基于音视频的主讲跟踪多方网络会议方法和系统
文献发布时间:2023-06-19 13:43:30
技术领域
本申请涉及线上会议技术领域,尤其是涉及一种基于音视频的主讲跟踪多方网络会议方法和系统。
背景技术
数字化技术的发展,让音视频技术融合通讯深入和生活和工作。在企业协同办公方面,上述技术尤为普及,其可方便用户居家办公、远程交流等。
公开号为CN112689115A的专利公开了一种多方会议系统的控制方法。包括:会议中心和终端耦合至通信网络;会议中心对终端进行鉴权;会议中心指定某个终端为视频接入终端Cv并将视频接入终端Cv发送的第一视频数据和多个音频数据处理生成第一混合音频数据并发送至终端。将混合音频数据转换为会议纪要文本并储存并输出。
上述提供了一种多方会议系统,其可提高会议进程中终端环境配置的速率,提高音视频编码转换的速率,提高多方会议音视频的流畅性,但是其存在以下缺陷:
对于大型会议而言,除了部分线上人员外,在主办场所,其线下也会存在不少参与人员,因此通常会以电子大屏的形式展示,然而随着主讲人员的切换,对于大屏投放内容目前依赖人工,相对呆板,切换流畅度不佳,因此本申请提出一种新的技术方案。
发明内容
为了改善会议过程的流畅性,本申请提供一种基于音视频的主讲跟踪多方网络会议方法和系统。
第一方面,本申请提供一种基于音视频的主讲跟踪多方网络会议方法,采用如下的技术方案:
一种基于音视频的主讲跟踪多方网络会议方法,包括建立会议发起者的会议中心和多个与会者的终端的通讯连接,还包括:
记录会议中心为主讲;
获取主讲的音视频数据并传输至各个终端;以及,
识别音视频数据,判断是否存在主讲切换指示信息,如果是,则执行主讲切换处理;
所述主讲切换处理包括:
识别主讲切换指示信息后的其他音视频数据,对比与会者身份信息库得到下一个主讲人的身份数据;以及,
根据与会者终端预关联的与会者身份数据,查找和确定新主讲的终端,并获取新主讲的音视频数据。
可选的,所述识别音视频数据包括:
分离音视频数据,得到音频数据和视频数据;
对音频数据执行音频转译文字,识别文字信息;和/或,
对视频数据进行图像识别,识别人体行为识别;
所述主讲切换指示信息包括预选定的文字信息和/或人体行为信息。
可选的,还包括:
获取主讲的稿件数据和稿件的章、节或页的切换设置数据;其中,章、节或页的切换设置数据包括各个章、节或页的耗时数据;以及,
根据章、节或页的切换设置数据,计算稿件总耗时并基于其生成动态的进度条;
所述进度条发送至会议中心和/或与会者的终端。
可选的,所述章、节或页的切换设置数据的产生方式包括:
分别对各个章、节或页设置耗时;或,
对若干个章、节或页设置耗时;或,
各个章、节或页设置耗时设置为耗时相同,一次性设置。
可选的,还包括:
获取预排的交互活动所发生的章、节或页,作为交互节点;以及
根据交互节点确定其在进度条上预发生的区段,作为交互区段;
所述识别音视频数据执行于交互区段。
可选的,还包括:
对所述音频数据做静音检测;或,
获取的音视频数据为静音检测后的数据;
在执行音频转译文字前,对静音检测得到的特殊编码帧剔除。
可选的,还包括:
获取与会者终端的反馈信息;
判断是否有举手行为,如果是,则发送举手提示至会议中心;
判断会议中心的反馈信息是否同意举行行为,如果是,则传输与会者终端的反馈信息中的音视频数据至会议中心。
第二方面,本申请提供一种基于音视频的主讲跟踪多方网络会议系统,采用如下的技术方案:
一种基于音视频的主讲跟踪多方网络会议系统,包括存储器和处理器,所述存储器上存储有能够被处理器加载并执行如上所述任一种方法的计算机程序。
综上所述,本申请包括以下至少一种有益技术效果:
1、通过对主讲人员的音视频分析处理,识别主讲切换指示,并进一步根据其识别出主讲人员的身份,主动跟踪切换主讲人员及设备,将新主讲人员的音视频传输给会议中心和其他与会者的终端,实现网络会议的主讲无缝切换;
2、可以根据设置稿件各个章、节或页的耗时,基于其生成进度条提示主讲人员把控PPT、演讲等的进度和时间。
附图说明
图1是本申请的通信架构示意图;
图2是本申请的整体流程示意图;
图3是本申请的实施例所指的现有的某会议的界面示意图;
图4是本申请的进度条示意图。
具体实施方式
以下结合附图1-4对本申请作进一步详细说明。
本申请实施例公开一种基于音视频的主讲跟踪多方网络会议方法。
参照图1和图2,基于音视频的主讲跟踪多方网络会议方法,其包括:
S1、建立会议发起者的会议中心和多个与会者的终端的通讯连接;以及,
S2、交互多方音视频数据。
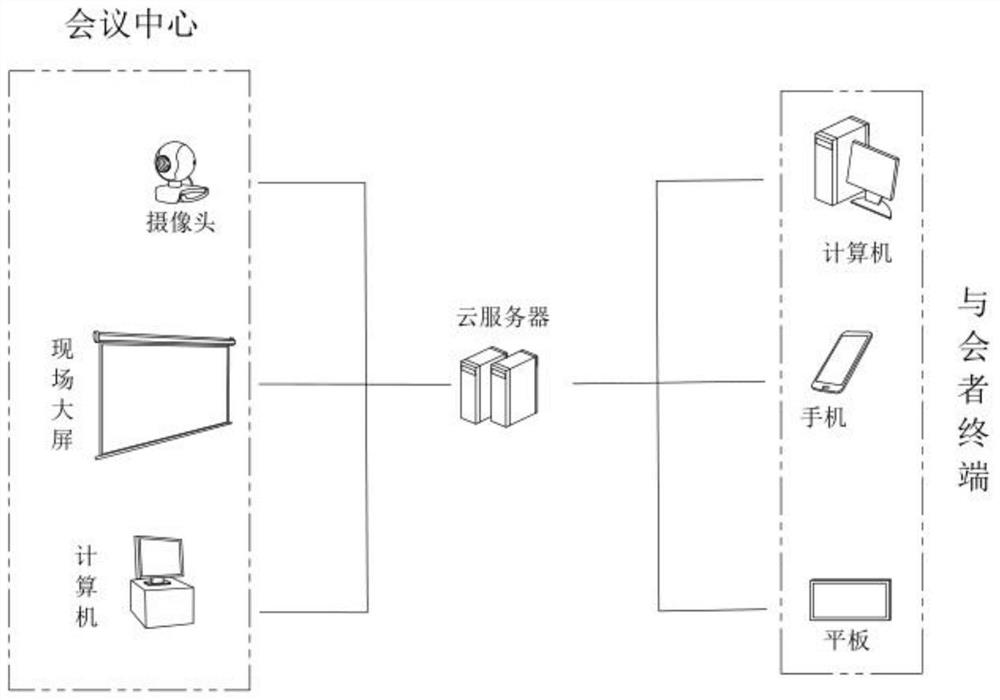
关于会议中心,其包括布设于会场的控制用计算机、多媒体大屏和现场摄像头;计算机用于连接和控制多媒体大屏、现场摄像头;多媒体大屏用于在会议发起者选定的现场展示主讲的稿件等,现场摄像头用于采集现场的视频图像。
与会者的终端包括计算机、手机或平板,其通过互联网与上述计算机连接,以便用户之间远程进行音视频沟通。
上述交互多方音视频数据包括:
101、记录会议中心为主讲;
102、获取主讲的音视频数据并传输至各个终端;以及,
103、识别音视频数据,判断是否存在主讲切换指示信息,如果是,则执行主讲切换处理。
对于主讲的音视频数据,其由主讲(此处为会议中心)的音视频采集装置采集反馈。
因为主讲切换信息设置为:包括预选定的文字信息和/或人体行为信息,所以识别音视频数据包括:先对音视频数据分析,得到音频数据和视频数据;后续,对音频数据执行音频转译文字,识别文字信息;和/或,对视频数据进行图像识别,识别人体行为识别。
具体的,文字信息的音转译获取,其借用市面上的音转译平台实现(如某飞),而文字信息的内容有如“现在有请XX发言”;即在主讲人员说出本句内容后,通过音转译平台对其转译,再文字识别,在被识别存在主讲切换指示,执行主讲切换处理。
同理的,人体行为信息,如主讲人员站立于多媒体大屏前侧,做出以135°斜向上抬举一个手臂的动作;此时,经过动作识别技术,识别其存在主讲切换指示。为提高准确性,上述两方式,可以配合使用,即文字信息和动作相差±3S内,即本判定存在主讲切换指示。
上述阶段,除了会议发起者之外,其他与会人员暂时无发言权限,会议中心暂不展示其他与会者的音视频等,从而避免现有部分会议系统,与会者进入忘记关麦,而发生尴尬事件的问题。
关于主讲切换处理,其包括:
201、识别主讲切换指示信息后的其他音视频数据,对比与会者身份信息库得到下一个主讲人的身份数据;以及,
202、根据与会者终端预关联的与会者身份数据,查找和确定新主讲的终端,并获取新主讲的音视频数据。
其中,与会者身份信息库为参会前,与会者主动录入或会议发起方主动录入;在身份录入阶段,自动绑定设备识别码、网络地址,以用于配合实现获取主讲的音视频数据。
根据上述内容,应用本方法后,在会议过程中监测主讲的音视频,并在其作出切换指示后,主动对后续的音视频数据识别,追踪并切换至主讲人员选定的下一位主讲,以将新主讲的音视频数据通过会议中心播放,实现会议中心的大屏内容的智能无缝切换,同时,还切换传输给其他与会者的音视频数据,改善会议流畅度和体验。
本方法还包括:
301、获取主讲的稿件数据和稿件的章、节或页的切换设置数据;以及,
302、根据章、节或页的切换设置数据,计算稿件总耗时并基于其生成动态的进度条。
其中,章、节或页的切换设置数据包括各个章、节或页的耗时数据;进度条发送至会议中心和/或与会者的终端。
参照图4,其为进度条示意,其技术可参考clock.html和progress.html;图中的数字代表每页ppt消耗的时间,以及这个PPT或讲演文档需要消耗的整个时间;通过进度条的向右推进,可以精确的掌控没有PPT的耗时,以帮助演讲者调整和控制演讲的时间和进度。
本方法之所以设置上述内容,是因为:
参照图3,现有的网络会议,很多在会议的右边或者左边显示一个时钟计数器(如某讯会议),累计会议的时长,除此之外没有其他作用;而,有培训需求的人群、对演讲时间有明确要求的人群或某些会议的主讲人群,如果能帮助他们把控培训或演讲时间,则可有效提高相关会议质量。
对于章、节或页的切换设置数据的产生方式包括:
分别对各个章、节或页设置耗时;或,
对若干个章、节或页设置耗时;或,
各个章、节或页设置耗时设置为耗时相同,一次性设置。
具体的,例如:PPT文件(稿件)有25页,可以对每页PPT要花费的时间进行单独设定,如第一页1分钟,第二页2分钟;或者对需要耗时间控制的页面进行时间设置;又或者进行统一的耗时设定,如:每页PPT5分钟。
对于本申请而言,上述进度条及其关联设置,不仅仅辅助用户对演讲进度等把控,其还被应用在配合前述的主讲切换,具体的,包括:
401、获取预排的交互活动所发生的章、节或页,作为交互节点;以及,
402、根据交互节点确定其在进度条上预发生的区段,作为交互区段。
其中,预排的交互活动在稿件上传阶段,由相关人员确定;或更为便捷的,在稿件中做交互标记,识别标记自动确定;后续,识别音视频数据执行于交互区段。
上述设置的优势在于:在非必要,如不必做会议摘记等情况时,不在对会议全过程的音视频数据做识别,使得主讲切换更加有针对性,减小资源浪费等。
针对上述,本方法还进一步的设置为:
对音频数据做静音检测;或,获取的音视频数据为静音检测后的数据;
后续,在执行音频转译文字前,对静音检测得到的特殊编码帧剔除。
具体的,静音检测可集成于对采集的语音(音频)处理的编码模块中;静音检测算法配合噪声抑制算法,识别当前是否有语音输入,如果没有语音输入,则编码输出一个特殊的编码帧(比如长度为0);后续,通过对编码帧剔除,可得到更为精准的“音频”数据,减小转译错误、转译成本等。
上述均为主讲的单线交互,而会议等过程中,存在多方同时交互的需求,为此本方法还包括:
501、获取与会者终端的反馈信息;
502、判断是否有举手行为,如果是,则发送举手提示至会议中心;
503、判断会议中心的反馈信息是否同意举行行为,如果是,则传输与会者终端的反馈信息中的音视频数据至会议中心。
上述举手行为包括终端同与会者人机交互产生的举手触发信息,会议中心接收后将其展示于大屏、计算机的交互界面,以告知主讲及相关人员。
根据上述内容,本方法还适用于多人同时在线交互,能满足更多用户需求。
本申请实施例还公开一种基于音视频的主讲跟踪多方网络会议系统。
基于音视频的主讲跟踪多方网络会议系统包括存储器和处理器,所述存储器上存储有能够被处理器加载并执行如上所述中任一种方法的计算机程序。
以上均为本申请的较佳实施例,并非依此限制本申请的保护范围,故:凡依本申请的结构、形状、原理所做的等效变化,均应涵盖于本申请的保护范围之内。