一种显微影像下目标精确识别和分割的方法及其系统
文献发布时间:2023-06-19 12:22:51
技术领域
本发明涉及计算机视觉图像处理,显微影像分析等技术领域,特别是一种显微影像下目标精确识别和分割的方法及其系统。
背景技术
显微影像中目标识别在生物学和医学中具有重要的应用。现有显微影像分析主要依赖人工判断,耗时耗力。如染色体核型分析需要识别并将所有46条染色体进行排列,而血液细胞检查需要对多个视野下的所有类别骨髓细胞识别并求统计平均。
人工分析方法是最直接的一种,然而由于显微影像下单个视野通常存在几十到上百个目标,而每次分析往往需要统计多个视野实现统计意义上的精确,非常耗时耗力。而由于目标往往聚在一起,使得一些细微病变特征难以有效发现。
现有技术存在如上诸多问题,亟待解决。
发明内容
本发明目的在于提供一种显微影像下目标精确识别和分割的方法及其系统,用于基于深度学习目标检测和语义分割进行显微影像中单个目标识别和高质量再现,解决人工进行显微影像目标识别和精细判断费时费力的难题。
为了达成如上目的,本发明提供一种显微影像下目标精确识别和分割的方法,包括:
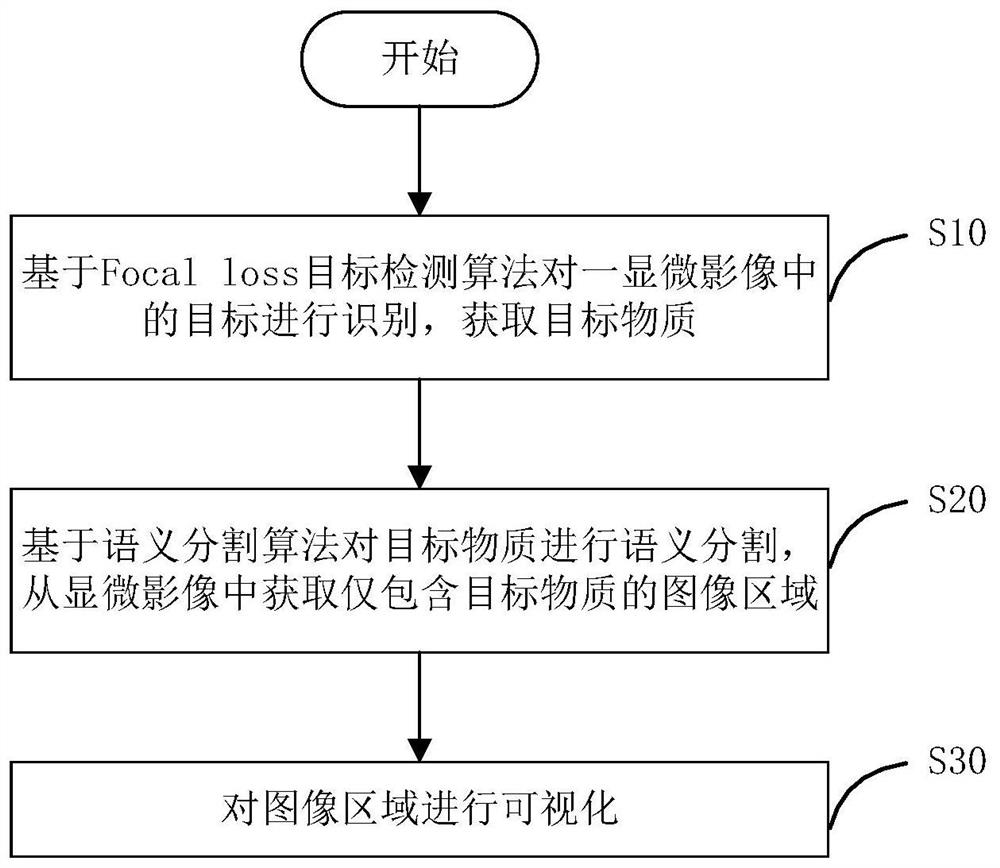
步骤一,基于Focal loss目标检测算法对一显微影像中的目标进行识别,获取目标物质;
步骤二,基于语义分割算法对所述目标物质进行语义分割,从所述显微影像中获取仅包含所述目标物质的图像区域;及
步骤三,对所述图像区域进行可视化。
所述的方法,其中,在所述步骤一执行前,进一步包括:对所述显微影像进行统一预处理的步骤。
所述的方法,其中,所述统一预处理的方式为对所述显微影像以50%的概率使用随机翻转,在-5°和5°之间随机旋转以及随机明暗度和对比度变化的方式进行处理。
所述的方法,其中,所述步骤一中,所述基于Focal loss目标检测算法对一显微影像中的目标进行识别的步骤包括:
构建用于目标区域检测的网络模型;
依据该网络模型对该显微影像进行识别,获取候选矩形框;
根据该候选矩形框得到目标物质对应的矩形框。
所述的方法,其中,所述步骤二中,所述基于语义分割算法对所述目标物质进行语义分割的步骤包括:
通过在标准Unet中加入deep supervision的方式构建语义分割网络;
将交叉熵损失函数与bias-dice损失函数相结合获取损失函数;
依据该语义分割网络与该损失函数对所述目标物质进行语义分割。
为了达成如上目的,本发明还提供一种显微影像下目标精确识别和分割的系统,包括:
目标识别模块,用于基于Focal loss目标检测算法对一显微影像中的目标进行识别,获取目标物质;
语义分割模块,用于基于语义分割算法对所述目标物质进行语义分割,从所述显微影像中获取仅包含所述目标物质的图像区域;及
可视化模块,用于对所述图像区域进行可视化。
所述的系统,其中,还包括:一预处理模块,用于对所述显微影像进行统一预处理。
所述的系统,其中,所述预处理模块对所述显微影像以50%的概率使用随机翻转,在-5°和5°之间随机旋转以及随机明暗度和对比度变化的方式进行处理。
所述的系统,其中,所述目标识别模块进一步包括:
模型构建模块,用于构建用于目标区域检测的网络模型;
区域预测模块,用于依据该网络模型对该显微影像进行识别,获取候选矩形框;
目标区域模块,用于根据该候选矩形框得到目标物质对应的矩形框。
所述的系统,其中,所述语义分割模块进一步包括:
分割网络模块,用于在标准Unet中加入deep supervision的方式构建语义分割网络;
损失函数模块,用于将交叉熵损失函数与bias-dice损失函数相结合获取损失函数;
分割模块,用于依据该语义分割网络与该损失函数对所述目标物质进行语义分割。
与现有技术相比,本发明技术效果在于:
1.本发明利用基于Focal Loss的目标检测算法对显微影像中目标进行定位以及类别判断,解决样本不平衡对检测精度的影响。
2.本发明提取每一个矩形框对应的图像区域,利用语义分割算法,将仅包含目标物质部分的图像区域分割出来进行可视化,从而省去了医生手动进行抠图的操作,节省了医生的时间和精力。而将单个目标呈现更有利于医生观察到目标细微病变,提高诊断精度。
附图说明
图1是本发明的显微影像下目标精确识别和分割的方法流程图;
图2是本发明的显微影像下目标精确识别和分割效果图;
图3是本发明加入deep supervision结构的标准Unet示意图;
图4是本发明的显微影像下目标精确识别和分割的系统结构图。
具体实施方式
以下结合附图和具体实施例对本发明进行详细描述,但不作为对本发明的限定。
如图1所示,是本发明的显微影像下目标精确识别和分割的方法流程图。
在进行生物医学影像的研究过程中,显微影像中的识别和精细分割是一个共性需求。如研究细胞生物学现象需要对细胞器进行精细识别并判断出异常情况,在进行染色体核型分析时需要计数单条染色体并将单条染色体精细分割出呈现到报告里,在血液检查中进行骨髓细胞分析时需要对单视野下的细胞类别进行统计。
这些过程目前主要依赖于人工分析,效率低下。经过研究发现,这一缺陷可以用深度学习目标检测及分析方法来实现。在调研深度学习算法时,将Focal Loss与当前主要的深度学习目标检测模型很好地结合,解决样本不平衡对检测精度的影响。在对分割模型损失函数设计中可以通过调节显微影像中对目标精确度和召回度的惩罚程度来提高可视化效果。
本发明选用Focal Loss应用在深度学习目标检测框架下,保证模型应对样本不平衡情况下的准确识别。应用Bce-bias-dice loss使得模型对遗漏预测的像素点增加惩罚,从而保证可视化图上尽可能多地保留样本的原有信息。
因此,本发明提出的基于目标检测和语义分割算法的显微影像诊断方法,主要目的是为了利用深度学习技术帮助医生,完成显微影像目标物质的检测和分割这种繁琐的工作,节省医生的时间和精力。在图1所示的流程图中,包括如下步骤:
步骤10,基于Focal loss目标检测算法对一显微影像中的目标进行识别,获取目标物质;
在一实施例中,该步骤需要先对输入的显微影像进行统一预处理,再利用基于Focal loss的目标检测算法对显微影像图中的目标进行精确识别。目标检测算法在标定目标物质的位置及大小的同时进行分类,确定每种目标物质所属的类别。
步骤20,基于语义分割算法对目标物质进行语义分割,从显微影像中获取仅包含目标物质的图像区域;
在一实施例中,该步骤在目标检测过程完成之后,每个目标物质所对应的矩形框将会被检测出来。本发明将每一个矩形框对应的图像区域提取出来,利用语义分割算法,将仅包含目标物质部分的图像区域分割出来进行后续的可视化,从而省去了医生手动进行抠图的操作,节省了医生的时间和精力。而将单个目标呈现更有利于医生观察到目标细微病变,提高诊断精度。
步骤30,对图像区域进行可视化。
该方法首先完成目标检测算法和语义分割算法的训练,之后应用训练好的模型,可以预测出显微影像图中目标物质的类别,并将其分割出来,如图2所示。
下面结合图1、2,结合一实施例对本发明的显微影像下目标精确识别和分割的方法作进一步说明,主要包含以下四个步骤:
步骤100,对训练数据进行预处理。
对于所有图片,首先使用高斯滤波,过滤掉图片中的一些噪声,从而减少由图像噪声带来的误差。对于训练图片,本发明以50%的概率使用随机翻转,在-5°和5°之间随机旋转以及随机明暗度和对比度变化的方式对其进行处理,从而达到数据增广的效果。
步骤200,构建目标检测模型。
(201)VarifocalNet网络
VarifocalNet网络,简称VFNet,是一种基于FPN模型,用于目标区域检测的网络结构。该模型使用VarifocalNet网络预测得到目标区域的候选矩形框(bounding box)。
在计算候选矩形框与gt框(ground-truth)的近似程度,即预测的准确性时,采用Intersection over Union(IoU),其具体计算方法如下:
其中,IoU(A,B)指A与B的重叠程度,它反映模型预测的准确性,A、B分别对应预测的候选矩形框区域以及gt框区域。
传统目标检测的方法的分类得分往往难以准确衡量预测质量。预测准确的候选框置信度S较低,而使得在非极大值抑制(Non-Maximum Suppression)时不被选中。
采用VarifocalNet网络,将目标位置的质量预测与分类得分相结合,使用IoU相关的分类得分(IACS,IoU-aware classification score)作为检测得分。
网络训练采用的损失函数为Varifocal Loss,根据Focal Loss演化而来。FocalLoss对正负样本的处理相同。而VarifocalNet网络中对Focal Loss进行修正,其表达形式如下:
其中,VFL(p,q)即VarifocalNet网络的损失,p是预测的IACS分数,α是负样本的加权权重,q是目标的IoU得分,即在正样本中q是gt框与预测的候选矩形框的IoU,而在负样本中q为0,r是指Focal Loss的衰减系数,通常大于1。Varifocal Loss中仅对负样本使用p
在该模型中,候选矩形框具体采用星型包围框(star-shaped bounding box)的表现形式,用于预测目标区域。使用9个固定的采样点。具体表现为给定一个采样点(x,y),x,y为采样点的坐标,使用一个3×3卷积回归得到候选矩形框,星型包围框编码为四维向量(l′,t′,r′,b′),分别表示该采样点到四条边的距离,随后启发式选取9个(x,y),(x,y+b′),(x,y-t′),(x+r′,y),(x+r′,y+b′),(x+r′,y-t′),(x-l′,y),(x-l′,y+b′),(x-l′,y-t′)。由于这些点是通过人为设定,直接计算得到,不需要增加预测负担,计算效率较高。
对于星型包围框的更新,是一个残差学习的问题。训练过程中学习4个距离的缩放因子(Δl,Δt,Δr,Δb),用于改变初始星型包围框的区域,具体更新变现为四维向量(l,t,r,b)=(Δl×l′,Δt×t′,Δr×r′,Δb×b′),分别表示该采样点到四条边的距离,使得更新后的星型包围框与gt框更接近。
(202)Faster R-CNN网络
本发明对多种目标检测网络具有兼容性。目标检测网络同样可以采用Faster R-CNN网络。Faster R-CNN可看作RPN网络和Fast R-CNN网络的结合。
Faster R-CNN网络使用RPN网络(Region Proposal Network)代替SelectiveSearch方法产生矩形框,计算速度上提高了10倍。经过一系列卷积层、池化层后得到的特征图(Feature map)上每个特征点映射回原图中的感受野的中心点,作为一个基准点。基于每个基准点会选取多个不同面积、长宽比的候选框。其中面积选取3种,分别为{128
Faster R-CNN网络中训练数据的采样使用IoU得分作为依据。样本分为正样本和负样本,其中正样本的选取为候选矩形框与gt框的IoU值大于0.7的样本,若没有大于0.7的样本,则选取得分最大的样本作为正样本;负样本则是与所有gt框的IoU值都小于0.3的候选矩形框。其他样本被丢弃。
训练RPN网络需要训练分类任务与回归任务。总损失为两部分损失函数的线性加权求和。
分类任务的损失函数采用Focal Loss,形式如下:
其中,L
回归任务的损失函数采用的形式如下:
对任意x,定义
其中,L
回归任务的损失采用目标检测模型中常用的
其中,下标a表示模版框(anchor),上标*表示真实目标矩形框,t
RPN网络的完整损失函数为上述两个任务损失函数的加权求和,具体表示如下:
其中,L({p
在Fast R-CNN网络部分,Faster R-CNN网络使用RPN网络预测得到的候选矩形框,通过RoI Pooling感兴趣区域池化(Region of Interest)下采样到相同大小的特征,具体为7×7的特征图,将特征图展平处理后再经过一系列全连接层得到预测结果。对得到的特征向量进行分类预测和回归预测。两部分与RPN网络的分类回归任务计算方法类似。具体损失函数表达如下:
L(p,u,t
其中,L(p,u,t
由于RPN网络和Fast R-CNN网络均需要使用CNN网络提取图像特征,在Faster R-CNN网络中,这两部分共用一个特征提取网络。共享CNN网络部分权值。
如上有关步骤200的描述是基于Focal loss目标检测算法对一显微影像中的目标进行识别的过程,在实际进行目标检测过程中,VarifocalNet网络重点通过Focal loss来降低负样本的权重,在本发明中主要用于单类目标检测;而对于多类目标检测,本发明则采用基于Focal Loss的Faster R-CNN网络,效果更好。
步骤300,构建语义分割网络。
本发明的语义分割网络部分主要是在UNet上进行改进,并设计新的损失函数。
(301)加入deep supervision的UNet
在标准的UNet中,模型被分为编码器和解码器两部分。编码器接收原图,并逐层进行卷积和下采样操作,从而将原图编码成为多个特征图。解码器则接收编码器的结果,并逐层融合和上采样,最终得到分割结果。通过编码器解码器模型,网络可以处理多尺度特征,并产生边缘平滑的分割结果。
本发明是在标准的UNet加入了deep supervision结构,对于每一层解码器的输出,都将其上采样并卷积成为预测的分割结果,然后将其与标签计算损失,将各个层次的损失值加起来得到最终的损失值。其结构如图3。
为了量化分割结果,本发明使用mean dice指标对结果进行评价,其计算公式如下:
此处A、B分别对应预测的像素区域以及真实标注像素区域。
在实现过程中,分割网络接收大小为512*512的图片作为输入,并在每个下采样层利用卷积池化,使其特征图的长宽减半,通道数加倍,从而逐渐增加感受野。在每个上采样层,结合编码器传入的特征图并利用卷积和双线性插值,使得特征图长宽加倍并逐渐恢复为原图大小。每层特征图的尺寸如下:
其中,Downsample1~Downsample4指经过四次下采样后对应特征层的大小,Upsample1~Upsample3指经过四次上采样后对应特征层的大小,详见图3。
通过多个不同尺度特征层的分析,模型能更加有效地提取不同尺度的特征,提高分割准确率。
(302)Bce-bias-dice损失函数
Bias-dice损失函数如下:
在Bias-dice损失函数中,p
Bias-dice损失函数虽然能够让模型更多保留前景信息,增强可视化效果。但是,Bias-dice损失函数由于刻意减小了假阳性的惩罚,而另一方面大部分显微影像分析中背景占主体部分,这造成单独使用Bias-dice损失函数会对背景部分预测不对的惩罚性不够,带来训练不够稳定,损失值波动性较大的缺点。针对这一问题,本发明将交叉熵损失函数与Bias-dice损失函数相结合后的Bce-bias-dice损失函数,从而解决了Bias-dice损失函数不够稳定的问题,最终的损失函数如下。
本发明提出的Bce-bias-dice损失将作为基于deep supervision结构的UNet的损失函数。
采用本发明如上方法后的技术效果体现在如下方面:
1.本发明利用基于Focal Loss的目标检测算法对显微影像中目标进行定位以及类别判断,在Kaggle 2018data science bowl细胞核分割公开数据集上进行实验,该公开数据集共有670张图片。按照6:4将其划分为训练集和测试集,得到402张图片作为训练数据,268张图片作为测试数据。在测试集上mAP达到了66.68。
2.本发明利用深度学习语义分割算法对检测出的目标进行语义分割,将原图进行切割处理后,得到41363张子图。按照6:4将其划分为训练集和测试集,得到29372张图片作为训练数据,11991张图片作为测试数据。在测试集上mean dice达到93.08。
如图4所示,是本发明的显微影像下目标精确识别和分割的系统示意图。
在图4中,系统400包括:
目标识别模块41,用于基于Focal loss目标检测算法对一显微影像中的目标进行识别,获取目标物质;
语义分割模块42,用于基于语义分割算法对目标物质进行语义分割,从所述显微影像中获取仅包含目标物质的图像区域;及
可视化模块43,用于对图像区域进行可视化。
进一步地,系统400还包括:预处理模块40,用于对显微影像进行统一预处理,即对显微影像以50%的概率使用随机翻转,在-5°和5°之间随机旋转以及随机明暗度和对比度变化的方式进行处理。
进一步地,该目标识别模块41包含:
模型构建模块411,用于构建用于目标区域检测的网络模型;
区域预测模块412,用于依据该网络模型对该显微影像进行识别,获取候选矩形框;
目标区域模块413,用于根据该候选矩形框得到目标物质对应的矩形框。
上述显微影像下目标精确识别和分割实施例中的目标识别方式同样适用于目标识别模块41。
进一步地,该语义分割模块42包含:
分割网络模块421,用于在标准Unet中加入deep supervision的方式构建语义分割网络;
损失函数模块422,用于将交叉熵损失函数与bias-dice损失函数相结合获取损失函数;
分割模块423,用于依据该语义分割网络与该损失函数对所述目标物质进行语义分割。
上述显微影像下目标精确识别和分割实施例中的语义分割方式同样适用于语义分割模块42。
与现有技术相比,本发明提供了一种显微影像下目标精确识别和分割的方法,其是基于深度学习的显微影像普适分析方法,能基于深度学习目标检测和语义分割进行显微影像中单个目标识别和高质量再现,解决人工进行显微影像目标识别和精细判断费时费力的难题。
当然,本发明还可有其它多种实施例,在不背离本发明精神及其实质的情况下,熟悉本领域的技术人员当可根据本发明做出各种相应的改变和变形,但这些相应的改变和变形都应属于本发明所附的权利要求的保护范围。
- 一种显微影像下目标精确识别和分割的方法及其系统
- 基于有限场景下大目标语义分割模型的轨行区识别方法