一种基于深度学习的合成雷达图像去噪方法
文献发布时间:2023-06-19 18:34:06
技术领域
本发明涉及图像去噪方法,尤其涉及一种基于深度学习的合成雷达图像去噪方法。
背景技术
合成孔径雷达(Synthetic Aperture Rada,SAR)是一种捕捉微波的传感器,其原理就是通过波形的反射来进行图像建立,从而解决了传统光学的遥感雷达在采集图像时受到天气、空气杂质等环境影响。合成孔径雷达应用最多的就是其变化检测(Change Detect,CD),变化检测就是针对某一目标进行动态获取图像信息,其包括图像预处理、生成差异图和分析计算差异图三个步骤,其应用在自然灾害估计、资源的管理分配以及测量土地的地貌特征等等。然而,在变换检测过程中,SAR图像中固有的斑点噪声会降低其变化检测的性能。因此,图像去噪方法已成为变化检测中预处理的基本方法。如何从有噪声的SAR图像中恢复一幅干净的图像是当前迫切需要解决的问题。图像去噪算法不仅仅应用在合成孔径雷达图像中,在工业、医学、生活消费、工程等领域中都有涉及,应用颇广。
图像去噪是加强图像处理的一个基本方面。目前合成孔径雷达图像中去噪主要分为两个方向,一个图像滤波处理,另外一个是非相干多视处理。图像滤波处理主要是通过滤波器进行噪声滤除,例如中值滤波、均值滤波、BM3D、CSF、WNNM、TNRD以及小波去噪,其本质上就是一个最大后验(MAP)的优化问题,尽管这些算法在去除合成噪声方面取得不错的性能,但是由于他们的假设噪声与自然界中的实际噪声存在一定偏差,在实际的环境中,去噪效果欠佳。另外一种就是非相干多视去噪,其原理就是将图像分解为多个多普勒带宽,每一个多普勒带宽分别使用不同的合成孔径,最后再将分解的图像进行叠加,该方法有效去除了斑点噪声,但是分解图像会造成分辨率的下降,分辨率的下降将会对变化检测(CD)中其他的任务造成很大影响。
发明内容
发明目的:本发明的目的是提供一种实现在控制降噪与细节权衡上做到平衡的基于深度学习的合成雷达图像去噪方法。
技术方案:本发明的合成雷达图像去噪方法,包括步骤如下:
S1,对初始噪声图像进行预处理;
S2,将预处理后的图像输入到构建的MALNet模型中,对图像特征进行处理;
S3,将处理后的图像特征通过Sigmod激活函数,转化为0-1的浮点数信息后,与初始噪声图像相减,完成图像重建;
S4,将重建的图像与初始未加噪的图像对比,通过Loss函数进行计算损失值,并通过反向传播,来对MALNet模型的权重参数进行Adam优化,最后保存训练好的MALNet模型参数。
进一步,步骤S2中,所述MALNet模型包括非规则卷积核、注意力模块和密集级联块,非规则卷积核、注意力模块和密集级联块依次连接,对图像特征的处理步骤如下:
S21,对带噪声的图像依次通过非对称卷积核和注意力模块来获取到图像基础特征;
S22,图像基础特征经过密集级联块自主学习图像的残差信息,并反馈到最后一层的输出层。
进一步,步骤S2中,所述非规则卷积核包括conv3*3、conv3*1、conv1*3和conv5*5,带噪声的图像分别经过conv3*3、conv3*1、conv1*3和conv5*5进行图像的初步特征提取,最后将图像的初步特征进行融合拼接,表达为:
F(x)=Cat[ReLU(conv(5*5))+ReLU(conv(3*1))+ReLU(conv(1*3))+ReLU(conv(3*3))]
式中,每一个卷积核后都经过ReLU激活函数,将图像数值滤波至[0,∞]的范围。
进一步,步骤S2中,所述密集级联块包括多级联块层,每极联块层包括依次连接的Conv3x3、ReLU和平均池化层,带噪声的图像依次通过每个阶段的联块层进行特征增强,并且将每一阶段的输出作为后一阶段的输入;
在网络前向传播时,每一卷积模块的输出作为下一卷积模块和下下卷积模块的输入,再通过最后的广义平均池化来获取到图像的全局感受野。
进一步,步骤S4中,采用给定的均方误差来训练MALNet模型,其Loss函数表达为:
MALNet[y(a,b)]=Rim(a,b)=y(a,b)-n(σ,δ)
其中,N为所有样本数目,y(a,b)表示输入噪声图像,n(σ,δ)表示方差为δ、均值为σ的噪声。
本发明与现有技术相比,其显著效果如下:
本发明针对合成孔径雷达SAR噪声图像,采用卷积神经网络模型MALNet,该模型运用端到端架构,不需要单独的子网或手动干预,相比于其他去噪算法而言,卷积神经网络模型MALNet不仅能够产生比较好的结果,而且具有很好鲁棒性,网络在控制降噪与细节权衡上做到了良好的平衡;图像在不同噪声水平上的去噪结果进一步表明,卷积神经网络模型MALNet能提供感知上令人满意的去噪结果。
附图说明
图1为本发明的非对称卷积核图;
图2为本发明的注意力模块结构图;
图3为密集级联块示意图;
图4为本发明的MALNet模型的结构图;
图5(a)为无噪声图像效果图;
图5(b)为噪声图像效果图;
图5(c)为WNNM的去噪效果图;
图5(d)为SAR-BM3D的去噪效果图;
图5(e)为SAR-CNN的去噪效果图;
图5(f)为本发明所提出的MALNet去噪效果图。
具体实施方式
下面结合说明书附图和具体实施方式对本发明做进一步详细描述。
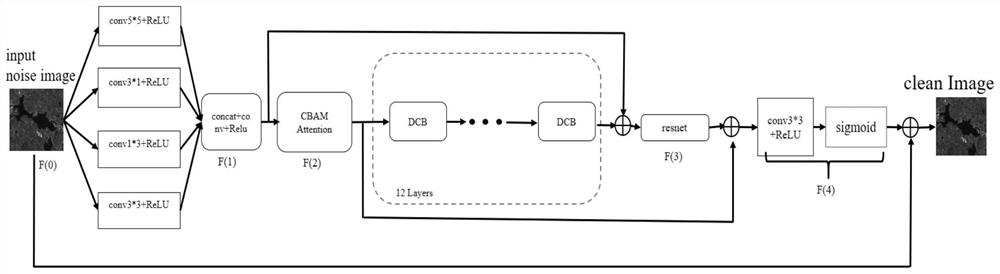
针对SAR图像去噪问题,本发明提出了一种基于多尺度注意力的密集级联卷积神经网络(Multi-size Head Attention Layers,MALNet)去噪算法,该网络主要是将多尺度非规则卷积核和注意力的思想应用其中,多尺度非规则卷积核相较于单一的卷积核有着很好的图像感受野,即它能够从不同的尺度来进行图像信息的收集,以便提取到更为精详的图像细节特征。随后,网络中对不同尺度卷积核进行维度拼接,对拼接后的特征图引入注意力机制进行特征的注意力划分,使得整个模型对图像主要特征有着良好的增强能力。网络中间采用密集级联层(Dense Cascade Block,DCB)来对特征进一步的强化,输出时使用sigmoid作为激活函数,避免模型的梯度出现饱和与消失。最后通过网络差减来实现图像的恢复与重建,实现去噪功能。
如图4所示,为本发明的去噪网络MALNet,MALNet主要包括由多尺度注意力机制模块、密集级联块DCB(Dense Cascade Block)。本发明网络是端对端的结构,去噪机制就是,首先将带噪声的图像通过开始的非对称卷积核和注意力模块(CBAM Convolutional BlockAttention Module)来获取到图像的基础特征,其次经过密集级联块(DCB)来自主学习图像的残差信息,最后反馈到最后一层的输出特征,去噪后重建图像。
以下是对每一个模块的介绍:
非对称卷积:目前大多数神经网络中使用的是规则形卷积结构,例如3*3、4*4、5*5。其规则形的卷积核结构在特征提取时虽然表现出不错的效果,但是在一些图像边缘信息和图像模糊信息的提取方面存在不足。非对称卷积结构是Chunwei Tian在2021年首次提出的网络结构,该网络对恢复有噪声的低分辨图像上时非常有效,非对称卷积通相较于现有的正方形卷积,可以进行模型压缩和加速,先前的工作表明,可以将标准的d×d卷积分解为1×d和d×1卷积,以减少参数量。其理论相当简单,如果二维卷积核的秩为1,则运算可等价地转换为一系列一维卷积。然而,由于深度网络中下学习到的核具有分布特征值,其内部秩比实际中的高,因此直接将变换应用于卷积核会导致显著的信息损失。另一方面,非对称卷积也被广泛的用来做网络结构设计,例如Inception-v3中,7*7卷积被1*7卷积和7*1卷积代替。语义分割ENet网络也采用这种方法来设计高效的语义分割网络,虽然精度略有下降,但降低了33%的参数量。因此,非对称卷积在速率和准确度方面有着比方形卷积更好的优势。本发明采用两个非对称卷积模块,分别是conv3*3、conv3*1、conv1*3、conv5*5,如图1。这四个卷积核来进行图像的初步特征提取,最后将它们进行融合拼接(Concatenate,Cat),其网络可以表达为:
F(x)=Cat[ReLU(conv(5*5))+ReLU(conv(3*1))+ReLU(conv(1*3))+ReLU(conv(3*3))] (1)
式中,每一个卷积核后都需经过ReLU激活函数,将图像数值滤波至[0,∞]的范围,以防止图像在反向传播时产生梯度爆炸和消失。
注意力机制:注意力机制,本质上就是通过网络自主学习出一组权重系数,并以“动态加权”的方式来强调感兴趣的区域,同时抑制不相关背景区域的机制。目前主流使用的注意力机制分别三种:通道注意力、空间注意力和自注意力。通道注意力指的是构建出当前模型的不同通道的权重系数,通过学习来捕获最佳的模型通道,其余通道的权重系统自主削减,从而达到强化重要的特征以及抑制非重要的特征。通道注意力的代表主要是SEnet。空间注意力指提升关键区域的特征表达,本质上是将原始图片中的空间信息通过空间转换模块,变换到另一个空间中并保留关键信息,为每个位置生成权重掩膜(mask)并加权输出,从而增强感兴趣的特定目标区域同时弱化不相关的背景区域。本发明引入的是当前比较主流的注意力机制,即CBAM,其结构如图2,其集权了空间与通道双重注意力机制,其效果更佳。
密集级联块:密集级联网络是一个自动训练和自动添加隐含单元的网络,其网络具有学习速率高、自定义网络神经元与深度、反向传播有效化等优点。受到Resnet启发,本发明设计了一种密集级联层的网络结构,如图3所示,该结构通过一系列的卷积模块,在网络前向传播时,每一卷积模块的输出作为下一卷积模块和下下卷积模块的输入,从而来构成密集级联层,再通过最后的广义平均池化来获取到图像的全局感受野,使得网络更好的学习到图像的整体信息。
本发明的去噪网络MALNet如图4所示,MALNet主要是由多尺度非规则卷积核、注意力模块、级联块DCB(Dense Cascade Block)组成。本发明网络是端对端的结构设计,即输入为噪声图,输出为清洁图。本发明的去噪机制如下,首先将带噪声的图像通过开始的非对称卷积核和注意力模块来获取到图像的基础特征,其次经过级联块(DCB)自主学习图像的残差信息,最后反馈到最后一层的输出特征,去噪后重建图像。
根据式(2)对图像进行加噪:
y(a,b)=n(σ,δ)×x(a,b) (2)
其中,y(a,b)表示输入噪声图像,x(a,b)表示未加噪的图像;n(σ,δ)表示方差为δ、均值为σ的噪声。
输入噪声图像经过网络MALNet后,输出残差图像(Residual Image,Rim),表达为:
MALNet[y(a,b)]=Rim(a,b)=y(a,b)-n(σ,δ) (3)
随后,使用给定的均方误差(MSE)来训练去噪网络,其Loss(损失)函数表达为:
(4)式中,w和b是网络中学习的权重(Weights,w)与偏置(Bias,b),N为所有样本数目,则是网络中所有学习到的参数集合。
本发明使用了制作好的400张加上噪声的图像的训练集,训练时首先选定一个个噪声参数为σ,然后,分别在图像的同一位置将初始去噪结果和原图裁剪成相同的256*256大小的图像块,作为网络的输入来训练所提出的MALNet网络,每一张图片切割成40x 40的窗口化来进行训练,其中使用的数据增强方式为随机翻转、平移、缩放、旋转、镜像,训练的epoch大小设置为150,BatchNorm为归一化设置,其中momentum设置为0.95,batchsize大小设置为64,使用Adam优化器来优化MALNet,根据epoch=30、60、90来动态调整学习率,初始设置为0.0001,其它均为默认设置。通过反复调整参数,如epoch、学习率、batchsize以及后面的DCB循环次数,最终得到的模型为训练时在验证集上取得的性能最好的模型。测试时,网络能适应任意大小的噪声图像,本发明采用Python来对图像进行高斯噪声加性处理,使用Pytorch来实现模型算法。详细具体步骤如下:
a、首先是对数据预处理,先将输入像素大小为256*256的图像转化为灰度图像(灰度值为0-255),并且将每一张图像分割成为像素大小为40x 40的窗格图像。其次,逐一对每一个窗格图像进行加噪,噪声水平为均值σ,方差为0的高斯噪声,并且对每一个窗格图像进行随机的翻转、平移、旋转、镜像、缩放,来达到数据增强的作用。最后,将所有窗格恢复至像素大小为256*256的待处理图像。
b、将图像送入设计的MALNet模型中,首先将图像通过四个并行的卷积核(Conv5*5、Conv3*1、Conv1*3、Conv3*3)对图像细节信息进行卷积提取,再通过ReLU激活函数对图像数值过滤至非负的范围内。其次分别通过CBAM注意力机制(Attention),通过网络的自主学习出一组权重系数,并以“动态加权”的方式来强调所感兴趣的区域同时抑制不相关背景区域的机制。如图4,最后将四个并行图像特征进行通道维度的叠加(Concat),四张残差图像进行叠加融合。
c、再将图像特征通过六层DCB模块进行信息增强,其中DCB模块工作原理:首先通过第一阶段的三个计算层,其计算层分别是:Conv3x3、ReLU、平均池化(Average Pool),再经过第二、第三阶段的特征增强,并且将每一阶段的输出作为后一阶段的输入值和,完成密集级联网络的构造。最后通过一个Sigmod激活函数,将图像数值转换至0-1之间的浮点数完成整个DCB模块的构建。
d、图像经过步骤c后得到的数值矩阵,经过十二层的DCB特征迭代增强之后,经过Resnet后,和前部网络残差连接相加。
e、再次通过Sigmod激活函数,转化为0-1的浮点数信息后与初始噪声图像相减,完成干净图像的重建。
f、将MALNet重建的图像与初始未加噪的图像对比,通过Loss函数进行计算损失值,并通过反向传播来对MALNet模型的权重参数进行Adam优化。
g、保存训练好的参数模型,通过test网络完成图像的输入输出操作,即可端对端的进行图像去噪处理。
至此,循环往复步骤a-g,MALNet模型完成所有图像去噪任务。
本发明进行了定性和定量实验,以评估和演示所提出的MALNet模型在去噪方面的性能。将WNNM、SAR-BM3D和SAR-CNN三种算法与我们提出的方法进行了比较。肉眼观察去噪后图像的清晰状况和完整的迹象。为了公平的比较,使用了三种算法文献中作者提供的默认设置去对比,并使用峰值信噪比(Peak Signal to Noise Ratio,PSNR),结构相似指数(Structural Similarity Index Measure,SSIM)值作为客观评价指标,分别计算PSNR、SSIM、作为误差度量,对比其他去噪方法以测试该模型的去噪效果。假设原始干净的图像X的大小为N×M,N为图像长、M为图像高,i为图像横坐标、j图像为纵坐标,Y为去噪图像。PSNR表示为:
其中f max表示输入图像的最大强度,对于一些8位灰度图像,有256个可能的灰度值,因此f max=256。PSNR用于衡量模型的去噪效果,此外还可以使用其他的指标来评价原图与去噪图像之间的差别。
SSIM是一种质量评估,用来衡量两幅图像之间的相似性。假设X和Y是计算SSIM的两个非负图像信号,表达为:
其中,μ
本发明对比了三个去噪算法,选取了飞机作为验证图像,如图5(a)-(f)飞机图像去噪效果图,其中展示了当前噪声等级为σ=30时不同算法的去噪结果的视觉效果对比,可以很明显的观察到WNNM的去噪效果图有很多瑕疵没有去除干净,并且纹理丢失相当严重,整张图像的噪声去除的不干净,视觉效果模糊。SAR-BM3D则是保留了一些细节,但是飞机机身很模糊,机尾部分已经被抹去大部分边缘信息,海岸图像中的海浪边缘信息被抹去的较严重。SAR-CNN的去噪效果图中的飞机跑道边缘信息没有得到很好的保留,而且旁边的摆放物体比较模糊,飞机机翼虽然恢复出来了,然而最下方的飞机整体仍然与参考图像相差甚远,并且所恢复出来的小物件是模糊的,在另外种场景对比图中,画面呈现出噪点较多的情况,并且一些纹理线条褶皱的较严重,而且画面撕裂感很强,其去噪效果一般。
在表1的去噪评价指标中,分别表示不同方法在不同图像上的PSNR和SSIM结果,表1中的行分别为噪声参数为σ=20、30、40、50时不同算法所产生的PSNR和SSIM数值,列分别为同一方法在不同噪声水平下的PSNR和SSIM数值,所包含的方法有:去噪参数为σ时的SAR-BM3D模型,去噪参数为σ时的SAR-CNN模型,去噪参数为σ的WNNM模型和本发明的MALNet。
表1 去噪评价指标表
从表1中,可以计算出所提出的MALNet的平均PSNR值比SAR-BM3D高出约9.25dB,比SAR-CNN高出约0.75dB,比WNNM高出约14.45dB,其余本发明模型在每个噪声水平上得到PSNR值均比所对比其余三者值高,尤其是在噪声参数为20时,本发明的方法比所对比的SAR-CNN算法最大高出2.56dB。在结构相似性方面可以看出,MALNet的结构相似度大部分都是所对比的方法中最高值,只有在噪声参数为40时,略低于SAR-CNN,并且所得到的平均结构相似度也是最高的。因此,综合PSNR和SSIM两个客观评价指标,本发明所提出的网络在去噪的性能上是优于所对比的方法的。
- 一种基于keystone变换的合成孔径雷达逆投影成像方法
- 一种基于多视联合的合成孔径雷达图像去噪方法和装置
- 一种基于卷积神经网络的合成孔径雷达图像去噪方法