一种基于预训练模型的安全事件实体识别方法
文献发布时间:2023-06-19 12:22:51
技术领域
本发明属于人工智能自然语言处理技术领域,涉及一种基于预训 练模型的安全事件实体识别方法。
背景技术
随着我国在经济快速发展,城市中各种各样的安全突发事件也在 不断增多,这些公共安全突发事件给当事人和救援人的生命财产安全 造成严重威胁,也对我国经济和民众生活带来很大的影响。因此,公 共安全应急管理亟待加强。但是,现阶段公共安全事件舆情中的知识 与信息不能有效地抽取和复用,无法为公共安全事件管理提供充分的 协助和预警。
近几年,人工智能的发展成为了行业重要的发展方向,其中自然 语言处理作为该领域的重要研究方向,其研究成果已经应用于医疗、 法律、金融等行业中,大大提高了领域智能化水平。但是,公共安全 事件领域中也存在大量的案例文本信息,在现有的自然语言处理研究 领域,对中文公共安全事件的研究处于起步阶段。本发明借鉴已有行 业的中文自然语言处理方法分析公共安全事件实例文本信息特征。以 公开的中文突发事件语料中的实体和关系等信息提取作为研究重点 进行深入研究,目的是为了将公共安全事件实例信息化,能够更好的 进行知识表示,存储规范中的语义信息,构建公共安全事件领域知识图谱。该图谱可以用于事故案例快速检索,事故关联路径分析及统计 分析等,从而提高我国公共事件管理水平,加强公共安全应急管理体 系建设。
发明内容
本发明的目的是提供一种基于预训练模型的安全事件实体识别 方法,能够解决现有安全事件领域信息无法有效抽取的问题。
本发明所采用的技术方案是,基于预训练模型的安全事件实体识 别方法,首先在对原始的RoBERTa模型进行任务二次预训练优化过 程中,加入公共安全领域词典的全词Mask机制,使 PreTrain100K+RoBERTa
具体包括以下步骤:
步骤1,从github直接获取CEC数据集及及说明文件;
步骤2,CEC数据集共有332条公共安全事件实例,采用了XML 语言作为标注格式对CEC数据集进行标注,其中包含了六个最重要 的数据标签:Event、Denoter、Time、Location、Participant和Object; Event用于描述事件;Denoter、Time、Location、Participant和Object 用于描述事件的指示词和要素,根据XML标签的不同利用python语言提取标注的实体,构建安全事件实体词典。
步骤3,针对步骤2数据文本中Denoter、Time、Location、 Participant和Object五个标签进行命名实体识别研究,将标签分别简 记为DEN、TIME、LOC、PAR、OBJ,分别表示行为、时间、位置、 参与者和对象。
步骤4,对步骤1中原始未标注的CEC数据集以安全事件实例 数目对文档进行划分,在332条数据集中随机选取30条规范作为验 证集;然后对332条数据集按7:3的比例划分选取训练集、测试集进 行实验,训练集232条实例,测试集100条实例。
步骤5,对步骤4中划分的训练集和验证集进行BIO标注,构建 用于命名实体识别任务的安全事件数据集,数据文件中为两列信息, 单字符与相对应标签为一行的格式;
步骤6,构建领域预训练数据集;从互联网中获取100K条未标 注的新闻领域语料,进行数据清洗,删除语料中多余的符号及冗余信 息,对预训练数据进行格式上的统一处理。
步骤7,构建中文预训练语言模型,将步骤5中得到的新闻领域 预训练数据集输入到本发明提出的PreTrain100K+RoBERTa
步骤8,构建实体识别模型,将步骤7中生成的预训练语言模型 和动态字向量作为实体识别模型的输入;
步骤9,设置训练的实体识别模型作为服务端测试模型效果, 将测试数据集输入模型,输出测试数据的实体类别标签,最终实现公 共安全事件文本中命名实体的自动识别。
步骤2中,构建了安全事件实体词典,并将词典融合到预训练模 型中,提高下游命名实体识别模型的效果。
本发明使用无标注新闻领域数据对RoBERTa进行领域二次预训 练,在大规模无标注的语料上采用自监督的方式训练语言模型,将得 到的语言模型连接下游任务模型进行微调。
步骤7的具体过程如下:
步骤7.1,采用全词Mask机制,如果一个完整的词的部分子词 被Mask,则同属该词的其他部分也会被Mask,这更符合中文语法习 惯,使模型能够更好的学习中文语言表述方式。
步骤7.2,将步骤2中构建的CEC安全事件实体词典,引入到 RoBERTa模型的分词函数中使其能后在Mask机制预测时保留公共安 全事件文本实体完整的语义。
步骤7.3,将100K的新闻领域预训练数据和安全事件实体词典 输入进模型,设置训练迭代次数为100000次,得到安全事件领域的 预训练模型PreTrain100K+RoBERTa
步骤8的具体过程如下:
步骤8.1,将构建的CEC实体训练集输入到经过领域二次训练的 PreTrain100K+RoBERTa
步骤8.2,PreTrain100K+RoBERTa
步骤8.3,将文本特征向量输入到BiLSTM-CRF模型中,生成 PreTrain100K+RoBERTa
步骤8.3中,对轨道交通规范语料进行实体预测标注,具体步骤 如下:
步骤8.3.1,以安全事件实例中“工业区发生中毒事件”为例, 利用具有新闻领域语义能力的预训练模型对训练集向量化表示;将 “工业区发生中毒事件”中的每一个词都训练得到一个768维向量, 得到每个词的初始化向量,然后将结果作为深度学习模型的输入;
步骤8.3.2,使用深度学习中的BiLSTM-CRF算法,双向LSTM 同时考虑了过去的特征和未来的特征,一个正向输入序列,一个反向 输入序列,预测词在上下文中的语义。比如输入“工”后BiLSTM会 预测下一个词是“业”的概率,然后输入“工业”预测下一个词“区” 出现的概率,这是正向输入。当反向输入序列时,预测“中毒事件” 一词前可能出现“发生”的概率,再将两者的输出结合起来作为最终 的结果输入到下一层;
步骤8.3.3,将步骤8.3.2得到的特征矩阵作为CRF的输入,CRF 通过添加特征函数和BiLSTM得到的特征矩阵进行序列标注,生成实 体识别模型;该模型能够识别安全事件领域的实体。
本发明的有益效果是:
本发明以《中文突发事件语料库》为例研究公共安全领域的实体 识别方法。本发明提出的方法是对RoBERTa模型进行二次领域预训 练,使用未标注的公开新闻领域数据集进行训练,通过自监督学习从 大规模数据中获得与具体任务相关的预训练模型,提取一个词在一个 特定上下文中的语义表征,使模型具备命名实体识别的能力。首先将 其训练的语言模型以及输出的动态词向量作为下游命名实体识别任 务的输入进行微调,针对具体领域数据修正网络。命名实体识别任务 将采用BiLSTM模型获取公共安全实例文本的上下文抽象特征,结合 条件随机场CRF进行序列解码标注实体类别,最终实现公共安全事 件文本中命名实体的自动识别。采用本发明基于预训练模型的安全事 件实体识别方法将提高公共安全事件实例信息化水平,能够更好的进 行知识表示,存储文本语料中的语义信息,构建公共安全事件领域知 识图谱。该图谱可以用于事故案例快速检索,事故关联路径分析及统 计分析等,从而提高我国公共事件管理水平,加强公共安全应急管理 体系建设。
附图说明
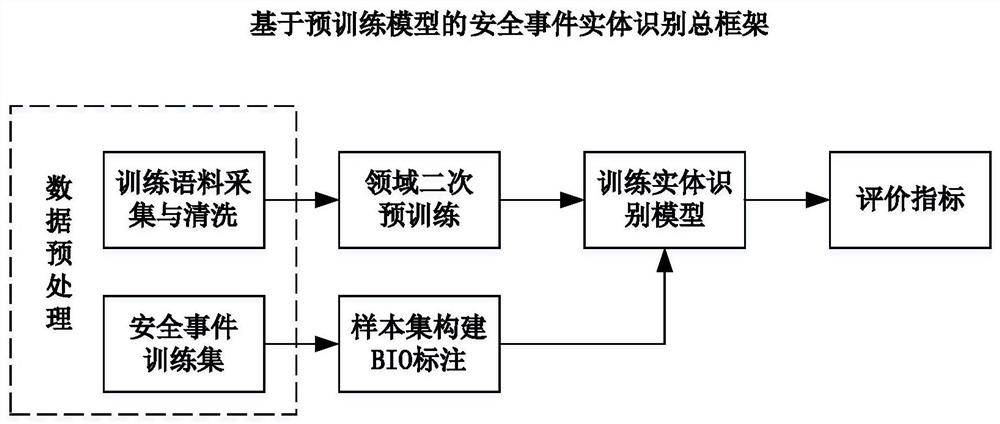
图1是本发明基于预训练模型的安全事件实体识别方法总框架 图;
图2是本发明基于预训练模型的安全事件实体识别方法的总流 程图;
图3是本发明基于预训练模型的安全事件实体识别方法中 RoBERTa预训练模型结构示意图;
图4是本发明基于预训练模型的安全事件实体识别方法中BiLSTM模型结构示意图;
图5是本发明基于预训练模型的安全事件实体识别方法中CRF 模型结构示意图;
图6是本发明基于预训练模型的安全事件实体识别方法中 PreTrain100K+RoBERTa
图7是本发明基于预训练模型的安全事件实体识别方法中 PreTrain100K+RoBERTa
具体实施方式
下面结合附图和具体实施方式对本发明进行详细说明。
本发明的目的提供一种基于预训练模型的安全事件实体识别方 法,具体框架如图1所示。提出了改进的命名实体识别模型 PreTrain100K+RoBERTa
-BiLSTM-CRF。在对原始的RoBERTa模型进行领域二次预训练 优化过程中,加入公共安全领域词典的全词Mask机制,使 PreTrain100K+RoBERTa
本发明一种基于预训练模型的安全事件实体识别方法,参照图2, 具体包括以下步骤:
步骤1,本发明的实验语料来源于由上海大学语义智能实验室构 建的《中文突发事件语料库》,简称为CEC数据集。从github可以直 接获取数据集及及说明文件。
步骤2,CEC数据集共有332条公共安全事件实例,采用了XML 语言作为标注格式,其中包含了六个最重要的数据标签:Event、 Denoter、Time、Location、Participant和Object。Event用于描述事件; Denoter、Time、Location、Participant和Object用于描述事件的指示 词和要素。根据XML标签的不同利用python语言提取标注的实体, 构建安全事件实体词典。
步骤3,本发明将针对数据文本中Denoter、Time、Location、 Participant和Object五个标签进行命名实体识别研究,将标签分别简 记为DEN、TIME、LOC、PAR、OBJ,分别表示行为、时间、位置、 参与者和对象,其详细信息如表1所示:
表1待预测标签
步骤4,本实验数据以安全事件实例数目对文档进行划分,在332 条数据集中随机选取30条规范作为验证集,并对整个数据集按7:3 的比例划分选取训练集、测试集进行实验,训练集232条实例,测试 集100条实例。
步骤5,对步骤4中划分的训练集和验证集进行BIO标注,构建 用于命名实体识别任务的安全事件数据集,数据文件中为两列信息, 单字符与相对应标签为一行的格式。
步骤6,构建领域预训练数据集。从互联网中获取100K条未标 注的新闻领域语料,进行数据清洗,删除语料中多余的符号及冗余信 息,对预训练数据进行规范化处理。格式如下:
{"text":""}
{"text":""}
步骤7,构建中文预训练语言模型,模型结构如图3所示。将步 骤5中得到的新闻领域预训练数据集输入到本发明提出的 PreTrain100K+RoBERTa
步骤7.1,本发明采用全词Mask机制,如果一个完整的词的部 分子词被Mask,则同属该词的其他部分也会被Mask,这更符合中文 语法习惯,使模型能够更好的学习中文语言表述方式,具体方式如表 2所示。
表2全词Mask
步骤7.2,将步骤2中构建的CEC安全事件实体词典,引入到 RoBERTa模型的分词函数中使其能后在Mask机制预测时保留公共安 全事件文本实体完整的语义,模型结构如图6所示。
步骤7.3,将100K的新闻领域预训练数据和安全事件实体词典 输入进模型,设置训练迭代次数为100000次,得到安全事件领域的 预训练模型PreTrain100K+RoBERTa
步骤8,构建实体识别模型,将步骤7中生成的预训练语言模型 和动态字向量作为实体识别模型的输入。
步骤8.1,将构建的CEC实体训练集输入到经过领域二次训练的 PreTrain100K+RoBERTa
步骤8.2,PreTrain100K+RoBERTa
步骤8.3,将文本特征向量输入到BiLSTM-CRF模型中,生成 PreTrain100K+RoBERTa
对轨道交通规范语料进行实体预测标注,具体步骤如下:
步骤8.3.1,以安全事件实例中“工业区发生中毒事件”为例, 利用具有新闻领域语义能力的预训练模型对训练集向量化表示;将 “工业区发生中毒事件”中的每一个词都训练得到一个768维向量, 得到每个词的初始化向量,然后将结果作为深度学习模型的输入。
步骤8.3.2,使用深度学习中的BiLSTM-CRF算法,双向LSTM 同时考虑了过去的特征和未来的特征,一个正向输入序列,一个反向 输入序列,预测词在上下文中的语义。比如输入“工”后BiLSTM会 预测下一个词是“业”的概率,然后输入“工业”预测下一个词“区” 出现的概率,这是正向输入。当反向输入序列时,预测“中毒事件” 一词前可能出现“发生”的概率,再将两者的输出结合起来作为最终 的结果输入到下一层。
步骤8.3.3,将步骤8.3.2得到的特征矩阵作为CRF的输入,CRF 通过添加特征函数和BiLSTM得到的特征矩阵进行序列标注,生成实 体识别模型;该模型能够识别安全事件领域的实体。
步骤9,设置训练的实体识别模型作为服务端测试模型效果, 将测试数据集输入模型,可输出测试数据的实体类别标签,最终实现 公共安全事件文本中命名实体的自动识别。
步骤10,统计实体识别模型自动识别的正确和错误的文本数量, 采用准确率(Precision)、精确率(Accuracy),召回率(Recall)和F1值作 为评价命名实体识别模型的指标。
命名实体识别的评价标准主要是判断实体的边界是否正确,实体 的类型是否标注正确。在预测过程中,只有当实体标签的类型中边界 的类型与预定义的实体类型完全正确时,才判断该实体预测正确。命 名实体识别的评价指标有准确率(Precision)、精确率(Accuracy),召回 率(Recall)和F1值。具体公式为:
其中,TP(True Positive)代表被判定为正样本,实际为正样本的个 数;TN(TrueNegative)代表被判定为负样本,实际为负样本的个数;FP(False Positive)代表被判定为正样本,实际为负样本的个数; FN(False Negative)代表被判定为负样本,实际为正样本的个数。
- 一种基于预训练模型的安全事件实体识别方法
- 一种基于聚类与预训练模型结合的命名实体识别方法