一种多机器人轨迹规划方法
文献发布时间:2023-06-19 12:24:27
技术领域
本发明涉及多机器人协同控制技术领域,具体涉及一种多机器人轨迹规划方法。
背景技术
随着钢/铝等复杂构件行业的加工量和作业环境的不断变化,有些工作仅靠单机器人难以承担,需要通过多台机器人之间的协调配合才能完成,多机协同作业已取代单机成为构建智能产线的研究热点。多机器人系统相比于单机器人系统具有适应环境能力强、自我调节能力高、系统空间分布广、更好的数据冗余性、鲁棒性等特点。采用多机器人之间的协同合作,能够可靠地完成单机器人无法完成的高精度作业和高效加工。
焊接是一种潜在危险性高、强度大、熟练度要求高的工作。传统的机器人焊接工艺多采用手动示教生成焊接轨迹,不仅费时费力,精度也不高,而且受限于机器人有限的工作空间,难以实现复杂构件的三维任意复杂曲线焊接,迫切需要多台机器人之间的协同作业,即在同一个工位区域内,多个机器人分别对工件(即被焊接对象)进行协同夹持、搬运、翻转和焊接,实现相互配合作业,达到准时、同步、协调和高效的要求。
多机器人在工作空间大范围重叠的情况下,对于每个机器人的协同轨迹规划难度不小,采用传统的空间轨迹优化方法,较难得到最优解。面向复杂焊接任务,机器人焊接的空间三维复杂轨迹规划,不仅要保证多机器人系统不与环境中的障碍物有任何冲突,而且必须确保每台机器人之间保持给定的位置,尤其是在考虑机器人具有工作空间高度重叠时。
已有多机器人协作方案高度依赖于每个机器人的位置和速度等条件,传统的轨迹规划方法难以适应复杂和动态的系统和环境,因为每一个机器人都难以将其周围的机器人识别为障碍物或协作机器人。机器学习虽已应用于机器人控制、路径规划等,但大多数的研究,仅限于模拟仿真,遗传算法也有一些局限性需要加以弥补,应用于解决一个或多个任务的多机器人强化学习的轨迹规划研究相对欠活跃。
多机器人在工作空间高度重叠时,需要在同一工位区域内相互配合以实现对工件的夹持、搬运、翻转和焊接等操作,多机器人系统中的每一个机器人都必须独立动作,并与其他机器人加以协作。多机器人的协作方案高度依赖于每个机器人的位置和速度等条件,如何实现机器人协同执行复杂任务的高效性,满足空间三维复杂轨迹规划,是目前拟解决的关键问题。
发明内容
有鉴于此,为了解决现有技术中的上述问题,本发明提出一种多机器人轨迹规划方法,融合深度Q学习和卷积神经网络CNN算法,达到多台机器人能够相互协作且无干涉,从而实现多机器人的空间三维复杂轨迹规划。
本发明通过以下技术手段解决上述问题:
一种多机器人轨迹规划方法,包括如下步骤:
深度Q学习利用多机器人周围环境的状态分析出当前轨迹向量,设计深度Q学习的奖励网络,将当前轨迹向量和期望轨迹向量均作为奖励网络的输入,输出为奖励信息,用来对卷积神经网络CNN的参数进行训练;
卷积神经网络CNN算法利用多机器人周围环境的状态分析出当前轨迹向量,将当前轨迹向量作为卷积神经网络CNN的输入,基于所述奖励信息而训练好的卷积神经网络CNN采用卷积神经网络CNN算法输出相应的动作信息给环境信息;
再采用基于资源的多机器人任务分配算法,将工件的所有动作合理地分配给多台机器人,达到多台机器人能够相互协作且无干涉,从而实现多机器人的空间三维复杂轨迹规划。
进一步地,所述卷积神经网络CNN的基本结构为:输入层→卷积层→池化层→重复卷积层、池化层→全连接层→输出结果。
进一步地,当前轨迹向量将力求与期望轨迹向量一致。
进一步地,所述多机器人轨迹规划方法融合深度Q学习和卷积神经网络CNN算法,采用经验表示技术,在每个时间步长上发生的学习经验,通过将多个事件存储在数据集中,称为记忆再生;学习数据样本用于每次在重建的存储器中以一定的概率进行更新,通过重复使用经验数据并减少样本间的相关性。
进一步地,所述多机器人轨迹规划方法融合深度Q学习和卷积神经网络CNN算法,基于单个机器人分配角色的不同而使用经验数据,在开始学习之前,为每个机器人的角色设定不同的期望值,学习使补偿值总是增加;如果算法的搜索时间过长,则补偿值减小,并且执行学习以使搜索时间不增加;预处理部分采用卷积神经网络CNN查找异常值,后处理部分采用奇异点来学习数据;在预处理部分,利用输入图像来搜索图像的特征,并对这些特征进行采集和学习。
进一步地,在深度Q学习中,当机器人工作在一个离散的、受限的环境中时,它会在每个时间间隔内选择一组确定行为中的一个,并假设它处于马尔可夫状态,其状态变化为不同的概率;
P
式中,P
在每个时间间隔t内,机器人可从环境中获取状态s,然后再执行动作a
式中,
V
式中,R
Q
式中,Q(s
进一步地,在深度Q学习中,Q值在学习时是共享的,并用于学习机;为了优化Q值的更新,有必要定义一个目标函数,将其定义为目标值和Q值预测值的误差;目标函数如方程(5)所示:
式中,a为动作,a'为下一个所有可能的动作,获得损失函数的基本信息是转换
进一步地,在深度Q学习中,使用目标Q网络和Q网络两种,两种网络结构相同,仅权重参数不同;为了平滑深度Q学习中的收敛,目标网络不是连续更新,而是定期更新;采用均方根传递算法作为优化器,并根据参数梯度调整学习率;在训练集不断变化的情况下,不同于某些训练集的情况,有必要不断地改变参数。
进一步地,在多机器人任务分配算法中,机器人执行任务期间会持续消耗其资源,这些资源必须在运行期间重新填充;机器人会根据其资源水平,考虑访问资源站不同组合的所有可能性来计算任务性能,这样这使机器人能够减少任务期间不必要的时间和资源浪费。
与现有技术相比,本发明的有益效果至少包括:
本发明融合深度Q学习和卷积神经网络CNN算法,采用卷积神经网络CNN算法利用其周围环境的信息分析准确的位置,各机器人根据深度Q学习分析得到的位置进行动作,再通过基于资源的机器人任务分配方法,将工件的所有焊点合理地分配给多台焊接机器人,达到多台机器人能够相互协作且无干涉,从而实现多机器人的空间三维复杂轨迹规划,最终为多台机器人规划出最优的协同路径,使多个机器人能够相互协作且无干涉的发生,实现机器人协同执行复杂任务的高效性。
附图说明
为了更清楚地说明本发明实施例中的技术方案,下面将对实施例描述中所需要使用的附图作简单地介绍,显而易见地,下面描述中的附图仅仅是本发明的一些实施例,对于本领域普通技术人员来讲,在不付出创造性劳动的前提下,还可以根据这些附图获得其他的附图。
图1是本发明深度Q学习原理图;
图2是本发明卷积神经网络CNN的结构示意图;
图3是本发明融合深度Q学习和卷积神经网络CNN算法的轨迹规划流程图。
具体实施方式
为使本发明的上述目的、特征和优点能够更加明显易懂,下面将结合附图和具体的实施例对本发明的技术方案进行详细说明。需要指出的是,所描述的实施例仅仅是本发明一部分实施例,而不是全部的实施例,基于本发明中的实施例,本领域普通技术人员在没有做出创造性劳动前提下所获得的所有其他实施例,都属于本发明保护的范围。
多机器人在工作空间大范围重叠时,对每个机器人的协同轨迹规划难度较大。在传统的轨迹规划方法中,机器人需要搜索一个相对较宽的动作区域,并在给定的环境下以预先设计的路线移动。多机器人系统中的每一个机器人都必须独立动作,并与其他机器人协作,以获得优异的性能。此外,多机器人的协同方案高度依赖于每个机器人的位置和速度等条件。然而,传统的轨迹规划方法难以有效地处理各种情况,因为每一个机器人都难以将其周围的机器人识别为障碍物或协同的机器人。
为了弥补这些不足,针对复杂任务的多机器人轨迹规划问题,本发明研究多机器人轨迹规划中强化学习的信息和策略问题,提出一种通过强化学习使得机器人可快速到达目标点的方法。根据情况的不同,每个机器人可以被视为动态障碍物或协同的机器人。也就是说,系统中的每个机器人可以根据给定的任务执行独立的动作,同时相互协同。选择动作后,评估与目标的关系,并对每个机器人进行奖励或惩罚以开展学习。此时,强化学习就是一种深度Q学习(Deep Q-Learning,DQN),通过共享每个机器人的Q参数,耗费更少的轨迹搜索时间,可应用于多机器人的静态和动态环境中。
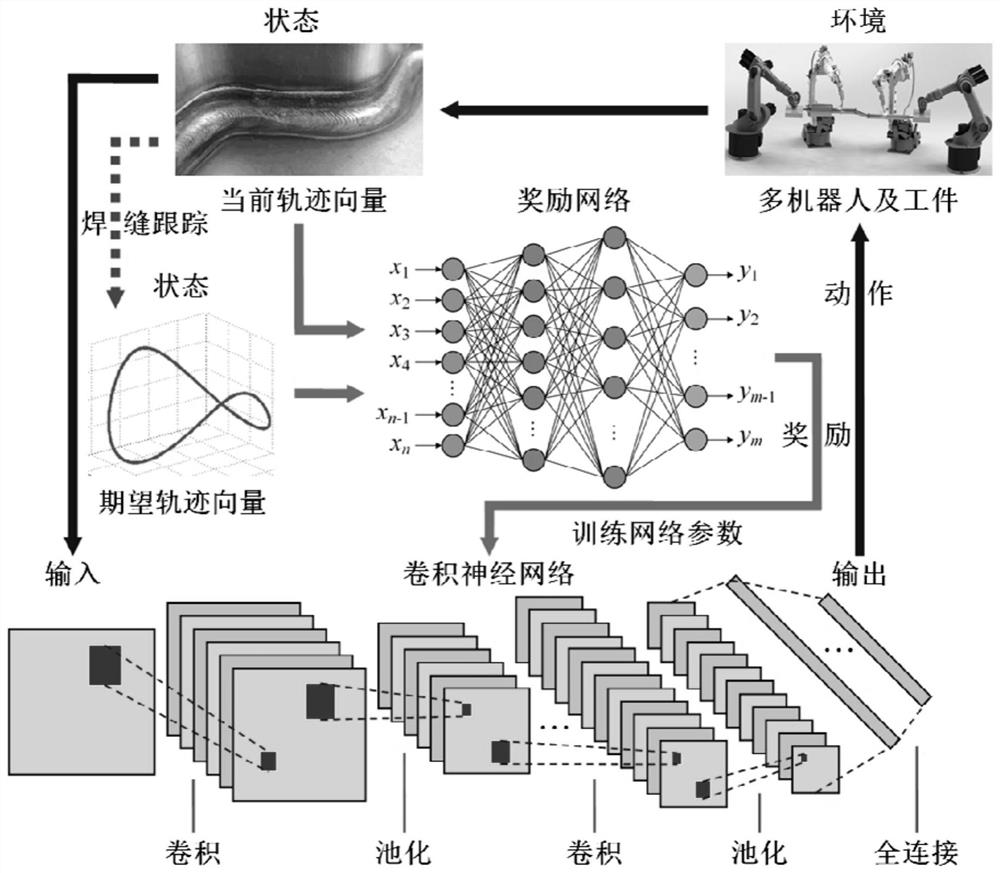
本发明基于深度Q学习的多机器人轨迹规划的原理,如图1。选择动作为输出的机器人通过识别环境并接收环境的状态,当状态被改变时,状态转换作为强化信号被传递给个体。选择单个机器人的行为,以便在较长一段时间内提升增强信号值的总和。动作的作用是为控制系统提供控制策略,多机器人协同夹持/搬运/翻转/焊接系统的最终目标是使得状态(多机器人协同作业)过程中无穷累积的奖励值趋于最大化,以实现环境(多机器人及工件))的最佳轨迹规划。
当机器人工作在一个离散的、受限的环境中时,它会在每个时间间隔内选择一组确定行为中的一个,并假设它处于马尔可夫(Markov)状态,其状态变化为不同的概率。
P
式中,P
在每个时间间隔t内,机器人可以从环境中获取状态s,然后再执行动作a
式中,
V
式中,R
Q
式中,Q(s
在多机器人轨迹规划中,现有方法难以适应复杂和动态的系统和环境,但可通过深度Q学习和卷积神经网络(Convolution Neural Networks,CNN)相融合,采用多机器人深度强化学习。1998年纽约大学杨立昆(Yann LeCun)提出的卷积神经网络CNN可以看作是神经认知机(Neocognitron)的推广形式,也是多层感知机(Multilayer Perceptron,MLP)的变种,多层感知机也叫人工神经网络(Artificial Neural Network,ANN),除了输入层和输出层,中间可以有多个隐藏层。
本发明采用的卷积神经网络CNN的基本结构为:输入层(Input Layer)→卷积层(Convolution Layer)→池化层(Pooling Layer)→(重复卷积层、池化层)→全连接层(Full Connected Layer)→输出结果(Output Layer),如图2所示。环境信息图像为2560×2000,输入层为2的整数倍,卷积层为16个,使用3×3的滤波器,池化层对卷积结果进行降低维度处理,全连接层为3个。
本发明融合深度Q学习和卷积神经网络CNN算法的轨迹规划流程,如图3所示。首先,设计奖励网络,将两个状态信息(当前轨迹向量、期望轨迹向量)均作为其网络输入,输出为奖励信息,用来对卷积神经网络CNN的参数进行训练。其中,当前轨迹向量将通过先进焊缝跟踪技术力求与期望轨迹向量一致。当前轨迹向量也作为卷积神经网络CNN的输入,基于前述的奖励输出而训练好的卷积神经网络CNN,会输出相应的动作信息给环境信息(多机器人及工件),从而使得多机器人能够实现协同夹持/搬运/翻转/焊接空间三维复杂焊缝。本发明融合深度Q学习和卷积神经网络CNN算法,采用经验表示技术,在每个时间步长上发生的学习经验,通过将多个事件存储在数据集中,也称为记忆再生。学习数据样本用于每次在重建的存储器中以一定的概率进行更新,通过重复使用经验数据并减少样本间的相关性,可以提高数据效率。
本发明融合深度Q学习和卷积神经网络CNN算法,基于单个机器人分配角色的不同而使用经验数据,在开始学习之前,为每个机器人的角色设定不同的期望值,学习使补偿值总是增加。如果算法的搜索时间过长,则补偿值减小,并且执行学习以使搜索时间不增加。预处理部分采用卷积神经网络CNN查找异常值,后处理部分采用奇异点来学习数据。在预处理部分,利用输入图像来搜索图像的特征,并对这些特征进行采集和学习。在这种情况下,为分配不同角色的每个机器人学习Q值,但是卷积神经网络CNN值具有相同的输入和不同的期望值。因此,Q值在学习时是共享的,并用于学习机。为了优化Q值的更新,有必要定义一个目标函数,将其定义为目标值和Q值预测值的误差。目标函数如方程(5)所示。
式中,a为动作,a'为下一个所有可能的动作,获得损失函数的基本信息是转换
在深度Q学习中,使用目标Q网络和Q网络两种,两种网络结构相同,仅权重参数不同。为了平滑深度Q学习中的收敛,目标网络不是连续更新,而是定期更新。采用均方根传递算法(Root Mean Square Propagation,RMSProp)作为优化器,并根据参数梯度调整学习率。这意味着,在训练集不断变化的情况下,不同于某些训练集的情况,有必要不断地改变参数。
随后,项目针对两机器人协同焊接的任务分配,提出一种基于资源(Resource-based,RB)的机器人任务分配算法。在该机器人任务分配算法中,机器人执行任务期间会持续消耗其资源,这些资源必须在运行期间重新填充。机器人会根据其资源水平,考虑访问资源站不同组合的所有可能性来计算任务性能,这样这使机器人能够减少任务期间不必要的时间和资源浪费。
综上分析,本发明提出融合深度Q学习和卷积神经网络CNN算法的高品质多机器人轨迹规划方法,卷积神经网络CNN算法利用其周围环境的信息分析准确的位置,各机器人根据深度Q学习分析得到的位置进行动作,再采用基于资源的多机器人任务分配算法,将工件的所有焊点合理地分配给两台焊接机器人,从而最终为多台机器人规划出最优的协同路径,使多个机器人能够相互协作且无干涉的发生。
以上所述实施例仅表达了本发明的几种实施方式,其描述较为具体和详细,但并不能因此而理解为对本发明专利范围的限制。应当指出的是,对于本领域的普通技术人员来说,在不脱离本发明构思的前提下,还可以做出若干变形和改进,这些都属于本发明的保护范围。因此,本发明专利的保护范围应以所附权利要求为准。
- 一种多机器人轨迹规划方法
- 基于时间优化的多机器人复杂交错轨迹规划方法及系统