用于GPU IP验证的联合仿真系统
文献发布时间:2023-06-19 18:30:43
技术领域
本发明涉及GPU芯片验证技术领域,尤其涉及一种用于GPU IP验证的联合仿真系统。
背景技术
现有的芯片验证过程通常是基于同一芯片设计使用说明书,采用硬件描述语言(Register Transistor Level,简称RTL)编写的待测设计(Design Under Test,简称DUT),同时采用C语言、C++、SystemC等高级语言编写的参考模型(Reference Model)。验证过程中向待测设计和参考模型输入相同的激励,进行联合仿真,通过比较待测设计和参考模型的输出对待测设计进行验证。但是,现有的参考模型是无时序的,仅能对芯片功能进行验证,不能验证芯片性能,且验证准确性不高。
图形处理器(Graphics Processing Unit,简称GPU)自底向上分别为组成单元(Unit)、组成模块(Block)、子系统(Sub System)、GPU知识产权核(IntellectualProperty,简称IP),在验证过程中需要对组成单元、组成模块、子系统、GPU IP进行验证和重用。GPU各个组成部分内部复杂,且验证过程中,参考模型需要遵循GPU内部的时序,在联合仿真过程中,如何让待测设计和参考模型获取相同的时序驱动实现正确的互动尤为重要,而现有技术的仿真过程无法准确控制待测设计和参考模型获取相同的时序,导致芯片验证的准确性和可靠性低。此外,现有的仿真过程是基于信号级别的访问,导致验证效率低,无法满足GPU芯片验证的需求。由此可知,如何提供一种准确、可靠、高效的适用于GPU芯片验证的联合仿真技术,实现对GPU芯片的验证,成为亟待解决的技术问题。
发明内容
本发明目的在于,提供一种用于GPU IP验证的联合仿真系统,实现了对GPU IP的准确、可靠、高效的联合仿真。
本发明提供一种用于GPU IP验证的联合仿真系统,包括待测设计、参考模型、OpenCL库、OpenGL库、激励生成接口、追踪文件生成模块、第六验证平台,其中,所述待测设计为GPU IP,所述OpenCL库、OpenGL库与激励生成接口相连接,所述激励生成接口与所述参考模型相连接,所述追踪文件生成模块与所述参考模型相连接;所述第六验证平台包括第六激励发生器、第六比较器和第六监视器,所述第六激励发生器与所述待测设计和追踪文件生成模块相连接,所述第六监视器与追踪文件生成模块和待测设计相连接,所述第六比较器与第六监视器相连接。
所述激励生成接口用于访问OpenCL库和OpenGL库生成第六测试激励,所述第六测试激励为C++数据结构类型。
所述参考模型用于从所述激励生成接口获取第六测试激励,按照待测设计的时序从所述参考模型的输入端口传输至所述参考模型中执行,并从所述参考模型的输出端口输出第六模型输出结果。
所述追踪文件生成模块用于从所述参考模型的输入端口转存第六测试激励,生成输入追踪文件,还用于从所述参考模型的输出端口转存第六模型输出结果,生成输出追踪文件。
所述第六激励发生器用于从所述追踪文件生成模块获取输入追踪文件,解析生成第七测试激励,按照待测设计的时序发送给待测设计。
所述待测设计用于执行所述第七测试激励,生成第六待测设计输出结果。
所述第六监视器还用于从所述待测设计获取第六待测设计输出结果,从所述追踪文件生成模块中获取输出追踪文件,进行解析,得到对应的第六模型输出结果。
所述第六比较器用于基于所述第六待测设计输出结果和对应的第六模型输出结果对待测设计进行验证。
本发明与现有技术相比具有明显的优点和有益效果。借由上述技术方案,本发明提供的一种用于GPU IP验证的联合仿真系统可达到相当的技术进步性及实用性,并具有产业上的广泛利用价值,其至少具有下列优点:
本发明实施例五基于OpenCL库、OpenGL库生成参考模型的对应的测试激励,通过运行参考模型,生成对应的追踪文件,再基于追中文件得到待测设计对应的测试激励,运行待测设计,然后再基于待测设计和参考模型的输出结果对待测设计进行验证,实现了对GPUIP的准确、可靠、高效的联合仿真。
上述说明仅是本发明技术方案的概述,为了能够更清楚了解本发明的技术手段,而可依照说明书的内容予以实施,并且为了让本发明的上述和其他目的、特征和优点能够更明显易懂,以下特举较佳实施例,并配合附图,详细说明如下。
附图说明
图1为本发明实施例一提供的基于DPI的GPU联合仿真系统示意图;
图2为本发明实施例二提供的基于TLM的GPU联合仿真系统示意图;
图3为本发明实施例三提供的多模式GPU联合仿真系统示意图;
图4为本发明实施例四提供的基于波形的GPU联合仿真系统;
图5为本发明实施例五提供的用于GPU IP验证的联合仿真系统。
具体实施方式
为更进一步阐述本发明为达成预定发明目的所采取的技术手段及功效,以下结合附图及较佳实施例,对依据本发明提出的一种用于GPU IP验证的联合仿真系统的具体实施方式及其功效,详细说明如后。
图形处理器(Graphics Processing Unit,简称GPU)内部结构复杂,为多层级结构,GPU的组成部分包括组成单元(Unit)、组成模块(Block)、子系统(Sub System)、GPU知识产权核(Intellectual Property,简称IP),其中,组成模块由组成单元组成,子系统由组成单元和/或组成模块组成,GPU IP由组成单元和/或组成模块和/或子系统组成。GPU组成部分根据验证过程中输入激励的不同可以分为两类,第一类为组成单元、组成模块、子系统,当组成单元、组成模块、子系统作为待测设计(Design Under Test,简称DUT)时,测试激励为SystemVerilog和UVM(Universal Verification Methodology)编写的带约束的随机验证激励。第二类为GPU IP,GPU IP很大部分对应的是C++语言,因为从GPU编程角度,通常基于开放运算语言库(Open Computing Language,简称OpenCL)和开放式图形库(OpenGraphics Library,简称OpenGL)来编辑和操作GPU。因此,在对GPU IP做验证时,需要基于OpenCL库和OpenGL库编程来生成测试激励。两种类型的测试激励不同,因此进行联合仿真的实现方式也不相同,以下通过不同的具体实施例分别进行说明。
实施例一、
实施例一提供了一种基于直接编程接口(Direct Programming Interface,简称DPI)的GPU联合仿真系统,如图1所示,用于GPU验证过程,包括第一验证平台、待测设计和参考模型,所述待测设计为GPU的组成部分,具体为GPU的组成单元、组成模块或子系统。所述第一验证平台包括第一激励发生器、第一转换器、第一监视器和第一比较器。其中,所述第一激励发生器与待测设计相连接,所述第一监视器分别与待测设计、第一转换器和第一比较器相连接,所述第一转换器与参考模型相连接。
所述第一激励发生器用于生成第一测试激励,所述第一测试激励为基于SystemVerilog和UVM编写的带约束的随机验证激励,按照待测设计的时序将所述第一测试激励发送给待测设计,所述第一测试激励为事务类型数据(Transaction),需要说明的是,事务类型数据相较于信号级的数据传输效率更高。
所述第一监视器用于采集输入所述待测设计的有效第一测试激励,发送给第一转换器;
作为示例,参考模型是有C++或其他高级语言编写的模型,由于SystemVerilog语言和C++等高级语言不能直接交互,且参考语言本身并不能按照待测设计时序运行,因此设置第一转换器和直接编程接口DPI来实现参考模型与测试平台的交互,以及实现按照待测设计的时序运行。所述第一转换器用于将第一测试激励转换为第一输入数据,所述第一输入数据为目标结构体类型,若参考模型为C++模型,则目标结构体为C++结构体(Struct),所述目标结构体为所述参考模型能够识别的结构体。所述第一转换器按照待测设计的时序通过直接编程接口DPI将所述第一输入数据发送给参考模型,并调用所述参考模型按照待测设计的时序执行所述第一输入数据,再通过直接编程接口DPI从所述参考模型获取第一运行结果,所述第一运行结果为目标结构体类型数据,将所述第一运行结果转换为事务类型数据,作为第一模型输出结果。
所述待测设计用于执行所述第一测试激励,生成第一待测设计输出结果。
所述第一监视器还用于从所述第一转换器获取第一模型输出结果,从所述待测设计获取第一待测设计输出结果,并发送给所述第一比较器。
所述第一比较器用基于所述第一模型输出结果和第一待测设计输出结果对待测设计进行验证。
作为一种示例,所述系统包括预先基于SystemVerilog和UVM编写的第一转换器父类(Base),所述第一转换器为基于所述第一转换器父类生成的子类。所述第一转换器父类中包括第一创建接口、第一初始化接口、第一数据存入接口、第一运行接口和第一数据取出接口,第一创建接口、第一初始化接口、第一数据存入接口、第一运行接口和第一数据取出接口均为应用程序接口(Application Programming Interface,简称API),所述第一转换器父类配置为:
在UVM的build_phase调用第一创建接口创建所述参考模型,调用所述第一初始化接口初始化所述参考模型。其中创建所述参考模型指的是实例化生成一个参考模型。
在UVM的run_phase调用所述第一数据存入接口按照待测设计的时序向所述参考模型的第一数据存入接口存入第一输入数据;调用所述第一运行接口触发所述参考模型按照待测设计的时序执行所述第一输入数据,生成第一运行结果;调用所述第一数据取出接口将所述第一运行结果存放在所述参考模型的输出接口。
需要说明的是,第一数据存入接口、第一运行接口和第一数据取出接口在每一个时钟周期内都在运行,若当前时钟周期没有有效数据,则第一数据存入接口轮空即可。
作为一种示例,所述第一转换器父类中还包括第一检查接口和第一复位接口,第一检查接口和第一复位接口也为应用程序接口,所述第一转换器父类还配置为:
在UVM的run_phase或者系统上电过程中,调用所述第一复位接口执行复位操作;复位操作分为两种,一种是系统上电过程的复位操作,一种是在运行过程中的复位过程。
在UVM的check_phase调用所述第一检查接口检查所述参考模型的最终状态是否正确。
需要说明的是,build_phase、run_phase、run_phase、check_phase均为UVM中的已有的phase,在此不再赘述,还可以基于其他应用需求绑定其他phase,例如connect_phase,不再一一列举。实施例一通过将上述phase与对应的接口进行绑定,来实现参考模型按照待测设计的时序运行。
作为一种示例,所述第一验证平台还包括第一事务级模块,所述第一事务级模块包括第一转换接口和第二转换接口,所述第一转换接口用于把事务类型数据转换为目标结构体类型数据,所述第二转换接口用于把目标结构体类型数据转换为事务类型数据。
在GPU联合仿真过程中,所述第一转换器接收第一测试激励后,调用所述第一转换接口将所述第一测试激励转换为所述第一输入数据,在UVM的run_phase调用所述第一数据存入接口,在所述第一数据存入接口中生成对应的直接编程接口DPI,通过对应的直接编程接口DPI按照待测设计的时序向所述参考模型的第一数据存入接口存入所述第一输入数据。
所述第一转换器调用所述第一运行接口,触发所述参考模型按照待测设计的时序执行所述第一输入数据,生成第一运行结果。
所述第一转换器调用所述第一数据取出接口,将所述第一运行结果存放在所述参考模型的输出接口,在所述第一数据取出接口中生成并调用对应的直接编程接口DPI,通过对应的直接编程接口DPI将所述第一运行结果传输给所述第一转换器,所述第一转换器调用所述第二转换接口将所述第一运行结果转换为事务类型数据,作为所述第一模型输出结果。
作为一种示例,所述参考模型内设置有时钟周期运行机制和时钟周期运行机制接口,所述第一转换器通过所述第一运行接口调用所述时钟周期运行机制接口,所述时钟周期运行机制接口调用所述时钟周期运行机制,在所述参考模型中运行一个时钟周期,频率和待测设计的频率保持一致。需要说明的是,参考模型本身并没有时序的设置,通过在参考模型内设置有时钟周期运行机制和时钟周期运行机制接口,再基于第一转换器对应的各个接口的调用,使得参考模型也可以按照待测设计的时序来运行,从而实现对待测设计的功能和性能验证,需要说明的是,参考模型进行性能验证的时序精度大于参考模型进行功能验证的精度。
由于待测设计和参考模型处理速度不同,为了保持时序一致,作为一种实施例,所述第一转换器的输入端口设置有第一先入先出队列(First Input First Output,简称FIFO),所述待测设计的输入端口设置有第二FIFO。
所述第一FIFO用于缓存第一测试激励,在向所述待测设计输入第一测试激励时,先判断当前第一FIFO待输出的第一测试激励是否符合预设的第一预设驱动逻辑,若符合,则向所述待测设计输入待输出的第一测试激励,若不符合,则待符合预设的第一预设驱动逻辑后,再向所述待测设计输入待输出的第一测试激励。
所述第二FIFO用于缓存第一输入数据,在UVM的run_phase调用所述第一数据存入接口之前,先判断当前第二FIFO待输出的目标结构体是否符合预设的第一预设驱动逻辑,若符合,则再执行在UVM的run_phase调用所述第一数据存入接口以及后续操作,若不符合,则待符合对应的预设的第一预设驱动逻辑之后,再执行在UVM的run_phase调用所述第一数据存入接口以及后续操作。
其中,所述第一预设驱动逻辑包括执行完预设数量的时钟周期、已经获取到预设的输出数据等。通过设置第一FIFO、第二FIFO和第一预设驱动逻辑能够保持参考模型和待测设计时序的一致性。
作为一种示例,所述待测设计包括多个层级设计的组成单元,两个互联的组成单元之间通过至少一个总线接口连接,所述第一测试激励基于对应的总线接口信息自动生成,所述直接编程接口DPI基于对应的总线接口信息和层级信息自动生成。具体的,待测设计={U
作为一种实施例,X
优选的,IDF-ID
需要说明的是,总线接口重构结构IDF中包含了详细的总线接口信息,将详细的总线接口信息存储到事务级数据对应的域中,可以自动生成第一测试激励。直接编程接口DPI包括发送端、接收端和对应操作指令,设计互联组装DIY中包括了层级信息,发送端和接收端的信息可以直接从层级信息中获取,第一转换器向参考模型发送数据的直接编程接口DPI对应的操作指令为set指令,第一转换器从参考模型发送数据的直接编程接口DPI对应的操作指令为get指令,因此可以自动化生成第一测试激励和直接编程接口DPI,且即便待测设计更改,对应的IDF和DIY更改,直接编程接口DPI也会随着IDF和DIY更改自动更改。
实施例一所述系统通过设置第一转换器和直接编程接口DPI实现了参考模型与第一测试平台的交互,并能够按照待测设计的时序运行,能够准确、可靠、高效地实现对GPU的组成单元、组成模块或子系统验证过程中的联合仿真,提高了GPU的组成单元、组成模块或子系统的验证可靠性、高效性和准确性。
实施例二、
实施例二提供了一种基于TLM(Transaction Level Modeling)的GPU联合仿真系统,用于GPU验证过程,所述待测设计为GPU的组成单元、组成模块或子系统,如图2所示,包括第二验证平台、待测设计和参考模型,所述待测设计为GPU的组成部分,所述第二验证平台包括第二激励发生器、第二转换器、第二监视器和第二比较器,其中,所述第二激励发生器与待测设计相连接,所述第二监视器分别与待测设计、第二转换器和第二比较器相连接,所述第二转换器与参考模型相连接,所述参考模型采用SystemC封装。
所述第二激励发生器用于生成第二测试激励,所述第二测试激励为基于SystemVerilog和UVM编写的带约束的随机验证激励,按照待测设计的时序发送给待测设计,所述第二测试激励为事务类型数据,可以理解的是所述第二测试激励与实施例一种的第一测试激励相同。
所述第二监视器用于采集输入所述待测设计的有效第二测试激励,发送给第二转换器。
如实施例一中所述,参考模型不能与测试平台直接交互,实施例二通过设置第一转换器和事务级传输通道TLM可以实现参考模型与测试平台的交互,以及实现按照待测设计的时序运行,所述第二转换器用于将第二测试激励的指针转换为第二输入数据,所述第二输入数据为通用数据包(Payload)类型,具体设置为不定长的向量,这样使得传输指针,且传输的数据类型相同,根据数据具体取值的不同设置不同的向量长度即可。所述第二转换器按照待测设计的时序通过事务级传输通道TLM发送给参考模型,并调用所述参考模型按照待测设计的时序执行所述第二输入数据,然后通过事务级传输通道TLM从所述参考模型获取第二运行结果,所述第二运行结果为通用数据包类型,将所述第二运行结果转换为事务类型数据,作为第二模型输出结果。通过事务级传输通道传输通用数据包类型的而输入数据,相较于实施例一种传输事务级类型的第一输入数据传输效率更高,系统性能更好。而实施例一种传输的事务级类型的第一输入数据相较于实施例二中传输的通用数据包类型的第二输入数据更加直观,可以根据具体的应用需求选择对应的传输方式。所述事务级传输通道TLM遵循TLM协议,优选的,事务级传输通道TLM为TLM2通道。需要说明的是,通用数据包中可以存入一个第二输入数据,也可以通过打包存入多个第二输入数据,优选的,本实施例每次传输的通用数据包中仅存入一个第二输入数据,避免后续解压。
所述待测设计用于执行所述第二测试激励,生成第二待测设计输出结果。
所述第二监视器还用于从所述第二转换器获取第二模型输出结果,从所述待测设计获取第二待测设计输出结果,并发送给所述第二比较器;
所述第二比较器用基于所述第二模型输出结果和第二待测设计输出结果对待测设计进行验证。
作为一种示例,所述系统包括预先基于SystemVerilog和UVM编写的第二转换器父类,所述第二转换器为基于所述第二转换器父类生成的子类,所述第二转换器父类中包括第二创建接口、第二初始化接口、第二数据存入接口和第二数据取出接口,第二创建接口、第二初始化接口、第二数据存入接口和第二数据取出接口均为应用程序接口,所述第二转换器父类配置为:
在UVM的build_phase调用第二创建接口创建所述参考模型,调用所述第二初始化接口初始化所述参考模型;
在UVM的run_phase调用所述第二数据存入接口按照待测设计的时序向所述参考模型的第二数据存入接口存入第二输入数据,触发对应的总线接口的存入事件,当所有预设的所有总线接口均触发存入事件时,触发所述参考模型按照待测设计的时序执行所述第二输入数据,生成第二运行结果;调用所述第二数据取出接口将所述第二运行结果存放在所述参考模型的输出接口。
需要说明的是,相较于实施例一,实施例二中无需设置第一运行接口,而是直接设置事件机制,触发相应事件,来控制参考模型按照待测设计的时序执行所述第二输入数据,提高了系统性能,此外,事务级传输通道TLM具体包括阻塞模式和非阻塞模式,本实施例中,优选的,将事务级传输通道TLM设置为阻塞模式,待所有预设的所有总线接口均触发存入事件时,再触发所述参考模型按照待测设计的时序执行所述第二输入数据,生成第二运行结果。此外,每一运行的总线接口无论当前时钟周期是否有有效数据,均会触发对应的总线接口的存入事件,只是没有有效数据时,对应数据为空即可。
作为一种实施例,所述第二转换器父类中还包括第二检查接口和第二复位接口,所述第二转换器父类还配置为:
在UVM的run_phase或者系统上电过程中,调用所述第二复位接口执行复位操作;复位操作分为两种,一种是系统上电过程的复位操作,一种是在运行过程中的复位过程。
在UVM的check_phase调用所述第二检查接口检查所述参考模型的最终状态是否正确。
需要说明的是,build_phase、run_phase、run_phase、check_phase均为UVM中的已有的phase,在此不再赘述,还可以基于其他应用需求绑定其他phase,例如connect_phase,不再一一列举。实施例二通过将上述phase与对应的接口进行绑定,来实现参考模型按照待测设计的时序运行。
作为一种示例,所述第二验证平台还包括第二事务级模块,所述第二事务级模块包括第三转换接口和第四转换接口,所述第三转换接口用于把事务类型数据转换为通用数据包类型数据,所述第二转换接口用于把通用数据包类型数据转换为事务类型数据。
在GPU联合仿真过程中,所述第二转换器接收第二测试激励后,调用所述第三转换接口将所述第二测试激励转换为所述第二输入数据,在UVM的run_phase调用所述第二数据存入接口,在所述第二数据存入接口中生成对应的事务级传输通道TLM,通过对应的事务级传输通道TLM按照待测设计的时序向所述参考模型的第二数据存入接口存入所述第二输入数据,触发对应的总线接口的存入事件,当所有预设的所有总线接口均触发存入事件时,触发所述参考模型按照待测设计的时序执行所述第二输入数据,生成第二运行结果。
所述第二转换器调用所述第二数据取出接口,将所述第二运行结果存放在所述参考模型的输出接口,在所述第二数据取出接口中生成并调用对应的事务级传输通道TLM,通过对应的事务级传输通道TLM将所述第二运行结果传输给所述第二转换器,所述第二转换器调用所述第四转换接口将所述第二运行结果转换为事务类型数据,作为所述第二模型输出结果。
作为一种示例,所述参考模型内设置有时钟周期运行机制和时钟周期运行机制接口,所述第二转换器通过触发所有预设的所有总线接口的存入事件,触发并调用所述时钟周期运行机制接口,所述时钟周期运行机制接口调用所述时钟周期运行机制,在所述参考模型中运行一个时钟周期。需要说明的是,参考模型本身并没有时序的设置,通过在参考模型内设置有时钟周期运行机制和时钟周期运行机制接口,再基于第二转换器对应的各个接口的调用,使得参考模型也可以按照待测设计的时序来运行,从而实现对待测设计的功能和性能验证,需要说明的是,参考模型进行性能验证的时序精度大于参考模型进行功能验证的精度。
实施例二中也可设置入实施例一中的第一FIFO和第二FIFO来解决待测设计和参考模型处理速度不同的问题,使得待测设计和参考模型时序保持一致,实现技术细节与实施例一相同,在此不再赘述。
作为一种示例,所述待测设计包括多个层级设计的组成单元,两个互联的组成单元之间通过至少一个总线接口连接,所述第二测试激励基于对应的总线接口信息自动生成,所述事务级传输通道TLM基于对应的总线接口信息和层级信息自动生成。待测设计的具体组成,以及IDF和DIY的描述细节已在实施例一中描述,在此不再赘述。
实施例二所述系统通过设置第二转换器和事务级传输通道TLM实现了参考模型与第二测试平台的交互,并能够按照待测设计的时序运行,能够准确、可靠、高效地实现对GPU的组成单元、组成模块或子系统验证过程中的联合仿真,提高了GPU的组成单元、组成模块或子系统的验证可靠性、高效性和准确性。
实施例三、
实施例一和实施例二均是在待测设计、参考模型以及验证平台开发到一定阶段,能够实现联合仿真的况下进行的,但是在开发前期,待测设计、参考模型和测试平台均未开发完善,还不能直接进行联合仿真,但是在开发初期也是需要及时发现待测设计和参考模型的问题,以便及时调整。此外,实施例一和实施例二在联合仿真过程中,一旦参考模型出现问题,则会直接导致联合仿真无法运行,基于上述问题,进一步提出了实施例三。
实施例三提供了一种多模式GPU联合仿真系统,用于GPU验证过程,如图3所示,包括待测设计、参考模型、第一验证结构、第二验证结构和第三验证结构,所述待测设计为GPU的组成部分,所述待测设计为GPU的组成单元、组成模块或子系统。所述系统的工作模式包括参考模型单独工作模式、待测设计单独工作模式和联合仿真模式。
在待测设计和参考模型开发的第一阶段,所述系统设置为参考模型单独工作模式,通过运行所述第一验证结构,验证参考模型,或者,所述系统设置为待测设计单独工作模式,通过所述第二验证结构,验证所述待测设计;所述第一阶段为待测设计和参考模型的设计初期,不能直接基于待测设计和参考模型进行联合仿真的阶段。在第一阶段通过验证参考模型、待测设计,可以更早发现参考模型和待测设计中存在的问题,及时进行调试。
在待测设计和参考模型开发的第二阶段,所述系统设置为联合仿真模式,通过所述第三验证结构基于所述参考模型验证待测设计,若所述参考模型故障,则切换为待测设计单独工作模式,通过所述第一验证结构验证所述待测设计,同时采用参考模型单独工作模式,通过所述第一验证结构,定参考模型故障点,其中,第二测试阶段指的是待测设计、参考模型和测试平台的设置能够直接进行联合仿真的阶段,所述第一阶段早于所述第二阶段,第三工作模式可以使得在联合仿真过程中,即便参考模型的通路出现故障也依然能切换到待测设计单独工作模式,通过所述第一验证结构验证所述待测设计,且能及时通过参考模型单独工作模式,通过所述第一验证结构,定参考模型故障点,及时修正参考模型。
需要说明的是,参考模型单独工作模式和待测设计单独工作模式,为两个独立的工作模式,可以独立并行运行。通过设置多模式的GPU联合仿真系统,可以使得参考模型和待测设计解耦合,提高了系统的稳定性和可靠性。
作为一种示例,所述第一验证结构包括第三验证平台,所述第三验证平台包括第三激励发生器和第三比较器,所述第三激励发生器与所述参考模型连接,所述第三比较器与所述第三激励发生器和参考模型连接,在参考模型单独工作模式下:
所述第三激励发生器用于向所述参考模型和第三比较器发送第三测试激励,所述第三测试激励为用于验证参考模型的激励,所述参考模型基于所述第三测试激励进行运行,生成第三运行结果发送给第三比较器。
所述第三比较器用于基于所述第三测试激励预测模型预测结果,并发送给所述第三比较器,需要说明的是,第三比较器中可以预设预测参考模型结果的逻辑。
所述第三比较器用于基于所述第三运行结果和模型预测结果验证所述参考模型。
通过在第一阶段验证参考模型可以及时发现参考模型的缺陷,调试参考模型。
作为一种示例,所述第二验证结构包括第四验证平台,所述第四验证平台包括第四激励发生器和波形生成器,所述待测设计分别与所述第四激励发生器和波形生成器相连接,在待测设计单独工作模式下。
所述第四激励发生器用于向所述待测设计发送第四测试激励,所述待测设计基于所述第四测试激励生成第四运行结果,并发送给波形生成器,需要说明的是,待测设计是基于Verilog、System Verilog、VHDL等硬件编程语言编写的设计,因此可以直接生成波形文件,现有的基于待测设计生成波形文件的实现方案全部落入本发明保护范围之内。
所述波形生成器基于所述第四运行结果生成待测设计波形文件,基于所述待测设计波形文件验证所述待测设计,基于波形文件可以生成对应的波形,基于波形可以更加直观地验证待测设计。
所述第三验证结构可以直接采用实施例一种的系统结构,也可以直接采用实施例二中的系统结构,具体细节已在实施例一和实施例二中展开,在此不再赘述。
实施例三通过设置不同的验证结构和工作模式,使得所述系统能够在不同的阶段对待测设计和参考模型进行验证,也使得参考模型和待测设计解耦合,便于更早发现并修正待测设计和参考模型的问题,提高了GPU联合仿真的准确性和可靠性。
实施例四、
实施例三中,在待测设计和参考模型开发的第一阶段,仅能通过基于所述第三测试激励预测模型预测结果来验证参考模型,但预测精确度有限,仅能发现少量的问题,如果需要分析更多数据,只能从参考模型运行的日志数据中来获取,但是日志数据多而繁杂,很难直接通过日志数据进行分析。而在第一阶段的待测设计通过获取波形文件,可以通过波形直观获取数据进行分析。此外,在第一阶段,由于参考模型、待测设计以及验证平台设计的不够完备,还不能实现基于待测设计和参考模型的联合仿真。基于上述问题,进一步提出了实施例四。
实施例四提供了一种基于波形的GPU联合仿真系统,如图4所示,用于待测设计和参考模型开发的第一阶段,所述第一阶段为待测设计和参考模型的设计初期,不能直接基于待测设计和参考模型进行联合仿真的阶段;所述系统包括待测设计、参考模型、第五验证平台、空壳模块、第一波形生成器、第二波形生成器和显示器,所述空壳模块(Stub)为只包括待测设计的顶层输入端口和输出端口信息的模块,也即待测设计是设计实体,空壳模块是待测设计对应的仅包括顶层端口信息的壳体。所述待测设计为GPU的组成部分,具体为GPU的组成单元、组成模块或子系统。
所述第五验证平台包括第五激励发生器、第五转换器、第五监视器,所述第五激励发生器分别与待测设计和第五监视器相连接,所述第五转换器与参考模型、空壳模块和第五监视器相连接,所述第一波形生成器与所述待测设计相连接,所述第二波形生成器与所述空壳模块相连接,所述显示器和第一波形生成器和第二波形生成器相连接。
所述第五激励发生器用于生成第五测试激励,所述第五测试激励为基于SystemVerilog和UVM编写的带约束的随机验证激励,按照待测设计的时序发送给待测设计,所述第五测试激励为事务类型数据。
所述第一波形生成器用于采集待测设计对应的第一波形文件,发送给所述显示器,需要说明的是,待测设计是基于Verilog、System Verilog、VHDL等硬件编程语言编写的设计,因此可以直接生成波形文件,现有的基于待测设计生成波形文件的实现方案全部落入本发明保护范围之内。
所述第五监视器用于采集输入所述待测设计的有效第五测试激励,发送给第五转换器;所述第五转换器用于将第五测试激励转换为第五输入数据,所述第五输入数据为参考模型可以识别的数据,将所述第五输入数据传输给参考模型运行,生成第一执行结果,所述第五转换器获取所述第一执行结果,所述第五转换器还用于将第五测试激励按照预设的顺序将第五测试激励拼接为输入向量,按照待测设计的时序将所述输入向量发送给所述空壳模块的输入端口;所述第五转换器还用于将所述第一执行结果转换为事务类型数据,并按照预设的顺序将转换后的第一执行结果拼接为输出向量,将所述输出向量发送至所述空壳模块的输出端口。通过上述操作即可将参考模型的输入端口和输出端口的数据对应放置在空壳模块的输入端口和输出端口。所述空壳模块基于接收到的输入向量驱动所述输入端口,基于所述输出向量驱动所述输出端口。所述第二波形生成器用于采集空壳模块对应的第二波形文件,发送给所述显示器。
所述显示器基于第一波形文件、第二波形文件呈现待测设计和参考模型的波形信息,进行验证。通过将参考模型的输入端口和输出端口的数据抓取下来,并放置在于待测设计对应的空壳模块上,即可生成参考模型对应的波形文件,既可对第一阶段的参考模型进行验证,又可通过对比第一波形文件和第二波形文件对应的文件,基于参考模型对待测设计进行验证。
作为一种示例,所述第五转换器还包括输入FIFO和输出FIFO,所述输入FIFO用于存储所述输入向量,所述出处FIFO用于存储所述输出向量;所述第五转换器按照待测设计的时序从所述输入FIFO中读出输入向量,发送给所述空壳模块的输入端口;所述第五转换器按照待测设计的时序从所述输出FIFO读出输出向量,发送给所述空壳模块的输出端口,通过设置输入FIFO和输出FIFO,控制参考模型的输入数据和输出数据按照待测设计的时序传输。
作为一种示例,所述第五输入数据为目标结构体类型,所述目标结构体为所述参考模型能够识别的结构体,按照待测设计的时序通过直接编程接口DPI将所述第五输入数据发送给参考模型,并调用所述参考模型按照待测设计的时序执行所述第五输入数据,再通过直接编程接口DPI从所述参考模型获取第五运行结果,所述第五运行结果为目标结构体类型数据,将所述第五运行结果转换为事务类型数据,作为所述第一执行结果。需要说明的是,本示例中第五转换器的具体实现细节可以直接采用实施例一中的第一转换器的具体实现方式来实现,在此不再赘述。
作为一种示例,所述待测设计包括多个层级设计的组成单元,两个互联的组成单元之间通过至少一个总线接口连接,所述第五测试激励基于对应的总线接口信息自动生成,所述直接编程接口DPI基于对应的总线接口信息和层级信息自动生成。具体实现细节采用实施例一中对应的具体实现方式来实现,在此不再赘述。
作为一种示例,所述第五输入数据为通用数据包类型,具体设置为不定长的向量,按照待测设计的时序通过事务级传输通道TLM发送给参考模型,并调用所述参考模型按照待测设计的时序执行所述第五输入数据,然后通过事务级传输通道TLM从所述参考模型获取第五运行结果,所述第五运行结果为通用数据包类型,将所述第五运行结果转换为事务类型数据,作为所述第一执行结果。需要说明的是,本示例中第五转换器的具体实现细节可以直接采用实施例二中的第二转换器的具体实现方式来实现,在此不再赘述。
作为一种示例,所述待测设计包括多个层级设计的组成单元,两个互联的组成单元之间通过至少一个总线接口连接,所述第五测试激励基于对应的总线接口信息自动生成,所述事务级传输通道TLM基于对应的总线接口信息和层级信息自动生成。待测设计的具体组成,以及IDF和DIY的描述细节已在实施例一中描述,在此不再赘述。所述事务级传输通道TLM遵循TLM协议。
实施例四通过将参考模型的输入端口和输出端口的数据抓取下来,并放置在于待测设计对应的空壳模块上,即可生成参考模型对应的波形文件,既可对第一阶段的参考模型进行验证,又可通过对比第一波形文件和第二波形文件对应的文件,基于参考模型对待测设计进行验证,提高了GPU联合仿真的灵活性、可靠性、高效性和准确性。
实施例五、
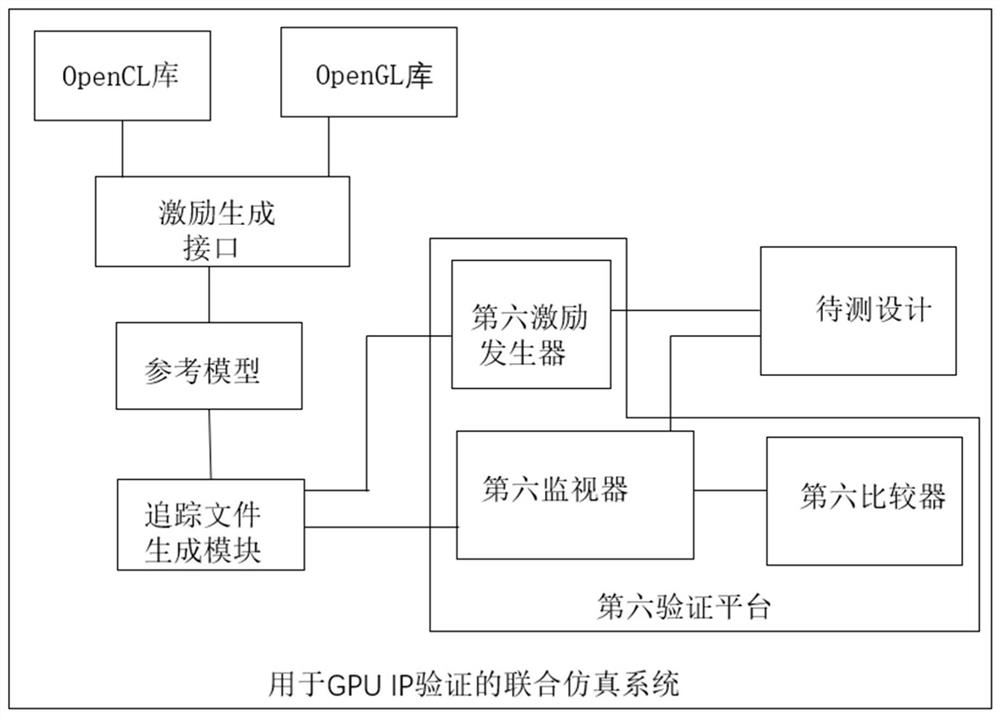
实施例五提供了一种用于GPU IP验证的联合仿真系统,如图5所示,包括待测设计、参考模型、OpenCL库、OpenGL库、激励生成接口、追踪文件生成模块、第六验证平台。其中,所述待测设计为GPU IP,所述OpenCL库、OpenGL库与激励生成接口相连接,所述激励生成接口与所述参考模型相连接,所述追踪文件生成模块与所述参考模型相连接;所述第六验证平台包括第六激励发生器、第六比较器和第六监视器,所述第六激励发生器与所述待测设计和追踪文件生成模块相连接,所述第六监视器与追踪文件生成模块和待测设计相连接,所述第六比较器与第六监视器相连接。
所述激励生成接口用于访问OpenCL库和OpenGL库生成第六测试激励,所述第六测试激励为C++数据结构类型;由于GPU IP验证很大部分对应的是C++语言编程,因为从GPU编程角度,通常基于OpenCL库和OpenGL库来编辑和操作GPU,因此GPU IP类的联合仿真不是于SystemVerilog和UVM编写的测试用例,而是基于OpenCL库和OpenGL库生成的C++测试用例,可以直接输入参考模型,而不能直接输入待测设计中。
所述参考模型用于从所述激励生成接口获取第六测试激励,按照待测设计的时序从所述参考模型的输入端口传输至所述参考模型中执行,并从所述参考模型的输出端口输出第六模型输出结果。
所述追踪文件生成模块用于从所述参考模型的输入端口转存(Dump)第六测试激励,生成输入追踪文件,还用于从所述参考模型的输出端口转存第六模型输出结果,生成输出追踪文件.
所述第六激励发生器用于从所述追踪文件生成模块获取输入追踪文件,解析生成第七测试激励,按照待测设计的时序发送给待测设计,需要说明的是,待测设计相当于基于参考模型的追踪文件进行重播(Replay),可以理解的是,由于第六测试激励是C++类型的,因此在输入待测设计之前需要转换为待测设计可以识别的数据类型,即生成第七测试激励。
所述待测设计用于执行所述第七测试激励,生成第六待测设计输出结果。
所述第六监视器还用于从所述待测设计获取第六待测设计输出结果,从所述追踪文件生成模块中获取输出追踪文件,进行解析,得到对应的第六模型输出结果。
所述第六比较器用于基于所述第六待测设计输出结果和对应的第六模型输出结果对待测设计进行验证。
所述系统可以采用不同的模式执行:
实施方式一、
所述系统包括参考模型单独工作模式和待测设计单独工作模式,所述系统先采用参考模型单独工作模式,执行以下操作:
所述激励生成接口访问OpenCL库和OpenGL库生成测试激励。
所述参考模型从所述激励生成接口获取第六测试激励,按照待测设计的时序从所述参考模型的输入端口传输至所述参考模型中执行,并从所述参考模型的输出端口输出第六模型输出结果。
所述追踪文件生成模块从所述参考模型的输入端口转存第六测试激励,生成输入追踪文件,还用于从所述参考模型的输出端口转存运行结果,生成输出追踪文件。
也即先仅参考模型运行,生成追踪文件,待测设计先不运行,生成输入追踪文件和输出追踪文件之后,所述系统切换为待测设计单独工作模式,执行以下操作。
所述第六激励发生器从所述追踪文件生成模块获取输入追踪文件,解析生成第七测试激励,按照待测设计的时序发送给待测设计。
所述待测设计执行所述第七测试激励,生成第六待测设计输出结果。
所述第六监视器从所述待测设计获取第六待测设计输出结果,发送给第六比较器,从所述追踪文件生成模块中获取输出追踪文件,进行解析,得到对应的第六模型输出结果,发送给第六比较器。
所述第六比较器基于所述第六待测设计输出结果和对应的第六模型输出结果对待测设计进行验证。
实施方式二、
所述系统包括联合仿真模式,所述系统在所述追踪文件生成模块从所述参考模型的输入端口转存第六测试激励,生成输入追踪文件,同时,所述第六激励发生器从所述追踪文件生成模块获取输入追踪文件,解析生成第七测试激励,按照待测设计的时序发送给待测设计。
所述第六监视器从所述待测设计获取第六待测设计输出结果,同时从所述追踪文件生成模块中获取输出追踪文件,进行解析,得到对应的第六模型输出结果。
所述第六比较器基于所述第六待测设计输出结果和对应的第六模型输出结果对待测设计进行验证。
实施方式二较实施方式一的具有更高的实时性。实施方式一较实施方式二更稳定可靠。根据具体的应用需求来选择对应的模式。
作为一种示例,所述待测设计包括多个层级设计的组成单元,两个互联的组成单元之间通过至少一个总线接口连接,所述输入追踪文件和输出追踪文件按照预设的追踪文件结构生成,所述追踪文件结构包括总线接口描述信息和对应的有效总线接口数据记录,其中,
所述总线接口描述信息包括总线接口对应的组成模块标识、总线接口标识、总线接口信号与互联的总线接口的信号映射信息、数据有效标识约束信息,所述总线接口标识基于总线接口对应的层级信息和总线接口实例基于DPI的GPU联合仿真系统生成;
所述有效总线接口数据记录包括总线接口中每一信号对应的信号值以及对应的时钟时钟周期序号和绝对时间。
实施例一中已详细记载待测设计的具体组成、设计互联组装DIY和总线接口重构结构IDF的技术细节,在此不再赘述。总线接口重构结构IDF中包含了详细的总线接口信息,设计互联组装DIY中包括了层级信息,基于此可以自动生成总线接口描述信息,并基于此生成对应的有效总线接口数据记录。
作为一种示例,所述第六验证平台还包括第一事务级模块,与实施例一种的第一事务级模块相同。所述第一事务级模块包括第一转换接口和第二转换接口,所述第一转换接口用于把事务类型数据转换为C++数据结构类型数据,所述第二转换接口用于把C++数据结构类型数据转换为事务类型数据。
作为一种示例,所述第六激励发生器用于从所述追踪文件生成模块获取输入追踪文件,解析得到第六测试激励,调用所述第二转换接口将所述第六测试激励转换为事务类型数据,得到第七测试激励,按照待测设计的时序发送给待测设计。
作为一种示例,所述第六监视器用于从所述追踪文件生成模块中获取输出追踪文件,进行解析,得到对应的第六模型输出结果,调用所述第一转换接口将对应的第六模型输出结果转换为事务类型数据之后,发送给所述第六比较器。
实施例五基于OpenCL库、OpenGL库生成参考模型的对应的测试激励,通过运行参考模型,生成对应的追踪文件,再基于追中文件得到待测设计对应的测试激励,运行待测设计,然后再基于待测设计和参考模型的输出结果对待测设计进行验证,实现了对GPU IP的准确、可靠、高效的联合仿真。
实施例六、
实施例六提供了一种GPU联合仿真系统,包括实施例一、实施例二、实施例三、实施例四、实施例五中的任何一个,或多个的组合,本领域技术人员可以理解的是,任何可以基于实施例一、实施例二、实施例三、实施例四、实施例五中的技术细节合理组合的方式都在本发明保护范围之内。
以上所述,仅是本发明的较佳实施例而已,并非对本发明作任何形式上的限制,虽然本发明已以较佳实施例揭露如上,然而并非用以限定本发明,任何熟悉本专业的技术人员,在不脱离本发明技术方案范围内,当可利用上述揭示的技术内容作出些许更动或修饰为等同变化的等效实施例,但凡是未脱离本发明技术方案的内容,依据本发明的技术实质对以上实施例所作的任何简单修改、等同变化与修饰,均仍属于本发明技术方案的范围内。
- 基于多核心联合仿真被验证设计的仿真验证平台
- 基于DPI的GPU联合仿真系统