一种面向多租户的时序数据分布式处理系统
文献发布时间:2023-06-19 18:29:06
技术领域
本发明涉及是时序数据处理技术领域,具体的说是一种面向多租户的时序数据分布式处理系统。
背景技术
随着用户对应用可用性重视程度的不断提高,大量的监控系统产生了海量的监控指标数据,包括性能指标数据和业务指标数据等。海量的监控数据往往成为分析处理系统实现实时处理的性能瓶颈。为了处理海量的监控数据,通常需要搭建复杂的大数据分析处理系统,对于一般的企业来说,搭建的这种大数据分析处理系统的运维复杂度较高。同时,随着云计算的兴起,方便的SaaS服务往往更能吸引人,而SaaS服务往往涉及多租户的问题,以及按租户分配资源,因此,如何灵活的分配计算和存储资源,是一个重要的研究方向。
发明内容
本发明针对目前技术发展的需求和不足之处,提供一种面向多租户的时序数据分布式处理系统。
本发明的一种面向多租户的时序数据分布式处理系统,解决上述技术问题采用的技术方案如下:
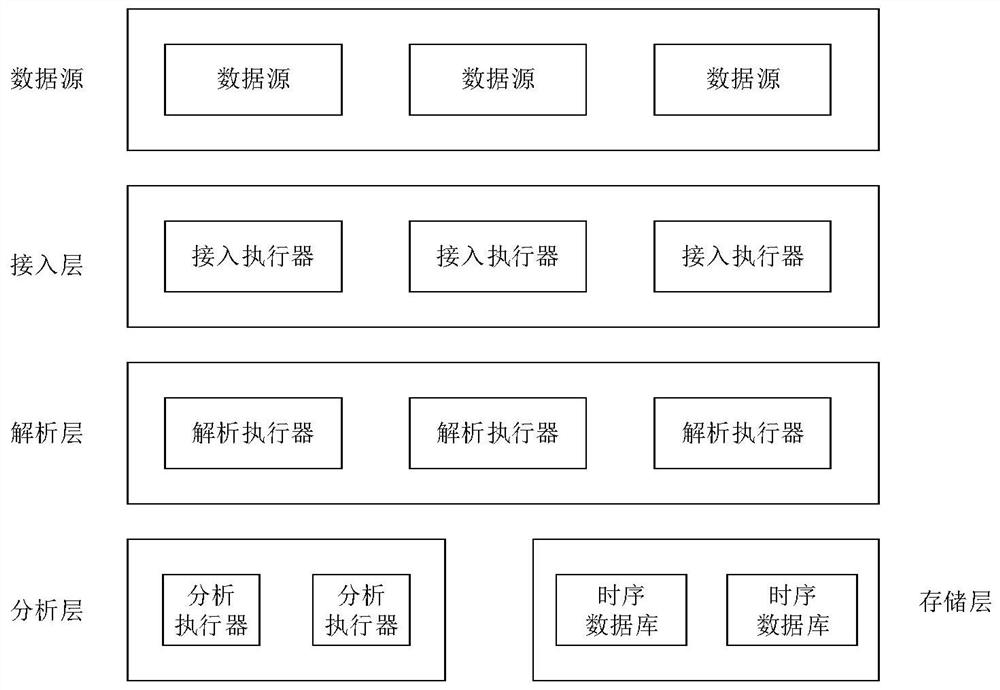
一种面向多租户的时序数据分布式处理系统,其实现基于数据源,分离设置的接入层、解析层、分析层,以及存储层,其中:
数据源通过Kafka接入,每个数据源的Kafka Topic包含多个分区,以支持水平扩展;
接入层不仅负责数据源接入任务同步线程的创建、租户权限的校验,还负责从数据源拉取数据添加租户信息封装为解析报文,并通过Kafka发送到解析层;
解析层不区分租户,采用统一的Kafka Topic汇聚不同租户数据源的数据,并对数据源中的指标、实例以及指标实例进行解析,随后通过Kafka发送到分析层;
分析层不区分租户,采用统一的Kafka Topic汇聚不同租户数据源的数据,并完成指标、实例以及指标实例的分析;
存储层采用时序数据库保存接入层、解析层、分析层产生的实时数据。
可选的,不同数据源对应的Kafka Topic相同或不同。
可选的,接入层包含N个接入执行器,并支持水平扩展;
解析层包含P个解析执行器,并支持水平扩展;
分析层包含Q个分析执行器,并支持水平扩展;
每个接入执行器、解析执行器、分析执行器对应一个docker容器,并包含多个Kafka消费者,其中,每一个消费者对应一个执行器中的独立处理线程。
进一步可选的,用户通过接入层创建数据源接入任务同步线程后,请求启动数据源接入任务同步线程,此时,
(1.1)接入层从请求头中获取租户编码,并将数据库数据源切换为租户数据源,
(1.2)接入层根据接入任务对应的消息数量发送数据源同步启动消息,
(1.3)接入层将接入任务的状态设置为启动中,同时,将接入任务同步线程数设置为0。
优选的,接入层利用Redis发布订阅功能向接入执行器发送数据源同步启动消息。
进一步可选的,所涉及接入层的接入执行器接收到数据源接入任务启动消息后,
(2.1)获取数据源接入任务启动消息中的租户编码,并将数据库数据源切换为租户数据源;
(2.2)判断数据源接入任务同步启动线程数是否超过租户最大允许同步线程数,
(2.2.a)若超过,则将接入任务状态设置为启动失败,
(2.2.b)若未超过,则执行步骤(2.3);
(2.3)判断接入任务消息类型是否为广播消息,
(2.3.a)若是,则进一步判断数据源接入任务同步启动线程数是否超过当前接入执行器最大同步线程数限制,
(2.3.a.a)若未超过当前接入执行器最大同步线程数限制、且当前接入任务状态为启动中,则将接入任务状态更新为运行中,并将接入任务同步线程数自增1,
(2.3.a.b)若超过当前接入执行器最大同步线程数限制,则将接入任务状态更新为部分成功,
(2.3.b)若否,则执行步骤(2.4);
(2.4)判断接入任务消息类型是否为单播消息,
(2.4.a)若是,则进一步判断数据源接入任务同步启动线程数是否超过当前接入执行器最大同步线程数限制,
(2.4.a.a)若未超过当前接入执行器最大同步线程数限制,则获取Redis分布式锁成功,将任务状态更新为启动中,并将接入任务同步线程数自增1;
(2.4.a.b)若超过当前接入执行器最大同步线程数限制,则获取分布式锁失败。
进一步可选的,所涉及接入层的接入执行器中数据源接入任务同步线程执行流程为:
(3.1)查询接入任务信息,创建Kafka消费者,循环拉取接入任务对应数据源KafkaTopic的数据;
(3.2)拉取接入任务对应数据源Kafka Topic的数据前,首先查询当前接入任务状态是否为运行中,
(3.2a)若不为运行中,则循环结束,线程终止,
(3.2b)若为运行中,则执行步骤(3.4);
(3.4)判断接入数据量是否超过租户最大配额,
(3.4.a)若接入数据量未超过租户最大配额,则将接收数据封装为解析报文,并将解析报文通过Kafka发送到解析层中解析执行器统一的Kafka Topic中,
(3.4.b)若接入数据量超过租户最大配额,则循环结束,线程终止,并将任务状态设置为停止。
进一步可选的,所涉及解析层采用统一的Kafka Topic汇聚不同租户数据源的数据,并对数据源中的指标、实例以及指标实例进行解析,具体流程包括:
(4.1)解析层的解析执行器获取解析报文中的租户编码,并将数据库数据源切换为租户数据源;
(4.2)判断当前数据源中是否存在相同实例名称的实例,
(4.2.a)若存在,则从Redis中获取实例ID,
(4.2.b)若不存在,则首先获取Redis分布式锁,获取锁成功,则在当前数据源下新增一个实例,获取锁失败,则从Redis中获取实例ID;
(4.3)判断当前数据源中是否存在相同名称的指标,
(4.3.a)若存在,则从Redis中获取指标ID,
(4.3.b)若不存在,则获取Redis分布式锁,获取锁成功,则在当前数据源下新增一个指标,获取锁失败,则从Redis获取指标ID;
(4.4)判断当前数据源中是否存在相同指标名和实例名的指标实例,
(4.4.a)若存在,则从Redis中获取指标实例ID,
(4.4.b)若不存在,则获取Redis分布式锁,获取锁成功,则在当前数据源下新增一个指标实例,获取锁失败,则从Redis中获取指标实例ID;
(4.5)将指标实例对应的指标值保存到时序数据库中,并判断当前指标实例是否存在指标分析任务,
若存在,则封装指标分析报文,并将指标分析报文发送到分析层中分析执行器统一的Kafka Topic中。
本发明的一种面向多租户的时序数据分布式处理系统,与现有技术相比具有的有益效果是:
本发明分离设置接入层、解析层、分析层,以方便用户可以按需水平扩展每一层的处理能力以满足需求,具有较强的灵活性;本发明的解析层和分析层采用统一的KafkaTopic汇聚待处理数据,实现多租户数据的透明处理;本发明的接入层通过接入任务启动消息的广播和单播实现接入任务的资源分摊,以及租户资源的按需申请,不需要复杂第三方的资源调度组件即可实现资源的调度。
附图说明
附图1是本发明的系统架构图;
附图2是本发明的数据源数据处理逻辑图;
附图3是本发明的请求启动数据源接入任务同步线程流程图;
附图4是本发明的接入执行器接入任务启动消息的处理流程图;
附图5是本发明的接入执行器中数据源接入任务同步线程执行流程图;
附图6是本发明的解析执行器处理流程。
具体实施方式
为使本发明的技术方案、解决的技术问题和技术效果更加清楚明白,以下结合具体实施例,对本发明的技术方案进行清楚、完整的描述。
实施例一:
结合附图1-6,本实施例提出一种面向多租户的时序数据分布式处理系统,其实现基于数据源,分离设置的接入层、解析层、分析层,以及存储层。
数据源通过Kafka接入,每个数据源的Kafka Topic包含多个分区,以支持水平扩展。不同数据源对应的Kafka Topic可以相同,也可以不同。
接入层不仅负责数据源接入任务同步线程的创建、租户权限的校验,还负责从数据源拉取数据添加租户信息封装为解析报文,并通过Kafka发送到解析层。
解析层不区分租户,采用统一的Kafka Topic汇聚不同租户数据源的数据,并对数据源中的指标、实例以及指标实例进行解析,随后通过Kafka发送到分析层。
分析层不区分租户,采用统一的Kafka Topic汇聚不同租户数据源的数据,并完成指标、实例以及指标实例的分析。
存储层采用influxdb时序数据库保存接入层、解析层、分析层产生的实时数据。
本实施例中,参考附图1,接入层包含N个接入执行器,并支持水平扩展;解析层包含P个解析执行器,并支持水平扩展;分析层包含Q个分析执行器,并支持水平扩展,其中,N、P、Q的值可以相等,也可以不相等。每个接入执行器、解析执行器、分析执行器对应一个docker容器,并包含多个Kafka消费者,其中,每一个消费者对应一个执行器中的独立处理线程。参考附图2,通常,一个消费者处理一个分区的数据,但是,当消费者数量不足时,一个消费者也可以处理两个、三个甚至多个分区的数据,此时,这个消费者按序处理不同分区的数据,效率必定会有所降低。
本实施例中,结合附图3,用户通过接入层创建数据源接入任务同步线程后,请求启动数据源接入任务同步线程,此时,
(1.1)接入层从请求头中获取租户编码,并将数据库数据源切换为租户数据源,
(1.2)接入层根据接入任务对应的消息数量,利用Redis发布订阅功能向接入执行器发送数据源同步启动消息,
(1.3)接入层将接入任务的状态设置为启动中,同时,将接入任务同步线程数设置为0。
结合附图4,接入层的接入执行器接收到数据源接入任务启动消息后,
(2.1)获取数据源接入任务启动消息中的租户编码,并将数据库数据源切换为租户数据源;
(2.2)判断数据源接入任务同步启动线程数是否超过租户最大允许同步线程数,
(2.2.a)若超过,则将接入任务状态设置为启动失败,
(2.2.b)若未超过,则执行步骤(2.3);
(2.3)判断接入任务消息类型是否为广播消息,
(2.3.a)若是,则进一步判断数据源接入任务同步启动线程数是否超过当前接入执行器最大同步线程数限制,
(2.3.a.a)若未超过当前接入执行器最大同步线程数限制、且当前接入任务状态为启动中,则将接入任务状态更新为运行中,并将接入任务同步线程数自增1,
(2.3.a.b)若超过当前接入执行器最大同步线程数限制,则将接入任务状态更新为部分成功,
(2.3.b)若否,则执行步骤(2.4);
(2.4)判断接入任务消息类型是否为单播消息,
(2.4.a)若是,则进一步判断数据源接入任务同步启动线程数是否超过当前接入执行器最大同步线程数限制,
(2.4.a.a)若未超过当前接入执行器最大同步线程数限制,则获取Redis分布式锁成功,将任务状态更新为启动中,并将接入任务同步线程数自增1;
(2.4.a.b)若超过当前接入执行器最大同步线程数限制,则获取分布式锁失败。
结合附图5,接入层的接入执行器中数据源接入任务同步线程执行流程为:
(3.1)查询接入任务信息,创建Kafka消费者,循环拉取接入任务对应数据源KafkaTopic的数据;
(3.2)拉取接入任务对应数据源Kafka Topic的数据前,首先查询当前接入任务状态是否为运行中,
(3.2a)若不为运行中,则循环结束,线程终止,
(3.2b)若为运行中,则执行步骤(3.4);
(3.4)判断接入数据量是否超过租户最大配额,
(3.4.a)若接入数据量未超过租户最大配额,则将接收数据封装为解析报文,并将解析报文通过Kafka发送到解析层中解析执行器统一的Kafka Topic中,
(3.4.b)若接入数据量超过租户最大配额,则循环结束,线程终止,并将任务状态设置为停止。
本实施例中,解析层采用统一的Kafka Topic汇聚不同租户数据源的数据,并对数据源中的指标、实例以及指标实例进行解析,结合附图6,具体流程包括:
(4.1)解析层的解析执行器获取解析报文中的租户编码,并将数据库数据源切换为租户数据源;
(4.2)判断当前数据源中是否存在相同实例名称的实例,
(4.2.a)若存在,则从Redis中获取实例ID,
(4.2.b)若不存在,则首先获取Redis分布式锁,获取锁成功,则在当前数据源下新增一个实例,获取锁失败,则从Redis中获取实例ID;
(4.3)判断当前数据源中是否存在相同名称的指标,
(4.3.a)若存在,则从Redis中获取指标ID,
(4.3.b)若不存在,则获取Redis分布式锁,获取锁成功,则在当前数据源下新增一个指标,获取锁失败,则从Redis获取指标ID;
(4.4)判断当前数据源中是否存在相同指标名和实例名的指标实例,
(4.4.a)若存在,则从Redis中获取指标实例ID,
(4.4.b)若不存在,则获取Redis分布式锁,获取锁成功,则在当前数据源下新增一个指标实例,获取锁失败,则从Redis中获取指标实例ID;
(4.5)将指标实例对应的指标值保存到时序数据库中,并判断当前指标实例是否存在指标分析任务,
若存在,则封装指标分析报文,并将指标分析报文发送到分析层中分析执行器统一的Kafka Topic中。
综上可知,采用本发明的一种面向多租户的时序数据分布式处理系统,可以方便用户可以按需水平扩展每一层的处理能力以满足需求,实现多租户数据的透明处理,实现接入任务的资源分摊和租户资源的按需申请,不需要复杂第三方的资源调度组件即可实现资源的调度。
以上应用具体个例对本发明的原理及实施方式进行了详细阐述,这些实施例只是用于帮助理解本发明的核心技术内容。基于本发明的上述具体实施例,本技术领域的技术人员在不脱离本发明原理的前提下,对本发明所作出的任何改进和修饰,皆应落入本发明的专利保护范围。
- 一种面向SaaS多租户以剧本为核心的云端影视项目管理方法与系统
- 一种加快面向多租户云存储系统数据索引的方法
- 一种加快面向多租户云存储系统数据索引的方法