一种集群节点故障检测方法及装置
文献发布时间:2023-06-19 13:45:04
技术领域
本发明涉及计算机技术领域,尤其涉及一种集群节点故障检测方法及装置。
背景技术
随着计算机技术的发展,集群技术不断提高。
在集群运行过程中,当集群中的某个节点出现故障时,集群的整体运行性能将会下降,及时识别故障并进行相应的排障处理,对于集群运行性能的保障具有关键意义。其中,节点出现的故障可以包括显性故障和隐性故障。
但是,现有技术无法有效检测出隐性故障。
发明内容
鉴于上述问题,本发明提供一种克服上述问题或者至少部分地解决上述问题的集群节点故障检测方法及装置,技术方案如下:
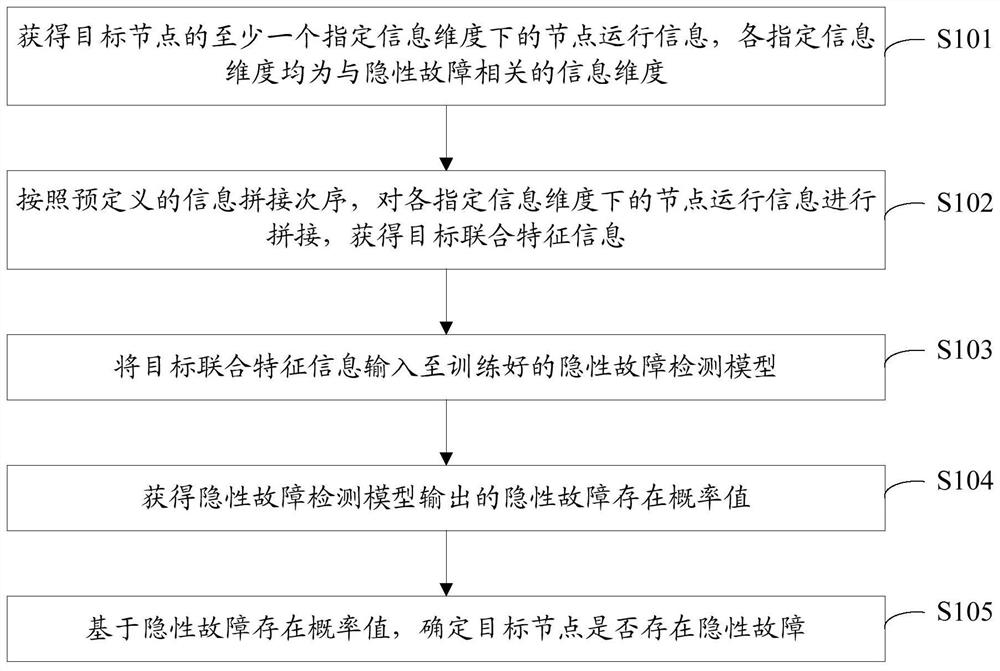
一种集群节点故障检测方法,包括:
获得目标节点的至少一个指定信息维度下的节点运行信息,各所述指定信息维度均为与隐性故障相关的信息维度;
按照预定义的信息拼接次序,对各所述指定信息维度下的节点运行信息进行拼接,获得目标联合特征信息;
将所述目标联合特征信息输入至训练好的隐性故障检测模型,获得所述隐性故障检测模型输出的隐性故障存在概率值;
基于所述隐性故障存在概率值,确定所述目标节点是否存在隐性故障。
可选的,各所述指定信息维度包括:Nmon日志信息维度、负载信息维度、SQL执行信息维度、目标日志信息维度和/或历史故障信息维度。
可选的,所述方法还包括:
确定第一节点的隐性故障时段;
基于所述第一节点在所述隐性故障时段内的节点运行信息和所述第一节点的历史故障信息,获得所述隐性故障检测模型的负样本训练数据;其中,所述第一节点在隐性故障时段内的节点运行信息包括:Nmon日志信息、负载信息、SQL执行信息和/或目标日志信息;
使用所述负样本训练数据,对处于训练阶段的所述隐性故障检测模型进行训练。
可选的,所述确定第一节点的隐性故障时段,包括:
确定所述第一节点的显性故障出现时刻;
确定所述第一节点的隐性故障持续时长;
将在所述显性故障出现时刻之前且与所述显性故障出现时刻间隔隐性故障持续时长的时刻,确定为隐性故障出现时刻;
将由所述隐性故障出现时刻至所述显性故障出现时刻之间的时段,确定为所述隐性故障时段。
可选的,所述方法还包括:
基于集群在指定时段内的平均负载、所述第一节点在所述指定时段内的平均负载和所述第一节点的CPU配置参数,计算出所述隐性故障持续时长。
可选的,所述方法还包括:
确定第二节点的健康运行时段;
基于所述第二节点在所述健康运行时段内的节点运行信息和所述第二节点的历史故障信息,获得所述隐性故障检测模型的正样本训练数据;其中,所述第二节点在健康运行时段内的节点运行信息包括:Nmon日志信息、负载信息、SQL执行信息和/或目标日志信息;
使用所述正样本训练数据,对处于训练阶段的所述隐性故障检测模型进行训练。
一种集群节点故障检测装置,包括:第一获得单元、第一拼接单元、第一输入单元、第二获得单元和第一确定单元;其中:
所述第一获得单元,用于获得目标节点的至少一个指定信息维度下的节点运行信息,各所述指定信息维度均为与隐性故障相关的信息维度;
所述第一拼接单元,用于按照预定义的信息拼接次序,对各所述指定信息维度下的节点运行信息进行拼接,获得目标联合特征信息;
所述第一输入单元,用于将所述目标联合特征信息输入至训练好的隐性故障检测模型;
所述第二获得单元,用于获得所述隐性故障检测模型输出的隐性故障存在概率值;
所述第一确定单元,用于基于所述隐性故障存在概率值,确定所述目标节点是否存在隐性故障。
可选的,各所述指定信息维度包括:Nmon日志信息维度、负载信息维度、SQL执行信息维度、目标日志信息维度和/或历史故障信息维度。
可选的,所述装置还包括:第二确定单元、第三获得单元和第一训练单元;其中:
所述第二确定单元,用于确定第一节点的隐性故障时段;
所述第三获得单元,用于基于所述第一节点在所述隐性故障时段内的节点运行信息和所述第一节点的历史故障信息,获得所述隐性故障检测模型的负样本训练数据;其中,所述第一节点在隐性故障时段内的节点运行信息包括:Nmon日志信息、负载信息、SQL执行信息和/或目标日志信息;
所述第一训练单元,用于使用所述负样本训练数据,对处于训练阶段的所述隐性故障检测模型进行训练。
可选的,所述第二确定单元包括:第三确定单元、第四确定单元、第五确定单元和第六确定单元,其中:
所述第三确定单元,用于确定所述第一节点的显性故障出现时刻;
所述第四确定单元,用于确定所述第一节点的隐性故障持续时长;
所述第五确定单元,用于将在所述显性故障出现时刻之前且与所述显性故障出现时刻间隔隐性故障持续时长的时刻,确定为隐性故障出现时刻;
所述第六确定单元,用于将由所述隐性故障出现时刻至所述显性故障出现时刻之间的时段,确定为所述隐性故障时段。
可选的,所述装置还包括:计算单元;
所述计算单元,用于基于集群在指定时段内的平均负载、所述第一节点在所述指定时段内的平均负载和所述第一节点的CPU配置参数,计算出所述隐性故障持续时长。
可选的,所述装置还包括:第七确定单元、第四获得单元和第二训练单元;
所述第七确定单元,用于确定第二节点的健康运行时段;
所述第四获得单元,用于基于所述第二节点在所述健康运行时段内的节点运行信息和所述第二节点的历史故障信息,获得所述隐性故障检测模型的正样本训练数据;其中,所述第二节点在健康运行时段内的节点运行信息包括:Nmon日志信息、负载信息、SQL执行信息和/或目标日志信息;
所述第二训练单元,用于使用所述正样本训练数据,对处于训练阶段的所述隐性故障检测模型进行训练。
本实施例提出的集群节点故障检测方法及装置,可以通过获得目标节点的至少一个指定信息维度下的节点运行信息,各指定信息维度均为与隐性故障相关的信息维度,按照预定义的信息拼接次序,对各指定信息维度下的节点运行信息进行拼接,获得目标联合特征信息,将目标联合特征信息输入至训练好的隐性故障检测模型,获得隐性故障检测模型输出的隐性故障存在概率值,基于隐性故障存在概率值,确定目标节点是否存在隐性故障。本发明可以分别将集群中的各个节点视作为目标节点进行隐性故障检测,实现对集群中所有节点的隐性故障监测,在节点出现隐性故障时即可以故障定位,并进行排障处理,避免节点的隐性故障发展为显性故障,从而避免给集群整体运行性能产生的不利影响,保障集群整体运行性能,保障集群运行效率。
上述说明仅是本发明技术方案的概述,为了能够更清楚地了解本发明的技术手段,可依照说明书的内容予以实施,并且为了让本发明的上述和其它目的、特征和优点能够更明显易懂,以下特举本发明的具体实施方式。
附图说明
为了更清楚地说明本申请实施例或现有技术中的技术方案,下面将对实施例或现有技术描述中所需要使用的附图作简单地介绍,显而易见地,下面描述中的附图仅仅是本申请的实施例,对于本领域普通技术人员来讲,在不付出创造性劳动的前提下,还可以根据提供的附图获得其他的附图。
图1示出了本发明实施例提供的第一种集群节点故障检测方法的流程图;
图2示出了本发明实施例提供的第二种集群节点故障检测方法的流程图;
图3示出了本发明实施例提供的在一天内对节点不同运行阶段的标记示意图;
图4示出了本发明实施例提供的第一种集群节点故障检测装置的结构示意图;
图5示出了本发明实施例提供的第二种集群节点故障检测装置的结构示意图。
具体实施方式
下面将参照附图更详细地描述本发明的示例性实施例。虽然附图中显示了本发明的示例性实施例,然而应当理解,可以以各种形式实现本发明而不应被这里阐述的实施例所限制。相反,提供这些实施例是为了能够更透彻地理解本发明,并且能够将本发明的范围完整的传达给本领域的技术人员。
如图1所示,本实施例提出了第一种集群节点故障检测方法,该方法可以包括以下步骤:
S101、获得目标节点的至少一个指定信息维度下的节点运行信息,各指定信息维度均为与隐性故障相关的信息维度;
其中,目标节点可以为某个需要检测是否存在隐性故障的节点。
需要说明的是,某个或多个节点存在隐性故障时,节点和集群均可以是未出现明显的故障现象,或者仅出现轻量级的故障现象而未达到明显故障的程度。而现有技术的故障监测手段较为有限,一般情况下,无法监测到节点的隐性故障,只有当节点的隐性故障发展至显性故障,即节点或集群出现明显的数据延迟或者负载较高等明显故障现象时,才能检测到节点出现了故障,也仅在此时才能开始收集日志进行分析,对故障进行定位,确定出现故障的节点。因此,现有技术可能存在无法检测隐性故障,故障定位时间长的问题,而该问题可能进一步导致集群整体运行效率低,整体运行性能下降的问题。对此,本发明可以通过图1所示方法,分别对集群中的各个节点进行隐性故障的监测,在节点出现隐性故障时即可以故障定位,避免节点的隐性故障发展为显性故障,从而避免给集群整体运行性能产生的不利影响,保障集群整体运行性能。
其中,指定信息维度可以是由技术人员在集群运行过程中确定的与隐性故障相关的信息维度。需要说明的是,本发明对于指定信息维度的具体类型不做限定。
其中,集群可以为GreenPlum集群,也可以为其它类型的集群。本发明对于集群的具体类型不做限定。
可选的,各指定信息维度包括:Nmon日志信息维度、负载信息维度、SQL执行信息维度、目标日志信息维度和/或历史故障信息维度。
其中,Nmon日志信息维度下的节点运行信息可以为本发明从指定时段内(比如从当前时刻开始计时的1小时内)的目标节点的Nmon日志信息中统计出的节点运行信息。其中,Nmon日志信息可以为Nmon日志中保存的节点运行信息。
可选的,Nmon日志信息可以包括CPU使用率、磁盘读写速率、内存占用率、虚拟内存使用率和/或文件系统占用率等。需要说明的是,CPU使用率、磁盘读写速率、内存占用率、虚拟内存使用率和文件系统占用率均可以存在包括更细级别的指标。比如,CPU使用率可以包括用户CPU、系统CPU、CPU等待IO和空闲CPU等指标;再比如,磁盘读写速率可以包括磁盘繁忙程度、读速率、写速率、磁盘转换速率等指标。可选的,Nmon日志信息中还可以包括CPU数量、磁盘数量、内存大小、虚拟内存大小、实例数量、磁盘或阵列卡等厂商配置参数信息等。需要说明的是,Nmon日志信息中也可以记录执行uptime时节点的负载信息,但是一天可能只统计一次,主要用于查看节点是否存在重启情况,因此本发明可以无需利用Nmon日志信息中记录的负载信息进行故障检测。
具体的,本发明可以按照采集周期τ
可选的,本发明可以按照统计周期τ
其中,负载信息维度下的节点运行信息可以为本发明从指定时段内(比如从当前时刻开始计时的1小时内)的目标节点的负载信息中统计出的节点运行信息。
需要说明的是,本发明可以参照Nmon日志信息维度下的节点运行信息的信息采集及统计方式,来获得负载信息维度下的节点运行信息。
具体的,本发明可以按照采集周期τ
可选的,负载信息维度下的节点运行信息中还可以包括目标数据,该目标数据可以用于标记目标节点的负载是否排在集群中所有节点负载的前列位置(比如前六名)。可选的,目标数据可以为0或1,当目标节点的负载排在集群中所有节点负载的前列位置时,目标数据可以为1,当目标节点的负载未排在集群中所有节点负载的前列位置时,目标数据可以为0。
可选的,本发明可以按照统计周期τ
可选的,本发明可以将τ
其中,SQL执行信息维度下的节点运行信息可以为本发明从指定时段内(比如从当前时刻开始计时的1小时内)的目标节点的SQL执行信息中统计出的信息。可选的,SQL执行信息可以包括SQL执行时长和新SQL的间隔时间。需要说明的是,如果SQL执行时间合理,没有长时间执行未结束的情况,并且不断有新的SQL语句即将执行,则集群的健康情况可能较好。
需要说明的是,本发明可以参照Nmon日志信息维度和负载信息维度下的节点运行信息的信息采集及统计方式,来获得SQL执行信息维度下的节点运行信息。
可选的,SQL执行信息维度下的节点运行信息的统计周期也可以为τ
其中,目标日志信息维度下的节点运行信息可以为本发明从指定时段内的目标节点的目标日志信息中采集到的节点运行信息。
其中,目标日志可以为除Nmon日志之外的日志。可选的,目标日志可以包括操作系统日志和/或特定厂商日志。
需要说明的是,操作系统日志和特定厂商日志中可以记录有很多有助于判断故障的关键字信息,例如reset、rejected I/O、hardware error和IO failure等。而日志文件信息和普通的文本信息具有较大差异,日志文件信息中可以存在有大量重复字词,因此,本发明可以本文会先统计日志中关键词的出现次数,并且去掉意义较小的并且出现次数较多的关键字,然后统计具有较大意义的关键字的文本特征。另,TF-IDF处理方式是传统的文本特征表示方式,本发明可以使用TF-IDF处理方式获得一些关键词的文本特征,为补充TF-IDF处理方式没有表示到的词,本发明可以采用文本处理模型对操作系统日志和特定厂商日志中的文本进行相应处理。
可选的,本发明可以利用TF-IDF处理方式和文本处理模型,分别对操作系统日志和特定厂商日志中的文本进行相应处理,获得相应的文本特征。其中,文本处理模型可以为word2vec、GloVe和BERT等模型。
需要说明的是,本发明可以参照Nmon日志信息维度和负载信息维度下的节点运行信息的信息采集及统计方式,来获得目标日志信息维度下的节点运行信息。
其中,历史故障信息维度下的节点运行信息可以为本发明从指定时段内的目标节点的历史故障信息和/或备节点的历史故障信息中,统计出的故障信息,比如故障次数和故障间隔时长。
需要说明的是,本发明可以参照Nmon日志信息维度和负载信息维度下的节点运行信息的信息采集及统计方式,来获得历史故障信息维度下的节点运行信息。
可选的,本发明可以按照统计周期τ
其中,备节点可以为目标节点的备用节点。需要说明的是,在集群运行过程中,目标节点及其备节点均可以负责处理各自的任务,当目标节点出现故障时,集群可以将原本由目标节点负责处理的任务可以转移至备节点中进行处理,此时备节点负载可能较高,导致备节点运行性能下降,从而导致集群的整体运行性能下降(集群的整体运行性能可以存在木桶效应,即整体运行性能可以取决于运行性能最不好的那个节点)。
可选的,历史故障信息维度下的节点运行信息中还可以包括本次统计的故障信息与上次统计的故障信息的特征距离或相似度,例如欧氏距离,曼哈顿距离、余弦相似度和皮尔逊系数等。需要说明的是,目标节点至今未发生过故障,则相似度可以为0。
可以理解的是,本发明在统计获得各指定信息维度下的节点运行的过程中,采集周期可以是不同的,统计周期可以是相同的(比如均可以为τ
S102、按照预定义的信息拼接次序,对各指定信息维度下的节点运行信息进行拼接,获得目标联合特征信息;
其中,信息拼接次序可以由技术人员根据实际故障检测效果进行设置,本发明对此不做限定。
可选的,本发明可以将Nmon日志信息维度、负载信息维度、SQL执行信息维度、目标日志信息维度和历史故障信息维度下的节点运行信息,依次进行拼接,将拼接所获得的信息确定为目标联合特征信息。
S103、将目标联合特征信息输入至训练好的隐性故障检测模型;
需要说明的是,本发明可以通过使用相应的正样本数据和负样本数据,对隐性故障检测模型进行训练,使得隐性故障检测模型可以在接收到目标联合特征信息之后,输出用于衡量是否存在隐性故障的故障率。
其中,本发明对于隐性故障检测模型的模型类型不做限定。比如,隐性故障检测模型可以为对数几率回归、决策树、GBDT、VM和多层感知机等机器学习模型。
S104、获得隐性故障检测模型输出的隐性故障存在概率值;
其中,隐性故障存在概率值即可以为用于衡量目标节点是否存在隐性故障的概率值。
可选的,隐性故障存在概率值可以为不小于0且不大于1的实数。可选的,当隐性故障存在概率值越大时,目标节点存在隐性故障的概率越大;当隐性故障存在概率值越小时,目标节点存在隐性故障的概率越小。
S105、基于隐性故障存在概率值,确定目标节点是否存在隐性故障。
可选的,本发明可以由技术人员预先设置概率阈值,并根据概率阈值和隐性故障检测模型输出的隐性故障存在概率值之间的大小关系,来确定目标节点是否存在隐性故障。
其中,当隐性故障检测模型输出的隐性故障存在概率值大于概率阈值时,本发明可以确定目标节点存在隐性故障;当隐性故障存在概率值不大于概率阈值时,本发明可以确定目标节点不存在隐性故障。
可以理解的是,本发明可以分别将集群中的各个节点视作为目标节点,并执行图1所示方法,实现对集群中所有节点的隐性故障监测,在节点出现隐性故障时即可以故障定位,并进行排障处理,避免节点的隐性故障发展为显性故障,从而避免给集群整体运行性能产生的不利影响,保障集群整体运行性能,保障集群运行效率。
本实施例提出的集群节点故障检测方法,可以通过获得目标节点的至少一个指定信息维度下的节点运行信息,各指定信息维度均为与隐性故障相关的信息维度,按照预定义的信息拼接次序,对各指定信息维度下的节点运行信息进行拼接,获得目标联合特征信息,将目标联合特征信息输入至训练好的隐性故障检测模型,获得隐性故障检测模型输出的隐性故障存在概率值,基于隐性故障存在概率值,确定目标节点是否存在隐性故障。本发明可以分别将集群中的各个节点视作为目标节点进行隐性故障检测,实现对集群中所有节点的隐性故障监测,在节点出现隐性故障时即可以故障定位,并进行排障处理,避免节点的隐性故障发展为显性故障,从而避免给集群整体运行性能产生的不利影响,保障集群整体运行性能,保障集群运行效率。
基于图1所示步骤,如图2所示,本实施例提出第二种集群节点故障检测方法。该方法还可以包括以下步骤:
S201、确定第一节点的隐性故障时段;
其中,第一节点可以为集群中的某个节点。
其中,隐性故障时段可以为节点在存在隐性故障下的运行时段。
需要说明的是,本发明可以基于第一节点的显性故障出现时刻,确定第一节点的隐性故障时段,之后基于第一节点在隐性故障时段内的节点运行信息,获得隐性故障检测模型的负样本训练数据。
可选的,本发明可以将节点出现显性故障前的指定时长内的时段,确定为隐性故障时段。
可选的,在本实施例提出的其它集群节点故障检测方法中,步骤S201可以包括:
确定第一节点的显性故障出现时刻;
确定第一节点的隐性故障持续时长;
将在显性故障出现时刻之前且与显性故障出现时刻间隔隐性故障持续时长的时刻,确定为隐性故障出现时刻;
将由隐性故障出现时刻至显性故障出现时刻之间的时段,确定为隐性故障时段。
其中,显性故障出现时刻可以为检测出目标节点存在显性故障的时刻。
具体的,本发明可以利用现有的故障检测方式来检测目标节点可能出现的显性故障。
其中,隐性故障持续时长可以为隐性故障出现时刻至显性故障出现时刻所经历的时长。可以理解的是,隐性故障持续时长即可以为隐性故障由开始出现,至发展为显性故障所经历的时长。具体的,隐性故障持续时长可以由技术人员根据实际工作情况进行设置,本发明对此不作限定。
具体的,隐性故障时段可以为由隐性故障出现时刻至显性故障出现时刻之间的时段。可以理解的是,隐性故障时段内的时长即可以为隐性故障持续时长。比如,如果隐性故障时长为2小时,则本发明可以在某一天的16点检测到目标节点出现显性故障,即显性故障出现时刻为16点时,立即将目标节点进行隔离修复,并将在16点前2个小时的时刻即14点确定为隐性故障出现时刻,之后将14点至16点的时段确定为隐性故障时段。
可选的,本发明可以在节点每出现显性故障时,记录节点的显性故障出现时刻,并记录节点的修复时长以及重新投入使用的时刻等信息。比如,如图3所示,本发明可以在某一天24小时内对某个节点的不同运行阶段进行记录,其中,该节点在16点出现显性故障并进行隔离维护,直至19点维护完毕,重新恢复使用,本发明可以将16点确定为该节点本次显性故障的出现时刻,将16点至19点之前的时段确定为维护时段,将16点之前的2个小时即14点至16点之间的时段确定为隐性故障时段。可以理解的是,本发明可以基于记录的节点的历史运行信息,在不同时段内确定相应的训练样本数据,比如,在隐性故障时段内确定负样本训练数据。
需要说明的是,本发明可以基于以下几个因素来计算隐性故障持续时长:(1)隐性故障持续时长的长短与负载的高低有关,不同业务和不同时间的集群负载是不一样的。负载较高的集群,隐性故障持续时长可以较短;负载较低的集群,隐性故障持续时长可以较长。隐性故障持续时长可以与负载成反比关系。因此,本发明可以根据负载来计算隐性故障持续时长;(2)负载数值代表的强弱与CPU的性能有关。相同数值的负载,如果CPU性能较差,则此时负载较强;如果CPU性能较好,则此时负载较弱;(3)如果集群中某个节点的负载高于集群整体平均负载,则该节点故障的概率相应也会增加。(4)计算出来的隐性故障持续时长需要一个合理的范围,如果计算出来的隐性故障持续时长为12小时,其在实际生产运维过程中显然是不合理的。
可选的,在本实施例提出的其它集群节点故障检测方法中,还可以包括:
基于集群在指定时段内的平均负载、第一节点在指定时段内的平均负载和第一节点的CPU配置参数,计算出隐性故障持续时长。
可选的,本发明可以将隐性故障持续时长控制在1至2小时内。
可选的,CPU配置参数可以包括目标节点中的CPU个数、CPU核数和CPU核线程数。
可选的,本发明可以利用隐性故障持续时长计算公式,来计算隐性故障持续时长。其中,隐性故障持续时长计算公式可以包括:
其中,t为隐性故障持续时长,n
S202、基于第一节点在隐性故障时段内的节点运行信息和第一节点的历史故障信息,获得隐性故障检测模型的负样本训练数据;其中,第一节点在隐性故障时段内的节点运行信息包括:Nmon日志信息、负载信息、SQL执行信息和/或目标日志信息;
可以理解的是,本发明可以基于第一节点在隐性故障时段内的各指定信息维度下的节点运行信息,获得隐性故障检测模型的负样本训练数据。
S203、使用负样本训练数据,对处于训练阶段的隐性故障检测模型进行训练。
具体的,本发明可以使用负样本训练数据,对隐性故障检测模型进行训练,提高隐性故障检测模型的检测性能。
本实施例提出的集群节点故障检测方法,可以获得隐性故障检测模型的负样本训练数据,并使用负样本训练数据对隐性故障检测模型进行训练。
基于图1,本实施例提出第三种集群节点故障检测方法,该方法还可以包括:
确定第二节点的健康运行时段;
基于第二节点在健康运行时段内的节点运行信息和第二节点的历史故障信息,获得隐性故障检测模型的正样本训练数据;其中,第二节点在健康运行时段内的节点运行信息包括:Nmon日志信息、负载信息、SQL执行信息和/或目标日志信息;
使用正样本训练数据,对处于训练阶段的隐性故障检测模型进行训练。
其中,第二节点可以为集群中的某个节点。需要说明的是,第二节点与上述第一节点可以为同一节点,也可以为不同节点,本发明对此不作限定。
其中,健康运行时段可以为第二节点在未存在隐性故障和显性故障情况下的运行时段。
具体的,本发明可以基于第二节点在健康运行时段内的各指定信息维度下的节点运行信息,获得隐性故障检测模型的正样本训练数据。
具体的,本发明可以在获得隐性故障检测模型的正样本训练数据之后,使用正样本训练数据对隐性故障检测模型进行训练,提高隐性故障检测模型的检测性能。
可选的,在本实施例提出的其它集群节点故障检测方法中,本发明可以基于某个节点在隐性故障时段内的各指定信息维度下的节点运行信息,获得隐性故障检测模型的负样本训练数据,可以基于某个节点在健康运行时段内的各指定信息维度下的节点运行信息,获得隐性故障检测模型的正样本训练数据,使用负样本训练数据和正样本数据,对隐性故障检测模型进行训练,保障隐性故障检测模型的检测性能。
可以理解的是,一般情况下,隐性故障时段的时长远低于健康运行时段,本发明如果按照相同的统计周期来获得样本训练数据,则正样本训练数据的数量将远大于负样本训练数据,可能导致训练样本过拟合的问题。比如,如图3所示,一天24小时,节点发生故障并且隔离维护的时间可以为3小时,隐性故障持续时长可以为2小时,那么在一天中,健康运行时段可以为19小时,隐性故障时段可以为2小时。按照统计周期为1小时计算,这样一天会有19个正样本训练数据,2个负样本训练数据,19:2极有可能产生过拟合。此时,本发明可以按照不同的统计周期来获得正样本训练数据和负样本训练数据,比如按照1小时的统计周期来获得正样本训练数据,此时19小时可以产生19个正样本训练数据,按照15分钟的统计周期来获得负样本训练数据,此时2小时可以产生8个负样本训练数据,这样19:8的样本数据之比可以稍微缓解一些样本不均衡情况。
可选的,本发明可以禁止采集集群在某个节点处于维护状态时的运行数据作为样本训练数据。如图3所示,本发明可以禁止采集集群在16点至19点之内的运行数据作为样本训练数据。可以理解的是,本发明需要收集的数据可以包括集群在无故障时段内的运行数据(正样本数据),集群在发生隐性故障时的且有利于在故障发生之前识别隐性故障的运行数据(负样本数据)。当集群中某个节点处于隔离阶段时,此时集群的运行数据是存在有显性故障的运行数据,该节点对应的备节点负载会增加,这个时候收集到的集群运行数据不属于正样本训练数据,也不属于负样本训练数据,而是属于干扰数据,本发明无需对干扰数据进行学习。可选的,当集群为GreenPlum集群时,本发明可以通过数据库的gp_configuration_history表中查询实例隔离时间,并将这段时间内采集到的数据剔除。
可选的,本发明在训练隐性故障检测模型时,可以采用k折交叉验证的方式重复利用负样本数据,进一步缓解样本不均衡的问题。
可选的,本发明也可以采用SMOTE过采样的方式来缓解样本不均衡的情况。
可选的,本发明在训练隐性故障检测模型时,在降维方面可以采用LDA有监督的线性降维方式进行降维;本发明也可以在模型训练前期,利用对数几率回归、随机森林和GBDT等方式筛选出一些与标记相关性较高的特征,以达到降维的目的。
可选的,本发明在存储方面,可以txt格式对采集的不同指定维度下的节点运行信息进行存储,以csv、json以及npy等格式对提取特征后的数据存储,以hdf5格式对模型参数文件存储。
可以理解的是,本发明可以在业务发展过程中不断的获得新的训练样本数据,并可以使用新的训练样本对隐性故障检测模型进行训练,此时本发明训练出的隐性故障检测模型可以是逐步变化的。具体的,本发明可以周期性的对训练好的隐性故障检测模型进行保存,如果当前时间的隐性故障检测模型的检测效果不佳,则本发明可以重新使用已保存的此前时间的隐性故障检测模型,即进行模型的回退。比如,本发明可以保存近一年内每个月的隐性故障检测模型。
本实施例提出的集群节点故障检测方法,可以获得隐性故障检测模型的正样本训练数据,并使用正样本训练数据对隐性故障检测模型进行训练,也可以使用正样本训练数据和负样本训练数据对隐性故障检测模型进行训练,保障隐性故障检测模型的检测效果。
与图1所示步骤相对应,如图4所示,本实施例提出第一种集群节点故障检测装置,该装置可以包括:第一获得单元101、拼接单元102、第一输入单元103、第二获得单元104和第一确定单元105;其中:
第一获得单元101,用于获得目标节点的至少一个指定信息维度下的节点运行信息,各指定信息维度均为与隐性故障相关的信息维度;
其中,目标节点可以为某个需要检测是否存在隐性故障的节点。
其中,指定信息维度可以是由技术人员在集群运行过程中确定的与隐性故障相关的信息维度。需要说明的是,本发明对于指定信息维度的具体类型不做限定。
其中,集群可以为GreenPlum集群,也可以为其它类型的集群。本发明对于集群的具体类型不做限定。
可选的,各指定信息维度包括:Nmon日志信息维度、负载信息维度、SQL执行信息维度、目标日志信息维度和/或历史故障信息维度。
其中,Nmon日志信息维度下的节点运行信息可以为本发明从指定时段内(比如从当前时刻开始计时的1小时内)的目标节点的Nmon日志信息中统计出的节点运行信息。其中,Nmon日志信息可以为Nmon日志中保存的节点运行信息。
可选的,Nmon日志信息可以包括CPU使用率、磁盘读写速率、内存占用率、虚拟内存使用率和/或文件系统占用率等。需要说明的是,CPU使用率、磁盘读写速率、内存占用率、虚拟内存使用率和文件系统占用率均可以存在包括更细级别的指标。需要说明的是,Nmon日志信息中也可以记录执行uptime时节点的负载信息,但是一天可能只统计一次,主要用于查看节点是否存在重启情况,因此本发明可以无需利用Nmon日志信息中记录的负载信息进行故障检测。
具体的,本发明可以按照采集周期τ
可选的,本发明可以按照统计周期τ
其中,负载信息维度下的节点运行信息可以为本发明从指定时段内(比如从当前时刻开始计时的1小时内)的目标节点的负载信息中统计出的节点运行信息。
需要说明的是,本发明可以参照Nmon日志信息维度下的节点运行信息的信息采集及统计方式,来获得负载信息维度下的节点运行信息。
具体的,本发明可以按照采集周期τ
可选的,负载信息维度下的节点运行信息中还可以包括目标数据,该目标数据可以用于标记目标节点的负载是否排在集群中所有节点负载的前列位置(比如前六名)。可选的,目标数据可以为0或1,当目标节点的负载排在集群中所有节点负载的前列位置时,目标数据可以为1,当目标节点的负载未排在集群中所有节点负载的前列位置时,目标数据可以为0。
可选的,本发明可以按照统计周期τ
可选的,本发明可以将τ
其中,SQL执行信息维度下的节点运行信息可以为本发明从指定时段内(比如从当前时刻开始计时的1小时内)的目标节点的SQL执行信息中统计出的信息。可选的,SQL执行信息可以包括SQL执行时长和新SQL的间隔时间。需要说明的是,如果SQL执行时间合理,没有长时间执行未结束的情况,并且不断有新的SQL语句即将执行,则集群的健康情况可能较好。
需要说明的是,本发明可以参照Nmon日志信息维度和负载信息维度下的节点运行信息的信息采集及统计方式,来获得SQL执行信息维度下的节点运行信息。
可选的,SQL执行信息维度下的节点运行信息的统计周期也可以为τ
其中,目标日志信息维度下的节点运行信息可以为本发明从指定时段内的目标节点的目标日志信息中采集到的节点运行信息。
其中,目标日志可以为除Nmon日志之外的日志。可选的,目标日志可以包括操作系统日志和/或特定厂商日志。
需要说明的是,操作系统日志和特定厂商日志中可以记录有很多有助于判断故障的关键字信息,例如reset、rejected I/O、hardware error和IO failure等。而日志文件信息和普通的文本信息具有较大差异,日志文件信息中可以存在有大量重复字词,因此,本发明可以本文会先统计日志中关键词的出现次数,并且去掉意义较小的并且出现次数较多的关键字,然后统计具有较大意义的关键字的文本特征。另,TF-IDF处理方式是传统的文本特征表示方式,本发明可以使用TF-IDF处理方式获得一些关键词的文本特征,为补充TF-IDF处理方式没有表示到的词,本发明可以采用文本处理模型对操作系统日志和特定厂商日志中的文本进行相应处理。
可选的,本发明可以利用TF-IDF处理方式和文本处理模型,分别对操作系统日志和特定厂商日志中的文本进行相应处理,获得相应的文本特征。其中,文本处理模型可以为word2vec、GloVe和BERT等模型。
需要说明的是,本发明可以参照Nmon日志信息维度和负载信息维度下的节点运行信息的信息采集及统计方式,来获得目标日志信息维度下的节点运行信息。
其中,历史故障信息维度下的节点运行信息可以为本发明从指定时段内的目标节点的历史故障信息和/或备节点的历史故障信息中,统计出的故障信息,比如故障次数和故障间隔时长。
需要说明的是,本发明可以参照Nmon日志信息维度和负载信息维度下的节点运行信息的信息采集及统计方式,来获得历史故障信息维度下的节点运行信息。
可选的,本发明可以按照统计周期τ
其中,备节点可以为目标节点的备用节点。
可选的,历史故障信息维度下的节点运行信息中还可以包括本次统计的故障信息与上次统计的故障信息的特征距离或相似度,例如欧氏距离,曼哈顿距离、余弦相似度和皮尔逊系数等。需要说明的是,目标节点至今未发生过故障,则相似度可以为0。
可以理解的是,本发明在统计获得各指定信息维度下的节点运行的过程中,采集周期可以是不同的,统计周期可以是相同的(比如均可以为τ
拼接单元102,用于按照预定义的信息拼接次序,对各指定信息维度下的节点运行信息进行拼接,获得目标联合特征信息;
其中,信息拼接次序可以由技术人员根据实际故障检测效果进行设置,本发明对此不做限定。
可选的,本发明可以将Nmon日志信息维度、负载信息维度、SQL执行信息维度、目标日志信息维度和历史故障信息维度下的节点运行信息,依次进行拼接,将拼接所获得的信息确定为目标联合特征信息。
第一输入单元103,用于将目标联合特征信息输入至训练好的隐性故障检测模型;
需要说明的是,本发明可以通过使用相应的正样本数据和负样本数据,对隐性故障检测模型进行训练,使得隐性故障检测模型可以在接收到目标联合特征信息之后,输出用于衡量是否存在隐性故障的故障率。
其中,本发明对于隐性故障检测模型的模型类型不做限定。比如,隐性故障检测模型可以为对数几率回归、决策树、GBDT、VM和多层感知机等机器学习模型。
第二获得单元104,用于获得隐性故障检测模型输出的隐性故障存在概率值;
其中,隐性故障存在概率值即可以为用于衡量目标节点是否存在隐性故障的概率值。
可选的,隐性故障存在概率值可以为不小于0且不大于1的实数。可选的,当隐性故障存在概率值越大时,目标节点存在隐性故障的概率越大;当隐性故障存在概率值越小时,目标节点存在隐性故障的概率越小。
第一确定单元105,用于基于隐性故障存在概率值,确定目标节点是否存在隐性故障。
可选的,本发明可以由技术人员预先设置概率阈值,并根据概率阈值和隐性故障检测模型输出的隐性故障存在概率值之间的大小关系,来确定目标节点是否存在隐性故障。
其中,当隐性故障检测模型输出的隐性故障存在概率值大于概率阈值时,本发明可以确定目标节点存在隐性故障;当隐性故障存在概率值不大于概率阈值时,本发明可以确定目标节点不存在隐性故障。
本实施例提出的集群节点故障检测装置,可以分别将集群中的各个节点视作为目标节点进行隐性故障检测,实现对集群中所有节点的隐性故障监测,在节点出现隐性故障时即可以故障定位,并进行排障处理,避免节点的隐性故障发展为显性故障,从而避免给集群整体运行性能产生的不利影响,保障集群整体运行性能,保障集群运行效率。
基于图4,如图5所示,本实施例提出第二种集群节点故障检测装置,该装置还可以包括:第二确定单元201、第三获得单元202和第一训练单元203;其中:
第二确定单元201,用于确定第一节点的隐性故障时段;
其中,第一节点可以为集群中的某个节点。
其中,隐性故障时段可以为节点在存在隐性故障下的运行时段。
需要说明的是,本发明可以基于第一节点的显性故障出现时刻,确定第一节点的隐性故障时段,之后基于第一节点在隐性故障时段内的节点运行信息,获得隐性故障检测模型的负样本训练数据。
可选的,本发明可以将节点出现显性故障前的指定时长内的时段,确定为隐性故障时段。
可选的,在本实施例提出的其它集群节点故障检测装置中,第二确定单元201包括:第三确定单元、第四确定单元、第五确定单元和第六确定单元,其中:
第三确定单元,用于确定第一节点的显性故障出现时刻;
第四确定单元,用于确定第一节点的隐性故障持续时长;
第五确定单元,用于将在显性故障出现时刻之前且与显性故障出现时刻间隔隐性故障持续时长的时刻,确定为隐性故障出现时刻;
第六确定单元,用于将由隐性故障出现时刻至显性故障出现时刻之间的时段,确定为隐性故障时段。
其中,显性故障出现时刻可以为检测出目标节点存在显性故障的时刻。
具体的,本发明可以利用现有的故障检测方式来检测目标节点可能出现的显性故障。
其中,隐性故障持续时长可以为隐性故障出现时刻至显性故障出现时刻所经历的时长。可以理解的是,隐性故障持续时长即可以为隐性故障由开始出现,至发展为显性故障所经历的时长。具体的,隐性故障持续时长可以由技术人员根据实际工作情况进行设置,本发明对此不作限定。
具体的,隐性故障时段可以为由隐性故障出现时刻至显性故障出现时刻之间的时段。可以理解的是,隐性故障时段内的时长即可以为隐性故障持续时长。
可选的,本发明可以在节点每出现显性故障时,记录节点的显性故障出现时刻,并记录节点的修复时长以及重新投入使用的时刻等信息。
可选的,在本实施例提出的其它集群节点故障检测装置中,还可以包括:计算单元;
计算单元,用于基于集群在指定时段内的平均负载、第一节点在指定时段内的平均负载和第一节点的CPU配置参数,计算出隐性故障持续时长。
可选的,本发明可以将隐性故障持续时长控制在1至2小时内。
可选的,CPU配置参数可以包括目标节点中的CPU个数、CPU核数和CPU核线程数。
可选的,本发明可以利用隐性故障持续时长计算公式,来计算隐性故障持续时长。其中,隐性故障持续时长计算公式可以包括:
其中,t为隐性故障持续时长,n
第三获得单元202,用于基于第一节点在隐性故障时段内的节点运行信息和第一节点的历史故障信息,获得隐性故障检测模型的负样本训练数据;其中,第一节点在隐性故障时段内的节点运行信息包括:Nmon日志信息、负载信息、SQL执行信息和/或目标日志信息;
可以理解的是,本发明可以基于第一节点在隐性故障时段内的各指定信息维度下的节点运行信息,获得隐性故障检测模型的负样本训练数据。
第一训练单元203,用于使用负样本训练数据,对处于训练阶段的隐性故障检测模型进行训练。
具体的,本发明可以使用负样本训练数据,对隐性故障检测模型进行训练,提高隐性故障检测模型的检测性能。
本实施例提出的集群节点故障检测装置,可以获得隐性故障检测模型的负样本训练数据,并使用负样本训练数据对隐性故障检测模型进行训练。
基于图4,本实施例提出第三种集群节点故障检测装置,该装置还可以包括:第七确定单元、第四获得单元和第二训练单元;
第七确定单元,用于确定第二节点的健康运行时段;
第四获得单元,用于基于第二节点在健康运行时段内的节点运行信息和第二节点的历史故障信息,获得隐性故障检测模型的正样本训练数据;其中,第二节点在健康运行时段内的节点运行信息包括:Nmon日志信息、负载信息、SQL执行信息和/或目标日志信息;
第二训练单元,用于使用正样本训练数据,对处于训练阶段的隐性故障检测模型进行训练。
其中,第二节点可以为集群中的某个节点。需要说明的是,第二节点与上述第一节点可以为同一节点,也可以为不同节点,本发明对此不作限定。
其中,健康运行时段可以为第二节点在未存在隐性故障和显性故障情况下的运行时段。
具体的,本发明可以基于第二节点在健康运行时段内的各指定信息维度下的节点运行信息,获得隐性故障检测模型的正样本训练数据。
具体的,本发明可以在获得隐性故障检测模型的正样本训练数据之后,使用正样本训练数据对隐性故障检测模型进行训练,提高隐性故障检测模型的检测性能。
可选的,在本实施例提出的其它集群节点故障检测装置中,本发明可以基于某个节点在隐性故障时段内的各指定信息维度下的节点运行信息,获得隐性故障检测模型的负样本训练数据,可以基于某个节点在健康运行时段内的各指定信息维度下的节点运行信息,获得隐性故障检测模型的正样本训练数据,使用负样本训练数据和正样本数据,对隐性故障检测模型进行训练,保障隐性故障检测模型的检测性能。
可选的,本发明在训练隐性故障检测模型时,在降维方面可以采用LDA有监督的线性降维方式进行降维;本发明也可以在模型训练前期,利用对数几率回归、随机森林和GBDT等方式筛选出一些与标记相关性较高的特征,以达到降维的目的。
可选的,本发明在存储方面,可以txt格式对采集的不同指定维度下的节点运行信息进行存储,以csv、json以及npy等格式对提取特征后的数据存储,以hdf5格式对模型参数文件存储。
本实施例提出的集群节点故障检测装置,可以获得隐性故障检测模型的正样本训练数据,并使用正样本训练数据对隐性故障检测模型进行训练,也可以使用正样本训练数据和负样本训练数据对隐性故障检测模型进行训练,保障隐性故障检测模型的检测效果。
还需要说明的是,术语“包括”、“包含”或者其任何其他变体意在涵盖非排他性的包含,从而使得包括一系列要素的过程、方法、商品或者设备不仅包括那些要素,而且还包括没有明确列出的其他要素,或者是还包括为这种过程、方法、商品或者设备所固有的要素。在没有更多限制的情况下,由语句“包括一个……”限定的要素,并不排除在包括要素的过程、方法、商品或者设备中还存在另外的相同要素。
以上仅为本申请的实施例而已,并不用于限制本申请。对于本领域技术人员来说,本申请可以有各种更改和变化。凡在本申请的精神和原理之内所作的任何修改、等同替换、改进等,均应包含在本申请的权利要求范围之内。
- 一种集群节点故障检测方法及装置
- 集群系统中节点的故障检测方法和装置