工程化DNA聚合酶变体
文献发布时间:2023-06-19 12:21:13
本申请要求于2018年10月29日提交的美国临时专利申请序列第62/752,215号的优先权,该美国临时专利申请为了所有的目的通过引用以其整体并入。
对序列表、表格或计算机程序的引用
按照37C.F.R.§1.821,以计算机可读形式(CRF)通过EFS-Web以文件名CX9-181WO2_ST25.txt同时提交的序列表通过引用并入本文。序列表的电子副本创建于2019年10月28日,文件大小为5,361千字节。
发明领域
本发明提供了工程化DNA聚合酶多肽及其组合物、以及编码工程化DNA聚合酶多肽的多核苷酸。本发明还提供了使用包含工程化DNA聚合酶多肽的组合物用于诊断和其他目的的方法。
发明背景
DNA聚合酶是从脱氧核糖核苷酸合成DNA的酶。这些酶是DNA复制必需的。DNA聚合酶类型繁多,一般分为7个家族,即A、B、C、D、X、Y和RT。这些家族具有不同的性质,并且在不同类型的生物体中发现。例如,A组聚合酶是在真核生物和原核生物中都发现的复制和修复聚合酶(实例包括T7 DNA聚合酶和大肠杆菌(E.coli)polI)。B组聚合酶也是在真核生物和原核生物中发现的复制和修复酶(例如pol II、pol B等)。C组和D组包含分别在原核生物体和广古菌门(Euryarchaeota)中发现的复制型聚合酶(C组聚合酶包括pol III,但D组聚合酶未充分表征)。X、Y和RT组聚合酶是在真核生物(X组)、真核生物和原核生物(Y组)以及病毒、逆转录病毒和真核生物(RT组)中发现的复制和修复酶。X组聚合酶的实例包括polβ,而Y组聚合酶包括pol IV和pol V,并且RT组聚合酶包括乙肝病毒的聚合酶。这些聚合酶中的一些,特别是从嗜热生物体获得的那些,已经在各种体外方法中发现了巨大的用途,包括但不限于聚合酶链式反应(PCR)。嗜热聚合酶的可得性使PCR的自动化成为可能。因此,在可使用PCR的应用中,这些是非常重要的酶。虽然许多酶是商售可得的(例如,Taq和许多其他酶),但本领域仍需要具有高保真度水平的热稳定酶。
发明概述
本发明提供了工程化DNA聚合酶多肽及其组合物、以及编码工程化DNA聚合酶多肽的多核苷酸。本发明还提供了使用包含工程化DNA聚合酶多肽的组合物用于诊断和其他目的的方法。
本发明提供了工程化DNA聚合酶,该工程化DNA聚合酶包含与参考序列SEQ ID NO:2、6、22、24、26、28和/或824具有至少85%、90%、91%、92%、93%、94%、95%、96%、97%、98%、99%或更多的序列同一性的多肽序列或其功能片段,其中该工程化DNA聚合酶在其多肽序列中包含至少一个取代或取代集,并且其中多肽序列的氨基酸位置参考SEQ ID NO:2、6、22、24、26、28和/或824编号。
本发明还提供了工程化DNA聚合酶,该工程化DNA聚合酶在选自以下的一个或更多个位置处包含至少一个取代或取代集:21、21/66/247/282、247/282/575、282/575、283/647/702/743、339/647/661/664/668/702/712、372/391/702、391、391/647/659/661/668/671/712/716、391/647/659/661/668/671/716、391/647/659/664/668/702/728/732、391/647/659/664/671/702、391/647/661/664/671/702/716、391/647/671/728、391/659/702/716/732/737、391/661/664/668/671/716/737、391/671、391/702/712/716/732/743、647/659/661/664/668/702、647/659/664/668/702/712/737、647/659/668/671/716/728、647/668、647/668/671/712、659/702/743、661/664/668/671/716、668/702、671/702、671/702/716、702和743和/或其任何组合,其中氨基酸位置参考SEQ ID NO:6编号。在一些实施方案中,至少一个取代或取代集选自21E、21E/66T/247G/282R、247G/282K/575L、282K/575L、283M/647H/702A/743A、339L/647H/661T/664L/668E/702A/712V、372S/391E/702A、391E、391E/647H/659E/661T/668E/671P/712V/716I、391E/647H/659E/661T/668E/671P/716I、391E/647H/659E/664L/668E/702A/728A/732E、391E/647H/659E/664L/671P/702A、391E/647H/661T/664L/671P/702A/716I、391E/647H/671P/728A、391E/659E/702A/716I/732E/737R、391E/661T/664L/668E/671P/716I/737R、391E/671P、391E/702A/712V/716I/732E/743A、647H/659E/661T/664L/668E/702A、647H/659E/664L/668E/702A/712V/737R、647H/659E/668E/671P/716I/728A、647H/668E、647H/668E/671P/712V、659E/702A/743A、661T/664L/668E/671P/716I、668E/702A、671P/702A、671P/702A/716I、702A和743A,其中氨基酸位置参考SEQ ID NO:6编号。
本发明还提供了工程化DNA聚合酶,该工程化DNA聚合酶在选自以下的一个或更多个位置处包含至少一个取代或取代集:18/387、24/719、43/528、48/760、101/646、108/679、223、257、282、359、360、361、362、376/619、390、391、394、394/399、420、421、478、502、506、514、515、521、528、583/730、603、619、631、646、655、662、666、668、685、691、702、721、738、754、760和761和/或其任何组合,其中氨基酸位置参考SEQ ID NO:6编号。在一些实施方案中,至少一个取代或取代集选自18H/387C、24M/719A、43L/528S、48H/760H、101S/646R、108C/679S、223N、257R、257W、282R、359C、360R、360T、360V、361G、361M、361W、362R、376V/619F、390A、390G、390Q、391A、391G、394G、394M/399R、394N、394T、420A、420G、420I、420K、420V、421M、421Q、478L、502A、506R、514R、515F、515G、515R、521P、521T、528A、528S、583N/730A、603R、619C、619V、631G、646R、655W、662C、666T、668C、668L、685D、691S、702A、721R、721T、738V、754C、760F、760G、761R和761W和/或其任何组合,其中氨基酸位置参考SEQ IDNO:6编号。在一些实施方案中,至少一个取代或取代集选自Y18H/E387C、K24M/K719A、P43L/T528S、Y48H/E760H、P101S/K646R、R108C/Q679S、D223N、M257R、M257W、N282R、R359C、S360R、S360T、S360V、S361G、S361M、S361W、T362R、A376V/T619F、Y390A、Y390G、Y390Q、K391A、K391G、L394G、L394M/L399R、L394N、L394T、R420A、R420G、R420I、R420K、R420V、S421M、S421Q、K478L、L502A、S506R、P514R、K515F、K515G、K515R、K521P、K521T、T528A、T528S、S583N/L730A、V603R、T619C、T619V、E631G、K646R、E655W、E662C、K666T、R668C、R668L、K685D、G691S、T702A、S721R、S721T、K738V、A754C、E760F、E760G、A761R和A761W和/或其任何组合,其中氨基酸位置参考SEQ ID NO:6编号。
本发明还提供了工程化DNA聚合酶,该工程化DNA聚合酶在选自以下的一个或更多个位置处包含至少一个取代或取代集:174/361/394/666/668/721、360/391、361/391/659、361/394/420/528/646/666/721/743、361/394/420/528/666、361/394/420/646/666/702/721/743、361/528/646/666、361/528/646/702/721、361/528/666、361/646、394/420、502/507/695、528/646/659/668/743、528/666、528/668、528/743、619、666和685/691/743和/或其任何组合,其中氨基酸位置参考SEQ ID NO:22编号。在一些实施方案中,至少一个取代或取代集选自174V/361G/394T/666T/668L/721T、360T/391G、361G/394T/420A/528A/666T、361G/394T/420A/528S/646R/666T/721T/743P、361G/528A/646R/666T、361G/528A/666T、361G/528S/646R/702T/721T、361G/646R、361M/391A/659D、361W/394T/420A/646R/666T/702T/721T/743P、394G/420K、502I/507F/695A、528S/646R/659D/668L/743P、528S/666T、528S/668L、528S/743P、619C、666T和685D/691S/743P和/或其任何组合,其中氨基酸位置参考SEQ ID NO:22编号。在一些实施方案中,至少一个取代或取代集选自A174V/S361G/L394T/K666T/R668L/S721T、S360T/K391G、S361G/L394T/R420A/T528A/K666T、S361G/L394T/R420A/T528S/K646R/K666T/S721T/A743P、S361G/T528A/K646R/K666T、S361G/T528A/K666T、S361G/T528S/K646R/A702T/S721T、S361G/K646R、S361M/K391A/E659D、S361W/L394T/R420A/K646R/K666T/A702T/S721T/A743P、L394G/R420K、L502I/Y507F/S695A、T528S/K646R/E659D/R668L/A743P、T528S/K666T、T528S/R668L、T528S/A743P、T619C、K666T和K685D/G691S/A743P和/或其任何组合,其中氨基酸位置参考SEQ ID NO:22编号。
本发明还提供了工程化DNA聚合酶,该工程化DNA聚合酶在选自以下的一个或更多个位置处包含至少一个取代或取代集:100、277、280、281、283、339、401、468、479、480、482、489、490、491、496、497和498和/或其任何组合,其中氨基酸位置参考SEQ ID NO:22编号。在一些实施方案中,至少一个取代或取代集选自100Y、277A、280Y、281C、283V、339M、401S、468N、479P、479Q、480D、480M、482Q、482V、489V、490L、491L、496A、497D和498C和/或其任何组合,其中氨基酸位置参考SEQ ID NO:22编号。在一些实施方案中,至少一个取代或取代集选自H100Y、V277A、T280Y、I281C、L283V、F339M、G401S、G468N、K479P、K479Q、K480D、K480M、K482Q、K482V、E489V、K490L、K491L、R496A、Q497D和R498C和/或其任何组合,其中氨基酸位置参考SEQ ID NO:22编号。
本发明还提供了工程化DNA聚合酶,该工程化DNA聚合酶在选自以下的一个或更多个位置处包含至少一个取代或取代集:15/134/482/490/497/671/685、234/497/647、257/390/420、257/390/420/647、257/401/420、257/401/420/482/647/671/685、257/482/497/647、257/647、257/671/685/702、281、281/391/478、281/391/478/685、281/391/488/492、281/391/495/561/659/668、281/391/659/668、281/391/668、281/478/659/685/702、281/478/668、281/488、281/488/492/495/659/668、281/488/492/668/702、281/488/495、281/488/495/668、281/492/495/668、281/492/495/668/702、281/668、390/401/716、390/420、390/491/671、390/497、390/671/685、391、391/478、391/478/479/668、391/478/492/668、391/479/659/668、391/488/492/659/685、391/488/492/668、391/488/495/668/685/702、391/492/495、391/492/495/659、391/492/515/659/685、391/495/659、401、401/482/659/671/702、401/490、401/490/659/671、401/671、420、420/482/659/702、420/490、420/490/659/661/671、420/659/702、420/661/671、420/685、478、478/479、478/479/668、478/479/702、478/488/659、478/488/668/685/702、478/515、479/492、479/659/678、482/497/647/716、482/497/671/685、482/671/702/716、488、488/492、488/492/495、488/495、488/495/685、490/497/661/671/685/702/716、492、492/495/659/668、492/659/685、492/668/685/712、492/668/712、495、495/659、495/659/685、497/647、497/647/659/671、497/659/691/716、497/661、497/661/671、497/671/702、497/671/716、497/685、497/702、515、659、659/691和671和/或其任何组合,其中氨基酸位置参考SEQ ID NO:24编号。在一些实施方案中,至少一个取代或取代集选自15N/134N/482Q/490L/497D/671P/685K、234V/497D/647H、257W/390H/420Q、257W/390Q/420Q/647H、257W/401S/420Q、257W/401S/420Q/482Q/647H/671P/685K、257W/482Q/497D/647H、257W/647H、257W/671P/685K/702T、281C、281C/391E/478L/685K、281C/391E/488R/492V、281C/391G/478L、281C/391G/495N/561A/659D/668E、281C/391G/659D/668E、281C/391G/668E、281C/478L/659D/685K/702T、281C/478L/668E、281C/488R、281C/488R/492V/495N/659D/668E、281C/488R/492V/668E/702T、281C/488R/495N、281C/488R/495N/668E、281C/492V/495N/668E、281C/492V/495N/668E/702T、281C/668E、390Q/401S/716I、390Q/420Q、390Q/491D/671P、390Q/497D、390Q/671P/685K、391E、391E/478L、391E/478L/479P/668E、391E/488R/492V/659D/685K、391E/488R/492V/668E、391E/492V/495N/659D、391G/478L/492V/668E、391G/479P/659D/668E、391G/488R/495N/668E/685K/702T、391G/492V/495N、391G/492V/515L/659D/685K、391G/495N/659D、401S、401S/482Q/659D/671P/702T、401S/490L、401S/490L/659D/671P、401S/671P、420G、420Q、420Q/482Q/659D/702T、420Q/490L、420Q/490L/659D/661T/671P、420Q/659D/702T、420Q/661T/671P、420Q/685K、478L、478L/479P、478L/479P/668E、478L/479P/702T、478L/488R/659D、478L/488R/668E/685K/702T、478L/515L、479P/492V、479P/659D/678G、482Q/497D/647H/716I、482Q/497D/671P/685K、482Q/671P/702T/716I、488R、488R/492V、488R/492V/495N、488R/495N、488R/495N/685K、490L/497D/661T/671P/685K/702T/716I、492V、492V/495N/659D/668E、492V/659D/685K、492V/668E/685K/712V、492V/668E/712V、495N、495N/659D、495N/659D/685K、497D/647H、497D/647H/659D/671P、497D/659D/691G/716I、497D/661T、497D/661T/671P、497D/671P/702T、497D/671P/716I、497D/685K、497D/702T、515L、659D、659D/691G和671P和/或其任何组合,其中氨基酸位置参考SEQ ID NO:24编号。在一些实施方案中,至少一个取代或取代集选自D15N/D134N/K482Q/K490L/Q497D/L671P/D685K、A234V/Q497D/D647H、M257W/Y390H/R420Q、M257W/Y390Q/R420Q/D647H、M257W/G401S/R420Q、M257W/G401S/R420Q/K482Q/D647H/L671P/D685K、M257W/K482Q/Q497D/D647H、M257W/D647H、M257W/L671P/D685K/A702T、I281C、I281C/K391E/K478L/D685K、I281C/K391E/I488R/M492V、I281C/K391G/K478L、I281C/K391G/Y495N/T561A/E659D/R668E、I281C/K391G/E659D/R668E、I281C/K391G/R668E、I281C/K478L/E659D/D685K/A702T、I281C/K478L/R668E、I281C/I488R、I281C/I488R/M492V/Y495N/E659D/R668E、I281C/I488R/M492V/R668E/A702T、I281C/I488R/Y495N、I281C/I488R/Y495N/R668E、I281C/M492V/Y495N/R668E、I281C/M492V/Y495N/R668E/A702T、I281C/R668E、Y390Q/G401S/L716I、Y390Q/R420Q、Y390Q/K491D/L671P、Y390Q/Q497D、Y390Q/L671P/D685K、K391E、K391E/K478L、K391E/K478L/K479P/R668E、K391E/I488R/M492V/E659D/D685K、K391E/I488R/M492V/R668E、K391E/M492V/Y495N/E659D、K391G/K478L/M492V/R668E、K391G/K479P/E659D/R668E、K391G/I488R/Y495N/R668E/D685K/A702T、K391G/M492V/Y495N、K391G/M492V/K515L/E659D/D685K、K391G/Y495N/E659D、G401S、G401S/K482Q/E659D/L671P/A702T、G401S/K490L、G401S/K490L/E659D/L671P、G401S/L671P、R420G、R420Q、R420Q/K482Q/E659D/A702T、R420Q/K490L、R420Q/K490L/E659D/V661T/L671P、R420Q/E659D/A702T、R420Q/V661T/L671P、R420Q/D685K、K478L、K478L/K479P、K478L/K479P/R668E、K478L/K479P/A702T、K478L/I488R/E659D、K478L/I488R/R668E/D685K/A702T、K478L/K515L、K479P/M492V、K479P/E659D/E678G、K482Q/Q497D/D647H/L716I、K482Q/Q497D/L671P/D685K、K482Q/L671P/A702T/L716I、I488R、I488R/M492V、I488R/M492V/Y495N、I488R/Y495N、I488R/Y495N/D685K、K490L/Q497D/V661T/L671P/D685K/A702T/L716I、M492V、M492V/Y495N/E659D/R668E、M492V/E659D/D685K、M492V/R668E/D685K/I712V、M492V/R668E/I712V、Y495N、Y495N/E659D、Y495N/E659D/D685K、Q497D/D647H、Q497D/D647H/E659D/L671P、Q497D/E659D/S691G/L716I、Q497D/V661T、Q497D/V661T/L671P、Q497D/L671P/A702T、Q497D/L671P/L716I、Q497D/D685K、Q497D/A702T、K515L、E659D、E659D/S691G和L671P,其中氨基酸位置参考SEQ ID NO:24编号。
本发明还提供了工程化DNA聚合酶,该工程化DNA聚合酶在选自以下的一个或更多个位置处包含至少一个取代或取代集:55/579、108、108/521、156/451、236/755、240、247、248、256、298、299、299/319、302、309、316、319、350、356、357、358、370、384、385、386、389、406、407、411、415、440、443、447、450、451、520、536、539、540、544、550/575、566、568、575、579、579/767、600、601、601/638、609/648、624、634、648、656、672、758、765、767、772、777、778、779、780、782、784和785和/或其任何组合,其中氨基酸位置参考SEQ ID NO:24编号。在一些实施方案中,至少一个取代或取代集选自55E/579V、55G/579A、108A、108C、108F、108G、108S、108V/521R、108Y、156L/451C、236R/755T、240A、240Y、247I、247S、248P、256A、298E、299A、299A/319G、299E、299Q、299R、302F、309V、316G、319E、319H、319S、350V、356N、356P、356V、357S、358I、370D、370S、370T、384R、385L、386G、386P、386V、389Q、389R、406V、407A、407L、407R、407S、407Y、411H、415V、440H、443V、447A、447L、450L、450Y、451G、520C、536N、536Q、536T、539G、539H、539Q、539S、539V、540G、544G、550S/575Q、566G、566Q、568G、568L、575F、575T、579A、579M、579Q、579Q/767Q、579R、579S、600A、601I、601L/638L、601M、601V、609C/648Q、624C、624S、634R、648Q、648R、656A、656Y、672G、758V、765D、767G、767T、772G、777D、778Q、779D、780A、780W、782S、782V、784-和785G和/或其任何组合,其中氨基酸位置参考SEQ ID NO:24编号。在一些实施方案中,至少一个取代或取代集选自D55E/N579V、D55G/N579A、R108A、R108C、R108F、R108G、R108S、R108V/K521R、R108Y、F156L/V451C、K236R/V755T、R240A、R240Y、K247I、K247S、E248P、R256A、K298E、T299A、T299A/K319G、T299E、T299Q、T299R、K302F、A309V、E316G、K319E、K319H、K319S、I350V、D356N、D356P、D356V、V357S、S358I、L370D、L370S、L370T、K384R、P385L、D386G、D386P、D386V、E389Q、E389R、P406V、E407A、E407L、E407R、E407S、E407Y、W411H、I415V、E440H、E443V、I447A、I447L、I450L、I450Y、V451G、S520C、E536N、E536Q、E536T、I539G、I539H、I539Q、I539S、I539V、K540G、E544G、V550S/R575Q、K566G、K566Q、E568G、E568L、R575F、R575T、N579A、N579M、N579Q、N579Q/E767Q、N579R、N579S、G600A、F601I、F601L/A638L、F601M、F601V、A609C/G648Q、V624C、V624S、K634R、G648Q、G648R、I656A、I656Y、E672G、I758V、R765D、E767G、E767T、Q772G、T777D、G778Q、L779D、D780A、D780W、W782S、W782V、K784-和R785G和/或其任何组合,其中氨基酸位置参考SEQ ID NO:24编号。
本发明还提供了工程化DNA聚合酶,该工程化DNA聚合酶在选自以下的一个或更多个位置处包含至少一个取代或取代集:248、281、281/302、281/492、302/401、339/491/492/579/712、390/466/539/712和661和/或其任何组合,其中氨基酸位置参考SEQ ID NO:26编号。在一些实施方案中,至少一个取代或取代集选自248P、281I、281I/302F、281I/492S、302F/401S、339A/491D/492V/579A/712V、390Q/466A/539S/712V和661T和/或其任何组合,其中氨基酸位置参考SEQ ID NO:26编号。在一些实施方案中,至少一个取代或取代集选自E248P、C281I、C281I/K302F、C281I/M492S、K302F/G401S、F339A/K491D/M492V/N579A/I712V、Y390Q/I466A/I539S/I712V和V661T和/或其任何组合,其中氨基酸位置参考SEQ IDNO:26编号。
本发明还提供了工程化DNA聚合酶,该工程化DNA聚合酶在选自以下的一个或更多个位置处包含至少一个取代或取代集:240/579、240/579/702、248/391/539/579/659/702、248/391/659、302/391/579、339/390/420/425/466/490/491/515/702、391、391/482、391/659、420/515、579、579/659/702、579/702和659/702和/或其任何组合,其中氨基酸位置参考SEQ ID NO:28编号。在一些实施方案中,至少一个取代或取代集选自240A/579A、240A/579A/702A、248P/391G/539S/579A/659D/702A、248P/391G/659D、302F/391G/579A、339A/390Q/420G/425R/466A/490L/491P/515L/702A、391G、391G/482Q、391G/659D、420G/515F、579A、579A/659D/702A、579A/702A和659D/702A和/或其任何组合,其中氨基酸位置参考SEQID NO:28编号。在一些实施方案中,至少一个取代或取代集选自R240A/N579A、R240A/N579A/T702A、E248P/K391G/I539S/N579A/E659D/T702A、E248P/K391G/E659D、K302F/K391G/N579A、F339A/Y390Q/R420G/S425R/I466A/K490L/K491P/K515L/T702A、K391G、K391G/K482Q、K391G/E659D、R420G/K515F、N579A、N579A/E659D/T702A、N579A/T702A和E659D/T702A和/或其任何组合,其中氨基酸位置参考SEQ ID NO:28编号。
本发明还提供了工程化DNA聚合酶,该工程化DNA聚合酶在选自以下的一个或更多个位置处包含至少一个取代或取代集:257、420、515和521和/或其任何组合,其中氨基酸位置参考SEQ ID NO:6编号。在一些实施方案中,至少一个取代或取代集选自257W、420Q、515L和521S和/或其任何组合,其中氨基酸位置参考SEQ ID NO:6编号。在一些实施方案中,至少一个取代或取代集选自M257W、R420Q、K515L和K521S和/或其任何组合,其中氨基酸位置参考SEQ ID NO:6编号。
本发明还提供了工程化DNA聚合酶,该工程化DNA聚合酶在选自以下的一个或更多个位置处包含至少一个取代或取代集:71/361/702/721/738、277、281、339、391/491、401、479、480、482、488、490、491、492、495、497、528/646/659/668/743、702/743和743和/或其任何组合,其中氨基酸位置参考SEQ ID NO:22编号。在一些实施方案中,至少一个取代或取代集选自71D/361M/702T/721R/738V、277A、281C、339M、391N/491Q、401S、479P、480M、482Q、482V、488R、490L、490Y、491D、492V、495N、497D、528S/646R/659D/668L/743P、702T/743P和743P和/或其任何组合,其中氨基酸位置参考SEQ ID NO:22编号。在一些实施方案中,至少一个取代或取代集选自G71D/S361M/A702T/S721R/K738V、V277A、I281C、F339M、K391N/K491Q、G401S、K479P、K480M、K482Q、K482V、I488R、K490L、K490Y、K491D、M492V、Y495N、Q497D、T528S/K646R/E659D/R668L/A743P、A702T/A743P和A743P和/或其任何组合,其中氨基酸位置参考SEQ ID NO:22编号。
本发明还提供了工程化DNA聚合酶,该工程化DNA聚合酶在选自以下的一个或更多个位置处包含至少一个取代或取代集:240、370、385、539、540、550/575、634和777和/或其任何组合,其中氨基酸位置参考SEQ ID NO:24编号。在一些实施方案中,至少一个取代或取代集选自240A、370T、385L、539V、540G、540Q、550S/575Q、634R、和777D和743P和/或其任何组合,其中氨基酸位置参考SEQ ID NO:24编号。在一些实施方案中,至少一个取代或取代集选自R240A、L370T、P385L、I539V、K540G、K540Q、V550S/R575Q、K634R和T777D和/或其任何组合,其中氨基酸位置参考SEQ ID NO:24编号。
本发明还提供了工程化DNA聚合酶,该工程化DNA聚合酶在选自以下的一个或更多个位置处包含至少一个取代或取代集:390/391、482和515和/或其任何组合,其中氨基酸位置参考SEQ ID NO:28编号。在一些实施方案中,至少一个取代或取代集选自390Q/391G、482Q、515F和515L和/或其任何组合,其中氨基酸位置参考SEQ ID NO:28编号。在一些实施方案中,至少一个取代或取代集选自Y390Q/K391G、K482Q、K515F和K515L和/或其任何组合,其中氨基酸位置参考SEQ ID NO:28编号。
本发明还提供了工程化DNA聚合酶,该工程化DNA聚合酶在选自以下的一个或更多个位置处包含至少一个取代或取代集:281、281/579和/或其任何组合,其中氨基酸位置参考SEQ ID NO:28编号。在一些实施方案中,至少一个取代或取代集选自281I和281I/579A和/或其任何组合,其中氨基酸位置参考SEQ ID NO:28编号。在一些实施方案中,至少一个取代或取代集选自C281I和C281I/N579A和/或其任何组合,其中氨基酸位置参考SEQ IDNO:28编号。
本发明还提供了工程化DNA聚合酶,该工程化DNA聚合酶在选自以下的一个或更多个位置处包含至少一个取代或取代集:13、15、19、26、52、55、61、80、81、82、95、111、118、141、148、152、156、162、163、179、181、187、189、191、196、208、221、229、231、242、258、274、297、313、314、317、325、326、333、349、377、387、394、395、411、447、450、451、453、469、482、496、502、520、521、537、563、564、564/572、567、569、575、580、601、603、619、620、648、667、673、690、705、719、731、758、761、772、774、775、778、783和784和/或其任何组合,其中氨基酸位置参考SEQ ID NO:824编号。在一些实施方案中,至少一个取代或取代集选自13T、15G、15W、19S、26S、52M、55K、55P、61A、61R、80G、81T、82Q、95R、111A、111V、118V、141R、141S、148P、152T、156R、162Q、163A、163G、163K、163P、163Q、163W、179G、181R、187L、189G、191A、191N、196A、196R、208C、221G、229S、231H、242L、258L、258R、258S、274I、274L、274V、297F、313F、314V、317P、317R、317T、325Q、326K、333R、349I、377W、387A、387S、394G、394R、395H、411T、447V、450V、451Y、453R、469H、469L、482V、496S、502W、520C、521V、537G、537K、563L、564D/572G、564Q、567G、569G、569L、569T、575H、575W、580A、580I、601I、603R、619L、619V、620K、648F、667N、667T、673M、690L、705L、719A、731G、758V、761P、772S、774R、775F、775G、778P、778R、783Q、783R和784E,其中氨基酸位置参考SEQ ID NO:824编号。在一些另外的实施方案中,至少一个取代或取代集选自I13T、D15G、D15W、I19S、I26S、L52M、D55K、D55P、E61A、E61R、V80G、K81T、V82Q、K95R、I111A、I111V、I118V、E141R、E141S、L148P、D152T、F156R、E162Q、F163A、F163G、F163K、F163P、F163Q、F163W、A179G、V181R、I187L、L189G、Y191A、Y191N、S196A、S196R、V208C、N221G、Y229S、I231H、V242L、G258L、G258R、G258S、F274I、F274L、F274V、G297F、E313F、T314V、S317P、S317R、S317T、S325Q、M326K、Y333R、L349I、R377W、E387A、E387S、L394G、L394R、R395H、W411T、I447V、I450V、V451Y、Y453R、D469H、D469L、K482V、R496S、L502W、S520C、K521V、M537G、M537K、P563L、G564D/K572G、G564Q、P567G、I569G、I569L、I569T、R575H、R575W、Y580A、Y580I、F601I、V603R、T619L、T619V、R620K、G648F、Y667N、Y667T、K673M、I690L、I705L、K719A、L731G、I758V、A761P、Q772S、S774R、K775F、K775G、G778P、G778R、L783Q、L783R和K784E,其中氨基酸位置参考SEQID NO:824编号。
本发明还提供了工程化DNA聚合酶,该工程化DNA聚合酶在选自以下的一个或更多个位置处包含至少一个取代或取代集:15/447/569/775/783/784、82/242/569、82/450/567/569、313、314/447/569/783/784、537/667、567/569/667和569和/或其任何组合,其中氨基酸位置参考SEQ ID NO:824编号。在一些实施方案中,至少一个取代或取代集选自15W/447V/569T/775F/783Q/784E、82Q/242L/569L、82Q/450V/567G/569G、313F、314V/447V/569T/783Q/784E、537K/667N、567G/569G/667N和569T,其中氨基酸位置参考SEQ ID NO:824编号。在一些另外的实施方案中,至少一个取代或取代集选自D15W/I447V/I569T/K775F/L783Q/K784E、V82Q/V242L/I569L、V82Q/I450V/P567G/I569G、E313F、T314V/I447V/I569T/L783Q/K784E、M537K/Y667N、P567G/I569G/Y667N和I569T,其中氨基酸位置参考SEQ ID NO:824编号。
本发明还提供了工程化DNA聚合酶,其中该工程化DNA聚合酶包含与表3.1、表3.2、表3.3、表3.4、表3.5、表3.6、表3.7、表3.8、表3.9、表4.1、表4.2、表4.3、表4.4、表4.5、表6.2和/或表6.3中列出的至少一种工程化DNA聚合酶变体的序列至少85%、90%、91%、92%、93%、94%、95%、96%、97%、98%、99%或更多相同的多肽序列。在一些实施方案中,工程化DNA聚合酶具有DNA聚合酶活性。在一些实施方案中,与野生型DNA聚合酶相比,工程化DNA聚合酶具有至少一种改进的性质。在一些实施方案中,野生型DNA聚合酶选自来自强烈火球菌(Pyrococcus furiosus)的Pfu DNA聚合酶、来自嗜热球菌属物种(Thermococcus sp.)菌株2319x1的B组DNA聚合酶以及来自水生栖热菌(Thermus aquaticus)的Taq DNA聚合酶。在一些实施方案中,与野生型DNA聚合酶相比,工程化DNA聚合酶具有至少一种改进的性质,其中改进的性质选自在聚合酶链式反应中产生增加的产物、更高的保真度和更高的热稳定性。在一些实施方案中,工程化DNA聚合酶在聚合酶链式反应中比野生型DNA聚合酶产生更高的产物产量。在一些实施方案中,野生型DNA聚合酶选自来自强烈火球菌的Pfu DNA聚合酶、来自嗜热球菌属物种菌株2319x1的B组DNA聚合酶以及来自水生栖热菌的Taq DNA聚合酶。在一些另外的实施方案中,工程化DNA聚合酶显示出比野生型DNA聚合酶更高的保真度。在一些实施方案中,野生型DNA聚合酶选自来自强烈火球菌的Pfu DNA聚合酶、来自嗜热球菌属物种菌株2319x1的B组DNA聚合酶以及来自水生栖热菌的Taq DNA聚合酶。在又一些另外的实施方案中,工程化DNA聚合酶显示出比野生型DNA聚合酶更高的热稳定性。在一些另外的实施方案中,野生型DNA聚合酶选自来自强烈火球菌的Pfu DNA聚合酶、来自嗜热球菌属物种菌株2319x1的B组DNA聚合酶以及来自水生栖热菌的Taq DNA聚合酶。在又一些另外的实施方案中,工程化DNA聚合酶是纯化的。
本发明还提供了编码本文提供的工程化DNA聚合酶的多核苷酸序列。在一些实施方案中,多核苷酸序列编码至少一种本文提供的工程化DNA聚合酶。在一些另外的实施方案中,多核苷酸序列包含与参考序列SEQ ID NO:1、5、21、23、25、27和/或823和/或其功能片段的至少85%、90%、91%、92%、93%、94%、95%、96%、97%、98%、99%或更多的序列同一性,其中该工程化多肽在一个或更多个氨基酸位置处包含至少一个取代。在一些另外的实施方案中,多核苷酸序列编码至少一种工程化DNA聚合酶,该工程化DNA聚合酶包含与参考序列SEQ ID NO:2、6、22、24、26、28和/或824具有至少85%、90%、91%、92%、93%、94%、95%、96%、97%、98%、99%或更多的序列同一性的序列。在一些另外的实施方案中,多核苷酸序列包括SEQ ID NO:1、5、21、23、25、27和/或823。在一些另外的实施方案中,多核苷酸序列可操作地连接到控制序列。在又一些另外的实施方案中,多核苷酸序列是密码子优化的。
本发明还提供了表达载体,所述表达载体包含至少一种本文提供的多核苷酸序列。本发明还提供了转化有本文提供的至少一种表达载体的宿主细胞。
本发明还提供了在宿主细胞中产生工程化DNA聚合酶的方法,所述方法包括在合适的培养条件下培养本文提供的宿主细胞,从而产生至少一种工程化DNA聚合酶。在一些实施方案中,方法包括从培养物和/或宿主细胞中回收至少一种工程化DNA聚合酶。在一些另外的实施方案中,方法还包括纯化至少一种工程化DNA聚合酶的步骤。本发明还提供了组合物,该组合物包含本文提供的至少一种工程化DNA聚合酶。
本发明还提供了用于确定DNA聚合酶保真度的高通量测定系统。本发明还提供了用于高通量确定DNA聚合酶保真度的方法,所述方法包括:i)提供:至少一种DNA聚合酶;报告质粒,所述报告质粒包含编码第一报告蛋白和第二报告蛋白以及选择标记的基因;扩增系统,所述扩增系统包括热循环仪和用于进行聚合酶链式反应的试剂;和纯化系统;转化系统,所述转化系统包括感受态宿主细胞;和流式细胞仪;ii)在使得报告构建体被DNA聚合酶扩增以产生PCR产物的条件下,使DNA聚合酶和报告质粒暴露于扩增系统;iii)使PCR扩增子环化以提供环化的PCR扩增子;vi)使用转化系统转化PCR扩增子以产生转化的细胞;和vii)使用流式细胞仪分析转化的细胞;和viii)确定DNA聚合酶的保真度。在一些实施方案中,方法包括本文提供的(例如,如任何实施例和表格中提供的)至少一种DNA聚合酶。在一些实施方案中,方法还包括诱导转化的细胞的步骤。在一些另外的实施方案中,第一报告蛋白包括绿色荧光蛋白。在又一些另外的实施方案中,第二报告蛋白包括dsRed。在又另外的实施方案中,选择标记包括氯霉素乙酰转移酶。在一些另外的实施方案中,PCR扩增子的环化使用至少一种连接酶进行。在一些实施方案中,PCR扩增子是纯化的。在一些另外的实施方案中,方法还包括确定与参考DNA聚合酶相比聚合酶保真度的倍数改进。在一些实施方案中,参考DNA聚合酶是野生型聚合酶。在一些另外的实施方案中,野生型聚合酶选自来自强烈火球菌的Pfu DNA聚合酶、来自嗜热球菌属物种菌株2319x1的B组DNA聚合酶以及来自水生栖热菌的Taq DNA聚合酶。在一些实施方案中,每种变体的相对错误率通过将变体的第一荧光蛋白(例如,仅绿色)频率除以亲本对照的频率来计算。在一些另外的实施方案中,报告了聚合酶保真度的倍数改进,并确定了相对错误率。
附图说明
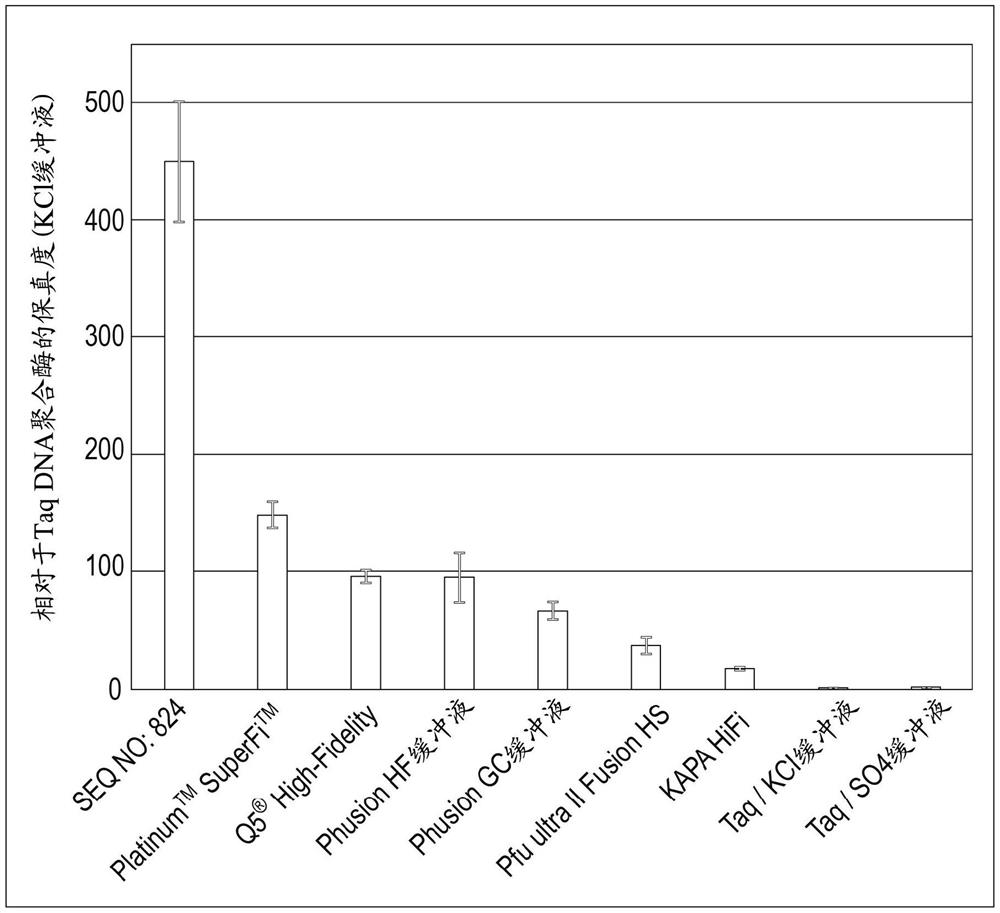
图1提供了显示如实施例5所述测试的聚合酶的相对错误率的图。
图2提供了显示具有低GC含量的生物体(表皮葡萄球菌(Staphylococcusepidermidis),32%GC)的微生物全基因组重测序的覆盖均匀性的图。归一化的覆盖绘制为每个基因组的GC含量的函数。归一化的覆盖的理论理想值绘制为虚线(1.0)。
图3提供了显示具有高GC含量的生物体(类球红细菌(Rhodobactersphaeroides),69%GC)的微生物全基因组重测序的覆盖均匀性的图。归一化的覆盖绘制为每个基因组的GC含量的函数。归一化的覆盖的理论理想值绘制为虚线(1.0)。
发明描述
本发明提供了工程化DNA聚合酶多肽及其组合物、以及编码工程化DNA聚合酶多肽的多核苷酸。本发明还提供了使用包含工程化DNA聚合酶多肽的组合物用于诊断和其他目的的方法。在一些实施方案中,工程化DNA聚合酶多肽是优化的,以提供增强的聚合活性与高复制保真度,特别是在涉及低浓度DNA输入、高通量分析和/或测序反应的条件下提供增强的聚合活性与高复制保真度。在一些实施方案中,本发明提供了用于诊断和研究目的的包含工程化DNA聚合酶的方法和组合物。本发明还提供了工程化DNA聚合酶多肽、突变体、生物活性片段及其类似物、以及包含它们的组合物。
在一些实施方案中,本发明的工程化DNA聚合酶可用于使用来自患者样品的少量DNA的诊断和研究应用,所述少量DNA包括无细胞DNA、循环肿瘤DNA、从循环肿瘤细胞分离的DNA、循环胎儿DNA、从病毒感染的细胞分离的DNA、细针抽吸物,或通过FACS(荧光激活细胞分选)、激光捕获显微术或微流体装置分离的单细胞。然而,并不意图本发明使用的样品限于任何特定的样品类型,因为任何合适的样品,包括那些具有低DNA浓度的样品,可用于本发明。
在一些实施方案中,本发明的工程化DNA聚合酶可用于构建中等至高浓度DNA样品的DNA测序文库。
在一些实施方案中,本发明的工程化DNA聚合酶可用于分子克隆应用,特别是那些与天然存在的酶的Km相比DNA浓度低的分子克隆应用。在一些实施方案中,这适用于其中样品以小体积制备的高通量克隆应用,或任何低浓度的DNA样品,诸如环境样品、患者样品或古DNA(ancient DNA)。
在一些实施方案中,本发明的工程化DNA聚合酶可用于简化的分子生物学工作流程,包括自动化工作流程,其去除了操作之间的清理步骤。因为工程化DNA聚合酶对低浓度底物有活性,所以可以将更小体积(或稀释)的含有抑制剂的底物样品添加到连接反应。相关的含抑制剂的DNA样品可以包括PCR缓冲液中的DNA、电泳缓冲液中的DNA或粗提物中的DNA。与天然的DNA聚合酶相比,本发明的工程化DNA聚合酶能够有效地连接稀释的样品。可选地,在其他实施方案中,本发明的工程化DNA聚合酶可用于含有一种或更多种抑制剂的未稀释样品。
在一些实施方案中,本发明的工程化DNA聚合酶可用于在微流体液滴或孔板中进行的一锅多酶反应(single-pot multi-enzyme reactions)。DNA聚合酶的高比活性允许为反应中其他酶的性能选择缓冲剂配方,这实现了对整个工作流程没有限制的连接性能。
在一些实施方案中,本发明的工程化DNA聚合酶可用于构建DNA文库。这些文库可用于DNA测序、高通量筛选、遗传选择、噬菌体展示、酵母展示、核糖体展示、基于细胞的测定、生物化学测定或基于成像的高内涵筛选(imaging-based high-content screening)。在一些实施方案中,当在使用野生型DNA聚合酶时文库大小、多样性或保真度受到连接底物浓度的限制时,本发明的工程化DNA聚合酶特别有用。
除非另外定义,否则本文使用的所有技术和科学术语通常具有与本发明所属领域普通技术人员通常理解的相同的含义。通常,本文使用的命名法和下文描述的细胞培养、分子遗传学、微生物学、有机化学、分析化学和核酸化学的实验室程序是本领域中熟知的并且普遍地采用的那些。这样的技术是熟知的,并且在本领域技术人员熟知的许多教科书和参考著作中进行了描述。对于化学合成和化学分析,使用了标准技术或其修改形式。
本文(上文和下文两者)提及的所有专利、专利申请、文章和出版物,在此通过引用明确地并入本文。
尽管本发明的实践中可使用类似于或等同于本文描述的那些方法和材料的任何合适的方法和材料,本文描述了一些方法和材料。应理解本发明不限于所描述的特定方法、方案和试剂,因为这些可以根据本领域技术人员使用其的情况而改变。因此,下文即将定义的术语通过参考本申请作为整体而被更充分地描述。本文(上文和下文两者)提及的所有专利、专利申请、文章和出版物,在此通过引用明确地并入本文。
除非上下文另外清楚地指示,否则如本文使用的单数“一((a)”、“一(an)”和“该(the)”包括复数指示物。
数值范围包括限定该范围的数字。因此,本文公开的每个数值范围意图包括落在这样的较宽数值范围内的每一较窄数值范围,如同这样的较窄数值范围在本文被全部明确地写出。还意图本文公开的每个最大(或最小)的数值限制包含每个较低(或较高)的数值限制,如同这样的较低(或较高)的数值限制在本文中被明确地写出。
术语“约”意指特定值的可接受误差。在一些实例中,“约”意指给定值范围的0.05%、0.5%、1.0%或2.0%内。在一些实例中,“约”意指给定值的1个、2个、3个或4个标准差内。
此外,本文提供的标题不是本发明的各个方面或实施方案的限制,本发明的各个方面或实施方案可以通过参考作为整体的本申请而获得。因此,下文即将定义的术语通过参考本申请作为整体而被更充分地定义。然而,为了促进对本发明的理解,许多术语在下文中被定义。
除非另外指示,否则分别地,核酸以5'至3'方向从左至右书写;氨基酸序列以氨基至羧基方向从左至右书写。
如本文使用的,术语“包括/包含(comprising)”及其同根词以其包含性意义被使用(即,等同于术语“包括/包含(including)”及其相应的同根词)。
如本文使用的,“EC”编号是指生物化学和分子生物学国际联合命名委员会(Nomenclature Committee of the International Union of Biochemistry andMolecular Biology,NC-IUBMB)的酶命名法。该IUBMB生物化学分类是基于酶催化的化学反应的酶的数字分类系统。
如本文使用的,“ATCC”是指美国典型培养物保藏中心((American Type CultureCollection),其生物保藏收集物包括基因和菌株。
如本文使用的,“NCBI”是指美国国家生物技术信息中心(National Center forBiological Information)和其中提供的序列数据库。
如本文使用的,术语“DNA”指脱氧核糖核酸。
如本文使用的,术语“RNA”指核糖核酸。
如本文使用的,术语“融合蛋白”和“嵌合蛋白”以及“嵌合体”是指通过连接最初编码单独蛋白的两个或更多个基因而产生的杂合蛋白。在一些实施方案中,融合蛋白通过重组技术(例如,本领域已知的分子生物学技术)产生。
如本文使用的,术语“聚合酶”是指使核苷三磷酸聚合的一类酶。聚合酶使用模板核酸链来合成互补核酸链。模板链和合成的核酸链可以独立地是DNA或RNA。本领域已知的聚合酶包括但不限于DNA聚合酶(例如,大肠杆菌DNA polI、水生栖热菌(T.aquaticus)DNA聚合酶[Taq]、DNA依赖性RNA聚合酶,以及逆转录酶)。如本文使用的,聚合酶是含有足够的氨基酸来发挥聚合酶的期望酶功能的多肽或蛋白质。在一些实施方案中,聚合酶不包含天然酶中发现的所有氨基酸,而仅包含足以允许聚合酶发挥期望催化活性的氨基酸,包括但不限于发挥5’-3’聚合、5’-3’核酸外切酶和3’-5’核酸外切酶活性的氨基酸。
如本文使用的,术语“DNA聚合酶活性”、“合成活性”和“聚合酶活性”在本文中可互换使用,并且是指酶通过掺入脱氧核苷三磷酸来合成新DNA链的能力。
如本文使用的,术语“双链体”和“ds”是指双链核酸(例如DNA)分子,其由两个单链多核苷酸组成,这两个单链多核苷酸的序列互补(A与T配对,C与G配对),以反向平行的5’至3’方向排列,并通过核碱基(即腺嘌呤[A]、鸟嘌呤[G]、胞嘧啶[C]和胸腺嘧啶[T])之间的氢键保持在一起。
如本文使用的,术语“平的(blunt)”是指不具有5’或3’突出端的具有自身互补性(self-complementarity)的DNA双链体或单链(“ss”)DNA的末端。平末端可以在一条或两条链上具有5’磷酸,这使得它们可以通过连接酶诸如T4 DNA连接酶进行连接。
如本文使用的,术语“末端修复”是指修复DNA(例如,片段化的或受损的DNA,或与其他DNA分子不相容的DNA分子)的方法。在一些实施方案中,方法包括两个功能:1)通过酶诸如T4 DNA聚合酶和/或Klenow片段将具有突出端的双链DNA转化为不具有突出端的双链DNA;和2)通过酶诸如多核苷酸激酶将磷酸基团添加到DNA(单链或双链)的5’末端。
“蛋白质”、“多肽”和“肽”在本文可互换使用,以表示无论长度或翻译后修饰(例如,糖基化或磷酸化)如何,通过酰胺键共价连接的至少两个氨基酸的聚合物。
“氨基酸”通过其普遍已知的三字母符号或通过IUPAC-IUB生物化学命名委员会推荐的单字母符号在本文被提及。同样地,核苷酸可以通过其普遍接受的单字母代码被提及。用于遗传编码的氨基酸的缩写是常规的并且如下:丙氨酸(Ala或A)、精氨酸(Arg或R)、天冬酰胺(Asn或N)、天冬氨酸(Asp或D)、半胱氨酸(Cys或C)、谷氨酸(Glu或E)、谷氨酰胺(Gln或Q)、组氨酸(His或H)、异亮氨酸(I1e或I)、亮氨酸((Leu或L)、赖氨酸(Lys或K)、甲硫氨酸((Met或M)、苯丙氨酸(Phe或F)、脯氨酸(Pro或P)、丝氨酸(Ser或S)、苏氨酸(Thr或T)、色氨酸(Trp或W)、酪氨酸(Tyr或Y)和缬氨酸(Val或V)。当使用三字母缩写时,除非前面明确有“L”或“D”,或者从使用缩写的上下文清楚看出,否则氨基酸可以关于α-碳(C
用于遗传编码核苷的缩写是常规的并且如下:腺苷(A);鸟苷(G);胞苷(C);胸苷(T);和尿苷(U)。除非具体阐明,否则缩写的核苷可以是核糖核苷或2’-脱氧核糖核苷。核苷可以基于个体或基于集合体(aggregate)被指定为核糖核苷或2’-脱氧核糖核苷。当核酸序列以单字母缩写的串呈现时,根据常规惯例使序列以5’至3’方向呈现,并且不示出磷酸。
当提及细胞、多核苷酸或多肽使用时,术语“工程化”、“重组”、“非天然存在的”和“变体”指如下材料或与该材料的天然或自然形式对应的材料:已经以自然界中本来不存在的方式被修饰或与其相同但由合成材料和/或通过使用重组技术操纵来产生或获得。
如本文使用的,“野生型”和“天然存在的”是指在自然界中发现的形式。例如野生型多肽或多核苷酸序列是生物体中存在的序列,其可以从自然界中的来源分离并且未通过人为操纵被有意地修饰。
如本文使用的,“编码序列”是指编码蛋白质的氨基酸序列的核酸的那部分(例如,基因)。
如本文使用的,术语“序列同一性百分比(%)”是指多核苷酸和多肽之间的比较,并且通过在比较窗上比较两条最佳比对的序列来确定,其中为了两个序列的最佳比对,多核苷酸或多肽序列在比较窗中的部分与参考序列相比可以包含添加或缺失(即,空位)。百分比可以如下计算:确定两个序列中出现相同的核酸碱基或氨基酸残基的位置的数目以得到匹配位置的数目,将匹配位置的数目除以比较窗中位置的总数目,并且将结果乘以100以得到序列同一性百分比。可选择地,百分比可以如下计算:确定两个序列中出现相同的核酸碱基或氨基酸残基的位置的数目或者核酸碱基或氨基酸残基与空位对齐的位置的数目以得到匹配位置的数目,将匹配位置的数目除以比较窗中位置的总数目,并且将结果乘以100以得到序列同一性百分比。本领域技术人员理解,存在许多可用于比对两个序列的已建立的算法。用于比较的序列的最佳比对可以通过以下来进行,例如,通过Smith和Waterman的局部同源性算法(Smith和Waterman,Adv.Appl.Math.,2:482[1981]),通过Needleman和Wunsch的同源性比对算法(Needleman和Wunsch,J.Mol.Biol.,48:443[1970]),通过Pearson和Lipman的相似性搜索方法(Pearson和Lipman,Proc.Natl.Acad.Sci.USA 85:2444[1988]),通过这些算法的计算机实现(例如,GCG Wisconsin软件包中的GAP、BESTFIT、FASTA和TFASTA),或者通过目视检查,如本领域已知的。适合用于确定序列同一性百分比和序列相似性的算法的实例包括但不限于BLAST和BLAST 2.0算法(参见例如,Altschul等人,J.Mol.Biol.,215:403-410[1990];和Altschul等人,Nuclcic Acids Res.,3389-3402[1977])。用于进行BLAST分析的软件是公众可通过美国国家生物技术信息中心网站可获得的。该算法包括首先通过鉴定查询序列中长度“W”的短字来鉴定高评分序列对(HSP),所述短字当与数据库序列中相同长度的字比对时匹配或满足某一正值的阈值评分“T”。T被称为邻近字评分阈值(参见,Altschul等人,上文)。这些最初的邻近字击中((word hit)充当用于启动搜索的种子以找到更长的包含它们的HSP。然后字击中沿着每个序列的两个方向延伸直到累积比对评分不能增加。对于核苷酸序列,累积评分使用参数“M”(用于匹配残基对的奖励评分;总是>0)和“N”(用于错配残基的惩罚评分;总是<0)计算。对于氨基酸序列,评分矩阵用于计算累积评分。在以下情况,字击中在每一个方向的延伸停止:累积比对评分从其最大达到值下降了量“X”;由于累积一个或更多个负评分残基比对,累积评分达到0或低于0;或到达任一序列的末端。BLAST算法参数W、T和X决定比对的灵敏性和速度。BLASTN程序(对于核苷酸序列)使用以下作为默认值:11的字长(W)、10的期望值(E)、M=5、N=-4以及两条链的比较。对于氨基酸序列,BLASTP程序使用以下作为默认值:3的字长(W),10的期望值(E)和BLOSUM62评分矩阵(参见例如,Henikoff和Henikoff,Proc.Natl.Acad.Sci.USA89:10915[1989])。序列比对和序列同一性%的示例性确定可以使用GCG Wisconsin软件包(Accelrys,Madison WI)中的BESTFIT或GAP程序,使用提供的默认参数。
如本文使用的,“参考序列”是指用作序列比较的基础的已定义序列。参考序列可以是较大序列的子集,例如,全长基因或多肽序列的区段。通常,参考序列为至少20个核苷酸或氨基酸残基的长度、至少25个残基的长度、至少50个残基的长度、至少100个残基的长度,或者核酸或多肽的全长。由于两个多核苷酸或多肽可以各自(1)包含两个序列之间相似的序列(即,完整序列的一部分),并且(2)还可以包含两个序列之间不同的序列,因此两个(或更多个)多核苷酸或多肽之间的序列比较通常通过比较两个多核苷酸或多肽在“比较窗”上的序列来鉴定和比较有序列相似性的局部区域来进行。在一些实施方案中,“参考序列”可以基于一级氨基酸序列,其中参考序列是可以在一级序列中具有一个或更多个变化的序列。例如,短语“基于SEQ ID NO:6的参考序列,在对应于X712的残基处具有缬氨酸”(或“基于SEQ ID NO:6的参考序列,在对应于位置712的残基处具有缬氨酸”)是指这样的参考序列,其中在SEQ ID NO:6中的位置X172处的对应残基(例如,异亮氨酸)已经被改变为缬氨酸。
如本文使用的,“比较窗”是指至少约20个连续核苷酸位置或氨基酸残基的概念区段,其中序列可以与至少20个连续核苷酸或氨基酸的参考序列进行比较,并且其中与参考序列(其不包含添加或缺失)相比,为了两个序列的最佳比对,序列在比较窗中的部分可以包含20%或更少的添加或缺失(即,空位)。比较窗可以比20个连续残基更长,并且任选地包括30、40、50、100或更长的窗。
如本文使用的,当在对给定氨基酸或多核苷酸序列进行编号的情况中使用时,“对应于”、“参考于”和“相对于”是指当给定氨基酸或多核苷酸序列与参考序列相比较时对指定参考序列的残基进行编号。换言之,给定聚合物的残基数目或残基位置关于参考序列被指定,而不是通过给定氨基酸或多核苷酸序列内残基的实际数字位置被指定。例如,给定的氨基酸序列,诸如工程化DNA聚合酶的氨基酸序列可以通过引入空位以与参考序列对齐从而优化两个序列之间的残基匹配。在这些情况下,尽管存在空位,对给定氨基酸或多核苷酸序列中的残基关于与其比对的参考序列进行编号。在一些实施方案中,序列被加标签(例如,使用组氨酸标签)。
如本文使用的,“突变”是指核酸序列的改变。在一些实施方案中,突变导致编码的多肽序列的改变(即,与不具有突变的原始序列相比)。在一些实施方案中,突变包括取代,从而产生不同的氨基酸(例如,用色氨酸取代天冬氨酸)。在一些替代实施方案中,突变包括添加,使得氨基酸被添加到原始多肽序列中。在一些另外的实施方案中,突变包括缺失,使得氨基酸从原始多肽序列中缺失。给定序列中可能存在任何数量的突变。
如本文使用的,“氨基酸差异”和“残基差异”是指在多肽序列的一个位置处的氨基酸残基相对于参考序列中对应位置处的氨基酸残基的差异。氨基酸差异的位置通常在本文中被称为“Xn”,其中n是指残基差异所基于的参考序列中的对应位置。例如,“与SEQ ID NO:824相比在位置X15处的残基差异”(或“与SEQ ID NO:824相比在位置15处的残基差异”)是指在对应于SEQ ID NO:824的位置15的多肽位置处的氨基酸残基的差异。因此,如果参考多肽SEQ ID NO:824在位置15处具有天冬氨酸,则“与SEQ ID NO:824相比在位置X15处的残基差异”是指在对应于SEQ ID NO:824的位置15的多肽位置处除了天冬氨酸以外的任何残基的氨基酸取代。在本文的大多数情况下,在一个位置处的特定氨基酸残基差异被指示为“XnY”,其中“Xn”指定(如上文描述的)参考多肽的对应残基和位置,并且“Y”是在工程化多肽中发现的氨基酸(即,与参考多肽中不同的残基)的单字母标识符。在一些情况下(例如,实施例中的表格中),本公开内容还提供由常规符号“AnB”表示的特定氨基酸差异,其中A是参考序列中的残基的单字母标识符,“n”是在参考序列中的残基位置的编号,并且B是工程化多肽的序列中残基取代的单字母标识符。在一些情况下,本公开内容的多肽相对于参考序列可以包含一个或更多个氨基酸残基差异,其由相对于参考序列存在残基差异的一列指定位置指示。在一些实施方案中,在多于一个氨基酸可以在多肽的特定残基位置中使用的情况下,可以使用的各种氨基酸残基由“/”分开(例如,X775F/X775G、X775F/G或K775F/G)。本公开内容包括含一个或更多个氨基酸差异的工程化多肽序列,该一个或更多个氨基酸差异包括保守和非保守的氨基酸取代的任一者/或两者、以及序列中氨基酸的插入和缺失(例如,在位置784处的缺失)。
如本文使用的,术语“氨基酸取代集”和“取代集”是指多肽序列中的一组氨基酸取代。在一些实施方案中,取代集包括1个、2个、3个、4个、5个、6个、7个、8个、9个、10个、11个、12个、13个、14个、15个或更多个氨基酸取代。在一些实施方案中,取代集是指在实施例中任一表格中列出的任一变体DNA聚合酶多肽中存在的氨基酸取代的集合。在这些取代集中,个体取代用分号(“;”;例如,P567G;I569G;Y667N)或斜线(“/”;例如,P567G/I569G/Y667N)分隔开。在一些实施方案中,“取代”包括氨基酸的缺失。
如本文使用的,“保守氨基酸取代”是指用具有相似侧链的不同残基来取代残基,并且因此通常包括用相同或相似的氨基酸定义类别中的氨基酸取代多肽中的氨基酸。例如但不限于,具有脂肪族侧链的氨基酸可以被另一种脂肪族氨基酸(例如,丙氨酸、缬氨酸、亮氨酸和异亮氨酸)取代;具有羟基侧链的氨基酸被另一种具有羟基侧链的氨基酸(例如,丝氨酸和苏氨酸)取代;具有芳族侧链的氨基酸被另一种具有芳族侧链的氨基酸(例如,苯丙氨酸、酪氨酸、色氨酸和组氨酸)取代;具有碱性侧链的氨基酸被另一种具有碱性侧链的氨基酸(例如,赖氨酸和精氨酸)取代;具有酸性侧链的氨基酸被另一种具有酸性侧链的氨基酸(例如,天冬氨酸或谷氨酸)取代;和疏水性氨基酸或亲水性氨基酸分别被另一种疏水性氨基酸或亲水性氨基酸取代。
如本文使用的,“非保守取代”是指用具有显著不同的侧链性质的氨基酸取代多肽中的氨基酸。非保守取代可以使用定义的组之间而不是定义的组之内的氨基酸,并且影响:(a)取代区域中的肽骨架的结构(例如,用脯氨酸取代甘氨酸);(b)电荷或疏水性,和/或(c)侧链体积。例如但不限于,示例性非保守取代包括用碱性氨基酸或脂肪族氨基酸取代酸性氨基酸;用小氨基酸取代芳族氨基酸;和用疏水性氨基酸取代亲水性氨基酸。
如本文使用的,“缺失”是指通过从参考多肽去除一个或更多个氨基酸对多肽进行的修饰。缺失可以包括去除1个或更多个氨基酸、2个或更多个氨基酸、5个或更多个氨基酸、10个或更多个氨基酸、15个或更多个氨基酸或者20个或更多个氨基酸、多达组成参考酶的氨基酸总数的10%或者多达组成参考酶的氨基酸总数的20%,同时保留酶活性和/或保留工程化聚合酶的改进的性质。缺失可以涉及多肽的内部部分和/或末端部分。在各种实施方案中,缺失可以包括连续的区段或可以是不连续的。缺失用“-”表示,并且可能存在于取代集中。
如本文使用的,“插入”是指通过将一个或更多个氨基酸添加到参考多肽对多肽进行的修饰。插入可以处于多肽的内部部分或到羧基或氨基末端。如本文使用的插入包括本领域已知的融合蛋白。插入可以是氨基酸的连续区段或被天然存在的多肽中的一个或更多个氨基酸分开。
如本文使用的,“功能片段”和“生物活性片段”在本文可互换使用,是指如下多肽:所述多肽具有一个或更多个氨基末端缺失和/或羧基末端缺失和/或内部缺失,但其中剩余的氨基酸序列与和它进行比较的序列(例如,本发明的全长工程化DNA聚合酶)中的对应位置相同,并且保留全长多肽的基本上全部活性。
如本文使用的,“分离的多肽”是指与其天然伴随的其他污染物(例如,蛋白质、脂质和多核苷酸)基本上分开的多肽。该术语包括已经从它们天然存在的环境或表达系统(例如,宿主细胞或体外合成)中取出或纯化的多肽。重组DNA聚合酶多肽可以存在于细胞内、存在于细胞培养基中,或以各种形式(诸如裂解物或分离的制品)制备。因此,在一些实施方案中,本文提供的重组DNA聚合酶多肽是分离的多肽。
如本文使用的,“基本上纯的多肽”是指如下组合物,在所述组合物中多肽物质是存在的主要物质的组合物(即,在摩尔或重量基础上,多肽物质比在该组合物中的任何其他单独的大分子物质更丰富),并且当目标物质构成存在的大分子物质的按摩尔或%重量计至少约50%时,通常为基本上纯的组合物。通常,基本上纯的DNA聚合酶组合物构成组合物中存在的所有大分子物质的按摩尔或%重量计约60%或更多、约70%或更多、约80%或更多、约90%或更多、约95%或更多和约98%或更多。在一些实施方案中,将目标物质纯化至基本同质(即,通过常规检测方法不能在组合物中检测出污染物物质),其中该组合物基本上由单一大分子物质组成。溶剂物质、小分子(<500道尔顿)和元素离子物质不被认为是大分子物质。在一些实施方案中,分离的重组DNA聚合酶多肽是基本上纯的多肽组合物。
如本文使用的,“改进的酶性质”是指与参考DNA聚合酶多肽诸如野生型DNA聚合酶多肽(例如SEQ ID NO:2的野生型DNA聚合酶)相比表现出任何酶性质的改进的工程化DNA聚合酶多肽。改进的性质包括但不限于诸如以下的性质:增加的蛋白质表达、增加的热活性(thermoactivity)、增加的热稳定性、增加的稳定性、增加的酶活性、增加的底物特异性和/或亲和力、增加的比活性、增加的对底物和/或终产物抑制的耐受性、增加的化学稳定性、改进的化学选择性、改进的溶剂稳定性、增加的对酸性pH的耐受性、增加的对蛋白水解活性的耐受性(即,降低的对蛋白水解的敏感性)、增加的溶解度和改变的温度谱(temperatureprofile)。
如本文使用的,“增加的酶活性”和“增强的催化活性”是指工程化DNA聚合酶多肽的改进的性质,其可以被表示为与参考DNA聚合酶(例如,野生型DNA聚合酶和/或另一种工程化DNA聚合酶)相比,比活性(例如,产生的产物/时间/重量蛋白质)的增加和/或底物向产物转化的转化百分比(例如,在指定的时间段使用指定量的DNA聚合酶,起始量的底物向产物转化的转化百分比)的增加。确定酶活性的示例性方法被提供在实施例中。与酶活性相关的任何性质可能受到影响,包括经典酶性质K
术语“蛋白水解活性”和“蛋白水解”在本文中可互换使用,是指将蛋白质分解成更小的多肽或氨基酸。蛋白质的分解通常是蛋白酶(protease)(蛋白酶(proteinase))水解肽键的结果。蛋白酶包括但不限于胃蛋白酶、胰蛋白酶、糜蛋白酶、弹性蛋白酶;羧肽酶A和B,以及肽酶(例如,氨基肽酶、二肽酶和肠肽酶)。
短语“降低对蛋白水解的敏感性”和“降低蛋白水解敏感性”在本文中可互换使用,意指在用一种或更多种蛋白酶处理后,根据本发明的工程化DNA聚合酶多肽与参考DNA聚合酶相比在标准测定(例如,如实施例中所公开的)中具有更高的酶活性。
如本文使用的,“转化”指一种或更多种底物向一种或更多种对应的产物的酶促转化(或生物转化)。“转化百分比”是指在指定条件下在一定时间段内被转化为产物的底物的百分比。因此,DNA聚合酶多肽的“酶活性”或“活性”可以表示为在指定的时间段内底物向产物转化的“转化百分比”。
如本文使用的,“杂交严格性”涉及核酸杂交中的杂交条件,诸如洗涤条件。通常,杂交反应在较低严格性的条件下进行,随后是不同的但较高严格性的洗涤。术语“中度严格杂交”是指允许靶DNA结合以下互补核酸的条件:所述互补核酸与靶DNA具有约60%同一性,优选地约75%同一性,约85%同一性,与靶多核苷酸具有大于约90%同一性。示例性中度严格条件是等同于在42℃于50%甲酰胺、5×Denhart溶液、5×SSPE、0.2%SDS中杂交,随后在42℃于0.2×SSPE、0.2%SDS中洗涤的条件。“高严格性杂交”通常是指与定义的多核苷酸序列在溶液条件下确定的热解链温度T
如本文使用的,“密码子优化的”是指将编码蛋白质的多核苷酸的密码子改变为特定生物体中优先使用的那些密码子,使得所编码的蛋白质在该生物体中被更有效地表达。尽管遗传密码是简并的,即大多数氨基酸由被称为“同义(synonyms)”或“同义(synonymous)”密码子的若干个密码子表示,但熟知的是,特定生物体的密码子使用是非随机的并且对于特定的密码子三联体是有偏倚的。就给定的基因、具有共同功能或祖先起源的基因、高度表达的蛋白质对比低拷贝数蛋白质以及生物体基因组的聚集蛋白质编码区域而言,这种密码子使用偏倚可能更高。在一些实施方案中,编码DNA聚合酶的多核苷酸是密码子优化的,用于从选择用于表达的宿主生物体的最佳产生。
如本文使用的,“控制序列”在本文中是指包括对本公开内容的多核苷酸和/或多肽的表达必要或有利的所有组分。每一个控制序列对于编码多肽的核酸序列可以是自然的或外来的。这样的控制序列包括,但不限于,前导序列、多腺苷酸化序列、前肽序列、启动子序列、信号肽序列、起始序列和转录终止子。在最小程度上,控制序列包括启动子和转录及翻译终止信号。在一些实施方案中,控制序列与接头一起被提供,以用于引入促进控制序列与编码多肽的核酸序列的编码区域的连接的特定限制性位点的目的。
“可操作地连接”在本文被定义为这样的配置,其中控制序列被适当地放置(即,以功能关系)在相对于感兴趣的多核苷酸的一定位置处,使得控制序列指导或调节编码感兴趣的多肽的多核苷酸的表达。
如本文使用的,“启动子序列”是指被宿主细胞识别用于感兴趣的多核苷酸诸如编码序列的表达的核酸序列。启动子序列包含介导感兴趣的多核苷酸的表达的转录控制序列。启动子可以是在选择的宿主细胞中显示出转录活性的任何核酸序列,包括突变、截短的和杂合启动子,并且可以从编码与宿主细胞同源或异源的细胞外或细胞内多肽的基因获得。
如本文使用的,“合适的反应条件”是指在酶促转化反应溶液中的那些条件(例如,酶载量(loading)、底物载量、温度、pH、缓冲液、助溶剂等的范围),在上述条件下本公开内容的DNA聚合酶多肽能够将底物转化为期望的产物化合物。示例性的“合适的反应条件”在本文提供(参见实施例)。
如本文使用的,“载量”,诸如在“化合物载量”或“酶载量”中,是指在反应起始时组分在反应混合物中的浓度或量。在酶促转化反应过程的情况下,“底物”是指由DNA聚合酶多肽作用的化合物或分子。
如本文使用的,在酶促转化过程的情况下,“产物”是指由DNA聚合酶多肽对底物的作用产生的化合物或分子。
如本文使用的,“培养”是指微生物细胞群体在合适的条件下使用任何合适的培养基(例如,液体、凝胶或固体培养基)的生长。
重组多肽(例如DNA聚合酶变体)可以使用本领域已知的任何合适的方法产生。例如,存在本领域技术人员熟知的许多种不同的诱变技术。此外,诱变试剂盒也可从许多商业分子生物学供应商获得。在定义的氨基酸处(定点)产生特定取代、在基因的局部区域中(区域特异性)产生特定或随机突变,或在整个基因内产生随机诱变(例如,饱和诱变)的方法是可获得的。本领域技术人员已知许多合适的方法来产生酶变体,包括但不限于使用PCR对单链DNA或双链DNA进行的定点诱变、盒式诱变、基因合成、易错PCR、重排和化学饱和诱变,或本领域已知的任何其他合适的方法。用于DNA和蛋白质工程化的方法的非限制性实例在以下专利中提供:美国专利第6,117,679号;美国专利第6,420,175号;美国专利第6,376,246号;美国专利第6,586,182号;美国专利第7,747,391号;美国专利第7,747,393号;美国专利第7,783,428号;和美国专利第8,383,346号。在变体产生之后,可以针对任何期望的性质(例如,高或增加的活性,或者低或降低的活性、增加的热活性、增加的热稳定性和/或酸性pH稳定性,等)对它们进行筛选。在一些实施方案中,可使用“重组DNA聚合酶多肽”(在本文中还被称为“工程化DNA聚合酶多肽”、“工程化DNA聚合酶”、“变体DNA聚合酶”和“DNA聚合酶变体”)。
如本文使用的,“载体”是用于将DNA序列引入到细胞中的DNA构建体。在一些实施方案中,载体是被可操作地连接至能够实现DNA序列中编码的多肽在合适宿主中的表达的合适的控制序列的表达载体。在一些实施方案中,“表达载体”具有可操作地连接至DNA序列(例如,转基因)以驱动在宿主细胞中的表达的启动子序列,并且在一些实施方案中,还包含转录终止子序列。
如本文使用的,术语“表达”包括参与多肽产生的任何步骤,包括但不限于,转录、转录后修饰、翻译和翻译后修饰。在一些实施方案中,该术语还涵盖多肽从细胞中的分泌。
如本文使用的,术语“产生”是指蛋白质和/或其他化合物从细胞的产生。意图是,该术语涵盖参与多肽产生的任何步骤,包括但不限于,转录、转录后修饰、翻译和翻译后修饰。在一些实施方案中,该术语还涵盖多肽从细胞中的分泌。
如本文使用的,如果氨基酸或核苷酸序列(例如,启动子序列、信号肽、终止子序列等)与可操作地与其连接的另一个序列在自然界中未缔合,则这两个序列是“异源的”。
如本文使用的,术语“宿主细胞”和“宿主菌株”是指用于包含本文提供的DNA(例如,编码至少一种DNA聚合酶变体的多核苷酸序列)的表达载体的合适的宿主。在一些实施方案中,宿主细胞是已经用使用如本领域已知的重组DNA技术构建的载体转化或转染的原核细胞或真核细胞。
如本文使用的,术语“类似物(analogue)”意指与参考多肽具有高于70%序列同一性但低于100%序列同一性(例如,高于75%、78%、80%、83%、85%、88%、90%、91%、92%、93%、94%、95%、96%、97%、98%、99%序列同一性)的多肽。在一些实施方案中,类似物包含非天然存在的氨基酸残基以及天然存在的氨基酸,所述非天然存在的氨基酸残基包括但不限于高精氨酸、鸟氨酸和正缬氨酸。在一些实施方案中,类似物还包含一个或更多个D-氨基酸残基以及两个或更多个氨基酸残基之间的非肽连接。
如本文使用的,术语“有效量”意指足以产生期望的结果的量。本领域普通技术人员可以通过使用常规实验确定有效量。
术语“分离的”和“纯化的”用于指从与其天然缔合的至少一种其他组分取出的分子(例如,分离的核酸、多肽等)或其他组分。术语“纯化的”不要求绝对纯度,而是意图作为相对定义。
如本文使用的,“组合物”和“制剂”涵盖包含至少一种的产物
如本文使用的,“无细胞DNA”是指在血流中自由循环且未被细胞包含或与细胞缔合的DNA。在一些实施方案中,无细胞DNA包含最初从正常体细胞或种系细胞、癌细胞、胎儿细胞、微生物细胞或病毒衍生和释放的DNA。
如本文使用的,“扩增”是指核酸复制。在一些实施方案中,该术语是指特定模板核酸的复制。
如本文使用的,“聚合酶链式反应”和“PCR”是指在此通过引用并入的美国专利第4,683,195号和第4,6884,202号中描述的方法。这些方法可用于增加混合物或纯化的DNA中靶序列区段或整个靶序列的浓度,而不需要克隆或纯化。一连串的(a sequence of)变性、退火和延伸构成了“循环”。变性、引物退火和聚合酶延伸的步骤可以重复许多次(即,使用多个循环),以获得高浓度的扩增DNA。该方法是本领域熟知的,并且自从该方法首次被描述以来,多年来已经开发了许多变化形式。通过PCR,有可能将特定靶序列的单个拷贝扩增到可通过若干不同方法检测到的水平,所述若干不同方法包括但不限于与标记的探针杂交,掺入生物素化引物,然后进行抗生物素蛋白-酶缀合物检测,将
如本文使用的,当关于PCR使用时,“靶”是指与用于PCR方法中的引物结合的核酸区域。“靶”是从用于PCR方法中的样品中存在的其他核酸中分选出来的。“区段”是靶序列中的核酸区域。
如本文使用的,“样品模板”是指来源于其中分析靶核酸的存在的样品的核酸。相比之下,“背景模板”是指样品模板以外的核酸,其可能存在或可能不存在于样品中。背景模板可能无意中被包含在样品中,它可能是由遗留(carryover)引起的,或者可能是由于从其纯化靶核酸的核酸污染物的存在而引起。例如,在一些实施方案中,来自待检测生物体以外的生物体的核酸可以作为背景存在于测试样品中。然而,并不意图本发明限于任何特定的核酸样品或模板。
如本文使用的,“可扩增核酸”用于指可以通过包括但不限于PCR的任何扩增方法进行扩增的核酸。在大多数实施方案中,可扩增核酸包含样品模板。
如本文使用的,“PCR产物”、“PCR片段”和“扩增产物”是指在通常包括变性、退火和延伸步骤的PCR扩增(或其他扩增方法,如上下文所示)的两个或更多个循环后获得的所得化合物。这些术语包括其中已经扩增了一个或更多个靶序列的一个或更多个区段的情况。
如本文使用的,“扩增试剂”和“PCR试剂”是指扩增所需的除了引物、核酸模板和扩增酶之外的那些试剂(例如脱氧核糖核苷三磷酸、缓冲液等)。通常,扩增试剂与其他反应组分一起被放置并包含在反应容器(例如试管、微孔等)中。并不意图本发明限于任何特定的扩增试剂,因为任何合适的试剂可用于本发明。
如本文使用的,“限制性核酸内切酶”和“限制性酶”是指在特定核苷酸序列(即“限制性位点”)处或附近切割双链核酸的酶。在一些实施方案中,限制性酶是细菌酶,并且在一些另外的实施方案中,核酸是DNA。
如本文使用的,“引物”是指这样的寡核苷酸(即,一连串的核苷酸),所述寡核苷酸无论是天然存在的还是合成产生的、重组产生的或通过扩增产生的,当置于诱导与核酸链互补的引物延伸产物的合成的条件下(即在核苷酸和诱导剂诸如DNA聚合酶的存在的情况下,并在合适的温度和pH)时,能够充当核酸合成的起始点。在大多数实施方案中,引物是单链的,但在一些实施方案中,它们是双链的。在一些实施方案中,引物具有足够的长度,以在存在DNA聚合酶的情况下引发延伸产物的合成。如本领域技术人员已知的,确切的引物长度取决于许多因素。
如本文使用的,“探针”是指这样的寡核苷酸(即,一连串的核苷酸),所述寡核苷酸无论是天然存在的还是合成产生的、重组产生的或通过扩增产生的,能够与另一种感兴趣的寡核苷酸杂交。探针可用于检测、鉴定和/或分离感兴趣的特定基因序列。在一些实施方案中,探针用“报告分子”(也称为“标记”)进行标记,该“报告分子”(也称为“标记”)有助于在合适的检测系统(例如,荧光、放射性、发光、酶和其他系统)中检测探针。不预期将本发明限于任何特定的检测系统或标记。引物、脱氧核糖核苷酸和脱氧核糖核苷可以含有标记。实际上,并不意图本发明的经标记的组合物限于任何特定的组分。说明性标记包括但不限于
如本文使用的,当关于聚合酶使用时,“保真度”意图是指相对于模板链,在合成的DNA链中模板指导地掺入互补碱基的准确性。通常,保真度基于在新合成的核酸链中掺入不正确碱基的频率来测量。掺入不正确的碱基可能导致点突变、插入或缺失。保真度可以根据本领域已知的任何方法来计算(参见例如Tindall和Kunkel,Biochem.,27:6008-6013[1988];和Barnes,Gene 112:29-35[1992])。聚合酶或聚合酶变体可以表现出高保真度或低保真度。如本文使用的,“高保真度”是指具有超过预定值的准确碱基掺入频率的聚合酶。如本文使用的,术语“低保真度”是指具有低于预定值的准确碱基掺入频率的聚合酶。在一些实施方案中,预定值是期望的准确碱基掺入频率或已知聚合酶(即参考聚合酶)的保真度。
如本文使用的,“改变的保真度”是指聚合酶变体的保真度不同于该聚合酶变体从其来源的亲本聚合酶的保真度。在一些实施方案中,改变的保真度高于亲本聚合酶的保真度,而在一些其他实施方案中,改变的保真度低于亲本聚合酶的保真度。改变的保真度可以通过使用本领域已知的任何合适的测定对亲本聚合酶和变体聚合酶进行测定并比较它们的活性来确定。
如本文使用的,术语“连接酶”是指通常用于将多核苷酸连接在一起或连接单个多核苷酸的末端的一类酶。连接酶包括ATP依赖性双链多核苷酸连接酶、NAD
如本文使用的,术语“衔接子”是指具有用于连接的相容DNA末端的单链或双链寡核苷酸。衔接子的末端可以是单链或双链的,并且可以包含与经加工的文库插入物DNA上的互补突出端相容的突出端。衔接子可以具有单链区域和双链区域二者。在一些实施方案中,术语“衔接子”用于指在NGS(即,下一代测序)反应中使用的可以包括引物结合位点、条形码和其他特征的全长衔接子,以及指在HTP筛选和连接测定中使用的具有与全长衔接子相同的连接相容末端但缺乏这些另外的特征的简化模型衔接子。设计用于
如本文使用的,术语“相容末端”是指具有5’或3’突出端的两个DNA双链体片段的末端,它们以5’至3’反向平行方向杂交,使得突出端上的所有碱基互补。在连接的情况下,至少一个DNA片段必须在核苷酸上具有5’磷酸,该核苷酸被放置为在3’或5’突出端杂交时与来自另一个分子的核苷酸的3’羟基相邻。连接导致两个底物分子在相容的末端处的共价连接。在一些涉及用于DNA测序的文库制备的实施方案中,两个DNA分子诸如衔接子和插入物片段必须具有相容的末端,并且衔接子/插入物杂交体的两条链必须连接,以实现通过PCR进行的有效文库扩增或通过与衔接子杂交的引物的聚合酶延伸进行的测序。
如本文使用的,术语“突出端”是指双链DNA片段末端处存在的一个或更多个未配对多核苷酸的区域。5’或3’DNA末端可以存在于未配对区域。双链DNA片段可以是两个互补单链多核苷酸的双链体,或者它可以是具有形成双链DNA的区域的自身互补性的单个多核苷酸。
术语“受试者”包括哺乳动物,诸如人类、非人类灵长类动物、家畜、伴侣动物和实验室动物(例如啮齿动物和兔类动物)。该术语意图包括雌性以及雄性。
如本文使用的,术语“患者”是指正在接受疾病评估、治疗疾病或正在经历疾病的任何受试者。
当通过参考在野生型DNA聚合酶或参考DNA聚合酶的序列中的特定氨基酸残基的修饰来提及特定的DNA聚合酶变体(即,工程化DNA聚合酶多肽)时,应当理解,本文包括在一个或更多个等同位置(如根据相应氨基酸序列之间的任选氨基酸序列比对来确定的)修饰的另一种DNA聚合酶的变体。
本发明的工程化DNA聚合酶多肽变体进行聚合酶反应,包括可用于聚合酶链式反应(PCR)和其他利用聚合酶产生DNA的反应的那些。
本发明的工程化DNA聚合酶变体可用于有效产生适用于NGS和其他诊断方法的DNA文库。这些DNA聚合酶变体可用于溶液中以及用于固定化的实施方案中。
在一些另外的实施方案中,本发明的工程化DNA聚合酶多肽包含这样的多肽,该多肽包含与SEQ ID NO:2、6、22、24、26、28和/或824的至少70%、至少75%、至少80%、至少85%、至少90%、至少91%、至少92%、至少93%、至少94%、至少95%、至少96%、至少97%、至少98%或至少99%的序列同一性。
在一些实施方案中,工程化DNA聚合酶多肽通过将包含编码至少一种工程化DNA聚合酶多肽的至少一种多核苷酸序列的微生物在有利于产生工程化DNA聚合酶多肽的条件下培养来产生。在一些实施方案中,随后工程化DNA聚合酶多肽从所得的培养基和/或细胞中回收。
本发明提供了具有DNA聚合酶活性的示例性工程化DNA聚合酶多肽。实施例提供了显示序列结构信息的表格,所述序列结构信息使特定氨基酸序列特征与工程化DNA聚合酶多肽的功能活性相关联。该结构-功能相关信息以相对于参考工程化多肽SEQ ID NO:2、6、22、24、26、28和/或824的特定氨基酸残基差异以及示例性工程化DNA聚合酶多肽的经实验确定的相关活性数据的形式来提供。
在一些实施方案中,具有DNA聚合酶活性的本发明的工程化DNA聚合酶多肽包含与参考序列SEQ ID NO:2、6、22、24、26、28和/或824具有至少85%序列同一性的氨基酸序列,并且与参考序列(例如,野生型DNA聚合酶)相比,表现出至少一种改进的性质。在一些实施方案中,改进的性质是增加的在PCR期间产生的产物,而在一些另外的实施方案中,改进的性质是增加的保真度,并且在又一些另外的实施方案中,改进的性质是增加的热稳定性。
在一些实施方案中,表现出至少一种改进的性质的工程化DNA聚合酶与SEQ IDNO:2、6、22、24、26、28和/或824具有至少85%、至少88%、至少90%、至少91%、至少92%、至少93%、至少94%、至少95%、至少96%、至少97%、至少98%、至少99%或更大的氨基酸序列同一性,以及与SEQ ID NO:2、6、22、24、26、28和/或824相比在一个或更多个氨基酸位置处(诸如在1个、2个、3个、4个、5个、6个、7个、8个、9个、10个、11个、12个、14个、15个、20个或更多个氨基酸位置处)具有氨基酸残基差异。在一些实施方案中,工程化DNA聚合酶多肽是实施例中提供的表格(例如,表3.1、表3.2、表3.3、表3.4、表3.5、表3.6、表3.7、表3.8、表4.1、表4.2、表4.3、表4.4、表4.5、表6.2和/或表6.3)中列出的多肽。
在一些实施方案中,本发明提供了工程化DNA聚合酶多肽的功能片段。在一些实施方案中,功能片段包含其所源自的工程化DNA聚合酶多肽(即,亲本工程化DNA聚合酶)的活性的至少约90%、至少约95%、至少约96%、至少约97%、至少约98%或至少约99%。在一些实施方案中,功能片段包含工程化DNA聚合酶的亲本序列的至少约90%、至少约91%、至少约92%、至少约93%、至少约94%、至少约95%、至少约96%、至少约97%、至少约98%或至少约99%。在一些实施方案中,功能片段被截短少于5个、少于10个、少于15个、少于20个、少于25个、少于30个、少于35个、少于40个、少于45个和少于50个氨基酸。
在一些实施方案中,本发明提供了工程化DNA聚合酶多肽的功能片段。在一些实施方案中,功能片段包含其所源自的工程化DNA聚合酶多肽(即,亲本工程化DNA聚合酶)的活性的至少约95%、96%、97%、98%或99%。在一些实施方案中,功能片段包含工程化DNA聚合酶的亲本序列的至少90%、91%、92%、93%、94%、95%、96%、97%、98%或99%。在一些实施方案中,功能片段被截短少于5个、少于10个、少于15个、少于20个、少于25个、少于30个、少于35个、少于40个、少于45个、少于50个、少于55个、少于60个、少于65个或少于70个氨基酸。
在一些实施方案中,表现出至少一种改进的性质的工程化DNA聚合酶与SEQ IDNO:2、6、22、24、26、28和/或824具有至少85%、至少88%、至少90%、至少91%、至少92%、至少93%、至少94%、至少95%、至少96%、至少97%、至少98%、至少99%或更大的氨基酸序列同一性,以及与SEQ ID NO:2、6、22、24、26、28和/或824相比在一个或更多个氨基酸位置处(诸如在1个、2个、3个、4个、5个、6个、7个、8个、9个、10个、11个、12个、14个、15个或更多个氨基酸位置处)具有氨基酸残基差异。在一些实施方案中,工程化DNA聚合酶包含与SEQ IDNO:2、6、22、24、26、28和/或824的至少90%的序列同一性,并且包含至少1个、2个、3个、4个、5个、6个、7个、8个、9个、10个或更多个氨基酸位置的氨基酸差异。在一些实施方案中,工程化DNA聚合酶多肽由SEQ ID NO:6、22、24、26、28和/或824的序列组成。
本发明提供了编码本文描述的工程化DNA聚合酶多肽的多核苷酸。在一些实施方案中,多核苷酸被可操作地连接至控制基因表达的一个或更多个异源调节序列,以产生能够表达多肽的重组多核苷酸。在一些实施方案中,包含编码一种或更多种工程化DNA聚合酶多肽的至少一种异源多核苷酸的表达构建体被引入适当的宿主细胞中以表达对应的一种或更多种DNA聚合酶多肽。
如对技术人员将是明显的,蛋白质序列的可得性和对应于各种氨基酸的密码子的知识提供了能够编码主题多肽的所有多核苷酸的描述。遗传密码的简并性(其中相同氨基酸由可选择的或同义的密码子编码)允许制备极大数目的核酸,所有这些核酸编码工程化DNA聚合酶多肽。因此,本发明提供了用于产生编码本文描述的DNA聚合酶多肽的DNA聚合酶多核苷酸的每一种和每种可能的变异的方法和组合物,所述变异可以通过基于可能的密码子选择来选择组合进行制备,并且对于本文描述的任何多肽,包括实施例中(例如,表3.1、表3.2、表3.3、表3.4、表3.5、表3.6、表3.7、表3.8、表4.1、表4.2、表4.3、表4.4和/或表4.5中)呈现的氨基酸序列,所有这样的变异被认为具体地公开。
在一些实施方案中,优选地,密码子是优化的,用于被选择的宿主细胞使用以进行蛋白质产生。例如,细菌中使用的优选的密码子通常被用于在细菌中的表达。因此,编码工程化DNA聚合酶多肽的经密码子优化的多核苷酸在全长编码区域中约40%、50%、60%、70%、80%、90%或大于90%的密码子位置处包含优选的密码子。
在一些实施方案中,DNA聚合酶多核苷酸编码具有DNA聚合活性与本文公开的性质的工程化多肽,其中多肽包含与选自SEQ ID NO:2、6、22、24、26、28和/或824的参考序列或者任何变体(例如,实施例中提供的那些)的氨基酸序列具有至少80%、85%、86%、87%、88%、89%、90%、91%、92%、93%、94%、95%、96%、97%、98%、99%或更多的同一性的氨基酸序列,以及与参考多肽SEQ ID NO:2、6、22、24、26、28和/或824或者实施例中公开的任何变体的氨基酸序列相比的一个或更多个残基差异(例如1个、2个、3个、4个、5个、6个、7个、8个、9个、10个或更多个氨基酸残基位置)。在一些实施方案中,参考序列选自SEQ ID NO:2、6、22、24、26、28和/或824。在一些实施方案中,工程化DNA聚合酶变体包含SEQ ID NO:6、22、24、26、28和/或824中所列的多肽序列。在一些实施方案中,工程化DNA聚合酶变体包括实施例中提供的变体DNA聚合酶的一个或更多个取代或一个或更多个取代集。
本发明提供了编码本文提供的工程化DNA聚合酶变体的多核苷酸。在一些实施方案中,多核苷酸包含与选自SEQ ID NO:1、5、21、23、25、27和/或823的参考序列或者任何变体(例如,实施例中提供的那些)的核酸序列具有至少80%、85%、86%、87%、88%、89%、90%、91%、92%、93%、94%、95%、96%、97%、98%、99%或更多的同一性的核苷酸序列,以及与参考多核苷酸SEQ ID NO:1、5、21、23、25、27和/或823或者实施例中公开的任何变体的核酸序列相比的一个或更多个残基差异(例如1个、2个、3个、4个、5个、6个、7个、8个、9个、10个或更多个位置)。
在一些实施方案中,参考序列选自SEQ ID NO:1、5、21、23、25、27和/或823。在一些实施方案中,多核苷酸能够在高度严格的条件下与选自SEQ ID NO:1、5、21、23、25、27和/或823的参考多核苷酸序列或其互补序列或者编码本文提供的任何变体DNA聚合酶多肽的多核苷酸序列杂交。
在一些实施方案中,能够在高度严格条件下杂交的多核苷酸编码包含与SEQ IDNO:2、22、24、26、28和/或824相比具有一个或更多个残基差异的氨基酸序列的DNA聚合酶多肽。在一些实施方案中,工程化DNA聚合酶变体由SEQ ID NO:1、5、21、23、25、27和/或823中所列的多核苷酸序列编码。
在一些实施方案中,编码本文的工程化DNA聚合酶多肽中的任何一个的分离的多核苷酸以各种方式被操纵,以促进DNA聚合酶多肽的表达。在一些实施方案中,编码DNA聚合酶多肽的多核苷酸构成表达载体,其中存在一个或更多个控制序列来调节DNA聚合酶多核苷酸和/或多肽的表达。根据所用的表达载体,在分离的多核苷酸插入载体之前对分离的多核苷酸的操纵可以是期望的或必要的。利用重组DNA方法修饰多核苷酸和核酸序列的技术是本领域熟知的。在一些实施方案中,控制序列包括,除了其他以外,启动子、前导序列、多腺苷酸化序列、前肽序列、信号肽序列和转录终止子。在一些实施方案中,基于宿主细胞的选择对合适的启动子进行选择。对于细菌宿主细胞,用于指导本公开内容的核酸构建体的转录的合适启动子包括但不限于从以下获得的启动子:大肠杆菌lac操纵子、天蓝色链霉菌(Streptomyces coelicolor)琼脂糖酶基因(dagA)、枯草芽孢杆菌(Bacillus subtilis)果聚糖蔗糖酶基因(sacB)、地衣芽孢杆菌(Bacillus licheniformis)α-淀粉酶基因(amyL)、嗜热脂肪芽孢杆菌(Bacillus stearothermophilus)麦芽糖淀粉酶基因(amyM)、解淀粉芽孢杆菌(Bacillus amyloliquefaciens)α-淀粉酶基因(amyQ)、地衣芽孢杆菌青霉素酶基因(penP)、枯草芽孢杆菌xylA和xylB基因,以及原核β-内酰胺酶基因(参见,例如,Villa-Kamaroff等人,Proc.Natl Acad.Sci.USA 75:3727-3731[1978]),以及tac启动子(参见,例如,DeBoer等人,Proc.Natl Acad.Sci.USA 80:21-25[1983])。用于丝状真菌宿主细胞的示例性启动子包括但不限于从以下的基因获得的启动子:米曲霉(Aspergillus oryzae)TAKA淀粉酶、米黑根毛霉(Rhizomucor miehei)天冬氨酸蛋白酶、黑曲霉(Aspergillus niger)中性α-淀粉酶、黑曲霉酸稳定型α-淀粉酶、黑曲霉或泡盛曲霉(Aspergillus awamori)葡糖淀粉酶(glaA)、米黑根毛霉脂肪酶、米曲霉碱性蛋白酶、米曲霉磷酸丙糖异构酶、构巢曲霉(Aspergillus nidulans)乙酰胺酶和尖孢镰刀菌(Fusarium oxysporum)胰蛋白酶样蛋白酶(参见,例如WO 96/00787),以及NA2-tpi启动子(来自黑曲霉中性α-淀粉酶基因和米曲霉磷酸丙糖异构酶基因的启动子的杂合体),和其突变体启动子、截短的启动子和杂合的启动子。示例性酵母细胞启动子可以来自以下的基因:酿酒酵母(Saccharomyces cerevisiae)烯醇酶(ENO-1)、酿酒酵母半乳糖激酶(GAL1)、酿酒酵母醇脱氢酶/甘油醛-3-磷酸脱氢酶(ADH2/GAP)和酿酒酵母3-磷酸甘油酸激酶。用于酵母宿主细胞的其他有用的启动子是本领域已知的(参见例如,Romanos等人,Yeast 8:423-488[1992])。
在一些实施方案中,控制序列也是合适的转录终止子序列(即,由宿主细胞识别以终止转录的序列)。在一些实施方案中,终止子序列可操作地连接至编码DNA聚合酶多肽的核酸序列的3'末端。在选择的宿主细胞中有功能的任何合适的终止子可用于本发明中。用于丝状真菌宿主细胞的示例性转录终止子可以从以下的基因获得:米曲霉TAKA淀粉酶、黑曲霉葡糖淀粉酶、构巢曲霉邻氨基苯甲酸合酶、黑曲霉α-葡萄糖苷酶和尖孢镰刀菌胰蛋白酶样蛋白酶。用于酵母宿主细胞的示例性终止子可以从以下的基因获得:酿酒酵母烯醇酶、酿酒酵母细胞色素C(CYC1)和酿酒酵母甘油醛-3-磷酸脱氢酶。用于酵母宿主细胞的其他有用的终止子是本领域已知的(参见例如,Romanos等,上文)。
在一些实施方案中,控制序列也是合适的前导序列(即,对由宿主细胞的翻译重要的mRNA的非翻译区)。在一些实施方案中,前导序列可操作地连接至编码DNA聚合酶多肽的核酸序列的5'末端。在选择的宿主细胞中有功能的任何合适的前导序列可用于本发明中。用于丝状真菌宿主细胞的示例性前导序列从以下的基因获得:米曲霉TAKA淀粉酶和构巢曲霉磷酸丙糖异构酶。用于酵母宿主细胞的合适的前导序列从以下的基因获得:酿酒酵母烯醇化酶(ENO-1)、酿酒酵母3-磷酸甘油酸激酶、酿酒酵母α-因子和酿酒酵母醇脱氢酶/甘油醛-3-磷酸脱氢酶(ADH2/GAP)。
在一些实施方案中,控制序列也是多腺苷酸化序列(即,可操作地连接至核酸序列的3'末端的序列,并且其在转录时,被宿主细胞识别为将多腺苷残基添加至转录的mRNA的信号)。在选择的宿主细胞中有功能的任何合适的多腺苷酸化序列可用于本发明中。用于丝状真菌宿主细胞的示例性多腺苷酸化序列包括,但不限于来自以下的基因的那些:米曲霉TAKA淀粉酶、黑曲霉葡糖淀粉酶、构巢曲霉邻氨基苯甲酸合酶、尖孢镰刀菌胰蛋白酶样蛋白酶和黑曲霉α葡糖苷酶。用于酵母宿主细胞的有用的多腺苷酸化序列是已知的(参见例如Guo和Sherman,Mol.Cell.Biol.,15:5983-5990[1995])。
在一些实施方案中,控制序列也是信号肽(即,编码连接至多肽的氨基末端并将编码的多肽引导到细胞的分泌途径中的氨基酸序列的编码区)。在一些实施方案中,核酸序列的编码序列的5'末端固有地包含信号肽编码区,其符合翻译阅读框地(in translationreading frame)与编码分泌的多肽的编码区的区段天然地连接。可选地,在一些实施方案中,编码序列的5'末端包含对编码序列而言外来的信号肽编码区。将表达的多肽引导到选择的宿主细胞的分泌途径中的任何合适的信号肽编码区可用于一种或更多种工程化多肽的表达。用于细菌宿主细胞的有效信号肽编码区是包括但不限于从以下的基因获得的那些信号肽编码区:芽孢杆菌NClB 11837麦芽糖淀粉酶、嗜热脂肪芽孢杆菌α-淀粉酶、地衣芽孢杆菌枯草杆菌蛋白酶、地衣芽孢杆菌β-内酰胺酶、嗜热脂肪芽孢杆菌中性蛋白酶(nprT、nprS、nprM)和枯草芽孢杆菌prsA。另外的信号肽是本领域已知的(参见例如,Simonen和Palva,Microbiol.Rev.,57:109-137[1993])。在一些实施方案中,对于丝状真菌宿主细胞有效的信号肽编码区包括但不限于从以下的基因获得的信号肽编码区:米曲霉TAKA淀粉酶、黑曲霉中性淀粉酶、黑曲霉葡糖淀粉酶、米黑根毛霉天冬氨酸蛋白酶、特异腐质霉(Humicola insolens)纤维素酶和Humicola lanuginosa脂肪酶。用于酵母宿主细胞的有用的信号肽包括但不限于来自以下的基因的那些:酿酒酵母α因子和酿酒酵母转化酶。
在一些实施方案中,控制序列也是编码定位在多肽的氨基末端处的氨基酸序列的前肽编码区。产生的多肽被称为“前酶(proenzyme)”、“前多肽(propolypeptide)”或“酶原(zymogen)”。前多肽可以通过催化或自动催化前肽从前多肽的裂解被转化为成熟活性多肽。前肽编码区可以从包括但不限于以下的基因的任何合适的来源获得:枯草芽孢杆菌碱性蛋白酶(aprE)、枯草芽孢杆菌中性蛋白酶(nprT)、酿酒酵母α-因子、米黑根毛霉天冬氨酸蛋白酶和嗜热毁丝霉(Myceliophthora thermophila)乳糖酶(参见例如WO95/33836)。在信号肽和前肽区域两者均存在于多肽的氨基末端时,前肽区域紧邻多肽的氨基末端定位并且信号肽区域紧邻前肽区域的氨基末端定位。
在一些实施方案中,还利用了调节序列。这些序列促进相对于宿主细胞生长的多肽表达调节。调节系统的实例是引起基因的表达响应于化学或物理刺激(包括调节性化合物的存在)被开启或关闭的那些。在原核宿主细胞中,合适的调节序列包括但不限于lac、tac和trp操纵子系统。在酵母宿主细胞中,合适的调节系统包括但不限于ADH2系统或GAL1系统。在丝状真菌中,合适的调节序列包括但不限于TAKAα-淀粉酶启动子、黑曲霉葡糖淀粉酶启动子和米曲霉葡糖淀粉酶启动子。
在另一方面,本发明涉及包含编码工程化DNA聚合酶多肽的多核苷酸以及根据其待被引入的宿主的类型,一个或更多个表达调控区诸如启动子和终止子、复制起点等的重组表达载体。在一些实施方案中,本文描述的各种核酸和控制序列连接在一起以产生重组表达载体,所述重组表达载体包括一个或更多个方便的限制性位点,以允许在这样的位点插入或取代编码DNA聚合酶多肽的核酸序列。可选地,在一些实施方案中,本发明的核酸序列通过将核酸序列或包含该序列的核酸构建体插入到用于表达的合适的载体中来表达。在涉及产生表达载体的一些实施方案中,编码序列位于载体中以使编码序列与用于表达的适当的控制序列可操作地连接。
重组表达载体可以是任何合适的载体(例如,质粒或病毒),其可以方便地进行重组DNA程序并且引起DNA聚合酶多核苷酸序列的表达。载体的选择通常取决于载体与待引入载体的宿主细胞的相容性。载体可以是线性质粒或闭合的环状质粒。
在一些实施方案中,表达载体为自主复制载体(即,作为染色体外的实体存在的载体,其复制独立于染色体复制,诸如质粒、染色体外元件、微型染色体或人工染色体)。载体可以包含用于确保自我复制的任何工具(means)。在一些可选的实施方案中,载体是其中当被引入宿主细胞中时,被整合到基因组中并与其被整合进的一条或更多条染色体一起复制的载体。此外,在一些实施方案中,使用单一载体或质粒,或者一起包含待引入宿主细胞的基因组中的总DNA的两种或更多种载体或质粒,和/或转座子。
在一些实施方案中,表达载体包含允许容易选择经转化的细胞的一个或更多个选择标记(selectable marker)。“选择标记”是其产物提供抗生物剂或病毒抗性、对重金属的抗性、对营养缺陷型的原养性(prototrophy to auxotrophs)等的基因。细菌的选择标记的实例包括但不限于,来自枯草芽孢杆菌或地衣芽孢杆菌的dal基因,或赋予抗生素抗性诸如氨苄青霉素、卡那霉素、氯霉素或四环素抗性的标记。用于酵母宿主细胞的合适的标记包括但不限于ADE2、HIS3、LEU2、LYS2、MET3、TRP1和URA3。用于在丝状真菌宿主细胞中使用的选择标记包括但不限于amdS(乙酰胺酶,例如来自构巢曲菌(A.nidulans)或米曲霉(A.orzyae))、argB(鸟氨酸氨甲酰转移酶)、bar(膦丝菌素乙酰转移酶,例如来自吸水链霉菌(S.hygroscopicus))、hph(潮霉素磷酸转移酶)、niaD(硝酸还原酶)、pyrG(乳清苷-5'-磷酸脱羧酶,例如来自构巢曲霉或米曲霉)、sC(硫酸腺苷酰转移酶(sulfateadenyltransferase))和trpC(邻氨基苯甲酸合酶),以及其等同物。在另一个方面,本发明提供了一种宿主细胞,所述宿主细胞包含编码本发明的至少一种工程化DNA聚合酶多肽的至少一种多核苷酸,所述多核苷酸被可操作地连接至一个或更多个控制序列用于在宿主细胞中表达一种或更多种工程化DNA聚合酶。适合用于在表达由本发明的表达载体编码的多肽中使用的宿主细胞是本领域熟知的,并且包括但不限于细菌细胞,诸如大肠杆菌、河流弧菌(Vibrio fluvialis)、链霉菌属(Streptomyces)和鼠伤寒沙门菌(Salmonellatyphimurium)细胞;真菌细胞,诸如酵母细胞(例如,酿酒酵母或巴斯德毕赤酵母(Pichiapastoris)(ATCC登录号201178));昆虫细胞,诸如果蝇属(Drosophila)S2和夜蛾属(Spodoptera)Sf9细胞;动物细胞,诸如CHO、COS、BHK、293和Bowes黑素瘤细胞;和植物细胞。示例性宿主细胞还包括各种大肠杆菌(Escherichia coli)菌株(例如,W3110(ΔfhuA)和BL21)。
因此,在另一个方面,本发明提供了产生工程化DNA聚合酶多肽的方法,其中所述方法包括将能够表达编码工程化DNA聚合酶多肽的多核苷酸的宿主细胞在适合该多肽表达的条件下培养。在一些实施方案中,方法还包括分离和/或纯化如本文描述的DNA聚合酶多肽的步骤。
用于宿主细胞的适当的培养基以及生长条件是本领域熟知的。预期任何用于将表达DNA聚合酶多肽的多核苷酸引入细胞的合适方法可用于本发明。合适的技术包括但不限于,电穿孔、生物弹射粒子轰击(biolistic particle bombardment)、脂质体介导的转染、氯化钙转染和原生质体融合。
具有本文公开的性质的工程化DNA聚合酶多肽可以通过使编码天然存在的或工程化DNA聚合酶多肽的多核苷酸经历本领域中已知的和/或如本文所描述的任何合适的诱变和/或定向进化方法来获得。示例性的定向进化技术为诱变和/或DNA改组(参见例如,Stemmer,Proc.Natl.Acad.Sci.USA 91:10747-10751[1994];WO 95/22625;WO 97/0078;WO97/35966;WO 98/27230;WO 00/42651;WO 01/75767和美国专利6,537,746)。可以使用的其他定向进化程序包括,尤其是,交错延伸过程(StEP)、体外重组(参见例如,Zhao等人,Nat.Biotechnol.,16:258-261[1998])、诱变PCR(参见例如,Caldwell等人,PCR MethodsAppl.,3:S136-S140[1994])和盒式诱变(参见如,Black等人,Proc.Natl.Acad.Sci.USA93:3525-3529[1996])。
诱变和定向进化的方法可以容易地应用至编码DNA聚合酶的多核苷酸,以产生可以被表达、筛选和测定的变体文库。任何合适的诱变和定向进化方法可用于本发明并是本领域熟知的(参见例如美国专利第5,605,793、5,811,238、5,830,721、5,834,252、5,837,458、5,928,905、6,096,548、6,117,679、6,132,970、6,165,793、6,180,406、6,251,674、6,265,201、6,277,638、6,287,861、6,287,862、6,291,242、6,297,053、6,303,344、6,309,883、6,319,713、6,319,714、6,323,030、6,326,204、6,335,160、6,335,198、6,344,356、6,352,859、6,355,484、6,358,740、6,358,742、6,365,377、6,365,408、6,368,861、6,372,497、6,337,186、6,376,246、6,379,964、6,387,702、6,391,552、6,391,640、6,395,547、6,406,855、6,406,910、6,413,745、6,413,774、6,420,175、6,423,542、6,426,224、6,436,675、6,444,468、6,455,253、6,479,652、6,482,647、6,483,011、6,484,105、6,489,146、6,500,617、6,500,639、6,506,602、6,506,603、6,518,065、6,519,065、6,521,453、6,528,311、6,537,746、6,573,098、6,576,467、6,579,678、6,586,182、6,602,986、6,605,430、6,613,514、6,653,072、6,686,515、6,703,240、6,716,631、6,825,001、6,902,922、6,917,882、6,946,296、6,961,664、6,995,017、7,024,312、7,058,515、7,105,297、7,148,054、7,220,566、7,288,375、7,384,387、7,421,347、7,430,477、7,462,469、7,534,564、7,620,500、7,620,502、7,629,170、7,702,464、7,747,391、7,747,393、7,751,986、7,776,598、7,783,428、7,795,030、7,853,410、7,868,138、7,783,428、7,873,477、7,873,499、7,904,249、7,957,912、7,981,614、8,014,961、8,029,988、8,048,674、8,058,001、8,076,138、8,108,150、8,170,806、8,224,580、8,377,681、8,383,346、8,457,903、8,504,498、8,589,085、8,762,066、8,768,871、9,593,326、9,665,694、9,684,771号,以及所有相关的PCT和非美国的对应申请;Ling等人,Anal.Biochem.,254(2):157-78[1997];Dale等人,Meth.Mol.Biol.,57:369-74[1996];Smith,Ann.Rev.Genet.,19:423-462[1985];Botstein等人,Science,229:1193-1201[1985];Carter,Biochem.J.,237:1-7[1986];
Kramer等人,Cell,38:879-887[1984];Wells等人,Gene,34:315-323[1985];
Minshull等人,Curr.Op.Chem.Biol.,3:284-290[1999];Christians等人,Nat.Biotechnol.,17:259-264[1999];Crameri等人,Nature,391:288-291[1998];
Crameri,等人,Nat.Biotechnol.,15:436-438[1997];Zhang等人,Proc.Nat.Acad.Sci.U.S.A.,94:4504-4509[1997];Crameri等人,Nat.Biotechnol.,14:315-319[1996];Stemmer,Nature,370:389-391[1994];Stemmer,Proc.Nat.Acad.Sci.USA,91:10747-10751[1994];EP 3 049 973;WO 95/22625;WO97/0078;WO 97/35966;WO 98/27230;WO 00/42651;WO 01/75767;WO 2009/152336;和WO 2015/048573,其全部通过引用并入本文)。
在一些实施方案中,诱变处理后获得的酶克隆通过使酶制品经历确定的温度(或其他测定条件),并测量热处理或其他合适的测定条件之后剩余的酶活性的量来进行筛选。然后包含编码DNA聚合酶多肽的多核苷酸的克隆从基因分离、测序以鉴定核苷酸序列的改变(如果有),并且用于在宿主细胞中表达酶。测量来自表达文库的酶活性可以使用本领域已知的任何合适的方法(例如,标准生物化学技术,诸如HPLC分析)来进行。
对于已知序列的工程化多肽,编码酶的多核苷酸可以根据已知的合成方法通过标准的固相方法制备。在一些实施方案中,多达约100个碱基的片段可以被单独地合成,然后连接(例如,通过酶促或化学连接方法(chemical ligation method)或聚合酶介导的方法)以形成任何期望的连续序列。例如,本文公开的多核苷酸和寡核苷酸可以使用经典的亚磷酰胺方法通过化学合成制备(参见例如,Beaucage等人,Tet.Lett.,22:1859-69[1981];和Matthes等人,EMBO J.,3:801-05[1984]),如通常在自动合成方法中所实践的。根据亚磷酰胺方法,寡核苷酸被合成(例如,在自动的DNA合成仪中,纯化、退火、连接并克隆在适当的载体中)。
因此,在一些实施方案中,用于制备工程化DNA聚合酶多肽的方法可以包括:(a)合成编码多肽的多核苷酸,该多肽包含选自如本文描述的任何变体的氨基酸序列的氨基酸序列,和(b)表达由该多核苷酸编码的DNA聚合酶多肽。在方法的一些实施方案中,由多核苷酸编码的氨基酸序列可以任选地具有一个或若干(例如,多达3个、4个、5个或多达10个)氨基酸残基缺失、插入和/或取代。在一些实施方案中,氨基酸序列任选地具有1-2个、1-3个、1-4个、1-5个、1-6个、1-7个、1-8个、1-9个、1-10个、1-15个、1-20个、1-21个、1-22个、1-23个、1-24个、1-25个、1-30个、1-35个、1-40个、1-45个或1-50个氨基酸残基缺失、插入和/或取代。在一些实施方案中,氨基酸序列任选地具有1个、2个、3个、4个、5个、6个、7个、8个、9个、10个、11个、12个、13个、14个、15个、16个、17个、18个、19个、20个、21个、22个、23个、24个、25个、30个、35个、40个、45个或50个氨基酸残基缺失、插入和/或取代。在一些实施方案中,氨基酸序列任选地具有1个、2个、3个、4个、5个、6个、7个、8个、9个、10个、11个、12个、13个、14个、15个、16个、18个、20个、21个、22个、23个、24个或25个氨基酸残基缺失、插入和/或取代。在一些实施方案中,取代是保守取代或非保守取代。
可以使用本领域已知的任何合适的测定,包括但并不限于本文描述的测定和条件,评价所表达的工程化DNA聚合酶多肽的任何期望的改进的性质或性质的组合(例如,活性、选择性、保真度、稳定性、热稳定性、对各种pH水平的耐受性、蛋白酶敏感性等)。
在一些实施方案中,使用用于蛋白纯化的熟知技术中的任何一种或更多种,将宿主细胞中表达的工程化DNA聚合酶多肽中的任一种从细胞和/或培养基中回收,用于蛋白纯化的熟知技术除了其他以外包括,溶菌酶处理、声处理(sonication)、过滤、盐析、超离心和色谱法。
用于分离DNA聚合酶多肽的色谱技术,除了其他以外,包括,反相色谱、高效液相色谱、离子交换色谱、疏水相互作用色谱、尺寸排阻色谱、凝胶电泳和亲和色谱。用于纯化特定酶的条件部分地取决于因素诸如净电荷、疏水性、亲水性、分子量、分子形状等,并且对本领域技术人员是明显的。在一些实施方案中,亲和技术可以用于分离改进的DNA聚合酶。对于亲和色谱纯化,可以使用与感兴趣的DNA聚合酶多肽特异性结合的任何抗体。为了产生抗体,通过注射DNA聚合酶多肽或其片段免疫接种各种宿主动物,包括但不限于兔、小鼠、大鼠等。在一些实施方案中,DNA聚合酶多肽或片段借助于侧链官能基团或附接至侧链官能基团的接头被附接至合适的载体,诸如BSA。
在一些实施方案中,工程化DNA聚合酶多肽通过包括以下的方法在宿主细胞中产生:将包含编码如本文描述的工程化DNA聚合酶多肽的多核苷酸序列的宿主细胞(例如,大肠杆菌菌株)在有利于工程化DNA聚合酶多肽产生的条件下培养,并从细胞和/或培养基中回收工程化DNA聚合酶多肽。在一些实施方案中,宿主细胞产生多于一种工程化DNA聚合酶多肽。
在一些实施方案中,本发明提供了产生工程化DNA聚合酶多肽的方法,所述方法包括在允许产生工程化DNA聚合酶多肽的合适的培养条件下培养重组细菌细胞并任选地从培养物和/或培养的细菌细胞回收工程化DNA聚合酶多肽,所述重组细菌细胞包含编码与参考序列SEQ ID NO:2、6、22、24、26、28和/或824具有至少85%、90%、95%、96%、97%、98%或99%序列同一性并具有一个或更多个氨基酸残基差异的工程化DNA聚合酶多肽的多核苷酸序列。在一些实施方案中,宿主细胞产生多于一种工程化DNA聚合酶多肽。
在一些实施方案中,在工程化DNA聚合酶多肽从重组宿主细胞和/或培养基回收后,它们通过本领域已知的任何合适的一种或更多种方法进一步纯化。在一些另外的实施方案中,纯化的工程化DNA聚合酶多肽与其他成分和化合物组合以提供包含工程化DNA聚合酶多肽根据需要用于不同应用和用途的组合物和制剂(例如,诊断方法和组合物)。
实验
提供以下实施例,包括实验和获得的结果,仅用于说明的目的,而不应被解释为限制本发明。
在下文的实验公开内容中,应用了以下缩写:ppm(百万分率);M(摩尔/升);mM(毫摩尔/升);uM和μM(微摩尔/升);nM(纳摩尔/升);mol(摩尔);gm和g(克);mg(毫克);ug和μg(微克);L和1(升);ml和mL(毫升);cm(厘米);mm(毫米);um和μm(微米);sec.(秒);min(s)(分钟);h(s)和hr(s)(小时);Ω(欧姆);μf(微法拉);U(单位);MW(分子量);rpm(转/分);rcf(相对离心力);psi和PSI(磅/平方英寸);℃(摄氏度);RT和rt(室温);NGS(下一代测序);ds(双链);ss(单链);CDS(编码序列);DNA(脱氧核糖核酸);RNA(核糖核酸);大肠杆菌W3110(常用实验室大肠杆菌菌株,可从Coli Genetic Stock Center[CGSC],New Haven,CT获得);HTP(高通量);HPLC(高压液相色谱法);MCYP(microcyp);ddH
实施例1
DNA聚合酶基因的获得和表达载体的构建
由嗜热球菌属物种菌株2319x1的基因组编码的B组聚合酶(Unprot IDA0A0U3SCT0;SEQ ID NO:1和2,分别是多核苷酸和多肽序列),与强烈火球菌DNA聚合酶(SEQID NO:4)共有73%蛋白质序列同一性。这种聚合酶(SEQ ID NO:2)在本文称为“Pol3”。需要澄清的是,这种酶与参与原核DNA复制的DNA聚合酶III全酶不同。构建编码野生型(WT)Pol3聚合酶的加6-组氨酸标签形式(SEQ ID NO:6)的合成基因(SEQ ID NO:5),并且将其亚克隆至大肠杆菌表达载体pCK100900i中(参见例如,美国专利第7,629,157号和美国专利申请公布第2016/0244787号,这两篇文献都通过引用在此并入)。将这些质粒构建体转化至来源于W3110的大肠杆菌菌株中。使用本领域技术人员通常已知的定向进化技术从这些质粒产生基因变体的文库(参见例如,美国专利第8,383,346号和WO 2010/144103,这两篇文献都通过引用在此并入)。本文描述的酶变体中的取代是参考加6-组氨酸标签的酶(即,SEQ IDNO:6)或其变体来指示的,如所指示的。
实施例2
高通量(HTP)Pol3 DNA聚合酶基因表达和裂解物制备
在本实施例中,描述了用于聚合酶变体的HTP生长和裂解物制备的方法。
经转化的大肠杆菌细胞通过铺板到含有l%葡萄糖和30μg/ml氯霉素的LB琼脂板上来选择。在37℃孵育过夜之后,将菌落置于96孔浅平底NUNCTM微板(Thermo-Scientific)的孔中,该板填充有180μl/孔的补充有l%葡萄糖和30μg/ml氯霉素的LB培养基。允许培养物在摇动器(200rpm,30℃,和85%相对湿度;Kuhner)中生长过夜持续18-20小时。将过夜生长样品(20μL)转移至Costar 96孔深板中,该板填充有380μL的补充有30μg/ml氯霉素的极好肉汤(Terrific Broth)。板在摇动器(250rpm,30℃,和85%相对湿度;Kuhner)中孵育120分钟,直到OD
使细胞沉淀解冻,并通过在室温在300μl/孔的裂解缓冲液(20mM NaCl,50mMTris-HCl,pH 7.5)中摇动10分钟来重悬。然后,将150ul重悬的沉淀转移到
实施例3
PCR产物产量测定
Pol3变体的选择通过在相对于所用模板的长度具有短的延伸时间的终点PCR测定中测量PCR产物产量来实现。每种变体在30μL的反应中进行筛选,该反应包含80pg/μL的MCYP模板DNA(SEQ ID NO:7)、0.2mM dNTP、各自400nM的MCYP正向引物(SEQ ID NO:10)和反向引物(SEQ ID NO:11)、20mM Tris缓冲液,pH 8.8、10mM KCl、2mM MgSO
实施例4
高通量聚合酶保真度测试
基于菌落的报告物测定被充分确定为是确定聚合酶保真度的方法。在这些测定中,复制了报告基因诸如lacZ(参见,Barnes,Gene 112:29-35[1992])、lacI(Jozwiakowksi和Connolly,Nucl.Acids Res.,37:e102[2009])和rpsL(Kitabayashi等人,Biosci.Biotechnol.Biochem.,66:2194-2200[2002]),在克隆中观察到的基因失活突变的频率与报告基因复制中使用的DNA聚合酶的错误率成正比。将错误率报告为对于lacI或lacZ,在X-gal(5-溴-4-氯-3-吲哚基B-D-吡喃半乳糖苷)板上具有蓝色或白色表型的菌落的分数,或者对于rpsL,在选择性氨苄青霉素或链霉素琼脂板上生长的菌落的比率。因为校对DNA聚合酶的错误率非常低(例如,~3x 10
使用基于细胞的流式细胞术测定,开发了用于在本发明中使用的DNA聚合酶保真度的高通量测定。构建了报告质粒(SEQ ID NO:18),所述报告质粒编码在诱导型LacI启动子控制下的两种荧光蛋白eGFP(SEQ ID NO:14)和野生型dsRed(SEQ ID NO:16)的基因。该质粒还编码氯霉素乙酰转移酶的基因以用于选择。当该报告质粒转化到大肠杆菌中并用IPTG诱导时,两种荧光蛋白都在群体中的大多数细胞中表达。表达单个荧光蛋白(例如,dsRed)的大肠杆菌群体由于基因表达中的诱导和噪声的变化而表现出荧光强度的宽对数正态分布。因此,使dsRed失活的突变与基因表达中的噪声会是无法区分的。虽然在双标记的(eGFP/dsRed)群体的细胞中有广泛的基因表达,但这两种蛋白的表达是共同变化的。因此,强烈表达eGFP而不表达dsRed的细胞极其罕见,并且表达dsRed中有失活突变(但保留eGFP表达)的报告质粒的细胞容易与背景区分开。
PCR反应使用变体聚合酶和邻接的5’-磷酸化引物进行以复制报告质粒的整个序列。在PCR扩增期间,聚合酶诱导的错误被引入到由报告质粒编码的一种或两种荧光报告蛋白中。复制产物经由连接而环化,转化到大肠杆菌中,并且野生型和含错误转化体的混合群体被诱导表达双报告物。然后经诱导的细胞群体使用流式细胞术进行分析,以确定由于PCR错误而丧失dsRed表达但仍表达GFP的细胞的分数。重要的是,当WT报告质粒的分离的克隆被诱导48-72小时并通过流式细胞术分析时,仅表达eGFP的细胞的背景极低。
如实施例2中关于PCR反应所描述的,报告构建体使用5’-磷酸化正向引物(SEQ IDNO:19)和反向引物(SEQ ID NO:20)扩增。通常,每种DNA聚合酶使用0.25%体积/体积HTP裂解物的最终浓度。50ul的反应用120pg/ul的最终浓度的保真度报告构建体(SEQ ID NO:18)组装。在循环期间使用了5分钟的延伸时间。为了去除未通过PCR被DNA聚合酶变体扩增的背景DNA,剩余的甲基化全长报告质粒PCR模板(SEQ ID NO:18)通过添加DpnI限制性内切酶,随后在37℃孵育15分钟而被片段化。
线性ssDNA PCR扩增子通过使用ZR-96DNA清洁和浓缩器(Zymo)的柱纯化来进行纯化。简言之,向50μl PCR反应中添加200μl供应的结合缓冲液,并按照制造商的方案处理样品。样品在10-50μl无核酸酶水中洗脱。
然后使纯化的线性扩增子在200μl连接反应中在20℃环化1小时,所述连接反应具有66mM Tris-HCl,pH 8.0、1mM ATP、10mM MgCl
环化的扩增子然后使用ZR-96DNA清洁和浓缩器(Zymo)进行纯化和浓缩。简言之,向200μl连接反应中添加600μl供应的结合缓冲液,并使用制造商的方案处理样品。样品在12μl无核酸酶水中洗脱。
环化的扩增子使用BTX
第二天,通过向380μl LB培养基中添加20μl过夜培养物对板进行传代培养,并在30℃伴随摇动地生长。孵育2小时后,将IPTG添加到每块板中至1mM的最终浓度。板在30℃伴随摇动地孵育40-72小时,以允许野生型dsRed蛋白的诱导和完全成熟。诱导的培养物通过离心来沉淀,倾析上清液,并通过涡旋使细胞重悬于400μl的1x PBS中。细胞在PBS中进一步稀释100倍,用于流式细胞术分析。
除非下文的表格中另有指示,否则细胞使用带有自动进样器的ACCURI
实施例5
聚合酶保真度的相对比较
使用高通量流式细胞术测定,将变体DNA聚合酶的错误率与用于PCR的商购可得的DNA聚合酶的错误率进行比较。来自本研究的变体聚合酶用于扩增保真度报告质粒,并如实施例4描述地进行测定。商购可得的聚合酶用于使用随聚合酶一起供应的缓冲液(不添加镁)扩增报告构建体,并根据制造商对4.5kb质粒模板的建议使用热循环时间和温度。表5.1列出了每种聚合酶所用的缓冲液、dNTP的浓度、退火温度和延伸时间。计算每个样品相对于PLATINUM SUPERFI
实施例6
多于一种聚合酶性状的同时筛选
基于来自质粒和基因组DNA模板的不同大小和GC含量的扩增子的扩增,选择了跨越一系列应用而稳健的聚合酶性能。后续轮的筛选在缓冲液M6a中进行,缓冲液M6a为:30mMTris pH 8.8、10mM(NH
实施例7
下一代测序中覆盖的均匀性
微生物基因组的全基因组测序用于测试下一代测序应用中经扩增的文库的覆盖的均匀性。在这些实验中使用来自两种细菌(表皮葡萄球菌(ATCC 12228:2.5MB,32.1%GC)和类球红细菌(ATCC 17025:3.22MB,68.5%GC))的基因组DNA。来自每种生物体的DNA使用声处理(Covaris)剪切至400bp的平均片段长度。然后,使用KAPA加双索引衔接子(dual-indexed adapters),根据制造商的说明(Roche;产品KR0961),将100ng基因组DNA用作KAPAHyper文库制备工作流程的输入。使用MagBio HighPrep
尽管已经参考具体的实施方案描述了本发明,可以做出各种改变并且可以替换等同物以适应特定的情况、材料、物质的组成、一个或更多个方法步骤(process step orsteps),从而实现本发明的益处,而不偏离所要求保护的范围。
出于在美国的所有目的,本公开内容中引用的每一个和每个出版物和专利文件通过引用并入本文,如同每个这样的出版物或文件被明确和单独指出通过引用并入本文。出版物和专利文件的引用不意图指示任何这样的文件是相关的现有技术,也不构成对其内容或日期的承认。
- 工程化DNA聚合酶变体
- 高保真Pfu DNA聚合酶突变体、其编码DNA及其在NGS中的应用