基于GAN的还原有损压缩视频文件的系统和方法
文献发布时间:2023-06-19 13:26:15
技术领域
本发明涉及计算机视觉领域,更具体地,涉及一种基于生成对抗网络GAN的还原有损压缩视频文件的系统和方法。
背景技术
随着5G和视频技术的发展,基于摄像头的看家类产品发展迅速,而视频文件的存储规模也越来越大。以中国电信天翼看家产品为例,每日新增的视频文件就需要约25PB的存储空间,海量的存储最直接的是带来很大的硬件采购成本。另外,海量的存储对于扩容、运维、容灾等都带来很大的管理成本。所以,对视频文件尽可能大的压缩是一个迫在眉睫的长期的技术难题。
视频压缩有两种方法,一种是基于最新的H265编码进行压缩,另外一种是基于深度学习算法对视频进行编码。天翼看家产品目前大部分基于H265的编码方案,只有少部分老的摄像头还是H264的方案。如果想继续压缩,就需要对H265进行调参,比如增加GOP的长度、对I帧继续压缩等。这种有损压缩带来的问题就是视频的清晰度、流畅度会受到影响。基于深度学习的算法压缩比例更高,但也是基于有损压缩技术,同样会带来用户体验的下降。在视频解码后如何通过技术手段提高视频的清晰度和纹理的细致度,是行业内的难题。
题为“一种图像超分辨率方法及设备”的中国专利申请(CN201611086392.3)公开了一种超分辨图像生成方法,在预先设置生成网络以及判别网络后,将真实图像样本输入生成网络以输出超分辨率图像样本,并获取判别网络分别在输入真实图像样本以及超分辨率图像样本后输出的判别概率,根据真实图像样本、超分辨率图像样本以及判别概率确定生成网络损失函数以及判别网络损失函数,根据生成网络损失函数以及判别网络损失函数对生成网络以及判别网络的配置参数进行调整。在当调整完成后接收到处理低分辨率图像,能够根据生成网络生成低分辨率图像的超分辨率图像,并对超分辨率图像进行可视化处理,从而显著提高了图像超分辨率效果以及超分辨图像的真实性。然而,该方法在分辨率放大倍数较大的情况下,比如4倍以上,纹理的流畅度会很差。
题为“一种基于密集连接网络的图像超分辨率方法”的中国专利申请(CN201710193665.2)公开了一种基于密集连接网络的图像超分辨率方法,通过加大卷积神经网络的深度,在深度网络中引入大量的跳跃式连接,有效解决深度网络反向传播时的梯度消失问题,优化了信息在网络上的流动,提升了卷积神经网络的超分辨率重建能力。同时,本发明也有效结合了底层特征和高层抽象特征,减少模型参数,压缩了深度网络模型,从而提高了图像超分辨率的重建效率。此外,通过引入深度监督技术,在网络的不同深度都能重建超分辨率图像,不仅优化了深度网络的训练,并且在测试时可以根据测试端的计算能力选择适当的网络深度重建高清图像。最后,该发明利用了多个放大倍数的图像集进行训练,获得的模型可以在多个尺度上进行图像超分辨率,而不用针对每一个放大倍数训练不同的模型。
论文“Image Super-Resolution by Neural Texture Transfer”(https://arxiv.org/abs/1903.00834)提出了一种端到端的深度模型,能够根据与参照(Ref)图像的纹理相似性自适应地迁移Ref图像的纹理,从而丰富图像的细节。除了像之前的工作那样在原始像素空间中匹配内容,本论文的关键贡献是在神经空间中执行的多层面匹配。这种匹配方案有助于多尺度神经迁移,能让模型从那些形义相关的Ref图块中获得更多好处,并在最不相关的Ref输入上优雅地降级到单图像超分辨率(SISR)性能。该论文成果已被证明在给了与低分辨率(LR)输入有相似内容的Ref图像时有很好的恢复高分辨率(HR)细节的潜力。但是,当Ref的相似程度较低时,基于Ref的超分辨率(RefSR)的性能会严重下降。
发明内容
提供本发明内容以便以简化形式介绍将在以下具体实施方式中进一步的描述一些概念。本发明内容并非旨在标识所要求保护的主题的关键特征或必要特征,也不旨在用于帮助确定所要求保护的主题的范围。
针对上述现有技术中存在的不足,本发明旨在结合摄像头场景的具体情况,设计一种生成对抗网络GAN,在视频压缩比较大、损失较大的情况下,可以在云侧或者手机端解码还原视频文件,这样既大幅减少了视频文件存储的空间占用,又不影响用户体验。
根据本发明的一个方面,提供了一种用于训练基于生成对抗网络的高清图片生成模型的方法,所述方法包括:
对训练数据集进行自动标注,其中所述训练数据集包括多组高清参照图片和根据所述高清参照图片生成的低清图片;以及
使用所述训练数据集来完成所述生成对抗网络的训练,所述生成对抗网络的训练进一步包括重复执行以下步骤:
将所述低清图片送入到所述生成对抗网络的生成器并生成高清图片;
将所述生成器生成的高清图片与所述高清参照图片送入所述生成对抗网络的判别器以供所述判别器进行真实图片判别;以及
进行所述生成器和所述判别器的损失计算,并根据计算结果对所述生成器和所述判别器的参数进行更新,
其中经训练后的生成器被用作为所述高清图片生成模型。
根据本发明的进一步实施例,所述生成对抗网络的训练进一步包括:
在将所述低清图片送入到所述生成器之前,将所述低清图片与相应的高清参照图片进行融合;以及
将经融合的图片送入到所述生成器并生成高清图片。
根据本发明的另一方面,提供了一种用于还原视频文件的方法,所述方法包括:
获取待还原的视频文件;
将获取的待还原的视频文件输入通过如本发明所述的方法训练得到的高清图片生成模型;
所述高清图片生成模型处理输入的视频文件中的各图片帧,并输出与输入的图片对应的高清图片;以及
将所述高清图片生成模型输出的高清图片进行组合以得到经还原的视频文件。
根据本发明的另一方面,提供了一种用于还原视频文件的方法,所述方法包括:
获取待还原的视频文件;
对于获取的待还原的视频文件中的每一帧图片:
对当前图片进行特征提取;
基于提取的特征检索最相似的高清参照图片;
将所述当前图片与检索到的最相似的高清参照图片进行融合;以及
将经融合的图片输入通过如本发明所述的方法训练得到的高清图片生成模型;以及
所述高清图片生成模型处理并输出与输入的经融合的图片对应的高清图片;以及
将所述高清图片生成模型输出的高清图片进行组合以得到经还原的视频文件。
根据本发明的进一步实施例,基于提取的特征检索最相似的高清参照图片进一步包括:
基于提取的特征值在高清参照图片库中检索具有与所述特征值最接近的特征值的高清参照图片。
根据本发明的进一步实施例,所述高清参照图片库是通过以下方式构建的:
定期采集高清参照图片;
对当前采集的高清参照图片进行特征提取;
将提取的特征值与库中已有图片的特征值进行比对;以及
如果当前采集的高清参照图片的特征值与库中任意一个已有参照图片的特征值的度量距离小于预定阈值,则将当前采集的高清参照图片加入库中。
根据本发明的另一方面,提供了一种用于训练基于生成对抗网络的高清图片生成模型的系统,所述系统包括:
训练数据集标注模块,所述训练数据集标注模块被配置为对训练数据集进行自动标注,其中所述训练数据集包括多组高清参照图片和根据所述高清参照图片生成的低清图片;
生成网络模块,所述生成网络模块被配置为根据输入的低清图片生成高清图片;
判别网络模块,所述判别网络模块被配置为对输入的高清参照图片以及由所述生成网络模块生成的高清图片进行真实图片判别;以及
损失函数组模块,所述被损失函数组模块配置为对生成网络和判别网络进行损失计算,以供对所述生成网络和所述判别网络的参数进行更新。
根据本发明的进一步实施例,所述系统进一步包括:
高低清图片融合模块,所述高低清图片融合模块被配置成将高清参照图片和生成的对应低清图片进行融合,并将经融合的图片送入所述生成网络模块以生成高清图片。
根据本发明的另一方面,提供了一种用于还原视频文件的系统,包括:
存储单元,所述存储单元存储有根据本发明所述的方法预训练的高清图片生成模型以及计算机可执行指令;以及
至少一个处理单元,所述计算机可执行指令在被执行时可致使所述至少一个处理单元执行用于还原视频文件的方法,所述方法包括:
获取待还原的视频文件;
将获取的待还原的视频文件输入所述高清图片生成模型;
所述高清图片生成模型处理输入的视频文件中的各图片帧,并输出与输入的图片对应的高清图片;以及
将所述高清图片生成模型输出的高清图片进行组合以得到经还原的视频文件。
根据本发明的进一步实施例,所述存储单元进一步存储有经训练的特征值提取网络模型以及高清参照图片库,并且所述计算机可执行指令在被执行时可致使所述至少一个处理单元执行的方法进一步包括:
对于获取的待还原的视频文件中的每一帧图片:
通过所述特征值提取网络模型对当前图片进行特征提取;
基于提取的特征从所述高清参照图片库中检索最相似的高清参照图片;
将所述当前图片与检索到的最相似的高清参照图片进行融合;以及
将经融合的图片输入根据本发明所述的方法预训练的高清图片生成模型;以及
所述高清图片生成模型处理并输出与输入的经融合的图片对应的高清图片。
通过阅读下面的详细描述并参考相关联的附图,这些及其他特点和优点将变得显而易见。应该理解,前面的概括说明和下面的详细描述只是说明性的,不会对所要求保护的各方面形成限制。
附图说明
为了能详细地理解本发明的上述特征所用的方式,可以参照各实施例来对以上简要概述的内容进行更具体的描述,其中一些方面在附图中示出。然而应该注意,附图仅示出了本发明的某些典型方面,故不应被认为限定其范围,因为该描述可以允许有其它等同有效的方面。
图1是根据本发明的一个实施例的训练用于还原视频文件的生成对抗网络GAN的方法的示例流程图。
图2是根据本发明的一个实施例的用于还原视频文件的方法的示例流程图。
图3是根据本发明的另一实施例的用于还原视频文件的方法的示例流程图。
图4是根据本发明的一个实施例的训练用于基于生成对抗网络GAN的高清图片生成模型的系统的示例结构图。
图5是根据本发明的一个实施例的用于视频文件还原系统的示例结构图。
具体实施方式
下面结合附图详细描述本发明,本发明的特点将在以下的具体描述中得到进一步的显现。
图1是根据本发明的一个实施例的训练用于还原视频文件的生成对抗网络GAN的方法100的示例流程图。生成对抗网络GAN是一种非监督式机器学习架构,其包括两套独立的网络,两者之间作为互相对抗的目标。第一套网络是生成器G(也叫生成网络),用于生成类似于真实样本的随机样本,并将其作为假样本。第二套网络是判别器D(也叫判别网络),用来分辨输入图片是真实数据还是由诸如生成器G生成的虚假数据。在训练过程中,生成器G的目的是生成令判别器D难辨真假的假样本,而判别器D的目的是提高判别真实数据还是由生成器G生成的假样本的准确率。基于每一次的输出结果,不断对两个网络的参数进行调优,直到两者进入到一个均衡和谐的状态。训练后的产物是一个质量较高的生成器G和一个判断能力较强的判别器D。其中,在本发明中,经训练的生成器G可被用作为将低清图片还原成高清图片的模型。可以理解的是,此处的“高清”和“低清”可以表示高分辨率和低分辨率,也可以表示相同分辨率下的高码率和低码率。
方法100开始于步骤102,对训练数据集进行自动标注。更具体地,可以收集不同时间、不同条件(例如不同天气)下的高清视频,并从高清视频中自动提取高清图像帧作为高清参照图片,并为每一个高清参照图片生成相应的低清图片。多组对应的高清参照图片和低清图片可构成训练数据集。随后,可采用无监督学习的方式对训练数据集进行自动标注,标注可至少包括指示该图片为真实图片(即原始的高清参照图片)还是生成图片(即基于原始图片生成的低清图片)。
在步骤104,将低清图片送入到生成对抗网络的生成器并生成高清图片。如之前所提到的,在本发明中,生成器G被不断训练以根据输入的低清图片生成并输出高清图片,即将经压缩的图片还原成原始图片。当然,这一图片还原过程是有损的,但经过训练后可将损失降低到可接受的程度,从而从另一方面来说,提高了可允许的最大视频压缩率(即在该压缩率下仍然能够还原出可接受的高清图片),以达到节省存储空间或带宽的目的。
可选地,根据本发明的一个优选实施例,在将低清图片送入生成器之前,在步骤103,可先将低清图片和高清参照图片进行融合,并将经融合的图片送入生成器。融合的目的是为了提高训练的速度,加速模型更快的收敛。作为一个示例,融合可通过对低清图片和高清图片执行Concactenate操作来进行,即:
Rp=CONCATENATE(Lp,Hp)
其中Rp是经融合的图片,Lp是低清图片,Hp是高清参照图片。
在步骤106,将生成器生成的高清图片与原始的高清参照图片送入生成对抗网络的判别器来供其进行真实图片判别。判别器D被设计用来判别输入的图片是真实图片(真样本)还是生成图片(假样本)。判别器D或判别网络的具体结构同样不受限定。由于送入判别器D的生成图片和高清参照图片都带有标注,因此可确定判别器D对每一张图片的判别结果是否正确。
在步骤108,进行生成器和判别器的损失计算,并根据计算结果对生成器和判别器的参数进行更新。生成对抗网络的损失函数的设计不受限定,可根据需要设置合适的损失函数。作为一个优选实施例,可分别从纹理损失、色彩损失、内容损失等各个维度进行损失计算。
在步骤110,重复执行步骤104到步骤108,以完成生成器和判别器的训练。经训练后的生成器可根据输入的低清图片生成并输出高清图片。
图2是根据本发明的一个实施例的用于还原视频文件的方法200的示例流程图。
在步骤202,获取待还原的视频文件。如之前所提到的,原始的视频文件可以是由摄像头(例如中国电信天翼看家摄像头)捕捉的视频文件。出于诸如节省成本、容量或带宽的目的,该摄像头可以是低分辨率摄像头,或者摄像头本身是高分辨率摄像头,但捕捉的视频文件可经过较大的压缩,因而在云端或手机端获取的待还原的视频文件为低清视频文件或经压缩的视频文件。
在步骤204,将获取的待还原的视频文件输入经训练的高清图片生成模型。作为一个示例,高清图片生成模型可以是通过图1描述的方法训练出的用于还原有损压缩视频文件的生成对抗网络中的生成器。待还原的视频文件可逐帧地输入生成器,替代地,在一些用途中(诸如仅需要从视频中进行对象或事件识别而不需要还原每一帧时),也可按一定速率进行抽帧,将抽出的帧输入生成器。
在步骤206,高清图片生成模型处理输入的视频文件中的各图片帧,并输出与输入的图片对应的高清图片。如之前所描述的,经训练的高清图片生成模型可将输入的低清图片还原成相应的高清图片。
在步骤208,将高清图片生成模型输出的高清图片进行组合以得到经还原的视频文件。例如,可采用与输入视频相对应的帧率将连续的高清图片组合成视频文件,作为经还原的高清视频文件。
图3是根据本发明的另一实施例的用于还原视频文件的方法300的示例流程图。
与步骤202类似的,在步骤302,获取待还原的视频文件。
随后,在步骤304,对获取的视频文件的每一帧图片进行特征提取。例如,对图片进行特征提取可通过将图片输入特征值提取网络来进行。作为一个非限制性示例,特征值提取网络可以是基于VGG、Res等结构的深度学习网络。
在步骤306,基于提取的特征检索最相似的高清参照图片。作为一个示例,可预先构建高清参照图片库。例如,可定期采集高清参照图片,并对该参照图片进行同样的特征提取。随后,将提取出的特征值与库中已有的参照图片的特征值进行比对。如果特征值与库中任意一个已有参照图片的特征值的度量距离小于某个阈值,这说明库中已经有和该图片比较相似的图片,则舍弃该图片。反之,如果度量距离大于该阈值,则将该图片加入库中。回到步骤306,可基于提取到的当前图片的特征值来在高清参照图片库中检索与之最为相似(例如两者的度量距离最小)的图片作为检索结果返回。
在步骤308,将当前图片与检索到的与其最相似的高清参照图片进行融合。如之前提到的,融合可通过对低清图片和高清图片执行Concactenate操作来进行,即:
Rp=CONCATENATE(Lp,Hp)
其中Rp是经融合的图片,Lp是低清图片,Hp是高清参照图片。
在步骤310,将经融合的图片输入经训练的高清图片生成模型。
在步骤312,高清图片生成模型处理输入的图片,并输出与输入的图片对应的高清图片。如之前所描述的,该高清图片生成模型可以是基于融合图片来训练的生成器,因而可以根据融合图片来生成高清图片。
步骤304-312可重复执行,直至视频文件的所有帧都被处理。
在步骤314,将高清图片生成模型输出的高清图片进行组合以得到经还原的视频文件。
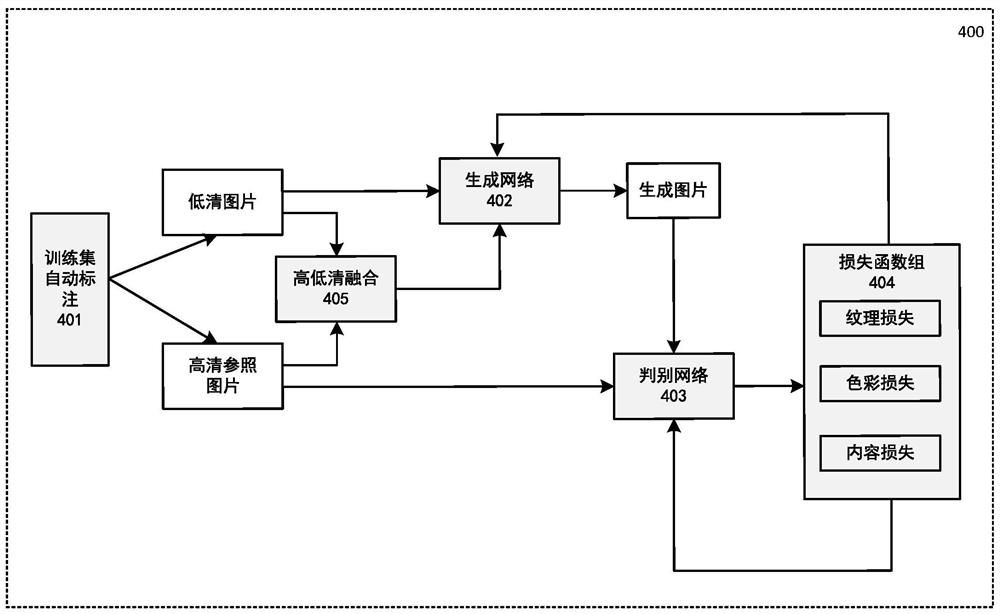
图4是根据本发明的一个实施例的训练用于基于生成对抗网络GAN的高清图片生成模型的系统400的示例结构图。如图4中所示,系统400可包括训练数据集标注模块401、生成网络模块402、判别网络模块403、以及损失函数组模块404。
训练数据集标注模块401可被配置为对训练数据集进行自动标注。如之前所描述的,训练数据集可由多组对应的高清参照图片和低清图片构成。可采用无监督学习的方式对训练数据集进行自动标注,例如将每一张图片标注为真实图片(即原始的高清参照图片)或生成图片(即基于原始图片生成的低清图片)。
生成网络模块402可被配置为根据输入的低清图片生成高清图片。生成网络模块的生成网络的具体结构不受限定,可以是标准的卷积神经网络,也可以是引入残差块的卷积神经网络。
判别网络模块403可被配置为对输入的高清参照图片以及由生成网络模块402生成的高清图片进行判别。判别过程可包括对高清参照图片和生成的高清图片进行特征提取,并基于提取的特征进行判别。判别的结果可以是该图片是真实图片还是生成图片的概率。
损失函数组模块404可被配置为对生成网络和判别网络进行损失计算。在一优选实施例中,损失计算可针对各个维度的特征分别进行,维度可包括但不限于纹理损失、色彩损失、内容损失等。计算的结果可被用于反向传播以供生成网络和判别网络的参数调优。
可选地,系统400还可包括高低清图片融合模块405。高低清图片融合模块405可被配置成将高清参照图片和生成的对应低清图片进行融合。经融合的图片可替代低清图片送入生成网络来生成高清图片以及进行训练。
图5是根据本发明的一个实施例的视频文件还原系统500的示例结构图。如图5中所示,系统500可包括存储单元501和至少一个处理单元502。存储单元501中存储有经训练的高清图片生成模型以及计算机可执行指令。高清图片生成模型可以是如图4中所描述的经训练的用于根据输入的低清图片生成高清图片的生成网络模块402。当计算机可执行指令由处理单元502执行时,可执行如图2所描述的用于还原有损压缩视频文件的方法,包括获取待还原的视频文件,将获取的待还原的视频文件输入经训练的高清图片生成模型,输出与输入的图片对应的高清图片,并将高清图片生成模型输出的高清图片进行组合以得到经还原的视频文件。
在另一实施例中,存储单元501中还可存储有预训练的特征值提取网络模型以及高清参照图片库。当计算机可执行指令由处理单元502执行时,可进一步执行如图3所描述的用于还原有损压缩视频文件的方法,包括对获取的视频文件的每一帧图片进行特征提取,基于提取的特征检索最相似的高清参照图片,将当前图片与检索到的与其最相似的高清参照图片进行融合,用经融合的图片代替原图片输入经训练的生成网络,输出与输入的图片对应的高清图片,并将高清图片生成模型输出的高清图片进行组合以得到经还原的视频文件。
作为一个示例,系统500可被布置在云端或手机端,这样既大幅减少了视频文件存储的空间占用和传输带宽,又不影响用户体验。
以上描述了本发明的基于生成对抗网络的用于还原有损压缩视频的方法和系统,与现有技术相比,至少具有以下技术效果:
(1)还原效果好:通过生成对抗网络的不断训练,可以将高压缩比的低清图片理想地还原成高清图片;
(2)样本集标注方便:采用自动样本集的方法,不需要手工标注;
(3)训练速度快:低清图片和高清图片融合后进行训练,模型收敛速度快。
以上所已经描述的内容包括所要求保护主题的各方面的示例。当然,出于描绘所要求保护主题的目的而描述每一个可以想到的组件或方法的组合是不可能的,但本领域内的普通技术人员应该认识到,所要求保护主题的许多进一步的组合和排列都是可能的。从而,所公开的主题旨在涵盖落入所附权利要求书的精神和范围内的所有这样的变更、修改和变化。
- 基于GAN的还原有损压缩视频文件的系统和方法
- 一种基于信息还原的内网视频文件监控方法