工况时长权重和皮尔逊相关系数对若干个短行程片段进行筛选,构建多个纯电动汽车候选工况;
计算并比较多个纯电动汽车候选工况中的特征参数的相对误差值和SAPD频率值,构建纯电动汽车行驶工况。
优选的,具体包括以下步骤,
步骤1,确定试验路线总长,采用层次分析法确定试验路线中不同道路的长度和比例,依据试验路线总长和试验路线中不同道路的长度和比例进行试验路线的规划,在规划后的试验路线上采集纯电动汽车行驶工况的数据,获得纯电动汽车行驶状况的车速和时间数据;
步骤2,对步骤1中采集到的纯电动汽车行驶状况的车速和时间数据进行数据预处理;
步骤3,将纯电动汽车行驶状况的车速和时间数据依据行驶速度划分为若干个短行程片段,获取每个短行程片段的特征参数;
步骤4,通过核化主成分分析方法对步骤3中获得的特征参数进行非线性降维,并通过K-Means聚类方法对非线性降维后的短行程片段特征参数进行预分类处理,并结合随机森林方法进行混合聚类分析,依据分类结果结合各类别占工况时长权重和皮尔逊相关系数对若干个短行程片段进行筛选,构建多个纯电动汽车候选工况;
步骤5,确定用于工况评价的多个特征参数,计算多个纯电动汽车候选工况中的多个特征参数与步骤2中的纯电动汽车行驶工况数据之间的相对误差值,结合速度-加速度概率分布确定典型代表工况,构建纯电动汽车行驶工况。
进一步的,步骤1中通过车辆追踪法和车载测量结合的方法,采集纯电动汽车行驶数据。
进一步的,步骤2中,对采集的汽车行驶数据中缺失、异常的数据利用插值法和小波分解和重构方法进行筛选、降噪处理。
优选的,步骤3中,所述行驶工况的特征参数包括时间特征参数、速度特征参数和加速度特征参数;
所述时间特征参数包括行驶时间、加速时间、减速时间、巡航时间和停车时间;
所述速度特征参数包括最大速度、平均速度和速度标准差;
所述加速度特征参数包括最大加速度、平均加速度、最小加速度、平均减速度和加、减速度标准差。
优选的,步骤4中,所述分类类别为低速类、中速类和高速类。
优选的,所述皮尔逊相关系数的公式如下,
式中,X和Y分别代表短行程片段数据和总体试验数据,r(X,Y)为短行程片段与总体试验数据的相关系数,
优选的,所述各类片段所占的时间比例计算公式如下:
式中:t
t
t
t
n
优选的,步骤5中,所述用于工况评价的特征参数包括平均速度、平均加减速度、各运行状态时间比例、电动汽车的功率需求参数KPE和动能需求参数RPA。
优选的,步骤5中,先计算多个纯电动汽车候选工况中的多个特征参数与步骤2中的纯电动汽车行驶工况数据之间的最小相对误差值MARE,并计算不同候选工况中SAPD频率值与步骤2的纯电动汽车行驶工况数据中SAPD频率值之间的百分比值SAPD
与现有技术相比,本发明具有以下有益的技术效果:
本发明提供了一种构建电动汽车行驶工况的方法,根据所采集的符合某一特殊地域和地区的电动汽车行驶数据利用核化主成分分析(K-PCA)方法实现短行程片段特征参数的非线性降维,并提出一种改进的KR混合聚类方法构建候选循环工况,将传统K-Means聚类算法结合随机森林算法对短行程片段进行聚类分析。再通过考虑针对电动汽车的特定特征参数和速度-加速度分布概率来确定评估标准,从候选工况中选择代表性循环工况。从而实现了工况构建精度更高,更能反映电动汽车的实际行驶特征,获得的工况曲线与实际工况的一致性更强。
本发明所提出的电动汽车行驶工况构建方法能更准确地反映电动汽车的实际行驶特征。在短行程片段划分时考虑到电动汽车在实际行驶过程中无怠速情况,与传统燃油汽车以加速、减速、匀速和怠速片段作为划分依据的不同,建立针对电动汽车新的短行程片段划分标准。
本发明提出的工况构建方法在保留了短行程中主成分分析结合K-Means聚类方法优点的基础上,考虑到行驶数据的非线性特征采用核化主成分分析对特征参数进行非线性降维,并提出一种更优化的混合聚类方法。其中采用机器学习中的具有良好的分类能力和泛化能力随机森林算法对K-Means聚类结果进行进一步分类预测,优化聚类结果,提高了分类的准确度,进而提高了工况构建的精度。且随机森林算法与其他分类算法相比,可以有效处理大数据集以及高特征维数的数据。
本发明建立了针对电动汽车行驶特征和性能特征的工况有效性评价方法,主要包括:采用聚类有效性综合评价指标评价聚类效果,保证聚类有效性;提出用于工况合成的短行程代表性片段筛选方法,构建出10条候选工况;提出候选工况筛选和评价方法,保证最终能构建出一条符合电动汽车行驶特征的典型代表性行驶工况曲线。
附图说明
图1为本发明一种纯电动汽车行驶工况构建方法的流程图;
图2为本发明实施例中实际试验道路示意图;
图3为本发明实施例中数据预处理前后车速曲线对比图;
图4为本发明实施例中混合聚类算法的流程图;
图5为本发明实施例中采用混合聚类算法的结果图;
图6为本发明实施例中所构建的纯电动汽车典型代表性工况曲线图。
具体实施方式
下面结合具体的实施例对本发明做进一步的详细说明,所述是对本发明的解释而不是限定。
本发明所提出的一种电动汽车行驶工况构建方法,具体实施方式主要包括以下步骤:
步骤1、纯电动汽车行驶数据采集。采用层次分析法完成试验规划,包括数据采集方法、试验路线和不同道路长度和比例分配的确定等,采用车辆追踪法和车载测量结合的方法,采集纯电动汽车行驶数据,主要为车速、时间数据;其中数据采集的试验规划的主要步骤如下:步骤1.1,试验路线总长确定:根据试验基本原则,需要从目标道路路网中选取一部分样本组成试验路线,完成数据采集,通过试验样本特征反映总体特点。设路网总长度L服从均值为μ,方差为σ
步骤1.2,采用层次分析法完成试验路线中不同道路长度和比例确定:基于层次分析法完成这一多目标决策问题,建立驾驶员的最佳出行方式模型。包括三个层级:(1)目标层:最佳出行方式;(2)准则层:快速出行和便捷出行作为备选准则;(3)方案层:将不同道路类型作为待选方案,包括快速路、主干道、次干道和支路等。
层次分析法的分析步骤主要分为3步:①对系统中各要素进行分析,并对重要性进行评价;②判断所选要素与某一准则的相对权重;③按照总权重大小对各个层级进行排序。最终通过分析计算求得试验路线中不同等级道路长度和比例。
步骤1.3,基于步骤1.1确定的试验道路总长和步骤1.2确定的验路线中不同道路长度和比例,完成试验路线的规划。基于规划的路线进行实车试验,采用车辆追踪法和车载测量结合的方法,采集纯电动汽车行驶数据,获得一系列代表电动汽车行驶状况的车速和时间数据。
步骤2、对步骤1中采集的纯电动汽车行驶车速与时间数据进行预处理。
由于在实车试验采集车速和时间数据过程中,不可避免地存在采集设备GPS信号丢失、设备采集信号异常(如信号异常尖峰值)的情况,为避免异常数据对工况构建精度产生影响,对步骤1采集到的纯电动汽车行驶数据中缺失、异常的数据利用插值法和小波分解和重构方法进行筛选、降噪处理,获得预处理后的汽车行驶车速与时间数据。即下文中的原始数据。
步骤3、划分短行程片段。将步骤1中的获得的一系列随机连续的车速与时间试验数据划分为若干个短行程片段,每个短行程片段依据速度进行划分,即将短行程片段定义为两个连续的停车片段之间的片段,每一个短行程片段包含若干随机的加速、减速、巡航和停车的车速数据,并获取每个短行程片段的时间相关特征参数、速度相关特征参数和加速度相关特征参数。具体步骤如下:
步骤3.1,基于短行程方法,考虑到纯电动汽车无怠速状态,提出如下的车速状态划分原则,并基于该原则将短行程片段定义为两个连续的停车片段之间的片段,每一个短行程片段由若干随机的加速、减速、巡航和停车的车速数据组成,最终将原始数据中一系列完整连续的车速数据划分为多个短行程片段。
其中v(km/h)和a(m/s
步骤3.2,依据步骤3.1中划分得到的一系列短行程片段,结合纯电动汽车行驶特征和性能特点在每个短行程片段中提取14个表征汽车行驶工况的特征参数如表1所示,作为后续对短行程片段进行分类的特征依据;
表1描述短行程片段的特征参数
步骤4、纯电动汽车候选工况构建;
步骤4.1,通过核化主成分分析(K-PCA)方法对步骤3获得的短行程片段特征参数进行非线性降维。
步骤4.2,对非线性降维后的短行程片段特征参数通过混合聚类方法构建候选循环工况。
具体的,采用K-Means聚类对非线性降维后的短行程片段特征参数进行预分类处理,再结合随机森林方法从K-Means各类聚类结果中选择训练集,对各类别剩余的行驶数据作分类预测。选择紧凑度(CP)、分离度(SP)、Davies-Bouldin指数(DB)和Dunn Validity指数(DVI)作为聚类有效性评价指标,即评估各类短行程片段数据是否能准确地分类到特定的类别中,以保证聚类的有效性,保证类间数据的特征差异大而各类内的数据特征差异较小,以定量评估聚类效果。
步骤4.3,聚类分析后,将短行程片段库按不同类的车速特征分为若干个特定类别,基于皮尔逊相关系数和各类短行程片段所占时长比例进行短行程片段的拼接组合,最终构建出10条候选工况。
短行程片段与总体试验数据的相关系数越大,短行程片段越能代表所属类别的整体特征。皮尔逊相关系数的公式如下:基于该公式,从聚类后获得的各类短行程片段库中,分别筛选出与总体试验数据的相关系数最大的10个片段,作为各类具有代表性的短行程片段,用于后续短行程片段的重新组合生成代表性工况曲线。
式中,X和Y分别代表短行程片段数据和总体试验数据,r(X,Y)为短行程片段与总体试验数据的相关系数,
设置一个工况总时长,按各类短行程片段所占时长比例进行短行程片段的拼接组合,各类片段所占的时间比例计算如下:
式中:t
t
t
t
n
步骤5、纯电动汽车代表性行驶工况构建;
步骤5.1,通过统计分析选取用于工况评价的10个特征参数,包括平均速度、平均加减速度、各运行状态时间比例、电动汽车的功率需求参数KPE和动能需求参数RPA。
步骤5.2,计算10个候选工况数据与步骤2中预处理后的车速数据之间10个特征参数的相对误差值(ARE),取各特征参数值的相对误差值小于10%的候选工况,计算最小相对误差值(MARE)。结合速度-加速度概率分布(SAPD),计算不同候选工况中SAPD频率值与原始数据中SAPD频率值之间的百分比值SAPD
步骤5.3,计算MARE和SAPD
实施例
详细地,下面结合附图以及具体实施例对本发明作进一步的说明。实施例:以国内某大型一线城市为例,构建纯电动汽车行驶工况。
步骤1:行驶工况数据采集。
结合该地区各等级道路占比、各等级道路交通流量、汽车保有量及市民出行道路选择意愿等因素,采用层次分析法完成试验规划,设计了试验路线如附图2所示。设计试验道路长度为38.46km,试验路线中快速路、主干道、次干道、支路比例分别为29.96%、24.80%、26.85%和18.39%。采用车辆追踪法和车载测量结合的方法,选择城市内保有量较大的一款纯电动汽车作为试验车辆;选择28位有经验的驾驶员在某城市的早高峰期7:00-9:00、午平峰期12:30-14:30、晚低峰期19:00-21:00在试验路线上循环驾驶采集数据;试验主要设备包括GPS、OBD和VBOX,主要采集汽车行驶的一系列随机连续的车速、时间数据。
步骤2:数据预处理,对原始数据进行筛选、降噪、平滑处理。
利用下式函数进行数据插值,去除数据中的奇点。式中v
为了使短行程片段划分的片段不过于杂乱,片段长度不过小,利用小波分解和重构方法进行降噪平滑处理。附图3显示了预处理前后部分速度曲线的比较。
步骤3:短行程片段划分。
将步骤2获得的一系列完整连续的车速数据分割为若干短行程片段。与传统燃油车不同,传统燃油车通常以怠速状态作为两个短行程片段间的分割点,而考虑到纯电动汽车无怠速状态,采用本发明提出的方法,将一个短行程定义为两个连续的停车片段之间的片段,即以相邻两个车速为0的点作为分割车速片段的依据,两个连续的停车片段之间包含若干随机的停车、加速、减速和巡航过程,同时排除运行时间小于10秒的短行程片段,获得了1414个有效的短行程片段。
其中v(km/h)和a(m/s
根据划分得到的1414个短行程片段,计算短行程片段特征参数值,得到短行程片段数据特征矩阵1414×14,结果如表2所示。
表2短行程片段特征参数值
步骤4:构建纯电动汽车候选工况曲线;
详细地,构建纯电动汽车候选工况步骤如下:
步骤4.1,核化主成分分析(K-PCA):提取特征参数,对数据进行非线性降维降低特征冗余,表2计算法的短行程片段的特征参数值。而传统方法中采用的主成分分析通常只能提取数据的线性特征,广泛存在非线性问题不能充分解决。因此本发明提出采用核化主成分分析法。
本发明给出了利用KPCA降低短行程特征参数维数的具体步骤:(1)为消除数量级对结果的影响,对表21414×14的特征参数矩阵进行标准化;(2)计算核矩阵:采用高斯径向基核函数:
其中σ代表高斯函数宽度,通过参数优化得到相对合适的参数σ=38.73;k=1,2…M,K是一个M×M的核矩阵,M=1414;
(3)采用奇异值分解(SVD)算法求K的特征值和特征向量;
(4)对特征值以降序排列(λ
即在特征空间F中须使λ
(5)计算一个测试样本x在特征向量上的投影值(主成分)并作为新特征:
对于一个新样本x,提取它的主成分只需将其F空间中相应的映射样本Φ(x)向V
(6)根据如上步骤计算得到各主成分及其累积贡献率,取累计贡献率85%的前几个主成分作为后续聚类分析的依据,最后计算主成分得分矩阵作为输出空间的变量。
表3主成分及累计贡献率
主成分分析结果表3所示,经K-PCA分析后,得到4个主成分,累积方差贡献率为91.96%。作为比较,采用PCA主成分分析得到3个主成分,累计方差贡献率为85.49%。从而得出结论,本发明采用的K-PCA对短行程片段数据进行非线性降维,获得的低维数据包含更多有效的原始数据信息。
步骤4.2,进行聚类分析。
本发明提出的K-Means结合随机森林的KR混合聚类算法实现流程图如附图4所示,具体步骤如下:
(1)将核化主成分得分矩阵替代原始数据,通过K-Means聚类分为低速、中速和高速三个类别。
(2)将K-Means三类结果中最接近聚类中心的30个短行程片段作为随机森林训练样本,并完成对剩余短行程片段的分类预测。
表4分类特征结果
K-Means聚类结合随机森林(K-Means+随机森林)和K-Means聚类的分类结果如附图5和表4所示。部分K-Means聚类后属于中速类的短行程片段经过随机森林分类后被分到第一类,从而优化了聚类结果,提高聚类的精确性。
(3)表5是K-means和混合聚类(K-Means+随机森林)方法的分类有效性评价指标。与K-Means聚类相比,混合聚类的CP和DB较小,表明类内距离越近;而SP和DVI值较大,表明类间距离越远。结果表明,本发明所提出的混合聚类算法能够有效提高同一个聚类内的相似度,降低不同聚类间的相似度。
表5分类有效性评价结果
步骤4.3,候选工况构建。
如图6所示,将一个代表循环工况时长设置为1200s,分别由三个类别的短行程片段按时间比例组合而成,经计算得到其中低速类为160s,中速类为603s,高速类为437s。根据短行程片段与总体试验数据的皮尔逊相关系数选择代表的短行程片段进行拼接组合最终构建出10条候选工况。
步骤5:构建纯电动汽车典型代表性工况曲线。
步骤5.1,10个特征参数来表征循环工况数据特征如表6所示。
步骤5.2,根据本发明提出的候选工况筛选指标PV值计算方法,以PV值最小为原则从10条候选工况中筛选一条典型代表工况。
基于传统短行程方法和本发明提出的方法所构建的代表工况特征对比结果如表6所示。所构建的代表工况与用于开发和验证的原始行驶数据之间的PV值分别为2.72%和2.95%,而传统短行程方法所构建工况与原始数据之间的PV值分别为3.64%和3.81%。本发明所提出的工况构建方法能够有效反应所研究纯电动汽车的行驶特征,且工况构建精度更高,与实际行驶工况的一致性更好,证明了该方法的有效性与可靠性。
表6代表工况特征参数对比
- 一种纯电动汽车行驶工况构建方法
- 一种基于车联网的纯电动汽车行驶工况预测方法