一种基于LSTM的数据链网络保障需求采集方法及其应用
文献发布时间:2023-06-19 12:19:35
技术领域
本发明属于网络技术领域,更具体地,涉及一种基于LSTM的数据链网络保障需求采集方法及其应用。
背景技术
数据链网络是实现指控平台、武器平台和传感器平台深度铰链的关键系统,是提升联合作战中“侦、控、打、评”作战环路敏捷性、精准度的核心系统。区别于一般的军事无线通信系统,数据链网络与作战行动是紧密关联的,是一个作战任务订制的通信系统,为了提供实时态势信息共享和传感器到武器平台的快速作战能力,需要在作战行动开始之前,根据特定的作战方案进行通信需求分析,进行科学精细网络设计规划。能否高效、精准地完成数据链网络设计规划,是实现数据链系统组网和作战运用的关键,是应用数据链系统提升作战体系的整体对抗能力、提高武器系统作战效能的前提。通过数据链网络保障需求采集形成数据链网络通信需求,是数据链网络设计规划的起点。
目前,数据链网络保障需求的采集主要依赖人工操作,从非格式化的作战计划文档中手动提取出任务类型、兵力编配、指挥关系、协同关系、兵力部署、作战地域、战场环境、行动计划等数据链保障需求要素。由于完全依赖人工操作,步骤繁琐、耗时较长,通常需要若干小时。考虑到数据链网络保障需求采集是数据链网络设计规划的起点,需求采集过程中耗时较长,将直接导致整个数据链网络设计规划过程耗时较长,不利于数据链网络的快速开通,将严重影响数据链系统的作战效能。
因此,设计一种自动化的数据链网络保障需求采集方法,将能有效缩短传统数据链网络保障需求人工采集所需要的时间,对实现高效的数据链网络设计规划具有重要意义。
发明内容
针对现有技术的至少一个缺陷或改进需求,本发明提供了提出一种基于LSTM的数据链网络保障需求采集方法及其应用,相比于现在人工采集的方式,本发明能够大大缩短需求采集所需要的时间,同时具有较高的需求采集准确性。
为实现上述目的,按照本发明的第一方面,提供了一种基于LSTM的数据链网络保障需求采集方法,包括步骤:
获取作战计划文档,将所述作战计划文档转换为向量后输入到命名实体识别模型,获取所述作战计划文档中的主体;
计算所述作战计划文档每个字与主体的位置向量,将所述作战计划文档的向量与所述位置向量输入到关系分类模型,获取与主体关联的客体,并确定主体与客体间的关系,获得包含包括主体、关系和客体的三元组数据;
对所述三元组数据进行反译重构得到数据链网络保障需求;
其中,所述命名实体识别模型和所述关系分类模型均基于LSTM神经网络实现。
优选的,所述命名实体识别模型包括依次连接的输入层、第一池化层、第一语义提取层、第二池化层、第二语义提取层、第三池化层、第三语义提取层和输出层,所述输入层用于接收所述作战计划文档的向量,所述输出层用于输出所述作战计划文档中的主体的开始位置和结束位置。
优选的,所述关系分类模型包括依次连接的输入层、第一池化层、语义提取层、第二池化层和输出层,所述输入层用于接收所述作战计划文档的向量与所述位置向量,所述关系分类模型还包括主体词位置筛选分类器,所述主体词位置筛选分类器用于接收所述第二池化层的输出,并将主体的语义向量提取出来输出给所述输出层,所述输出层包括第一输出层和第二输出层,所述第一输出层用于输出所述作战计划文档中的主体关联的客体的开始位置以及主体与客体间的关系,所述第二输出层用于输出所述作战计划文档中的主体关联的客体的结束位置以及主体与客体间的关系。
优选的,所述作战计划文档的向量包括所述作战计划文档的字向量、词向量和词性向量。
优选的,其部署在飞腾服务器和银河麒麟操作系统上,所述命名实体识别模型和所述关系分类模型基于百度飞桨深度学习开发框架实现。
按照本发明的第二方面,提供了一种基于LSTM的数据链网络保障需求采集系统,包括:
主体识别模块,用于获取作战计划文档,将所述作战计划文档转换为向量后输入到命名实体识别模型,获取所述作战计划文档中的主体;
关系识别模块,用于计算所述作战计划文档每个字与主体的位置向量,将所述作战计划文档的向量与所述位置向量输入到关系分类模型,获取与主体关联的客体,并确定主体与客体间的关系,获得包含包括主体、关系和客体的三元组数据;
重构模块,用于对所述三元组数据进行反译重构得到数据链网络保障需求;
其中,所述命名实体识别模型和所述关系分类模型均基于LSTM神经网络实现。
按照本发明的第三方面,提供了一种计算机可读存储介质,其上存储有计算机程序,所述计算机程序被处理器执行时实现上述任一项方法。
总体而言,本发明与现有技术相比,具有有益效果:
(1)本发明专利提出将数据链网络保障需求描述成<主体、关系、客体>三元组,并利用信息抽取技术实现从作战计划文本中自动提取数据链网络保障需求,相比传统的人工提取方法,能够有效提高提取效率,同时具有较高的提取精准度。
(2)本发明专利所提方法在国产服务器、国产操作系统和国产深度学习开发框架上进行设计部署,技术上完全自主可控;并且针对国产软硬件特点,对算法模型进行优化设计,相比信息抽取技术的主流方法模型,具有更好的运行效率。
附图说明
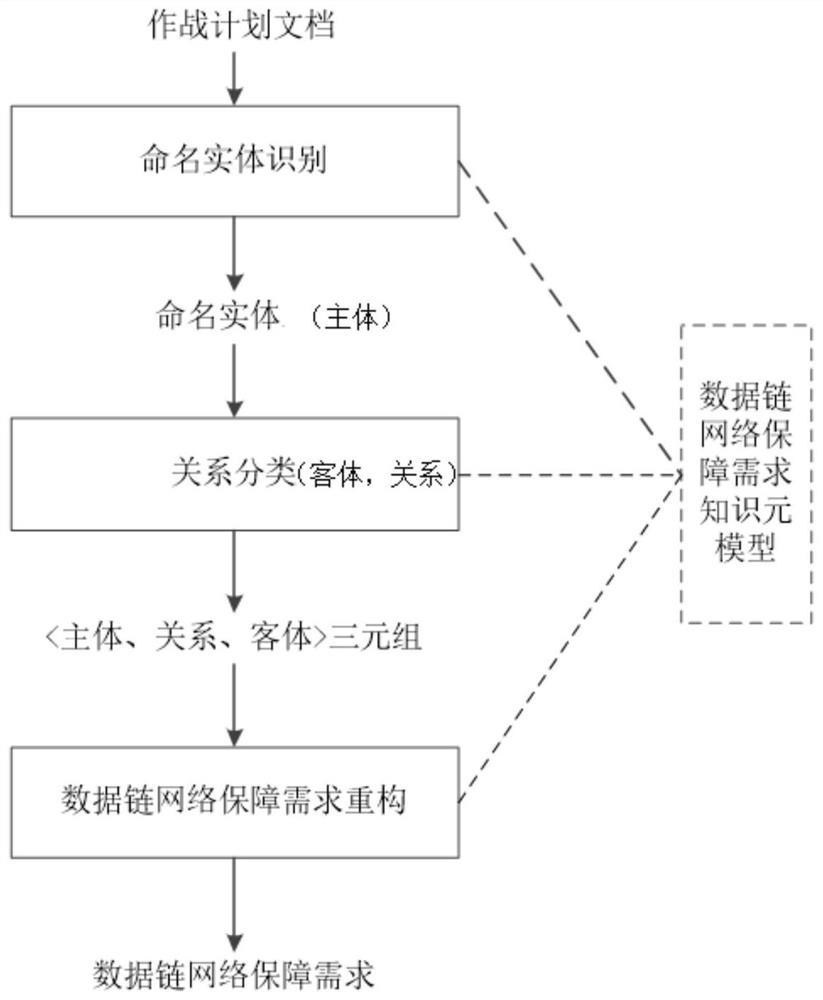
图1是本发明实施例的数据链网络保障需求采集方法流程图;
图2是本发明实施例的数据链网络保障需求采集方法部署示意图;
图3是本发明实施例的命名实体识别模型结构示意图;
图4是本发明实施例的命名实体识别模型处理示意图;
图5是本发明实施例的关系分类模型结构示意图;
图6是本发明实施例的关系分类模型处理示意图。
具体实施方式
为了使本发明的目的、技术方案及优点更加清楚明白,以下结合附图及实施例,对本发明进行进一步详细说明。应当理解,此处所描述的具体实施例仅用以解释本发明,并不用于限定本发明。此外,下面所描述的本发明各个实施方式中所涉及到的技术特征只要彼此之间未构成冲突就可以相互组合。
本发明实施例的基于LSTM的数据链网络保障需求采集方法,其基本思想是将数据链网络保障需求通过<主体、关系、客体>三元组信息进行表达,例如在作战计划文本中有这样一句“联合指挥所直接指挥海上联合编队指挥舰”,描述了联合指挥所和海上联合编队指挥舰之间存在着指挥关系,属于数据链网络保障需求信息,该保障需求可以描述成<联合指挥所、指挥、海上联合编队指挥舰>三元组。通过使用信息抽取技术,本发明实施例能够将作战计划文本中所有涉及数据链网络需求的信息提取成三元组,最后通过将三元组反译成数据链网络保障需求。
如图1所示,本发明实施例的基于LSTM的数据链网络保障需求采集方法包括步骤:(1)主体识别,具体是获取作战计划文档,将作战计划文档转换为向量后输入到命名实体识别模型,获取作战计划文档中的主体;(2)客体和关系识别,具体是计算作战计划文档每个字与主体的位置向量,将作战计划文档的向量与位置向量输入到关系分类模型,获取与主体关联的客体,并确定主体与客体间的关系,获得包含包括主体、关系和客体的三元组数据;(3)在从作战计划文本中抽取得到所有涉及数据链网络需求的三元组信息后,通过三元组反译重构得到数据链网络保障需求。在命名实体识别、关系分类和数据链网络保障需求重构这三个过程中,都需要使用数据链网络保障需求知识元模型,该元模型中定义了涵盖所有数据链网络保障需求的三元组类别,即<主体、关系、客体>三元组数据。
其中,主体的含义是动作的发出者或表述对象。客体的含义是动作的承受者。关系的含义是陈述主体的状态或者表明主体发出的动作。
下面对关键步骤的优选实现方式进行具体说明。
1.总体设计
1.1系统部署方案
如图2所示,为了支持国产自主可控软硬件平台,本专利提出的方法部署环境优选为:(1)国产飞腾服务器,配置飞腾2000PLUS(ARM架构,64核)CPU;(2)国产银河麒麟操作系统;(3)国产深度学习开发框架,百度飞桨(PaddlePaddle)框架。为了充分利用飞腾CPU的多核能力,提高系统的运行效率,采用并发的方式进行部署。
1.2算法模型设计
在信息抽取技术中,目前主流的方法大多基于预训练语言模型,这些方法具有准确性高的优点,但由于计算复杂度较高,导致计算时效性较差,耗时较长。目前,国产深度学习开发框架在国产硬件平台上还缺乏硬件加速板卡的良好支撑。例如,作为国产深度学习开发框架的优秀代表,百度公司研发的飞桨仍在进行与国产硬件加速板卡的适配工作。基于14nm工艺的昆仑AI处理器,百度开发了K100和K200两款硬件加速板卡,也仅完成了对部分开源神经网络算法模型的适配,仍缺乏对用户自定义神经网络算法模型的适配能力。因此,基于预训练语言模型的方法在国产软硬件平台上具有计算时效性较差的缺点,无法满足用户的使用需求。为了解决这个问题,本专利提出的方法中没有使用预训练语言模型,而是基于LSTM(Long Short Time Memory:长短时记忆)神经网络设计了轻量化的算法模型,在保证计算时效性的同时具有较高的准确性。
在传统的命名实体识别过程中,将同时识别文本段落中的主体和客体,再在关系分类过程中,对任意可能组合的主体和客体对进行关系判定。考虑到主体和客体两两组合导致的多样性既增加了计算复杂度,同时也会影响准确性,在本专利提出的方法中,在命名实体识别时,仅识别文本段落中的主体,然后在关系分类过程中,识别与该主体相关的客体并同时判定主体和客体之间的关系。
2.命名实体识别
通过命名实体识别,将作战计划文本中数据链网络保障需求涉及到的主体词抽取出来。例如,在“联合指挥所直接指挥海上联合编队指挥舰”中,联合指挥所和海上联合编队指挥舰之间存在着指挥关系,通过命名实体识别,应该将“联合指挥所”这个主体词给识别出来。在本专利中,本发明实施例设计了基于LSTM神经网络的命名实体识别模型,如图3所示。命名实体识别模型包括依次连接的输入层、第一池化层(Dropout层1)、第一语义提取层(语义提取层1)、第二池化层(Dropout层2)、第二语义提取层(语义提取层2)、第三池化层(Dropout层3)、第三语义提取层(语义提取层3)和输出层。
2.1输入层
产生输入文本的字向量、词向量和词性向量,作为网络的输入。其中字和词向量使用腾讯发布的词向量;词性向量使用随机初始化。网络在训练过程中对字向量和词性向量进行优化调整。
2.2 Dropout(池化)层1
该层无参数,通过以15%的概率随机将网络中一些神经元的输出置零,为网络提供抗过拟合能力。
2.3语义提取层1
使用BiLSTM(双向LSTM神经网络)提取文本的语义信息,其隐层神经元数量为200。BiLSTM层的网络参数使用随机初始化。
2.4 Dropout(池化)层2
该层无参数,通过以15%的概率随机将网络中一些神经元的输出置零,为网络提供抗过拟合能力。
2.5语义提取层2
使用BiLSTM(双向LSTM神经网络)进一步提取文本的语义信息,其隐层神经元数量为200。BiLSTM层的网络参数使用随机初始化。
2.6 Dropout(池化)层3
该层无参数,通过以15%的概率随机将网络中一些神经元的输出置零,为网络提供抗过拟合能力。
2.7语义提取层3
使用序列化Dense(分类神经网络),将文本中的每个字编码成100长度的向量,继续提取文本的语义信息。
2.8输出层1
使用序列化Dense(分类神经网络),将文本中的每个字分类成0或者1。若某个字被分类成1,则表示该字为某个主体的开始字。
2.9输出层2
使用序列化Dense(分类神经网络),将文本中的每个字分类成0或者1。若某个字被分类成1,则表示该字为某个主体的结束字。
在给定例句“联合指挥所直接指挥海上联合编队指挥舰”中,命名实体识别模型对例句进行处理示意如图4所示。
3.关系分类
给定作战计划文本和一个数据链网络保障需求涉及到的主体词,通过关系分类,将该主体词对应的客体词识别出来,同时判定该主体词和客体词之间的关系。例如,给定文本“联合指挥所直接指挥海上联合编队指挥舰”和一个主体词“联合指挥所”,通过命名实体识别,应该将“海上联合编队指挥舰”这个关联的客体词给识别出来,同时判定“联合指挥所”和“海上联合编队指挥舰”之间存在着指挥关系。在本专利中,本发明实施例设计了基于LSTM神经网络的关系分类模型,如图5所示。关系分类模型包括依次连接的输入层、第一池化层、语义提取层、第二池化层和输出层,输入层用于接收作战计划文档的向量与位置向量,关系分类模型还包括主体词位置筛选分类器,主体词位置筛选分类器用于接收第二池化层的输出,并将主体的语义向量提取出来输出给输出层,输出层包括第一输出层和第二输出层,第一输出层用于输出作战计划文档中的主体关联的客体的开始位置以及主体与客体间的关系,第二输出层用于输出作战计划文档中的主体关联的客体的结束位置以及主体与客体间的关系。
3.1输入层
产生输入文本的字向量、词向量、词性向量和文本中每个字距离给定主体词的位置向量,作为网络的输入。其中字词向量使用腾讯发布的词向量;词性向量和位置距离向量使用随机初始化。网络在训练过程中对字向量、词性向量和位置距离向量进行优化调整。
3.2 Dropout(池化)层1
该层无参数,通过以15%的概率随机将网络中一些神经元的输出置零,为网络提供抗过拟合能力。
3.3语义提取层
使用BiLSTM(双向LSTM神经网络)提取文本的语义信息,其隐层神经元数量为200。BiLSTM层的网络参数使用随机初始化。
3.4 Dropout(池化)层2
该层无参数,通过以15%的概率随机将网络中一些神经元的输出置零,为网络提供抗过拟合能力。
3.5主体词位置筛选器
该层无参数,实现从文本语义向量中,将主体词的语义向量提取出来。
3.6输出层1
使用序列化Dense(分类神经网络),将文本中的每个字分类成关系数量+1类。若某个字被分类成某个关系类别,则表示该字为某个客体的开始字,并且该客体与输入的主体具有该关系。
3.7输出层2
使用序列化Dense(分类神经网络),将文本中的每个字分类成关系数量+1类。若某个字被分类成某个关系类别,则表示该字为某个客体的结束字,并且该客体与输入的主体具有该关系。
在给定例句“联合指挥所直接指挥海上联合编队指挥舰”和主体词“联合指挥所”后,关系分类模型对例句和主体词进行处理示意如图6所示。
4.数据链网络保障需求重构
根据数据链网络保障需求知识元模型,将三元组重构成数据链网络保障需求。例如,根据三元组<联合指挥所,指挥,海上联合编队指挥舰>可以直接得到“联合指挥所”和“海上联合编队指挥舰”存在着指挥关系这个数据链网络保障需求。
5.实验结果
为了验证本专利所提出方法的有效性,在一台配置有飞腾2000PLUS(ARM架构,64核)CPU、64G内存、麒麟操作系统、百度飞浆(PaddlePaddle 1.7)深度学习开发框架的飞腾服务器上进行实验,并与基于谷歌BERT预训练语言模型的方法进行比较。实验数据集包含3000个样本,每个样本的平均长度为1000个字,表1给出了实验结果。
表1本专利方法和基于谷歌BERT预训练语言模型方法的实验结果比较
如表1所示,本专利方法和基于谷歌BERT预训练语言模型方法在计算精准度上差别不大,F1值都在84%以上;但在运行时间上,本专利方法具有明显优势,相比基于谷歌BERT预训练语言模型方法缩短了将近30倍。
本发明实施例的一种基于LSTM的数据链网络保障需求采集系统,包括:
主体识别模块,用于获取作战计划文档,将作战计划文档转换为向量后输入到命名实体识别模型,获取作战计划文档中的主体;
关系识别模块,用于计算作战计划文档每个字与主体的位置向量,将作战计划文档的向量与位置向量输入到关系分类模型,获取与主体关联的客体,并确定主体与客体间的关系,获得包含包括主体、关系和客体的三元组数据;
重构模块,用于对三元组数据进行反译重构得到数据链网络保障需求;
其中,命名实体识别模型和关系分类模型均基于LSTM神经网络实现。
系统的实现原理、技术效果与上述方法类似,此处不再赘述。
本发明实施例还提供一种计算机可读存储介质,其上存储有计算机程序,计算机程序被处理器执行以实现上述任一基于LSTM的数据链网络保障需求采集方法实施例的技术方案。其实现原理、技术效果与上述方法类似,此处不再赘述。
必须说明的是,上述任一实施例中,方法并不必然按照序号顺序依次执行,只要从执行逻辑中不能推定必然按某一顺序执行,则意味着可以以其他任何可能的顺序执行。
本领域的技术人员容易理解,以上所述仅为本发明的较佳实施例而已,并不用以限制本发明,凡在本发明的精神和原则之内所作的任何修改、等同替换和改进等,均应包含在本发明的保护范围之内。
- 一种基于LSTM的数据链网络保障需求采集方法及其应用
- 基于知识图谱的数据链网络保障方案智能推荐方法及应用