一种基于分组和多样性增强的长尾分布图像识别方法
文献发布时间:2023-06-19 13:26:15
技术领域
本发明涉及图像识别技术领域,具体涉及到一种基于分组和多样性增强的长尾分布图像识别方法。
背景技术
随着计算机视觉和神经网络的迅猛发展,图像单标签识别任务获得了前所未有的突破,在各种公开数据集中产生了非常良好的结果。然而在现实场景下,如果不进行人为刻意的筛选,我们获得的图像往往包含多个标签,因此越来越多的研究者开始关注多标签图像识别任务。多标签图像识别的目标是把图像中包含的所有标签都识别出来。对比单标签图像识别任务而言,多标签图像由于包含有多个标签,因此输出的标签组合数随着标签数量的增加呈现几何增长,这给多标签图像识别任务带来了巨大的挑战。
目前已经有很多研究人员通过建模标签之间的相关性来解决多标签图像识别问题,尽管这些方法都获得了不错的性能,但是也有一部分研究者发现多标签图像识别任务如同单标签图像识别一样也遭受长尾分布的影响。长尾分布指的是在整个数据集中,某些头部类具有非常多的样本,而大部分尾部类仅包含少量样本。假设数据集存在长尾分布,如果直接对这些数据进行训练的话,网络往往会更加倾向于学习头部类别,从而对识别的性能造成非常大的影响。
目前,处理长尾分布的方法总体可以归纳为重采样和重加权这两个策略。重采样策略是通过增大尾部类别被采样的次数,或者减少头部类别被采样的次数从而平衡的采样各个类别。但是因为多标签图像每张图像都包含多个标签,因此对于多标签图像而言重采样策略无法对类别进行平衡采样。重加权策略通过增大尾部类别的损失的权重,减少头部类别的损失权重来达到平衡学习各个类别的目的。然而重加权策略往往对参数十分敏感,并且对于多标签图像而言还会在一定程度上破坏标签的共现关系。此外,这两种策略都没办法减轻由于尾部类别样本过少所带来的过拟合的问题。
综上所述,提供一种有效的平衡各个类别的梯度,并且增强尾部类别的特征多样性,从而提高基于长尾分布的多标签图像识别任务的性能,减轻尾部类别的过拟合的长尾分布图像识别方法,是本领域技术人员急需解决的问题。
发明内容
本方案针对上文提到的问题和需求,提出一种基于分组和多样性增强的长尾分布图像识别方法,其由于采取了如下技术方案而能够解决上述技术问题。
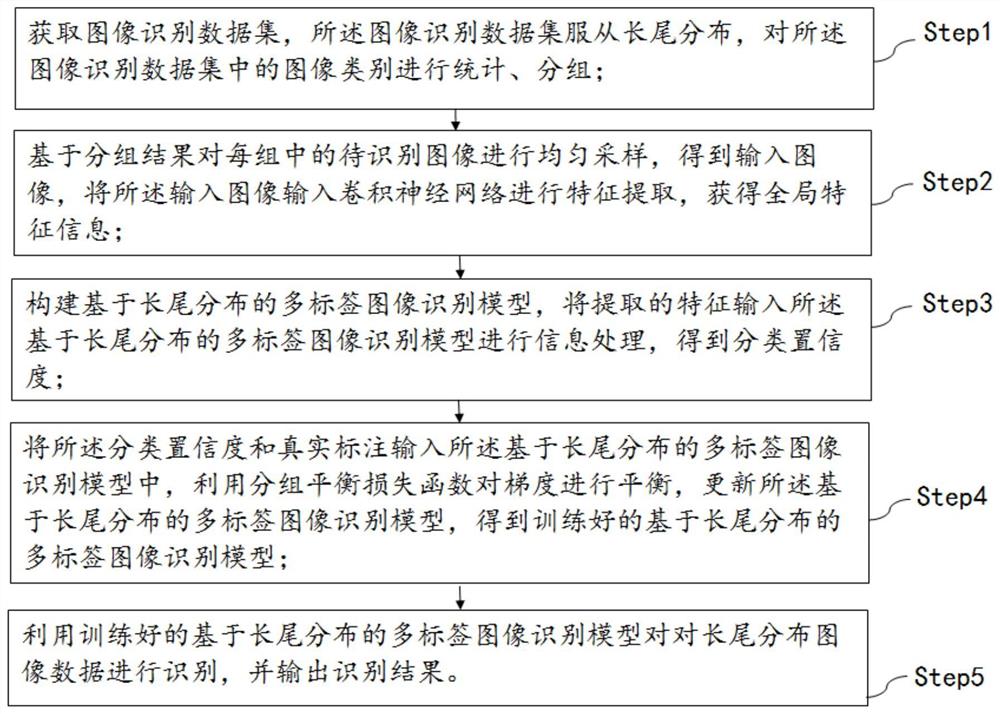
为实现上述目的,本发明提供如下技术方案:一种基于分组和多样性增强的长尾分布图像识别方法,包括:步骤Step1:获取图像识别数据集,所述图像识别数据集服从长尾分布,对所述图像识别数据集中的图像类别进行统计、分组;
步骤Step2:基于分组结果对每组中的待识别图像进行均匀采样,得到输入图像,将所述输入图像输入卷积神经网络进行特征提取,获得全局特征信息;
步骤Step3:构建基于长尾分布的多标签图像识别模型,将提取的特征输入所述基于长尾分布的多标签图像识别模型进行信息处理,得到分类置信度;
步骤Step4:将所述分类置信度和真实标注输入所述基于长尾分布的多标签图像识别模型中,利用分组平衡损失函数对梯度进行平衡,更新所述基于长尾分布的多标签图像识别模型,得到训练好的基于长尾分布的多标签图像识别模型;
步骤Step5:利用训练好的基于长尾分布的多标签图像识别模型对对长尾分布图像数据进行识别,并输出识别结果。
进一步地,对所述图像识别数据集中的图像类别进行统计、分组包括:统计所述图像识别数据集中各类别出现的频率,然后按照降序排序方法对统计的各类别频率进行排序,根据排序信息把类别均分为三组,三组类别为”头(head)”、“中(middle)”、“尾(tail)”。
更进一步地,所述图像识别数据集中的图像均为多标签图像,每个多标签图像包含有多个物体和标签,所述全局特征包含所有标签的信息。
更进一步地,所述基于长尾分布的多标签图像识别模型包括多样性增强模块和分组平衡损失模块,将所述卷积神经网络提取的全局特征信息经过处理后输入所述多样性增强模块获取分类的置信度,利用头部类别的信息来增强尾部类别的特征多样性,减轻尾部类别的过拟合。
更进一步地,所述多样性增强模块由一个融合矩阵和若干个全连接层组成,将所述卷积神经网络提取的全局特征信息X通过特征解耦卷积层进行解耦后,获得每个类别各自对应的特征Xcaf,X
更进一步地,所述分组平衡损失模块采用的分组平衡损失函数如下:
更进一步地,所述分组权重w的取值遵循以下规则:
从上述的技术方案可以看出,本发明的有益效果是:本发明通过分组采样方法可以有效的对每组进行均匀采样以实现平衡的采样各个类别,并且利用利用头部类别的信息来增强尾部类别的特征多样性,从而提高基于长尾分布的多标签图像识别任务的性能,减轻尾部类别的过拟合,且通过分组平衡模块能有效的对各个类别的梯度进行平衡,从而处理长尾分布问题。
除了上面所描述的目的、特征和优点之外,下文中将结合附图对实施本发明的最优实施例进行更详尽的描述,以便能容易地理解本发明的特征和优点。
附图说明
为了更清楚地说明本发明实施例或现有技术中的技术方案,下文将对本发明实施例或现有技术描述中所需要使用的附图作简单地介绍,其中,附图仅仅用于展示本发明的一些实施例,而非将本发明的全部实施例限制于此。
图1为本发明一种基于分组和多样性增强的长尾分布图像识别方法的具体过程示意图。
图2为本实施例中基于长尾分布的多标签图像识别模型的模型结构示意图。
图3为本实施例中各个类别特征融合的过程示意图。
图4为本实施例中各个类别梯度累积的示意图。
图5为本实施例中分类器可视化图的示意图。
具体实施方式
为了使得本发明的技术方案的目的、技术方案和优点更加清楚,下文中将结合本发明具体实施例的附图,对本发明实施例的技术方案进行清楚、完整地描述。附图中相同的附图标记代表相同的部件。需要说明的是,所描述的实施例是本发明的一部分实施例,而不是全部的实施例。基于所描述的本发明的实施例,本领域普通技术人员在无需创造性劳动的前提下所获得的所有其他实施例,都属于本发明保护的范围。
本申请利用各个类别在数据集中的频率进行分组,再对各个组进行均匀采样以获取输入图片,通过多样性增强模块来有效利用头部类别的信息来增强尾部类别的特征多样性,以减轻过拟合尾部类别的现象,并将分类置信度与真实标注送入分组平衡损失模块对梯度进行平衡,更新多标签图像识别模型,最终获得训练好的多标签图像识别模型,其中,分组平衡损失能忽略其他组的所有正向类别梯度,仅更新当前被采样组的类别,以此平衡各个类别之间的梯度,从而最终提高多标签图像识别的性能。
如图1至图5所示,该方法具体包括以下步骤:步骤Step1:获取图像识别数据集,所述图像识别数据集服从长尾分布,对所述图像识别数据集中的图像类别进行统计、分组。
具体地,对所述图像识别数据集中的图像类别进行统计、分组包括:统计所述图像识别数据集中各类别出现的频率,然后按照降序排序方法对统计的各类别频率进行排序,根据排序信息把类别均分为三组,三组类别为”头(head)”、“中(middle)”、“尾(tail)”。在训练过程中,每次先均匀的从这三组中采样一组,接着从该组中均匀的采样一个样本作为输入图片,其中,各个类别是指数据集中的所有图像类别,比如猫、狗等图像。统计图像识别数据集中所有图像类别出现的频率,这个统计出来的频率可以构成一个数组,比如图像识别数据集中一共20个类别,那么就可以构造一个长度为20的数组,统计的时候如果出现类别2,那么对应数组2位置上的频率加1,统计结束后这个数组就代表数据集中所有类别出现的频率。然后根据这个频率按照降序进行排序,那么出现频率高的类别就会被排在前面,频率低的就会被排在后面。然后根据这个排序的结果把类别均分成3组,那么频率高的被分为同一组(head),频率中等(middle)的被分为一组,频率低(tail)的被分为一组。
步骤Step2:基于分组结果对每组中的待识别图像进行均匀采样,得到输入图像,将所述输入图像输入卷积神经网络进行特征提取,获得全局特征信息。
在本实施例中,所述图像识别数据集中的图像均为多标签图像,每个多标签图像包含有多个物体和标签,所述全局特征包含所有标签的信息。
步骤Step3:构建基于长尾分布的多标签图像识别模型,将提取的特征输入所述基于长尾分布的多标签图像识别模型进行信息处理,得到分类置信度;
具体地,所述基于长尾分布的多标签图像识别模型包括多样性增强模块和分组平衡损失模块,将所述卷积神经网络提取的全局特征信息经过处理后输入所述多样性增强模块获取分类的置信度,这样能有效利用头部类别的信息来增强尾部类别的特征多样性,以减轻过拟合尾部类别的现象。
在本方法中,所述多样性增强模块由一个融合矩阵和若干个全连接层组成,而获取分类的置信度的具体过程如下:由于多标签图像包含有多个物体和标签,因此该全局特征包含所有标签的信息,需要进行特征解耦,将所述卷积神经网络提取的全局特征信息X通过特征解耦卷积层进行解耦后,获得每个类别各自对应的特征Xcaf,X
然后通过所述融合矩阵M将各个类别的特征进行融合,使得尾部类别特征可吸收头部类别特征的信息,最后采用全连接层把融合后的特征映射成分类置信度
如图3所示,尾部类别的特征多样性被增强,因此减轻的网络过拟合尾部类别的问题,从而提高了分类器的性能。
步骤Step4:将所述分类置信度和真实标注输入所述基于长尾分布的多标签图像识别模型中,利用分组平衡损失函数对梯度进行平衡,更新所述基于长尾分布的多标签图像识别模型,得到训练好的基于长尾分布的多标签图像识别模型。其中,分组平衡模块能忽略其他组的所有正向类别梯度,仅更新当前被采样组的类别,以此平衡各个类别之间的梯度,从而最终提高多标签图像识别的性能。如图4所示,可以看到基准的方法头部类别梯度累积值较高,而尾部较低,说明不采用任何措施直接对长尾分布数据进行训练会使网络偏向学习头部类,而本申请的方法可使得各个类别的梯度趋于平衡,其中,a为基准方法的梯度累积,b为本方法的梯度累积。
在本申请中,所述分组平衡损失模块采用的分组平衡损失函数如下:
步骤Step5:利用训练好的基于长尾分布的多标签图像识别模型对对长尾分布图像数据进行识别,并输出识别结果。
本申请可有效利用头部类别的信息来增强尾部类别的特征多样性,以减轻过拟合尾部类别的现象,并且能有效对各个类别的梯度进行平衡,从而处理长尾分布问题。如图5所示,可以看到基准方法的尾部类别的分类器聚集在一起,这说明由于尾部类别样本过少,网络出现过拟合尾部类现象,采用本申请的方法使得尾部类别的分类器被拉开了。
应当说明的是,本发明所述的实施方式仅仅是实现本发明的优选方式,对属于本发明整体构思,而仅仅是显而易见的改动,均应属于本发明的保护范围之内。
- 一种基于分组和多样性增强的长尾分布图像识别方法
- 多任务长尾分布图像识别方法、系统、电子设备及介质