基于文本语义映射关系的Web表格异常数据发现方法
文献发布时间:2023-06-19 18:27:32
技术领域
本发明涉及数据异常检测及其应用领域,尤其涉及基于文本语义映射关系的Web表格异常数据发现方法。
背景技术
随着万维网的快速发展,各种信息类网站逐渐融入人们的生活,成为人们日常获取各类信息不可或缺的工具。在网页中由包含语义信息内容组成的关系表格称为Web表格,海量的Web表格不仅方便了人们的知识获取,也成为大量机器学习和训练任务的重要数据来源。然而,由于Web语义表格面向用户开放,人人可参与编辑,导致其包含了大量异常数据甚至是恶意篡改信息。有效的识别Web表格中的异常数据具有重要的现实意义。
传统的表格异常处理技术主要包括基于完整性约束的和基于规则的异常发现方法,以及基于攻击和机器学习的方法。基于完整性约束的方法主要根据各类事先构建的约束信息进行处理,比如函数依赖、包含依赖、条件函数依赖等,该方法需要大量约束信息,对于丰富多变的网络表格难以有效扩展适用。基于规则的方法中自带有正确的数据,这些数值依赖于外部高质量资源,如果外部数据库缺乏相关知识,则无法检测数据中的错误。然而Web表格往往没有预定义的标准模式,对于传统的表格异常处理技术来说,由于局限于预定义的明确的关系模式信息,难以应对Web表格语义信息模糊甚至错误的问题。而基于机器学习的方法则局限于特征工程等方案,需要大量标注数据缺少一整套的面向Web表格的异常发现方法。
针对传统表格异常处理技术面临的挑战,可以引入语义模型作为新的辅助手段,协助对Web表格中的模糊或错误信息进行挖掘和发现。表格数据处理与一般的自然语言处理问题有紧密联系,都需要对其中的文字表述进行语义学习和处理,但与得到广泛研究的描述性文本不同,表格以其行列纵横的特点有着不同的语义呈现方式,需要提出针对表格形式的处理模型。此外,如何根据挖掘和利用表格中的语义映射关系来识别异常数据也是一项新的挑战。因此,如何设计针对表格语义特征的语义模型,实现Web表格的异常处理,是当前所需要解决的重要问题。
发明内容
发明目的:针对以上现有技术存在的问题,本发明提出了基于文本语义映射关系的 Web表格异常数据发现方法,着重解决传统表格异常处理技术中难以识别缺乏模式的表格错误,和难以应对模糊或错误的语义信息的问题。将单元格中的文本字符串转换为文本语义空间语义向量,并将其用于推断列的模式信息,最后基于关系映射的办法,实现错误发现找到表格中的错误。
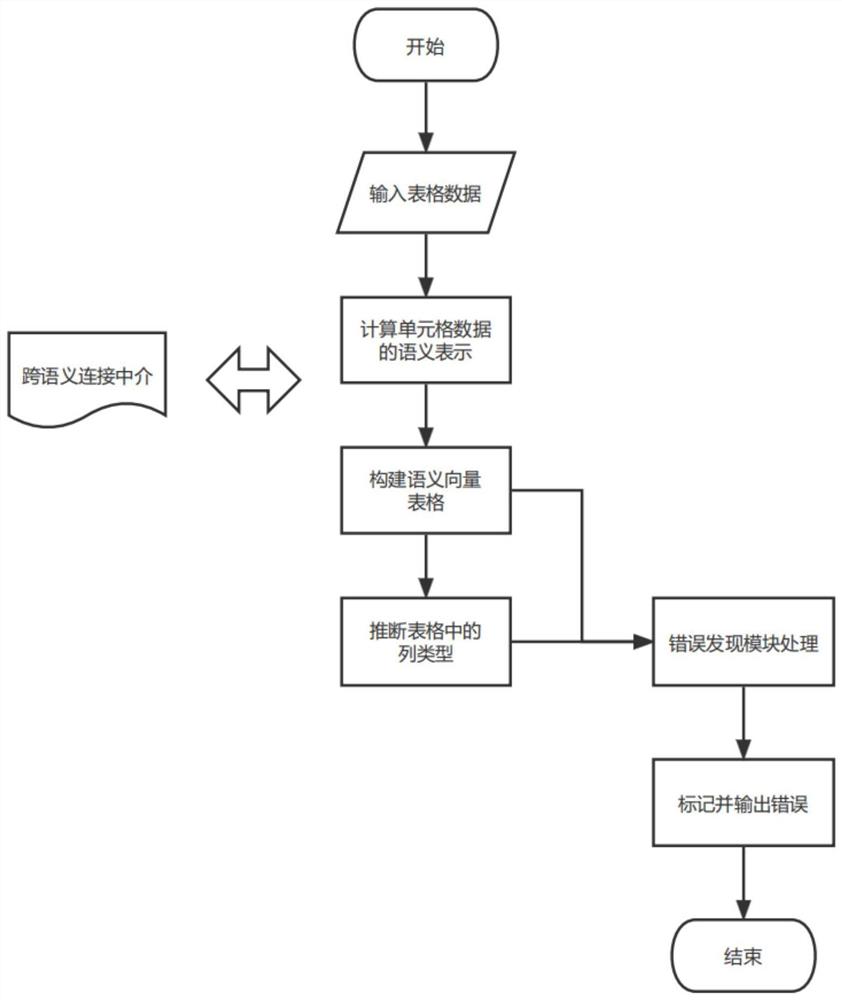
技术方案:为实现本发明的目的,本发明所采用的技术方案是:基于文本语义映射关系的Web表格异常数据发现方法,该方法包括以下步骤:
步骤1.给定待处理的Web表格数据T,其中T={c
步骤2.基于海量Web表格数据训练列类型推断模型M
步骤3.根据核心列和目标单元格所在列的映射关系建立错误发现模型M
进一步的,步骤1中,所述使用表格数据集合预训练语义模型M
步骤101.取表格T中任意一列j,组成列单元格数据集{c
步骤102.根据步骤101所述的方法处理行单元格数据行处理,得到行数据训练集Set
步骤103.生成训练集集合Set
步骤104.使用构建的训练集通过Word2Vec模型进行训练,训练得到文本-语义向量的映射字典。输入单元格内容c
步骤2中,所述使用多分类训练方式训练列类型推断模型M
步骤201.表格T中的某一列单元格数据为C
步骤202.从C′
步骤203.使用深度学习语言模型Transformer作为列类型推断模型M
步骤204.将输入文本送入词向量层(TokenEmbedding),将每一个词转换为维度相同的词嵌入向量;
步骤205.将输入文本送入位置向量层(PositionEmbedding),将每一个词转换为位置嵌入向量,具体是将[CLS]标签位置标注为E
步骤206.将Token Embedding和Position Embedding的各个向量相加作为M
O=Softmax(H
步骤207.将训练模型的方式转变为多分类问题,采用线性整流函数(ReLU函数)作为激活函数,使用交叉熵损失函数:
其中,M为类别的数量,即统计的列类型的总数,y
步骤208.通过多层感知机模型得到其隐层的计算结果为h
进一步的,步骤3中,所述根据核心列和目标单元格所在列的映射关系建立错误发现模型M
步骤301.定义表格的最左列为核心列,各行最左实体为核心实体,表格T中的核心实体集合为{c
步骤302.在表格T={c
h(h
步骤303.以长短期记忆人工神经网络(LSTM)为核心模型、序列对序列(Seq2Seq)模型为整体框架建立错误发现模型M
步骤304.在M
步骤305.在M
步骤306.使用余弦相似度计算单元格语义向量的预测值
步骤307.M
有益效果:与现有技术相比,本发明的技术方案具有以下有益技术效果:
(1)可以识别缺少明确模式信息的表格中的异常数据。由于Web表格是在开放的松散环境下由用户构造,并没有预定义的标准模式,这就要求模型理解表格中的语义信息,然而传统的异常发现方法难以应对语义多样的表格数据,需要大量约束条件或外部数据库的支持。本发明训练语义模型识别单元格语义和表中列的类型,可以识别没有标准模式信息的表格中的异常数据;
(2)可以提高Web表格异常数据发现的准确性。基于文本语义映射关系的Web表格异常数据发现方法解决了传统异常数据发现方法中难以识别模糊语义信息的问题,综合单元格语义和识别列类型,利用基于关系映射的办法推断单元格内容是否错误,有效识别语义模糊的文本数据。
附图说明
图1基于文本语义映射关系的Web表格异常数据发现方法流程图;
图2基于文本语义映射关系的Web表格异常数据发现方法实例图。
具体实施方式
下面结合附图和具体实施例,进一步阐明本发明。
本发明的目标是解决基于文本语义映射关系的Web表格异常数据发现问题。由于Web表格是在开放松散环境下构造的,因此往往存在着一些错误或异常数据。本发明所处理的Web表格是蕴含了实体以及实体间关系的语义表格,其中的某个单元格内容表示的是某个实体,比如单元格“MichaelJordan”,结合上下文可以知其是否代表的是“NBA 球星迈克尔乔丹”。而整张表表示的是实体间的关系,比如“Olajuwon”所在的球队是“HoustonRockets”,同时,表格中乔丹的球队可能被错误的填写为“Lakers”。本发明针对此类Web表格进行异常数据发现,找到表格中的异常数据并标记。
本发明构建基于文本语义映射关系的Web表格异常数据发现模型,通过语义表示模块将单元格中的字符串文本转换为语义空间向量,然后使用列类型推断模块对表格的列类型进行推断和表征,错误发现模块综合上述模块,基于映射关系发掘表格错误数据。为此,本发明具体执行步骤如下:
步骤1.给定待处理的Web表格数据T,其中T={c
步骤2.基于海量Web表格数据训练列类型推断模型M
步骤3.根据核心列和目标单元格所在列的映射关系建立错误发现模型M
进一步的,步骤1中,所述使用表格数据集合预训练语义模型M
步骤101.取表格T中任意一列j,组成列单元格数据集{c
如图2所示,分别对第一列和第二列进行处理,可能得到的列数据训练集为“Chamberlain Olajuwon JordanMichael”,以及“LakersRocketsAngelesLakersHoustonLos”;
步骤102.根据步骤101所述的方法处理行单元格数据行处理,得到行数据训练集Set
步骤103.生成训练集集合Set
步骤104.使用构建的训练集通过Word2Vec模型进行训练,训练得到文本-语义向量的映射字典。输入单元格内容c
步骤2中,所述使用多分类训练方式训练列类型推断模型M
步骤201.表格T中的某一列单元格数据为C
步骤202.从C′
步骤203.使用深度学习语言模型Transformer作为列类型推断模型M
步骤204.将输入文本送入词向量层(TokenEmbedding),将每一个词转换为维度相同的词嵌入向量;
步骤205.将输入文本送入位置向量层(PositionEmbedding),将每一个词转换为位置嵌入向量,具体是将[CLS]标签位置标注为E
步骤206.将Token Embedding和Position Embedding的各个向量相加作为M
O=Softmax(H
步骤207.将训练模型的方式转变为多分类问题,采用线性整流函数(ReLU函数)作为激活函数,使用交叉熵损失函数:
其中,M为类别的数量,即统计的列类型的总数,y
步骤208.通过多层感知机模型得到其隐层的计算结果为
进一步的,步骤3中,所述根据核心列和目标单元格所在列的映射关系建立错误发现模型M
步骤301.定义表格的最左列为核心列,各行最左实体为核心实体,表格T中的核心实体集合为{c
步骤302.在表格T={c
h(h
步骤303.以长短期记忆人工神经网络(LSTM)为核心模型、序列对序列(Seq2Seq)模型为整体框架建立错误发现模型M
步骤304.在M
步骤305.在M
步骤306.使用余弦相似度计算单元格语义向量的预测值
步骤307.M
- 文本和表格语义交互的数据处理方法、装置及存储介质
- 一种基于综合语义的Web服务发现方法