一种软件源代码缺陷自动修复方法及系统
文献发布时间:2023-06-19 18:32:25
技术领域
本发明属于计算机程序漏洞修复技术领域,尤其涉及一种软件源代码缺陷自动修复方法及系统。
背景技术
由于漏洞对软件安全构成巨大威胁,软件漏洞保护一直是人们持续关注的安全问题。与源代码漏洞检测相关的工作逐渐成熟,实现了自动、高精度的漏洞检测能力。然而,为了解决漏洞问题,还需要对其进行修复。
传统的漏洞自动修复方法大多基于用户定义的规则模式,对于特定的漏洞类型可以获得更好的性能,但不适合扩展到其他漏洞模式。随着神经网络的发展,提出了对源代码缺陷进行自动修复的方法。神经网络通过学习成对样本(漏洞样本和修复样本)之间的语义相关信息,实现对漏洞样本进行相应修复的推理。
目前,基于seq2seq的漏洞自动修复学习方式比较流行,但其自动修复性能仍不理想,主要原因可能是源代码在语义层次上不同于简单的自然语言文本,seq2seq模型不具备深入理解源代码语义的能力。此外,还出现了利用graph2Seq模型的基于图的程序修复方法,但目前这种方法只能解决简单的程序修复问题,例如单行缺陷代码的修改,且生成的补丁语法问题较为严重,导致补丁质量较差。
发明内容
本发明的第1方面,提供了一种软件源代码缺陷自动修复方法,包括:提取源代码的缺陷相关CPG子图;使用经过训练的缺陷修复模型基于所述CPG子图得到缺陷修复结果;其中,所述缺陷修复模型由一个图编码器、n个序列解码器和一个语法纠正解码器组成,所述n个序列解码器的输入端分别与所述图编码器的输出端连接,所述语法纠正解码器的输入端与所述n个序列解码器的输出端连接;其中,n ≥ 2。
在一个实施例中,所述缺陷修复模型的训练数据包括:1)包含漏洞的源代码片段;2)修复代码;3)修复代码的行数;4)修复代码中包含的语法相关符号序列。
在一个实施例中,训练所述缺陷修复模型时,所述语法纠正解码器的输入包括所述训练数据的语法相关符号序列和所述序列解码器输出的修复代码序列。
在一个实施例中,所述图编码器采用GGNN网络,每个所述序列解码器均采用LSTM网络,所述语法纠正解码器采用LSTM网络。
在一个实施例中,所述提取源代码的缺陷相关CPG子图,包括:获取所述源代码的CPG;提取所述CPG中与缺陷相关的节点和边,以合成所述CPG子图。
在一个实施例中,所述提取源代码的缺陷相关CPG子图,还包括:将合成的所述CPG子图的每个节点中的漏洞特征转换为符号表示;以及将所述符号表示转换为向量表示。
在一个实施例中,将基于源代码的每个词转换得到的向量的值相加作为整个源代码的向量表示输入所述缺陷修复模型。
本发明的第2方面,提供了一种软件源代码缺陷自动修复系统,包括:子图提取模块,用于提取源代码的缺陷相关CPG子图;缺陷修复模块,使用经过训练的缺陷修复模型基于所述CPG子图得到缺陷修复结果;其中,所述缺陷修复模型由一个图编码器、n个序列解码器和一个语法纠正解码器组成,所述n个序列解码器的输入端分别与所述图编码器的输出端连接,所述语法纠正解码器的输入端与所述n个序列解码器的输出端连接;其中,n ≥ 2。
此外,本发明还提供了一种电子设备,包括:存储器,用于存储计算机程序;处理器,与所述存储器数据耦合,用于在执行所述计算机程序时,实现所述的软件源代码缺陷自动修复方法。
此外,本发明还提供了一种计算机可读存储介质,所述计算机可读存储介质上存储有计算机程序,所述计算机程序被处理器执行时,实现所述的软件源代码缺陷自动修复方法。
本发明提出的源代码缺陷自动修复方法通过提取源代码的缺陷相关CPG子图,能够对多行源代码进行修复,具备高效的自动化修复能力,同时通过语法纠正解码器提高修复的准确度,能够保障软件开发阶段的源代码级别的安全性。
附图说明
通过阅读参照以下附图所作的对非限制性实施例所作的详细描述,本发明的其他特征、目的和优点将会变得更明显:
图1为根据本发明实施例的软件源代码缺陷自动修复方法流程示意图;
图2为根据本发明实施例的缺陷相关CPG子图提取步骤工作流程示意图;
图3为根据本发明实施例的缺陷修复模型组成示意图。
具体实施方式
下面结合附图和实施例对本发明作进一步的详细说明。可以理解的是,此处所描述的具体实施例仅仅用于解释相关发明,而非对该发明的限定。另外还需要说明的是,为了便于描述,附图中仅示出了与有关发明相关的部分。在不冲突的情况下,本发明中的实施例及实施例中的特征可以相互组合。
图1为根据本发明实施例的软件源代码缺陷自动修复方法流程示意图。如图1所示,该方法包括:
步骤100、提取源代码的缺陷相关CPG子图;
CPG 将AST(abstract syntax trees)、CFG(control flow graphs)、PDG(programdependence graphs) 整合到一种图中,相对于每个单独子图,采用CPG包含了源代码的数据流,控制流等语义信息,能实现丰富的源代码语义表征,其节点的代码信息密集度更高。此外,相对于AST,CPG删除了很多语法紧相关的与代码语义逻辑无关的节点,从而更有助于缺陷分析。
在一个实施例中,提取源代码的缺陷相关CPG子图,具体包括:
步骤101、缺陷相关CPG子图提取步骤;
图2为根据本发明实施例的缺陷相关CPG子图提取步骤工作流程示意图。如图2所示,包括如下子步骤:
步骤1011、获取所述源代码的CPG;
示例性地,可以基于Joern工具获得源代码的CPG,作为源代码的初始图表示,Joern工具对那些不可编译的代码片段也可以进行代码表征图提取。其中,节点由代码片段表示,边类型有AST、CFG、PDG三种。
步骤1012、筛选CPG中与缺陷相关的节点;
在一个实施例中,可以根据已知缺陷对CPG进行节点筛选,如果节点对应的代码语句符合漏洞特征,则确定为候选漏洞节点,进而得到只包含缺陷的节点。
步骤1013、基于节点筛选结果合成CPG子图。
根据候选漏洞节点从CPG中截取与候选漏洞节点存在数据依赖或者控制依赖关系的节点和相应的边构成漏洞CPG子图(也即缺陷相关CPG子图)。通过去除原始CPG中的与缺陷信息无关的冗余信息,提升CPG对缺陷的表征准确度。
步骤102、将合成的CPG子图的每个节点中的漏洞特征转换为符号表示;
依据正则表达式提取CPG子图中节点中的变量、函数、字符串等漏洞特征,然后将CPG子图的每个节点中的漏洞特征转换为一种短而固定的符号表示。其中,相同的特征映射到相同的符号表示形式。
示例性地,符号表示包含变量符号化,函数符号化以及字符串符号化等符号化类型。
步骤103、将符号表示转换为向量表示。
该步骤将符号表示结果转换为固定低维度的向量表示,例如,使用word2vec实现向量表示,进而作为缺陷修复模型的输入。
在一个实施例中,将基于源代码的每个词转换得到的向量的值相加作为整个源代码的向量表示输入所述缺陷修复模型。由于CPG中节点包含的源代码片段大多长度较短,因此本发明没有采用“先预设长度,然后根据输入的长短进行删除和增补操作”的方式,而是将源代码片段的每一个词都先转换成一个向量,而后将所有向量的值进行相加来得到整个源代码片段的向量表示,作为缺陷修复模型的输入。这种方式可以最大限度地保留源代码片段的整体语义信息。
步骤200、使用经过训练的缺陷修复模型基于所述CPG子图得到缺陷修复结果;其中,所述缺陷修复模型包括图编码器和分别与所述图编码器输出端连接的多个序列解码器。
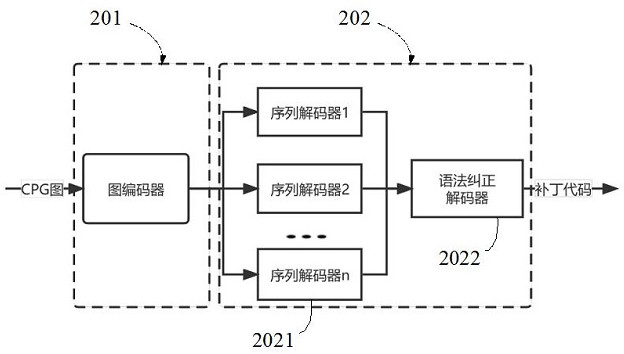
图3为根据本发明实施例的缺陷修复模型组成示意图。如图3所示,缺陷修复模型是基于编码器-解码器架构的graph2seq模型,包括图编码器201和序列解码器202,其中,序列解码器202包括分别与图编码器201输出端连接的多个序列解码器2021以及与各序列解码器2021输出端连接的语法纠正解码器2022。
在一个实施例中,缺陷修复模型的输入层神经元个数与输入向量的维度相同。图编码器201采用GGNN网络;多个序列解码器2021均采用LSTM网络,语法纠正解码器2022采用LSTM网络。其中,上述LSTM网络可以采用基于注意力的LSTM网络。
图编码器201基于GGNN模型,使用GRU单元处理时序节点间依赖关系,可以获得对输入的缺陷相关CPG子图的全局信息有效特征提取,从而实现更有效的缺陷模式表征。此外,基于图编码器可以实现对多行的缺陷问题的有效表征。序列解码器202包含由多个序列解码器2021组成的补丁生成解码器和语法纠正解码器2022。补丁生成解码器用于对图编码器201的输出进行序列解码,获得初始的补丁代码序列。而后,初始的补丁代码序列经过语法纠正解码器202对补丁代码语法进行微调,输出有效的补丁代码序列。由于补丁生成解码器是多头形式的,因此可以生成多行补丁代码。
在一个实施例中,缺陷修复模型共有四层结构:
第1层为输入层,神经元个数与输入向量的维度相同,每个神经元依次对应向量的一个维度的输入并直接传给第2层神经元;
第2层编码器层,基于GGNN以门控循环单元(GRU)来更新GNN变换后的神经元隐含状态;
第3层解码器层,基于LSTM层,用于从GGNN输出的图中解码出初始补丁序列,并传输给另一个LSTM层进行语法微调;
第4层为输出层,可以输出缺陷修复结果,即补丁代码序列。
以下对上述缺陷修复模型的训练过程进行说明。
在对上述缺陷修复模型进行训练时,训练数据集包括:1)包含漏洞的源代码片段;2)作为样本标签的修复代码;3)修复代码的行数;4)语法样本序列,即修复代码中包含的语法相关符号序列,该语法相关符号序列表示对样本标签序列(修复代码)进行代码遮盖,只留下其中的标点符号和数学符号,使得语法纠正解码器只能获取语法相关的内容进行学习。
训练时,对训练数据集中的包含漏洞的源代码片段采用前述步骤100提取源代码的缺陷相关CPG子图,将向量表示输入缺陷修复模型。缺陷修复模型的图编码器部分通过聚合有向图和无向图中的相邻信息,学习节点嵌入,并根据学习到的节点嵌入构建图嵌入。序列解码器部分使用图嵌入作为初始隐藏状态,输出目标预测结果。
本发明中,序列解码器部分包含n个序列解码器和一个语法纠正解码器,n对应训练数据包含的最大漏洞行数。当将漏洞相关的CPG子图输入图编码部分,图编码部分根据训练数据中的行数标签学习,预测需要修复的代码行数,并激活对应个数的序列解码器。其中,激活的方式为:预测样本包含m行需要修复的代码,则对应激活个序列解码器,其余的n-m代码行为空。
激活的序列解码器生成的修复代码序列输入到语法纠正解码器,生成最终的多个漏洞补丁序列。其中,语法纠正解码器的输入包括序列解码器输出的代码行(修复代码序列)和用于语法纠正的语法样本序列。
根据模型输出结果对模型参数不断优化,直到损坏函数值达到预定要求,完成模型训练。
本发明的第2方面,提供了一种软件源代码缺陷自动修复系统,包括:
子图提取模块,用于提取源代码的缺陷相关CPG子图;
缺陷修复模块,使用经过训练的缺陷修复模型基于所述CPG子图得到缺陷修复结果;其中,所述缺陷修复模型由一个图编码器、n个序列解码器和一个语法纠正解码器组成,所述n个序列解码器的输入端分别与所述图编码器的输出端连接,所述语法纠正解码器的输入端与所述n个序列解码器的输出端连接;其中,n ≥ 2。
本发明提出的源代码缺陷自动修复方法通过提取源代码的缺陷相关CPG子图,能够对多行源代码进行修复,具备高效的自动化修复能力,同时通过语法纠正解码器提高修复的准确度,能够保障软件开发阶段的源代码级别的安全性。
此外,本发明还提供了一种电子设备,包括:存储器,用于存储计算机程序;处理器,与所述存储器数据耦合,用于在执行所述计算机程序时,实现所述的软件源代码缺陷自动修复方法。
此外,本发明还提供了一种计算机可读存储介质,所述计算机可读存储介质上存储有计算机程序,所述计算机程序被处理器执行时,实现所述的软件源代码缺陷自动修复方法。
虽然通过以上实施例对本发明进行了较为详细的说明,但是本发明不仅仅限于以上实施例,在不脱离本发明发明构思的情况下,可以对本本发明实施例的技术方案进行修改或等同替换都不应脱离本发明实施例的技术方案的精神和范围。
- 一种面向缺陷补丁代码的软件缺陷原因自动分析方法
- 一种基于聚类分析的软件缺陷修复模板提取方法
- 一种基于开源代码库的软件缺陷自动检测方法
- 一种基于开源代码库的软件缺陷自动检测方法