面向分布式系统的失效恢复机制自动化测试方法及装置
文献发布时间:2023-06-19 18:27:32
技术领域
本发明属于软件技术领域,尤其涉及一种面向分布式系统的失效恢复机制自动化测试方法及装置。
背景技术
在大数据和云计算时代,分布式系统(Distributed Systems)已经成为现代应用程序的主要支柱,为用户提供可靠支撑。以分布式存储系统HDFS、集群管理服务YARN、分布式计算框架MapReduce、分布式协调服务ZooKeeper等为代表的分布式系统在大型互联网公司,如阿里巴巴、百度、腾讯、谷歌等得到广泛部署应用。大规模分布式系统管理大量分布式软件组件、硬件及其配置,通常由成千上万台物理机器(即计算节点,Node)组成。系统中数量众多的计算节点需要协同工作,运行各种复杂协议,面临各种非确定性场景(如网络、故障)。
可靠性和故障容忍是现代分布式系统的首要目标。由于断电、硬件错误、软件错误等原因,分布式集群中的节点不可避免地会发生失效(Crash)故障,使节点不可访问。随着分布式集群中节点规模的扩大,节点失效也变得更为常见。当一个节点失效发生后,正在节点上运行的任务以及节点内存数据会立即丢失,而集群中其他活动节点可能会无法正常工作(如主节点失效)。为了应对节点失效,开发者在分布式系统中引入了各种复杂的自动失效恢复机制,如HBase中的预写日志机制会持久化每一个写请求到日志文件,一旦节点失效,就可以通过重放日志来恢复节点失效之前的数据。
然而,对分布式系统而言,正确处理节点失效具有挑战。分布式系统的失效恢复处理本身也会出错。节点失效可能会在任意时刻发生在任意节点上,从而导致各种各样的失效场景,例如导致持久化状态部分更新以及内存数据丢失等。分布式系统本身的复杂性也加剧了失效恢复的复杂性。开发者难以预测所有可能的失效场景,也难以保证失效恢复机制都被正确地实现。此外,在系统测试阶段,通过自动化注入节点失效来彻底测试分布式系统也不具备可行性。因此不正确的失效恢复机制及其实现会引入错综复杂的失效恢复缺陷(Crash Recovery Bugs),从而导致集群无服务、节点不可访问、数据丢失等严重后果,影响分布式系统可靠性、可用性和性能。
现有的可用于检测失效恢复缺陷、测试分布式系统故障恢复正确性的工作主要基于故障注入技术,包括实现级分布式系统模型检查器、基于故障注入的分布式系统测试框架和基于程序分析技术的缺陷检测技术。其中实现级分布式系统模型检查器如Modist(Junfeng Yang et al.“MODIST:Transparent Model Checking of UnmodifiedDistributed Systems”.Proc.NSDI 2009.)、SAMC(Tanakorn Leesatapornwongsa et al.“SAMC:Semantic-Aware Model Checking for Fast Discovery of Deep Bugs in CloudSystems”.Proc.OSDI 2014.)、FlyMC(Jeffrey F Lukman et al.“FlyMC:Highly ScalableTesting of Complex Interleavings in Distributed Systems”.Proc EuroSys 2019.)等通过拦截分布式系统中的各种不确定性事件(如网络消息和故障),并对它们的执行顺序重新排序,来系统地枚举所有可能的执行路径,从而暴露只有在特殊执行路径下才会被触发的缺陷。这些分布式系统模型检查器在测试中不考虑故障或多数只考虑注入一个节点失效。另外,由于这些分布式系统模型检查器不止检测与节点失效相关的缺陷,因此在暴露一个失效恢复缺陷之前,这些方法会探索大量与节点失效无关的状态空间。分布式模型检查器面临的最大问题,是在应用于真实的分布式系统时的状态搜索空间爆炸问题。基于故障注入的分布式系统测试框架强调在系统中注入包括节点失效/重启在内的各种故障,来测试系统在异常情况下的表现行为。随机故障注入框架例如Chaos Monkey(https://netflix.github.io/chaosmonkey/)和Jepsen(https://github.com/jepsen-io/jepsen)可以随机注入节点失效,试图通过多次运行来触发一个缺陷。PreFail(Pallavi Joshi etal.“PREFAIL:A Programmable Tool for Multiple-Failure Injection”.Proc.OOPSLA2011.)是一个可编程的故障注入工具,允许测试人员自定义各种故障注入策略。Fate(Haryadi S.Gunawi et al.“FATE and DESTINI:A Framework for Cloud RecoveryTesting”.Proc.NSDI 2011.)通过抽象故障ID来系统地搜索故障场景空间,测试多种故障的组合。与分布式系统模型检查器相比,这些基于故障注入的分布式系统测试框架并不系统地控制各种非确定性事件的执行顺序,其面临的主要问题在于故障场景空间爆炸问题。通过程序分析技术来检测失效恢复缺陷的工作如FCatch(Haopeng Liu et al.“FCatch:Automatically Detecting Time-of-Fault Bugs in Cloud Systems”.Proc.ASPLOS2018.)和CrashTuner(Jie Lu et al.“CrashTuner:Detecting Crash-Recovery Bugs inCloud Systems via Meta-Info Analysis”.Proc.SOSP 2019.)基于特定的缺陷模式来进行缺陷检测,这些方法只能覆盖有限的故障场景空间。
综上所述,现有的针对分布式系统失效恢复缺陷检测的工作或者只能覆盖有限的故障场景空间、或者依赖测试人员经验、或者面临空间爆炸问题,因此这些方法在系统化测试分布式系统、暴露失效恢复缺陷方面仍然具有局限性。
发明内容
本发明的目的是针对现有基于故障注入的分布式系统测试方法中故障场景空间爆炸问题,提供一种面向分布式系统的失效恢复机制自动化测试方法及装置。该方法通过收集系统运行时信息调整节点失效/重启注入,并通过基于优化的故障场景选择策略调整故障场景测试优先级,来系统化测试故障场景空间,尽快覆盖更多系统代码,尤其是失效恢复相关代码,暴露失效恢复缺陷。
本发明的技术方案包括:
一种面向分布式系统的失效恢复机制自动化测试方法,所述方法包括:
将初始故障序列注入分布式系统,获取目标系统运行信息;其中,所述初始故障序列中不包含任一故障;
基于所述目标系统运行信息、系统特定约束和用户特定约束,生成和变异故障序列seq′,以更新故障序列队列;其中,所述系统特定约束表示所述目标系统中目标集群在同一时刻可容忍的节点宕机情况,所述用户特定约束表示所述故障序列seq′中的最大故障数目;
从所述故障序列队列选择一故障序列seq;
使用所述故障序列seq对所述分布式系统进行测试,获取缺陷报告或更新所述故障序列队列之后,返回至从所述故障序列队列选择一故障序列seq;
基于所述缺陷报告,得到所述分布式系统的测试结果。
进一步地,所述基于所述目标系统运行信息、系统特定约束和用户特定约束,生成和变异故障序列seq′,以得到故障序列队列,包括:
基于所述运行信息,得到I/O相关信息和代码覆盖;
在所述代码覆盖包含以往被测故障序列未覆盖的代码块,或所述被测故障序列seq中最后一个故障为节点失效故障的情况下,则,
基于所述I/O相关信息,生成一故障序列seq′;其中,所述I/O相关信息包括:执行的I/O操作所在的节点ID、调用栈、操作源路径、操作目标路径和时间戳,所述操作源路径和操作目标路径包括:节点ID、文件路径;
在所述故障序列seq′的中的故障数目等于用户特定约束中所述最大故障数目的情况下,则不对所述故障序列队列进行更新;
在所述故障序列seq′的中的故障数目小于用户特定约束中所述最大故障数目的情况下,则针对所述故障序列seq′中故障事件为节点失效或节点重启的最后一个I/O点之后的I/O点,每次操作选取一I/O点并添加节点失效故障或节点重启故障,以得到一组新的故障序列加入故障序列队列;
在所述代码覆盖包含以往被测故障序列覆盖的代码块且所述故障序列seq中最后一个故障不是节点失效故障的情况下,则丢弃所述故障序列seq,且不对所述故障序列队列进行更新。
进一步地,所述针对所述故障序列seq′中故障事件为节点失效或节点重启的最后一个I/O点之后的I/O点,每次操作选取一I/O点并添加节点失效故障或节点重启故障,以得到一组新的故障序列加入故障序列队列,包括:
找到所述故障序列seq′中故障事件为节点失效或节点重启的最后一个I/O点在序列中的位置loc,并创建所述最后一个I/O点之后I/O点的索引值i;其中,所述索引值i的初始值为loc+1;
创建一个变异故障序列集合mutates;所述变异故障序列集合mutates的初始值为空;
在第i个I/O点对应的故障事件为无故障事件的情况下,分别判断注入节点失效事件与节点重启事件是否满足系统特定约束,并将满足系统特定约束的故障序列加入所述变异故障序列集合mutates;
在第i个I/O点对应的故障事件为节点失效事件或节点重启事件的情况下,跳过所述第i个I/O点并处理第i+1个I/O点;
在所述最后一个I/O点之后的所有I/O点处理完毕后,将所述变异故障序列集合mutates加入故障序列队列。
进一步地,所述从所述故障序列队列选择一故障序列seq,包括:
在所述故障序列队列中选择一组可疑故障序列候选集合;
对所述可疑故障序列候选集合中的每一故障序列进行优先级打分;
根据打分结果,确定一故障序列;
进一步地,所述在所述故障序列队列中选择一组可疑故障序列候选集合,包括:
生成一个可疑故障序列候选集合candidates;所述可疑故障序列候选集合candidates的初始值为空;
当以一定概率应用策略一时,则基于所述故障序列队列中所有故障序列的故障ID,将全局而言具有未测试故障ID的故障序列加入所述可疑故障序列候选集合candidates;其中,所述应用策略一为优先选择全局而言具有未测试故障ID的故障序列进行测试,所述故障ID为一个故障序列中最后一个故障所对应I/O点的调用栈和故障事件类型计算得到的哈希值;
在当前可疑故障序列候选集合candidates不为空的情况下,将当前可疑故障序列候选集合candidates作为可疑故障序列候选集合;
在当前可疑故障序列候选集合candidates为空的情况下,且以一定概率应用策略二时,则找到故障序列队列中所有最后一个故障发生在恢复过程中I/O点的故障序列,并加入所述可疑故障序列候选集合candidates;其中,所述应用策略二为优先选择最后一个故障发生在恢复过程中的故障序列进行测试,所述恢复过程中I/O点通过判断该I/O点是否在故障注入测试后出现,且具有新的调用栈来决定;
在当前可疑故障序列候选集合candidates不为空的情况下,将当前可疑故障序列候选集合candidates作为可疑故障序列候选集合;
在当前可疑故障序列候选集合candidates为空的情况下,且以一定概率应用策略三时,计算故障序列队列中所有故障序列的故障ID,并对同一故障序列seq′变异得到的变异故障序列组mutates,若有具有对所述变异故障序列组mutates而言未测试过故障ID的故障序列,则将该故障序列加入至可疑故障序列候选集合candidates;其中,所述应用策略三为优先选择同一个变异组中具有未测试故障ID的故障序列进行测试。
在当前可疑故障序列候选集合candidates不为空的情况下,将当前可疑故障序列候选集合candidates作为可疑故障序列候选集合;
在当前可疑故障序列候选集合candidates为空的情况下,将故障序列队列中的所有故障序列作为可疑故障序列候选集合。
进一步地,所述对所述可疑故障序列候选集合中的每一故障序列进行优先级打分,包括:
基于故障序列的执行速度,计算第一优先级得分;其中,执行速度快的故障序列比执行速度慢的故障序列获取更高的第一优先级得分;
基于故障序列对应的代码覆盖率,计算第二优先级得分;其中,代码覆盖率高的故障序列比代码覆盖率低的故障序列获取更高的第二优先级得分;
基于故障序列在所述故障序列队列中的等候轮次,计算第三优先级得分;其中,等候轮次多的故障序列比等候轮次少的故障序列获取更高的第三优先级得分;
基于故障序列中的故障数目,计算第四优先级得分;其中,在所述故障数目不多于设定数量的情况下,故障数目多的故障序列比故障数目少的故障序列获取更高的第四优先级得分,在所述故障数目多于设定数量的情况下,故障数目少的故障序列比故障数目多的故障序列获取更高的第四优先级得分;
综合所述第一优先级得分、第二优先级得分、第三优先级得分以及第四优先级得分,得到相应故障序列的优先级得分。
进一步地,所述使用所述故障序列seq对所述分布式系统进行测试,获取缺陷报告或更新所述故障序列队列之后,返回至所述从所述故障序列队列选择一故障序列seq,包括:
在所述故障序列seq注入分布式系统的过程中,存在至少一故障无法注入的情况下,中断注入过程,并将所述故障序列seq加入所述故障序列队列之后,返回至所述从所述故障序列队列选择一故障序列seq;
在所述故障序列seq注入分布式系统的过程中,所述故障序列seq的全部故障被成功注入,且所述分布式系统中工作负载的故障征兆检查器未确认潜在缺陷,则基于所述分布式系统的运行信息对所述故障序列队列进行更新,并返回至所述从所述故障序列队列选择一故障序列seq;
在所述故障序列seq注入分布式系统的过程中,所述故障序列seq的全部故障被成功注入,且所述分布式系统中工作负载的故障征兆检查器确认潜在缺陷或确认时间超出设定时间,则生成一缺陷报告,并返回至所述从所述故障序列队列选择一故障序列seq
一种面向分布式系统的失效恢复机制自动化测试装置,所述装置包括:
信息获取模块,用于将初始故障序列注入分布式系统,获取目标系统运行信息;其中,所述初始故障序列中不包含任一故障;
队列更新模块,用于基于所述目标系统运行信息、系统特定约束和用户特定约束,生成和变异故障序列seq′,以更新故障序列队列;其中,所述系统特定约束表示所述目标系统中目标集群在同一时刻可容忍的节点宕机情况,所述用户特定约束表示所述故障序列seq′中的最大故障数目;
故障序列选择模块,从所述故障序列队列选择一故障序列seq;
系统测试模块,用于使用所述故障序列seq对所述分布式系统进行测试,获取缺陷报告或更新所述故障序列队列之后,返回至从所述故障序列队列选择一故障序列seq;
结果生成模块,用于基于所述缺陷报告,得到所述分布式系统的测试结果。
一种存储介质,所述存储介质中存储有计算机程序,其中,所述计算机程序被设置为运行时执行上述任一所述方法。
一种电子设备,其特征在于,包括存储器和处理器,所述存储器中存储有计算机程序,所述处理器被设置为运行所述计算机程序以执行上述任一所述方法。
与现有技术相比,本发明具有如下的技术优势:
1.本发明的方法针对分布式系统失效恢复机制,通过系统运行时反馈生成多样的、包含多个节点失效和节点重启组合的故障场景进行测试,能够系统化测试目标分布式集群的故障场景空间,尽可能充分地覆盖生成环境中可能遇到的情况,帮助分布式系统开发人员及时发现系统中存在的失效恢复缺陷。
2.本发明在生成和选择故障场景进行测试时,以代码覆盖为导向,尽可能优先测试容易增加代码覆盖、触发失效恢复缺陷的故障场景进行测试,能够在有限时间和资源内更加有效地探索故障场景空间,大幅提升测试效率。
3.本发明收集的系统运行时信息为I/O相关信息和代码覆盖信息,可以较为方便地适配到新的分布式系统。对于新的目标系统,开发人员只需要识别该系统应用层I/O相关操作,或使用本发明方法提供的JDK层的I/O操作识别即可。
附图说明
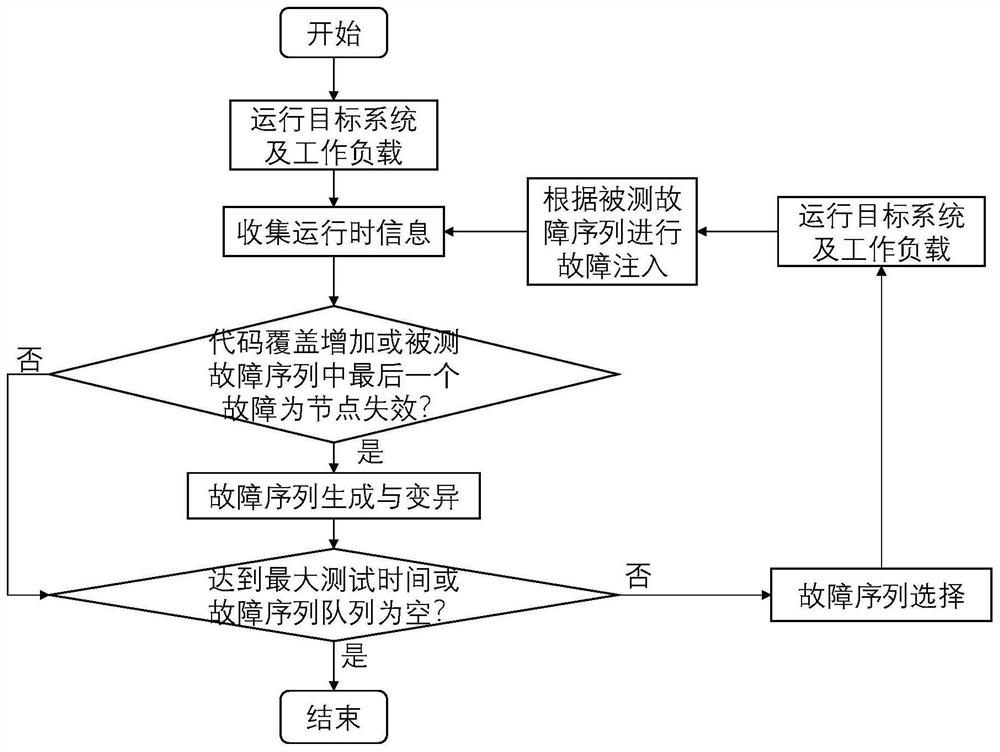
图1本发明方法测试模型流程图。
图2本发明方法整体架构示例图。
图3初始故障序列生成和变异示例图。
图4常规故障序列生成和变异示例图。
具体实施方式
下面将结合附图,对本发明实施方式中的技术方案进行清楚、完整地描述,显然,所描述的实施方式仅仅是本发明特定实施方式,而不是全部的实施方式。基于本发明中的实施方式,本领域普通技术人员在没有做出创造性劳动前提下所获得的所有其他实施方式,都属于本发明保护的范围。
本发明的技术方案包括一种针对分布式系统失效恢复机制的自动化测试方法。在该自动化测试方法中,包含一个或多个节点失效/重启故障的故障场景被抽象为一个按照时间戳顺序从小到大排列的I/O点所组成的故障序列,通过系统运行时反馈,自动生成一系列故障序列,来测试目标分布式系统的失效恢复机制,尽快覆盖更多失效恢复相关代码、暴露失效恢复缺陷。
具体来说,本发明基于如图1所示的测试模型:通过运行目标分布式系统和指定工作负载来收集系统运行时信息,如果代码覆盖增加或当前被测故障序列中最后一个故障为节点失效则进行故障序列生成与变异,如果未达到最大测试时间且故障序列队列不为空则从故障序列队列中选择新的故障序列进行测试,并根据被测故障序列进行故障注入。
以下结合图2中的具体实施架构示例图对本发明所述方法进行详细说明。
步骤1:将初始故障序列注入分布式系统,获取目标系统运行信息。
本发明首先初始化一个空的被测故障序列seq(即不向目标系统注入任何故障),驱动目标集群和工作负载首次运行,通过动态代码插装技术收集系统运行时信息。系统运行时信息包括代码覆盖信息、I/O相关信息,所述代码覆盖信息包括:目标集群在本次运行中覆盖的基本代码块的信息,所述I/O相关信息包括:目标集群在本次运行中执行的I/O操作所在的节点ID、调用栈、操作源路径、操作目标路径、时间戳,所述I/O操作包括:文件I/O、网络I/O,所述操作源路径和操作目标路径包括:节点ID、文件路径。
步骤2:基于目标系统运行信息、系统特定约束和用户特定约束,生成和变异故障序列seq′,以得到故障序列队列。
基于系统运行时信息、系统特定约束和用户特定约束,生成和变异故障序列,加入故障序列队列。具体而言,首先需要收集记录的目标集群中所有节点的运行时信息,将本次运行的代码覆盖信息与以往测试的代码覆盖信息做比较。如果本次运行增加了代码覆盖,或本次运行中注入的最后一个故障为节点失效故障,则根据收集到的I/O相关信息生成一个故障序列seq′。故障序列seq′中的I/O点为本次测试中实际执行过的I/O点按时间戳从小到大排列,这些I/O点所对应的故障事件为本次测试中根据故障序列seq进行故障注入时,实际注入的故障事件:节点失效、节点重启或无故障。对于首次运行,每个I/O点所对应的故障事件都为无故障事件。如图3所示,初始运行后得到一个包含4个I/O点的初始故障序列。如图4所示,正常运行中,根据一个被测故障序列seq进行故障注入测试后,基于收集到的本次运行中的I/O相关信息,得到一个包含4个I/O点的故障序列seq′,与本次运行中的被测故障序列seq相比,I/O点
其次,本发明基于一系列约束,通过向seq′中最后一个故障所在的I/O点之后,一个无故障的I/O点上注入一个新的故障(节点失效故障或节点重启故障)来生成一个新的变异故障序列。通过遍历seq′中最后一个故障所在的I/O点之后所有无故障的I/O点,本发明最终通过变异seq′,得到一系列变异故障序列,加入到故障序列队列中。在这里,一系列约束包括一般性约束(如只能使失效节点重启,只能使活动节点失效)、系统特定的约束(如目标集群在同一时刻失效的节点数可被目标集群所容忍),以及用户指定的约束(如注入的故障数目不超过用户指定的最大故障数)。最后,本步骤中基于seq′变异得到的所有变异故障序列被加入到故障序列队列中。
一示例中,故障序列队列更新过程包括:
1)判断当前运行是否为初始运行:
若是,则进入步骤2);
若否,则进入步骤3);
2)根据收集到的I/O操作及其相关信息,生成初始故障序列seq′,其中,初始故障序列中的I/O点对应本次运行中的I/O相关信息按时间戳从小到大排序,每个I/O点对应的故障事件都为无故障事件,进入步骤6);
3)根据收集到的运行时覆盖信息,判断本次测试是否增加了代码覆盖:
若是,则进入步骤5);
若否,则进入步骤4);
4)判断本次被测故障序列seq中最后一个故障是否为节点失效事件:
若是,则进入步骤5);
若否,则进入步骤13);
5)根据收集到的I/O操作及其相关信息、故障注入结果,对本次被测故障序列seq,进行校准,生成故障序列seq′。其中,seq′中I/O点对应的I/O相关信息为本次运行中实际执行到的I/O操作及其相关信息,seq′中I/O点对应的故障事件为本次运行中I/O点实际注入的节点失效事件、节点重启事件或无故障事件;
6)判断故障序列seq′中的故障数目是否等于用户特定约束中指定的最大故障数目:
若是,则进入步骤13);
若否,则进入步骤7);
7)对于故障序列seq′,找到该序列中故障事件为节点失效或节点重启的最后一个I/O点在序列中的位置为loc,创建一个索引值i,初始值为loc+1,创建一个变异故障序列集合mutates,初始值为空;
8)对于故障序列seq′中的第i个I/O点,判断其对应的故障事件是否为无故障事件:
若是,则进入步骤9);
若否,则进入步骤11);
9)判断在故障序列seq′中的第i个I/O点注入一个节点失效事件是否满足一系列约束:
若是,则生成一个新的变异故障序列m,其初始值与seq′相同,使m中第i个I/O点对应的故障事件变为节点失效事件,将m加入集合mutates,进入步骤10);
若否,则进入步骤10);
10)判断在故障序列seq′中的第i个I/O点注入一个节点重启事件是否满足一系列约束:
若是,则生成一个新的变异故障序列m,其初始值与seq′相同,使m中第i个I/O点对应的故障事件变为节点重启事件,将m加入集合mutates,进入步骤11);
若否,则进入步骤11);
11)使i的值变为i+1,判断i所指向的位置是否大于seq′中最后一个I/O点所在的位置:
若是,则进入步骤12);
若否,则进入步骤8);
12)将变异故障序列mutates加入故障序列队列中;
13)进入后续故障序列选择阶段。
步骤3:从故障序列队列选择一故障序列seq。
如果当前测试时间未达到预先指定的最大测试时间,且故障序列队列不为空时,根据预先配置的概率,从故障序列队列中选取一组可疑的故障序列,再对这些可疑故障序列进行优先级打分,根据优先级分数从候选可疑故障序列中随机选择一个故障序列seq进行测试。选择故障序列的具体步骤如下:首先选择一组可疑故障序列候选集合,再对候选集合中的每一个故障序列进行优先级打分,根据打分从中随机选择一个故障序列进行测试。
步骤3.1:选择一组可疑故障序列候选集合。
选择可疑故障序列候选集合的具体步骤如下:首先生成一个可疑故障序列候选集合candidates,其初始值为空。接着生成一个[0,1)之间的随机数random,判断random的值是否小于应用策略一的概率,如99%。若是,则计算故障序列队列中所有故障序列的故障ID,将全局而言具有未测试故障ID的故障序列加入candidates。如果candidates不为空,则将其作为可疑故障序列候选集合返回。
进一步地,所述故障序列的故障ID为一个故障序列中最后一个故障所对应I/O点的调用栈和故障事件类型计算得到的哈希值。
如果candidates为空,则重新生成一个[0,1)之间的随机数random,判断random的值是否小于应用策略二的概率,如95%。若是,则找到故障序列队列中所有最后一个故障发生在恢复过程中I/O点的故障序列,加入candidates。恢复过程中的I/O点通过判断该I/O点是否在故障注入测试后出现,且具有新的调用栈来决定。如果candidates不为空,则将其作为可疑故障序列候选集合返回。
如果此时candidates为空,则重新生成一个[0,1)之间的随机数random,判断random的值是否小于应用策略三的概率,如90%。若是,则计算故障序列队列中所有故障序列的故障ID,对于由同一个故障序列seq′变异得到的一组变异故障序列mutates,如果mutates中的一个序列m具有对变异组mutates而言未测试过的故障ID,则将m加入candidates。如果candidates不为空,则将其作为可疑故障序列候选集合返回。
最后,如果candidates仍为空,则将故障序列队列中的所有待测序列作为可疑故障序列候选集合返回。
一示例中,应用策略一:优先选择全局而言具有未测试故障ID的故障序列进行测试;应用策略二:优先选择最后一个故障发生在恢复过程中的故障序列进行测试;应用策略三:优先选择同一个变异组中具有未测试故障ID的故障序列进行测试。其中,属于同一个变异组的故障序列指由同一个故障序列seq′变异得到的故障序列。
此外,所述应用优化的故障场景选择策略一、二、三的概率为可配置参数,并基于所述可配置参数,调整所述方法应用于不同系统和不同工作负载时的效果。
步骤3.2:对候选集合中的每一个故障序列进行优先级打分。
对于获得的可疑故障序列候选集合candidates,本发明所述的方法根据以下原则对其中的故障序列进行打分:提高执行时间短的故障序列的测试优先级;提高代码覆盖率高的故障序列的测试优先级;提高在故障序列队列中等待轮次高的故障序列的测试优先级(其中等待轮次指一个故障序列在被测试前,在故障序列队列中经历的轮次。每次从故障序列中选择一个故障序列进行测试,即为一个轮次);当故障序列中故障数目不多于六个时,提高故障数目更多的故障序列的测试优先级,当故障数目大于六时,降低故障数目更多的故障序列的测试优先级。基于优先级分数,从可疑故障序列候选集合中随机选择一个故障序列进行测试。
步骤3.3:据打分从中随机选择一个故障序列进行测试。
本发明综合故障序列的各项打分,得到该故障序列的最终优先级得分。最后基于优先级得分从可疑故障序列候选集合中随机选择一个故障序列进行测试。
步骤4:使用故障序列seq对分布式系统进行测试,获取缺陷报告或更新所述故障序列队列之后,返回至从所述故障序列队列选择一故障序列seq。
根据当前被测故障序列,运行目标集群和工作负载,收集和记录系统运行时信息,并将在目标系统的I/O操作点收集的I/O相关信息汇报给故障注入测试控制器,由控制器根据被测故障序列控制目标系统执行和故障的注入。具体而言,故障注入测试控制器运行工作负载驱动目标集群运行。目标集群在所有I/O点收集相关信息报告给故障注入测试控制器并等待故障注入测试控制器的决策。故障注入测试控制器根据当前被测故障序列seq,决定在某个节点注入节点失效故障、节点重启故障,或使报告节点继续运行。
在本步骤中,首先,本发明在目标系统每个I/O点收集信息并报告给统一的故障注入测试控制器,由故障注入测试控制器将收集的I/O点信息和待测故障序列中的I/O点信息进行一一比对来按序注入故障、控制目标系统执行。如果一个报告的I/O点信息与当前待要注入的故障所在的I/O点信息相一致,则故障注入控制器通过调用预定义的脚本来注入相应的节点失效故障或节点重启故障(对于节点重启故障,故障注入控制器还会通知报告该I/O点信息的节点继续运行)。否则,故障注入控制器通知报告该I/O点信息的节点继续运行。
其次,在当前测试工作负载运行过程中,以及工作负载运行结束之后,本发明所述的方法会运行预定义故障征兆检查器来确认潜在的缺陷。具体而言,本发明的检查器会检查一般的故障征兆(如运行日志中的FATAL、ERROR和Exception,以及节点崩溃),也会检查操作特定的故障征兆(例如操作返回错误代码或者读取到过时数据)。基于本发明已经实现的检查器,用户很容易就可以为其他工作负载实现特定检查器。在实际使用中,测试人员可以通过为特定目标系统下的特定工作负载设计更为精细的故障征兆检查器来减少缺陷漏报和缺陷误报。
一示例中,对于一个故障注入测试,在工作负载运行结束之后,如果被测故障序列中存在故障无法被成功注入,则该故障序列会被重新加入故障序列队列在后续测试过程中被重新测试;如果被测故障序列中所有故障都被成功注入,且本次测试通过所有预定义的故障征兆检查器,则收集本次测试系统运行时信息进入后续故障序列生成和变异阶段;如果被测故障序列中所有故障都被成功注入,且本次测试没有通过所有预定义的故障征兆检查器,则生成一个缺陷报告,再从故障序列队列中选则一个新的故障序列进行测试;如果本次测试中工作负载无法在预先配置的超时时间内结束,则重新根据该被测故障序列进行故障注入测试,如果新的测试仍然无法在2倍的超时时间内结束,则生成一个挂起缺陷报告,再从故障序列队列中选则一个新的故障序列进行测试。
步骤5:基于缺陷报告,得到分布式系统的测试结果。
如果当前测试时间没有结束且故障序列队列中还有待测故障序列(即故障序列队列不为空),则从中选择一个故障序列进行进一步测试。否则本发明基于各次测试的缺陷报告,生成最终测试结果。
综上所述,本发明的方法针对分布式系统失效恢复机制,通过系统运行时反馈生成多样的、包含多个节点失效和节点重启组合的故障场景进行测试,能够系统化测试目标分布式集群的故障场景空间,尽可能充分地覆盖生成环境中可能遇到的情况,帮助分布式系统开发人员及时发现系统中存在的失效恢复缺陷。
本发明在生成和选择故障场景进行测试时,以代码覆盖为导向,尽可能优先测试容易增加代码覆盖、触发失效恢复缺陷的故障场景进行测试,能够在有限时间和资源内更加有效地探索故障场景空间,大幅提升测试效率。
本发明收集的系统运行时信息为I/O相关信息和代码覆盖信息,可以较为方便地适配到新的分布式系统。对于新的目标系统,开发人员只需要识别该系统应用层I/O相关操作,或使用本发明方法提供的JDK层的I/O操作识别即可。
尽管为说明目的公开了本发明的具体实施流程和实例附图,其目的在于帮助理解本发明的内容并据以实施,但是本领域的技术人员可以理解:在不脱离本发明及所附的权利要求的精神和范围内,各种替换、变化和修改都是可能的。因此,本发明不应局限于所展示实施流程和实例附图所公开的内容。
- 分布式系统的自动化测试方法、装置、设备及存储介质
- 一种面向分布式系统的自动化测试的执行控制与调度方法