一种基于MEANSHIFT优化的数据处理方法和装置
文献发布时间:2023-06-19 13:26:15
技术领域
本发明涉及数据挖掘和机器学习领域,更具体地,涉及基于MEANSHIFT优化的数据处理方法和装置。
背景技术
随着现代信息技术的快速发展,世界已跨入了互联网+大数据时代。大数据正深刻改变着人们的思维、生产和生活方式,大数据与各个行业的深度融合,产生出前所未有的社会和商业价值。大数据发展过程中产生了很多基于数据挖掘和机器学习的数据处理方法,其中传统的K-means算法从N个样本
中国专利申请“一种基于密度Canopy的K-means聚类方法”(CN201911127104.8)中提出了一种基于密度Canopy的K-means聚类方法,以密度Canopy聚类作为K-means算法的预处理步骤,相比传统K-means算法的聚类准确率有所提高,但是该方法并未考虑原始样本与其他类簇之间的关系,只能确保局部最优,无法得到全局最优。
中国专利申请“基于神经网络的K-means聚类方法”(CN201810570097.8)中提出了一种基于神经网络的K-means聚类方法,解决现有的K-means用两个独立的步骤迭代地优化聚类中心和标签分配导致推理速度慢、不能处理新的数据、大规模数据、在线数据,及对初始值敏感的问题,然而该方法也并未考虑样本与多个类簇最近且近似的场景,无法在该场景下合理地划分样本。
因此,为了针对样本与多个类簇最近且近似情况下,让样本划分的更加合理,进而提升聚类精度,希望提供一种改进的数据处理方法。
发明内容
提供本发明内容以便以简化形式介绍将在以下具体实施方式中进一步的描述一些概念。本发明内容并非旨在标识所要求保护的主题的关键特征或必要特征,也不旨在用于帮助确定所要求保护的主题的范围。
本发明提出一种基于均值偏移meanshift优化的数据处理方法和装置,考虑原始样本与其他类簇之间的关系,使得各个类簇边缘及其周边区域划分更加合理,簇内紧凑,大大提高聚类的精度和速度。
根据本发明的一个方面,提供了一种数据处理方法,所述方法包括:
实时采集用户行为数据作为原始样本集;
根据类簇个数和所述原始样本集来初始化类簇中心;
针对所述原始样本集中的每个样本,确定是否存在两个或更多个类簇中心与所述样本的距离最近,
若存在,则
利用均值偏移meanshift来计算所述样本的局部密度梯度方向,
计算所述样本的局部密度梯度方向与所述样本朝向所述两个或更多个类簇中心中的每个类簇中心的方向之间的相似度,以及
将所述样本划分至与最大相似度相对应的类簇中;
否则,将所述样本划分至距离类簇中心最近的类簇中;以及
根据聚类结果来向各用户组实时推送相关数据。
根据本发明的一个实施例,确定是否存在两个或更多个类簇中心与所述样本的距离最近进一步包括:
计算所述样本到K个类簇中心的欧式距离以获取针对所述样本的距离集,其中K为类簇个数;
计算所述样本距其他类簇中心c
其中,若存在集合
根据本发明的进一步实施例,利用均值偏移meanshift来计算所述样本的局部密度梯度方向进一步包括:
计算样本局部的均值漂移向量,其中所述向量表示相对样本自身所指向的估计密度最大增加的方向。
根据本发明的进一步实施例,计算相似度进一步包括:
利用余弦相似度算法来计算所述样本的局部密度梯度方向与所述样本朝向所述两个或更多个类簇中心中的每个类簇中心的方向之间的相似度,其中余弦值越大,相似度越高。
根据本发明的进一步实施例,所述初始化类簇中心是通过K-means++聚类算法来进行的,其中各个类簇中心之间的距离尽可能大。
根据本发明的另一方面,提供了一种数据处理装置,所述装置包括:
数据采集模块,所述数据采集模块被配置成实时采集用户行为数据作为原始样本集;
初始化类簇中心模块,所述初始化类簇中心模块被配置成根据类簇个数和所述原始样本集来初始化类簇中心;
数据聚类模块,所述数据聚类模块被配置成:
针对所述原始样本集中的每个样本,确定是否存在两个或更多个类簇中心与所述样本的距离最近,
若存在,则
利用均值偏移meanshift来计算所述样本的局部密度梯度方向,计算所述样本的局部密度梯度方向与所述样本朝向所述两个或更多个类簇中心中的每个类簇中心的方向之间的相似度,以及
将所述样本划分至与最大相似度相对应的类簇中;
否则,将所述样本划分至距离类簇中心最近的类簇中;以及
数据推送模块,所述数据推送模块被配置成基于聚类结果来向与各个类簇相关联的各用户组实时推送相关数据。
根据本发明的一个实施例,确定是否存在两个或更多个类簇中心与所述样本的距离最近进一步包括:
计算所述样本到K个类簇中心的欧式距离以获取针对所述样本的距离集,其中K为类簇个数;
计算所述样本距其他类簇中心c
其中,若存在集合
根据本发明的进一步实施例,利用均值偏移meanshift来计算所述样本的局部密度梯度方向进一步包括:
计算样本局部的均值漂移向量,其中所述向量表示相对样本自身所指向的估计密度最大增加的方向。
根据本发明的进一步实施例,计算相似度进一步包括:
利用余弦相似度算法来计算所述样本的局部密度梯度方向与所述样本朝向所述两个或更多个类簇中心中的每个类簇中心的方向之间的相似度,其中余弦值越大,相似度越高。
根据本发明的进一步实施例,所述初始化类簇中心是通过K-means++聚类算法来进行的,其中各个类簇中心之间的距离尽可能大。
与现有技术中的方案相比,本发明所提供的基于meanshift优化的数据处理方法和装置至少具有以下优点:
(1)通过考虑原始样本与其他类簇之间的关系,使得各个类簇边缘及其周边区域划分更加合理,簇内紧凑,进而提升聚类效果,使得达到全局最优。
(2)相比较传统的K-means算法,能更准确地预估K个类簇中心位置,使其快速收敛,减少迭代次数。
通过阅读下面的详细描述并参考相关联的附图,这些及其他特点和优点将变得显而易见。应该理解,前面的概括说明和下面的详细描述只是说明性的,不会对所要求保护的各方面形成限制。
附图说明
为了能详细地理解本发明的上述特征所用的方式,可以参照各实施例来对以上简要概述的内容进行更具体的描述,其中一些方面在附图中示出。然而应该注意,附图仅示出了本发明的某些典型方面,故不应被认为限定其范围,因为该描述可以允许有其它等同有效的方面。
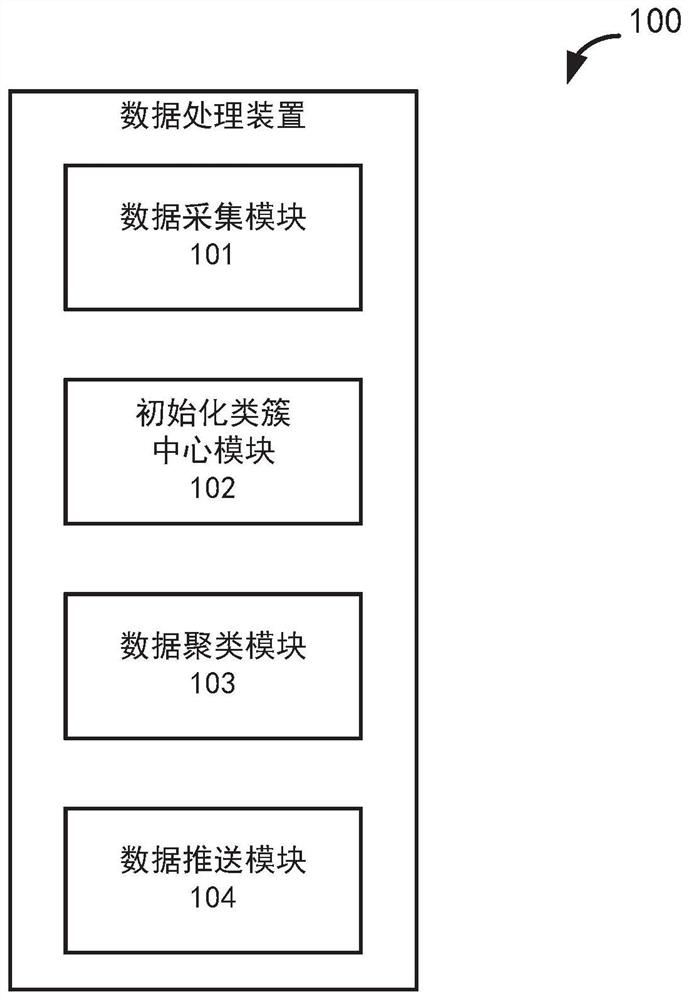
图1示出了根据本发明的一个实施例的基于meanshift优化的数据处理装置的示例架构图。
图2示出了根据本发明的一个实施例的基于meanshift优化的数据处理方法的流程图。
图3示出了根据本发明的一个实施例的基于meanshift的聚类算法的流程图。
图4示出了根据本发明的一个实施例的中心样本二维区域的示例。
具体实施方式
下面结合附图详细描述本发明,本发明的特点将在以下的具体描述中得到进一步的显现。
图1是根据本发明的一个实施例的基于meanshift优化的数据处理装置100的示例架构图。如图1所示,本发明的装置100包括:数据采集模块101、初始化类簇中心模块102、数据聚类模块103和数据推送模块104。
数据采集模块101可实时采集用户数据作为原始样本集,并且按照数据特性分类存储在大数据平台。作为一个示例,数据采集模块101可实时采集用户观看电视节目的行为数据作为原始样本集,其中每天统计用户i前30天观看的电视节目历史记录,针对T个节目类型中的每一个节目类型,根据其相应收看的时间进行累加,并归一化度量为一种评分,即time
初始化类簇中心模块102可以根据类簇个数和原始样本集来初始化类簇中心。作为一个示例,初始化类簇中心模块102可以利用K-means++聚类算法来初始化K个类簇中心,使其之间的距离尽可能大。该K-means++算法的具体步骤为:(1)首先从原始样本集X中随机选取一个样本点x
数据聚类模块103可以针对原始样本集中距离两个或更多个类簇中心最近且近似的每个样本,利用均值偏移meanshift算法来计算该样本的局部密度梯度方向;计算该样本的局部密度梯度方向与该样本朝向该两个或更多个类簇中心中的每个类簇中心的方向之间的相似度;以及将该样本归属至与最大相似度相对应的类簇中以进行聚类。具体而言,数据聚类模块103可以计算原始样本集X中的每个样本x
数据推送模块104可根据聚类结果来向各用户组实时推送相关数据。在一个示例中,可通过聚类算法自动将电视用户分成K组,然后对各组类簇中心T个属性(节目类型)进行排序,后台依据各自Top-N属性(节目类型)对各组定向推送相关的节目。
为了解说方便,以下将以基于均值偏移meanshift的K-means++聚类算法为例来描述本发明的实施方式,但本领域技术人员可以理解,本发明同样适用于其他的聚类算法。
图2是根据本发明的一个实施例的基于meanshift优化的数据处理方法200的流程图。方法开始于步骤201,数据采集模块101实时采集用户行为数据作为原始样本集X。
在步骤202,初始化类簇中心模块102根据类簇个数和原始样本集来初始化类簇中心。初始化类簇中心的算法包括但不限于K-means++、K-means、Canopy等。
在步骤203,数据聚类模块103针对原始样本集中的每个样本,确定是否存在两个或更多个类簇中心与该样本的距离最近且近似;若存在,则利用非参数估计均值偏移meanshift算法来计算该样本的局部密度梯度方向,计算该样本的局部密度梯度方向与该样本朝向该两个或更多个类簇中心中的每个类簇中心的方向之间的相似度,以及将该样本划分至与最大相似度相对应的类簇中;否则,将该样本划分至距离类簇中心最近的类簇中。以下在图3中进一步详细地描述了该算法的具体实现步骤。
在步骤204,数据推送模块104根据聚类结果来向各用户组实时推送相关数据。
图3示出了根据本发明的一个实施例的基于meanshift的聚类算法300的流程图。该算法300的详细步骤如下:
步骤1:输入类簇个数K和原始样本集X,即
步骤2:使用K-means++算法初始化K个类簇中心,
即
步骤3:计算原始样本集X中的每个原始样本x
步骤4:计算原始样本x
步骤5:若
步骤6:若存在集合
a)以样本x
b)求取x
注意,若Z为0,则视x
c)求取样本x
d)M
步骤7:将原始样本集X中每一个样本x
步骤8:当E
以上所已经描述的内容包括所要求保护主题的各方面的示例。当然,出于描绘所要求保护主题的目的而描述每一个可以想到的组件或方法的组合是不可能的,但本领域内的普通技术人员应该认识到,所要求保护主题的许多进一步的组合和排列都是可能的。从而,所公开的主题旨在涵盖落入所附权利要求书的精神和范围内的所有这样的变更、修改和变化。
- 一种基于MEANSHIFT优化的数据处理方法和装置
- 一种基于多相材料拓扑优化的3D打印模型数据处理方法