一种手部3D关键点的标注方法
文献发布时间:2023-06-19 12:24:27
技术领域
本发明涉及机器视觉物体检测技术领域,更具体地涉及一种手部3D关键点的标注方法。
背景技术
在一些特定场景中,常常通过标注手部关键点的方法来追踪手部动作,以判断手部动作是否符合要求。目前,手部关键点的标注方法可大致分为两类:真实手部标注法和虚拟手部数字建模法。真实手部标注法是先摆出需要的手势,然后采用摄像头采集手部图像或视频,后期再进行人工标注。该方法前期的采集方式相对简单,但无法获取手部的3D信息,在后期标注时只能标注关键点的2D坐标,使得标注精度低。并且,后期的人工标注也因为工作量巨大而使得标注效率低下。虚拟手部数字建模法可以对手部的背景、角度和光照条件进行任意替换,但其得到的手部图像与真实图像存在差异,同样会使得标注精度较低。并且,该方法需要花费大量的人力和时间,人工成本高而效率低。
发明内容
为解决上述现有技术中的问题,本发明提供一种手部3D关键点的标注方法,可以减少人工标注的工作量,从而降低人工成本并提高效率,同时可以提高标注精度。
本发明提供的一种手部3D关键点的标注方法,包括:
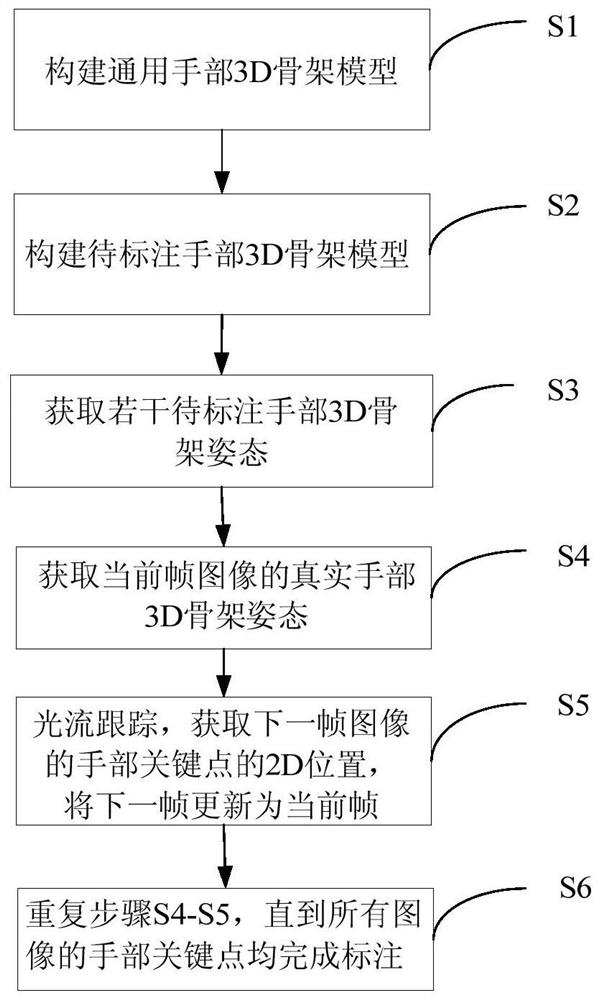
步骤S1,构建通用手部3D骨架模型,根据该通用手部3D骨架模型获取手部每个关键点的3D姿态角约束范围。
步骤S2,获取待标注手部每根手指均伸直的初始帧图像,根据所述初始帧图像以及所述通用手部3D骨架模型,获取待标注手部每段骨骼的长度,构建待标注手部3D骨架模型。
步骤S3,根据所述待标注手部3D骨架模型,获取在不同手势下的若干待标注手部3D骨架姿态。
步骤S4,获取待标注手部的当前帧图像以及当前帧图像的初始手部3D骨架姿态,在所述当前帧图像中标注出当前手部关键点的2D位置,根据所述当前手部关键点的2D位置、所述待标注手部3D骨架模型以及所述若干待标注手部3D骨架姿态,对当前帧图像的初始手部3D骨架姿态进行调整,确定当前帧图像的真实手部3D骨架姿态,获取当前帧图像中的手部3D关键点。
步骤S5,对所述当前手部关键点的2D位置进行光流跟踪,获取下一帧图像的手部关键点的2D位置,将下一帧图像的手部关键点的2D位置更新为当前手部关键点的2D位置,并将下一帧图像更新为当前帧图像。
步骤S6,重复步骤S4-S5,直到所有图像的手部3D关键点均完成标注。
所述步骤S2包括:
步骤S21,获取待标注手部做出不同手势的若干照片或视频,从所述若干照片或视频中选出每根手指均伸直的图像,作为初始帧图像,并在该初始帧图像中标注出所有手部关键点的2D位置。
步骤S22,根据待标注手部的大小或所述初始帧图像的深度信息,将所有手部关键点的2D位置转换为所有手部关键点的3D位置。
步骤S23,根据所有手部关键点的3D位置,获取待标注手部每段骨骼的长度。
步骤S24,根据待标注手部每段骨骼的长度,对通用手部3D骨架模型进行调整,确定待标注手部3D骨架模型。
所述步骤S3包括:采用红蓝立体显示法显示待标注手部3D骨架姿态包括:
步骤S31,获取手部所有关键点的3D坐标,对所有关键点的3D坐标进行加权求平均值,得到手部重心位置的Z轴坐标值D,计算出每个关键点红色分量和蓝色分量的屏显位置。
步骤S32,测量观测者眼睛距离显示器的距离d,将手部所有关键点的位置按d/D等比例缩放,得到位于显示器平面处的手部3D骨架模型的虚像。
步骤S33,计算虚像的每个手部关键点红色分量和蓝色分量的2D位置,并根据每个手部关键点红色分量和蓝色分量的2D位置画出所有手部关键点和骨骼连线。
所述步骤S5中确定当前帧图像的真实3D骨架姿态包括3D结构编辑环节和2D转3D算法环节。
所述3D结构编辑环节包括:保持待标注手部每段骨骼的长度不变,调整当前手部关键点的2D位置,以调整当前手部关键点的相对3D姿态角,进而对当前帧图像的初始3D骨架姿态进行调整;当手部关键点的2D位置被调整正确时,调整后的3D骨架姿态为当前帧图像的真实3D骨架姿态。
所述2D转3D算法环节为:对待标注手部3D骨架模型、当前帧图像的初始3D骨架姿态以及正确的手部关键点的2D位置进行适配,获得当前帧图像的真实3D骨架姿态。
本发明还提供一种手部3D关键点的标注方法,包括:
步骤S1,根据通用手部3D骨架模型、待标注手部的历史图像以及已标注好的手部3D关键点集合,训练用于预测手部3D关键点的深度神经网络模型。
步骤S2,人手将每根手指均伸直,采用具有深度的摄像机采集每根手指均伸直的初始帧图像,根据该初始帧图像以及通用手部3D骨架模型,获取待标注手部每段骨骼的长度,构建待标注手部3D骨架模型。
步骤S3,人手变换手部姿态,具有深度的摄像机对手部姿态实时采集,获取手部的当前帧图像,所述深度神经网络模型对当前帧图像中的手部3D关键点进行预测,获取当前帧图像的初始手部3D骨架姿态。
步骤S4,观察当前帧图像的初始手部3D骨架姿态与真实的手部姿态是否匹配,若匹配,则继续进行步骤S3;若不匹配,则进行步骤S5。
步骤S5,在当前帧图像中标注出当前手部关键点的2D位置,根据当前手部关键点的2D位置、步骤S2中构建的待标注手部3D骨架模型以及真实的手部姿态,对当前帧图像的初始3D骨架姿态进行调整,确定当前帧图像的真实3D骨架姿态,获取当前帧图像中的手部3D关键点。
步骤S6,将当前帧图像作为待标注手部的历史图像,并将当前帧图像中的手部3D关键点加入已标注好的手部3D关键点集合,重复步骤S1-S5,直到训练出的深度神经网络模型预测的手部3D骨架姿态与真实手部姿态基本匹配。
所述步骤S2包括:
步骤S21,采用具有深度的摄像机实时采集待标注手部每根手指均伸直的图像,作为初始帧图像,并在该初始帧图像中标注出所有手部关键点的2D位置。
步骤S22,根据初始帧图像的深度信息,将所有手部关键点的2D位置转换为所有手部关键点的3D位置。
步骤S23,根据所有手部关键点的3D位置,获取待标注手部每段骨骼的长度。
步骤S24,根据待标注手部每段骨骼的长度,对通用手部3D骨架模型进行调整,确定待标注手部3D骨架模型。
本发明的手部3D关键点的标注方法,建立了手部3D骨架模型,采用红蓝立体显示法使得手部骨架呈现出较好的立体效果,从而能够从不同视角对手部3D骨架模型中的手部关键点进行调整,提高了标注的精度。本发明通过深度相机采集手部视频图像,利用人手的灵活改变来减轻后期的人工标注工作量,从而降低人工成本并提高效率。本发明不仅适合从无到有的初始标注,也很适合对已有的跟踪结果、预测结果进行检查和修改,在实际应用过程中进行长尾迭代标注。
附图说明
图1是手部关键点的分布示意图。
图2是按照本发明一实施例的手部3D关键点的标注方法的流程图。
图3是按照本发明另一实施例的手部3D关键点的标注方法的流程图。
具体实施方式
下面结合附图,给出本发明的较佳实施例,并予以详细描述。
每根手指由三段骨骼——末段骨骼、中段骨骼、根段骨骼连接而成,而根段骨骼连接在手掌骨骼上。其中,将根段骨骼定义为中段骨骼的父骨骼,将中段骨骼定义为末段骨骼的父骨骼,则末端骨骼是中段骨骼的子骨骼,中段骨骼是根段骨骼的子骨骼。每一段子骨骼既有自己在世界坐标系下的绝对姿态(由3D位置和三维姿态角限定),又有相对于其父骨骼的相对状态。通常来说,将图1所示的标号为0-20的点定义为手部的关键点,本发明即为对这21个关键点的标注方法。需要说明的是,本发明中的摄像头和观测者为相同的坐标系,以观测者坐标系为例,其X轴向右,Y轴向上,Z轴向前;图像坐标系的X轴向右,Y轴向下,Z轴垂直屏幕指向观测者。观测者坐标系和图像坐标系这两个坐标系都是右手坐标系,可以相互转换。
1、实施例一
基于上述原理和说明,本发明一实施例的手部3D关键点的标注方法,如图2所示,包括以下步骤:
步骤S1,构建通用手部3D骨架模型,根据该通用手部3D骨架模型可以获取手部每个关键点的3D姿态角约束范围。
将图1所示的21个关键点按照人体手部每段骨骼的位置关系相连,即可得到通用手部3D骨架模型,相互连接的关键点按照从腕部到指尖的顺序依次为父子关系。此时不考虑手部每段骨骼的长度,也不考虑每个关键点相对于其父关键点的3D姿态角,而仅确定手部每个关键点的3D姿态角约束范围。每个关键点的3D姿态角约束范围是指该关键点相对于其父关键点的变化范围,例如,大拇指根部关键点(图1中的点1)相对于腕部关键点(图1中的点0)的3D姿态角约束范围是:pitch(-75~-85),yaw(0~45),roll(0-65)。
步骤S2,获取待标注手部每根手指均伸直(即手部摊平呈手掌状)的初始帧图像,根据该初始帧图像以及步骤S1中的通用手部3D骨架模型,获取待标注手部每段骨骼的长度,构建待标注手部3D骨架模型。
步骤S21,对于某个特定的人(该特定的人的手部即为待标注手部),获取其做出不同手势的若干照片或视频,从这些照片或视频中选出每根手指均伸直的图像,作为初始帧图像,并在该初始帧图像中标注出所有手部关键点的2D位置。需要说明的是,若图片和视频是由普通摄像机拍摄的,则需选取手部尽可能平行于摄像头视平面的图像;若图片和视频是由具有深度信息的摄像机拍摄的,则仅需手部摊平即可。
步骤S22,根据待标注手部的大小(没有深度信息时,其为经验值)或初始帧图像的深度信息,将所有手部关键点的2D位置转换为所有手部关键点的3D位置。
步骤S23,根据所有手部关键点的3D位置,获取待标注手部每段骨骼的长度。具体地,通过手部关键点的3D位置可以得出每个关键点相对于其父关键点的3D位置偏移量,根据3D位置偏移量即可得出每段骨骼的长度。
步骤S24,根据待标注手部每段骨骼的长度,对通用手部3D骨架模型进行调整,即,将表示待标注手部每段骨骼长度的参数应用于通用手部3D骨架模型,使得通用手部3D骨架模型中每段骨骼的长度确定下来,确定了每段骨骼长度的骨架模型即为待标注手部3D骨架模型。
步骤S3,根据待标注手部3D骨架模型,获取在不同手势下的若干待标注手部3D骨架姿态。具体地,对于某个特定的人的手部3D骨架模型而言,若腕部关键点在图像坐标系或观测者坐标系下的3D位置和3D姿态角确定,那么,改变每个关键点相对于其父关键点的相对3D姿态角,就可以获得这个人的不同手势所对应的3D骨架姿态。
为了能在显示器上直观显示出3D骨架姿态,从而更好地对3D骨架姿态进行观察,本发明采用红蓝立体显示法和旋转立体显示法。红蓝立体显示法能够提供静态立体视觉效果,提高观察效率。旋转立体显示法则能够提供动态立体视觉效果,可以弥补红蓝立体显示法对一部分人或一部分场景不适用的缺点。
其中,红蓝立体显示法包括:
步骤S31,获取手部所有关键点的3D坐标,对所有关键点的3D坐标进行加权求平均值,得到手部重心位置的Z轴坐标值D,计算出每个关键点红色分量和蓝色分量的屏显位置。
步骤S32,测量观测者眼睛距离显示器的距离d,将手部所有关键点的位置按d/D等比例缩放,得到位于显示器平面处的手部3D骨架模型的虚像。
步骤S33,计算虚像的每个手部关键点红色分量和蓝色分量的2D位置,并根据每个手部关键点红色分量和蓝色分量的2D位置画出所有手部关键点和骨骼连线。需要说明的是,红蓝分量必须以叠加的方式画上去,不能相互覆盖。
旋转立体显示法的原理如下:
首先,计算整个手部的重心和覆盖半径,画出以手部重心为中心、手部覆盖半径为半径的外包球体,则旋转操作在该外包球体内进行。其中,手部重心即为手部所有关键点的3D坐标的加权平均,可以为不同的关键点设置不同的权重,根据需要进行具体设置。以鼠标操作为例,记录下鼠标开始左击的位置,任何时刻的鼠标位置都可以转化成从摄像头为起点的一条射线,称为鼠标射线,该射线的方向利用摄像头内参就能计算出来。如果鼠标位于球面上,则计算鼠标射线跟球面的最近交汇点,然后随着鼠标的移动(左键+Ctrl持续按住中),计算新的位置对应在球面上的交汇点。前后两个交汇点与球心的相对位置形成了两个向量V0和V1,利用罗德里格旋转公式计算从V0到V1的旋转矩阵,这个旋转矩阵作用于初始时刻的手部骨架状态,就得到当前时刻的手部骨架状态,然后重新计算当前时候的骨架二维投影坐标,并实时更新到显示器上。如果鼠标落在球体的外面,则采用鼠标射线与球面的相切点作为交互点。如果鼠标一直处于球体的外面,则近似于对目标进行屏幕内旋转。
除了手部骨架本身的旋转之外,还可对场景进行旋转。场景旋转与骨架旋转的算法和原理相同,但场景旋转会记录旋转前的手部3D骨架整体姿态,然后在旋转后通过逆旋转矩阵一键返回原来的姿态角。为了区分,在实际操作时可用不同的快捷键来代表骨架旋转和场景旋转。通过场景旋转,既可以动态地感受手部3D骨架的立体结构,旋转停止后也可以从新的、更加合适的视角来观察和操纵手部3D骨架。
步骤S4,获取待标注手部的当前帧图像以及当前帧图像的初始3D骨架姿态,在当前帧图像中标注出当前手部关键点的2D位置,根据当前手部关键点的2D位置、步骤S2中构建的待标注手部3D骨架模型以及步骤S3获取的若干待标注手部3D骨架姿态,对当前帧图像的初始3D骨架姿态进行调整,确定当前帧图像的真实3D骨架姿态,获取当前帧图像中的手部3D关键点。
由于当前帧图像的初始3D骨架姿态是由上一帧图像的3D骨架姿态复制而来或通过随机设定关键点的相对3D姿态角而生成的,因此其与真实3D骨架姿态有一定差别,需要对其进行调整。需要说明的是,关键点的相对3D姿态角即指每个关键点相对于其父关键点的3D姿态角。
确定当前帧图像的真实3D骨架姿态包括两个环节:3D结构编辑环节以及2D转3D算法环节。
3D结构编辑环节包括:保持待标注手部每段骨骼的长度不变,调整当前手部关键点的2D位置,以调整当前手部关键点的相对3D姿态角,进而对当前帧图像的初始3D骨架姿态进行调整。当手部关键点的2D位置被调整正确时,即当前帧图像调整后的3D骨架姿态与上述待标注手部3D骨架姿态的其中一个完全匹配时,该调整后的3D骨架姿态即为当前帧图像的真实3D骨架姿态。3D结构编辑可以通过旋转立体显示法而在不同视角下进行,不仅能够准确地调整手部关键点的2D位置,而且操作也更加方便。
在调整某个手部关键点的2D位置时,改变的是该关键点相对于其父关键点的相对3D姿态角,而不改变该关键点的子关键点相对于该关键点的相对3D姿态角,因此该关键点的子关键点会跟随该关键点发生立体移动。所以每调整一个手部关键点,计算出该关键点相对于其父关键点的相对3D姿态角,从而计算出该关键点的绝对3D位置和绝对3D姿态角,进而计算出该关键点的子关键点的相对3D姿态角,为调整该关键点的子关键点做准备,子关键点调整完毕后,计算出子关键点的绝对3D位置和绝对3D姿态角。以此类推,直到每根手指上的关键点均调整完毕。这些调整后的手部关键点的3D位置,实时更新至当前帧图像的所有视图中,以供观测者记录和保存。
需要说明的是,在3D结构编辑时,某些关键点的2D位置可能无法被调整至正确的位置,此时保持这些关键点的相对3D姿态角不变,调整这些关键点对应的骨骼长度,以调整这些关键点的2D位置。在这种情况下,骨骼长度产生了一定误差,但该误差通常在允许的标注误差范围内,且后期可以被自动纠正。
2D转3D算法环节则是在得到正确的手部关键点的2D位置的基础上,对待标注手部3D骨架模型、当前帧图像的初始3D骨架姿态以及正确的手部关键点的2D位置进行适配,来获得当前帧图像的真实3D骨架姿态。具体地,根据下述三个约束条件,建立优化方程求最优解,或采用迭代的方式逼近最优解:
1)由于步骤S1获取的手部每个关键点的3D姿态角约束范围确定,因而当相对3D姿态角超出约束范围时,两个关键点会分别受到方向相反的力矩。
2)待标注手部的骨骼长度确定,因此每段骨骼相当于一个弹性系数非常大的弹簧,当实际骨骼长度大于固定长度时,两个关键点受到相向的压缩力,反之会受到相反方向的拉伸力。
3)手部关键点的2D位置对每个关键点的3D位置形成了一种新的约束力,即3D关键点在图像上的投影坐标,必须与图像上的2D关键点位置相匹配。
3D结构编辑环节以及2D转3D算法环节共同发挥作用,获取最终的真实3D骨架姿态。例如,在实际操作中,用鼠标拖动关键点时会自动执行3D结构编辑方法以调整骨架姿态,而鼠标停止拖动时则会实时地执行2D转3D算法自动进行姿态优化。
步骤S5,对当前手部关键点的2D位置进行光流跟踪,获取下一帧图像的手部关键点的2D位置,将下一帧图像的手部关键点的2D位置更新为当前手部关键点的2D位置,并将下一帧图像更新为当前帧图像。
跟踪后的关键点位置相当于从摄像头出发的一条射线(通过摄像头内参转换),如果某关键点的3D坐标落在相应的观测射线上,则不受力,否则它会受到垂直于观测射线并靠近射线的力。此时计算出的下一帧的3D结构中每个关键点的受力必然导致变形,变形必然会导致相互连接的父子关节点之间的物理距离会发生变化,而每个关键点又受到骨骼长度不变的约束。如果骨骼比初始长度变长了,则受到相互之间的拉力,反之则受到相互之间的斥力。
因此,对当前帧图像的手部3D骨架模型中的关键点进行光流跟踪的方法包括:首先,计算每个关键点受到观测射线的作用力以及骨骼长度不变的作用力;然后,用一微小的步长乘以这个力,使每个关节点朝受力方向移动一小步。最终收敛的结果,会使手部骨骼长度基本不变,仅通过改变手部整体的姿态或每个关节的角度姿态,来匹配光流跟踪的结果。该方法可以节省大量的标注工作量。
步骤S6,重复步骤S4-S5,直到所有图像的手部3D关键点均完成标注。
本发明建立了手部3D骨架模型,采用红蓝立体显示法使得手部骨架呈现出较好的立体效果,从而能够从不同视角对手部3D骨架模型中的手部关键点进行调整,提高了标注的精度。本发明可以减轻后期的人工标注工作量,从而降低人工成本并提高效率。本发明不仅适合从无到有的初始标注,也很适合对已有的跟踪结果、预测结果进行检查和修改,在实际应用过程中进行长尾迭代标注。
2、实施例二
本发明另一实施例的手部3D关键点的标注方法,如图3所示,包括以下步骤:
步骤S1,根据通用手部3D骨架模型、待标注手部的历史图像以及已标注好的手部3D关键点集合,训练用于预测手部3D关键点的深度神经网络模型。其中,构建通用手部3D骨架模型的方法与实施例一相同,在此不再赘述。
步骤S2,人手将每根手指均伸直(即手部摊平呈手掌状),采用具有深度的摄像机采集每根手指均伸直的初始帧图像,根据该初始帧图像以及通用手部3D骨架模型,获取待标注手部每段骨骼的长度,构建待标注手部3D骨架模型。具体包括:
步骤S21,对于某个特定的人(该特定的人的手部即为待标注手部),采用具有深度的摄像机实时采集其每根手指均伸直的图像,作为初始帧图像,并在该初始帧图像中标注出所有手部关键点的2D位置。
步骤S22,根据初始帧图像的深度信息,将所有手部关键点的2D位置转换为所有手部关键点的3D位置。
步骤S23,根据所有手部关键点的3D位置,获取待标注手部每段骨骼的长度。具体地,通过手部关键点的3D位置可以得出每个关键点相对于其父关键点的3D位置偏移量,根据3D位置偏移量即可得出每段骨骼的长度。
步骤S24,根据待标注手部每段骨骼的长度,对通用手部3D骨架模型进行调整,即,将表示待标注手部每段骨骼长度的参数应用于通用手部3D骨架模型,使得通用手部3D骨架模型中每段骨骼的长度确定下来,确定了每段骨骼长度的骨架模型即为待标注手部3D骨架模型。
步骤S3,人手变换手部姿态,具有深度的摄像机对手部姿态实时采集,获取手部的当前帧图像,步骤S1中的深度神经网络模型对当前帧图像中的手部3D关键点进行预测,获取当前帧图像的初始手部3D骨架姿态。
步骤S4,观察当前帧图像的手部3D骨架姿态与真实的手部姿态是否匹配,若匹配,则继续进行步骤S3;若不匹配,则进行步骤S5。为了更好地进行观察,本实施例采用红蓝立体显示法和旋转立体显示法,这两种方法的步骤与原理与实施例一相同,在此不再赘述。
步骤S5,在当前帧图像中标注出当前手部关键点的2D位置,根据当前手部关键点的2D位置、步骤S2中构建的待标注手部3D骨架模型以及真实的手部姿态,对当前帧图像的初始3D骨架姿态进行调整,确定当前帧图像的真实3D骨架姿态,获取当前帧图像中的手部3D关键点。
与实施例一相同,确定当前帧图像的真实3D骨架姿态包括两个环节:3D结构编辑环节以及2D转3D算法环节。这两个环节的步骤和原理与上述相同,在此不再赘述。
步骤S6,将当前帧图像作为待标注手部的历史图像,并将当前帧图像中的手部3D关键点加入已标注好的手部3D关键点集合,重复步骤S1-S5,直到训练出的深度神经网络模型预测的手部3D骨架姿态与真实手部姿态基本匹配。此时,手部3D关键点标注任务完成。
本实施例相比于实施例一的采集图像后进行人工标注的方法,效率要高一些,也可以避免无法符合要求的手部姿态的问题,能精确地采集到需要的手势类型,减少了一定的沟通成本。
以上所述的,仅为本发明的较佳实施例,并非用以限定本发明的范围,本发明的上述实施例还可以做出各种变化。即凡是依据本发明申请的权利要求书及说明书内容所作的简单、等效变化与修饰,皆落入本发明专利的权利要求保护范围。本发明未详尽描述的均为常规技术内容。
- 一种手部3D关键点的标注方法
- 一种基于双目视觉的手部关键点空间坐标获取方法