一种基于交叉口全息数据的单点交通信号控制方法
文献发布时间:2023-06-19 18:34:06
技术领域
本发明涉及交通控制技术领域,具体涉及一种基于交叉口全息数据的单点交通信号控制方法。
背景技术
目前国内使用广泛的感应信号控制系统主要有英国SCOOT(Split Cycle OffsetOptimization Technique)系统以及澳大利亚SCATS(Sydney Coordinated Area TrafficSystem)。随着城市化进程的不断加快以及机动车数量的指数级增加,传统感应交通信号控制方式难以应对实时变化巨大的交通流并进行有效管理,传统的感应控制原理为:基于车头时距、占有率、排队长度、拥挤程度进行绿灯时长调整。
缺点主要体现在以下几个方面:
1、传统感应交通信号控制系统的检测数据无法全面有效表征交叉口交通需求、线圈检测误差大可靠性低、难以有效发挥算法以及控制方法的效用等。
2、目前应用深度强化学习交通控制方法普遍协同优化不足,单智能体进行交通信号控制仅能系统最优,组合优化问题离散决策空间过于复杂;
3、单智能体状态空间维数过高,计算时间长,无法实际落地使用。
发明内容
本发明的目的在于提供一种基于交叉口全息数据的单点交通信号控制方法,利用交叉口车辆全息检测手段,实时获取车辆位置、速度信息,更有效以及更精确地控制交通信号。
为实现上述目的,本发明提供了一种基于交叉口全息数据的单点交通信号控制方法,包括下列步骤:
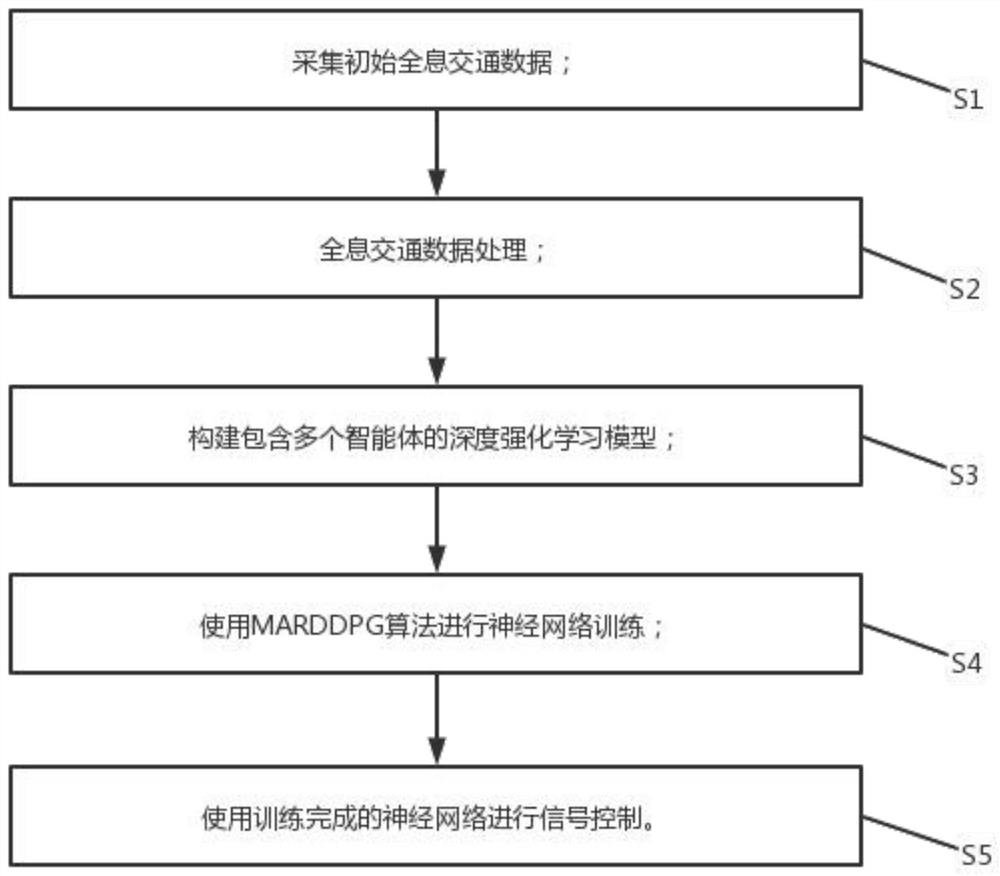
采集初始全息交通数据;
全息交通数据处理;
构建包含多个智能体的深度强化学习模型;
使用MARDDPG算法进行神经网络训练;
使用训练完成的神经网络进行信号控制。
其中,所述全息交通数据包括目标车辆运行数据、车道级交通数据、交叉口设计现状和交通信号控制现状,其中目标车辆运行数据包括目标车辆含时间戳ID、车辆类型、车辆纵向速度、车辆所在车道号码和车辆距停车线距离,车道级交通数据包括目标车道排队长度、车辆总等待时间、平均延误和通过停止线车辆数,交叉口设计现状包括交叉口各进口道车道数量和车道功能分布,交通信号控制现状包括交叉口现状相序和各相位时长分布。
其中,全息交通数据处理的过程,包括下列步骤:
删除冗杂数据;
删除轨迹异常数据;
采用线性函数插值法进行噪声轨迹数据补全。
其中,构建包含多个智能体的深度强化学习模型的过程中,交通信号控制智能体Agent选用MARDDPG算法进行深度强化学习,并分别进行状态空间S、动作空间A和奖励值R定义。
其中,使用MARDDPG算法进行神经网络训练的过程,包括下列步骤:
步骤1:参与者网络与评论家网络初始化参数化动作选择策略
步骤2:每隔5秒钟,单个智能体通过动作选择策略
步骤3:将已进行过的{s
步骤4:智能体选择M个历史训练步数据后,利用M中某个minibatch(以m表示),使评论家网络通过步骤1构建的值函数
用于更新
用于更新θ
为了最大化未来预期奖励来更新参与者网络,定义J(θ
步骤5:智能体采用“软更新”的方式来更新目标网络的参数
θ'
重复步骤2至步骤5,当
其中,使用训练完成的神经网络进行信号控制的过程,具体为根据智能体构建要求采集实时全息数据,输入信号控制智能体,通过智能体输出的各相位信号时长改变动作,生成相位时间矩阵G':
G'=[G1' G2' G3' … Gn']。
本发明提供了一种基于交叉口全息数据的单点交通信号控制方法,构建包含多个智能体的深度强化学习模型,再使用MARDDPG算法进行神经网络训练,最后使用训练完成的神经网络进行信号控制,区别于传统的交通检测技术,本发明充分利用交叉口全息数据能够将交通需求完全表达出来,同时采用MARDDPG算法的深度强化学习,每个智能体单独控制每个相位,单个智能体之间进行协同优化,更容易达到交叉口控制效率最优,进一步的,由于智能体单独控制每个相位,每个智能体的状态空间较小,结果收敛较快,能有效以及更精确地控制交通信号。
附图说明
为了更清楚地说明本发明实施例或现有技术中的技术方案,下面将对实施例或现有技术描述中所需要使用的附图作简单地介绍,显而易见地,下面描述中的附图仅仅是本发明的一些实施例,对于本领域普通技术人员来讲,在不付出创造性劳动的前提下,还可以根据这些附图获得其他的附图。
图1是本发明的一种基于交叉口全息数据的单点交通信号控制方法的流程示意图。
图2是本发明的深度强化学习模型的卷积网络结构示意图。
图3是本发明的交叉口车辆位置与位置矩阵以及速度矩阵的对比示意图。
具体实施方式
下面详细描述本发明的实施例,所述实施例的示例在附图中示出,其中自始至终相同或类似的标号表示相同或类似的元件或具有相同或类似功能的元件。下面通过参考附图描述的实施例是示例性的,旨在用于解释本发明,而不能理解为对本发明的限制。
请参阅图1,本发明提供了一种基于深度学习的农作物病虫害移动端识别方法,包括下列步骤:
S1:采集初始全息交通数据;
S2:全息交通数据处理;
S3:构建包含多个智能体的深度强化学习模型;
S4:使用MARDDPG算法进行神经网络训练;
S5:使用训练完成的神经网络进行信号控制。
具体的,在步骤S1中,全息交通数据包括目标车辆运行数据、车道级交通数据、交叉口设计现状、交通信号控制现状。
其中,目标车辆运行数据包括:目标车辆识别号C
车道级交通数据包括:目标车道排队长度Q
交叉口设计现状包括:交叉口各进口道车道数量、车道功能分布。
交通信号控制现状包括:交叉口现状相序、各相位时长分布。
在步骤S2中,全息交通数据处理的目的在于提高数据准确性,使交通控制效率更高,具体包括以下步骤:
步骤2.1、删除冗杂数据,受传输干扰以及设备识别率的影响,可能出现识别异常:正常输出数据应为字符串,若出现数据位数不符,或数据乱码,需删除相关目标车辆所有交通数据。
步骤2.2、删除轨迹异常数据,设备采集数据若出现车道转向不对应情况,即为轨迹异常,需删除相关目标车辆所有交通数据。
步骤2.3、噪声轨迹数据补全,由于设备定时间步长采集交通数据,可采用线性函数插值法,首先将轨迹偏移量大于阈值的目标车辆连续位置点形成轨迹,将形成的轨迹拟合为线性函数,再将此偏移轨迹点插入拟合曲线中前后轨迹点中值处。
步骤S3中,构建包含多个智能体的深度强化学习模型,具体包括下列步骤:
假设交叉口现状为经典n相位信号控制交叉口,各相位可通行车道数为m,在不调整相序的情况下,每相位部署1个信号控制智能体调整自身相位绿灯时长来控制交通流,并且能够在每次调整后,从环境中获得状态与反馈;所有信号控制智能体间可协同优化,达到交叉口总体交通拥堵的减小。
步骤3.1、交通信号控制智能体Agent使用了多智能体深度强化学习方法,根据全息交通数据高精度、交通流具有时间连续性的特点,选用多智能体递归深度确定性策略梯度算法(MARDDPG),此算法是一种加入了LSTM(长短期记忆)的MADDPG算法。
参与者(Actor)网络的输入为智能体Sti=(P,V,L),其中P,V是同维度矩阵,维数为45×m,将P矩阵与V矩阵组合为双通道图像,输入至堆叠子网络。子网络包含两个卷积层,第一卷积层包含32个滤波器,每个大小为4×4,应用跨距(2,2);第二卷积层包含64个滤波器,每个大小为2×2,应用跨距(2,2)。使用完全连接层将相位矩阵L编码为8维向量。然后,将所有网络的输出连接成一个向量,所有智能体合成所得的向量被分别发送到含有64个隐藏单元的LSTM,通过softmax激活函数输出动作预测值Q(S,A),具体卷积网络结构如图2所示,
评论者(Critic)网络结构与参与者网络相似,除输入状态空间以外,另需输入交叉口所有智能体的全局动作集合A。
重放缓冲区D用于在每个训练步骤中,随机采样样本,同时更新参与者网络与评论者网络。
步骤3.2、状态空间S定义,读取采集所得的目标车辆运行数据,每个智能体使用自身分配相位的相关可通行车道中的车辆位置、速度来定义状态。
如图3所示,为表示车辆位置,将所放行车道等距6米划分为离散单元,每个离散单元为一个元胞,如果对应元胞内有车,对应位置值为1,反之对应位置值为0;不同方向均以右侧为停止线横向放置矩阵Pi,智能体的位置矩阵P由各方向的矩阵Pi组成:
为表示车辆速度,读取目标车辆速度,按照P矩阵的排列方式,形成速度矩阵Vi,智能体的速度矩阵V由各方向的矩阵Vi组成:
状态空间中应对交叉口相位方案进行表示,各相位绿灯时间为Gi,并将其换算与周期长度的比值为Li,形成绿灯时间矩阵G与相位矩阵L:
G=[G1 G2 G3 … Gn]
L=[L1 L2 L3 … Ln]
综上,将交叉口状态定义为离散时间步长t处的St=(P,V,L)。
步骤3.3、动作空间A定义,控制当前相位的智能体于相位绿灯时间结束时选择动作,为保证系统稳定,相位绿灯时间应在小范围内进行变动,且每相位绿灯时间Gi均应限制在最大绿灯时间Gmax与最小绿灯时间Gmin之间(Gmin≤Gi≤Gmax)。
最大绿灯时间计算公式:
式中:G
C
L——总损失时间,
y——该相位关键流量比,
Y——各相位关键流量比之和;
最小绿灯时间计算公式:
式中:G
PL
Pv
I——绿灯时间间隔;
其动作集设为Ai=(-5,-4,-3,-2,-1,0,+1,+2,+3,+4,+5),如果智能体选择ai=+3,意味着当前相位绿灯时长增加3秒,并将改变后相位时间经换算后用于更新状态空间中相位矩阵。
步骤3.4、奖励值R定义,由于不同的指标对于每个智能体策略具有不同程度的影响,因此采用多种交叉口交通参数的调和权重值作为智能体的奖励值,即R=W
(1)排队长度Rl:即智能体控制的所有相关道路的队列长度lij之和,其来源为车道级交通数据采集:
Dij——智能体所控制的所有车道的排队长度;
(2)等待时间Rw:即智能体控制的所有相关道路的车辆等待时间Wij之和,其来源为目标车辆运行数据与车道级交通数据组合给出:
Wijn——智能体所控制的所有车道所有车辆的排队时间;
(3)平均延误Rd:即智能体控制的所有相关道路的平均延误,其来源为车道级交通数据采集:
dijn——智能体所控制的所有车道的平均延误;
(4)交叉口通过车辆Rc,由目标车辆运行数据采集得出:
Cijn——智能体所控制的所有车道在相位绿灯时间通过停止线所有车辆之和;
步骤S4中,神经网络训练,使用深度强化学习方法中的MARDDPG算法训练交通信号控制智能体,此算法通过更新动作策略来选择最优动作,具体包括以下子步骤:
步骤4.1、参与者网络与评论家网络初始化参数化动作选择策略
分别地,初始化所有目标网络的权重θ'
步骤4.2、每隔5秒钟,单个智能体通过动作选择策略
步骤4.3、将已进行过的{s
步骤4.4、智能体选择M个历史训练步数据后,本发明中M的采样数为64个。利用64个历史数据中进行随机批次划分出若干个minibatch(以m表示),具体的,先从缓冲区取64个数据,但不用64个数据更新,将64个数据随机进行划分几个minibatch,然后用minibatch(批次)的数据去更新损失函数;将状态与参与者网络选择的动作输入评论家网络,使评论家网络通过步骤4.1构建的值函数
用于更新
用于更新θ
为了最大化未来预期奖励来更新参与者网络,定义J(θ
步骤4.5、系统内所有智能体采用“软更新”的方式来更新目标网络的参数
θ'
重复步骤4.2至4.5,当
步骤S5,使用训练完成的神经网络进行信号控制,根据步骤3.2、3.4中的智能体构建要求采集实时全息数据,输入信号控制智能体,通过智能体输出的各相位信号时长改变动作,生成相位时间矩阵:
G'=[G1' G2' G3' … Gn']
其中Gn'为控制n相位的智能体优化后的绿灯时间,将其组合后于下一周期开始前输入至信号机中,使用优化后的信号控制方案进行交通信号控制。
以上所揭露的仅为本发明一种较佳实施例而已,当然不能以此来限定本发明之权利范围,本领域普通技术人员可以理解实现上述实施例的全部或部分流程,并依本发明权利要求所作的等同变化,仍属于发明所涵盖的范围。
- 一种基于深度强化学习的单点交叉口信号配时优化方法
- 一种基于电警数据的交叉口自适应交通信号控制系统及其工作方法
- 一种基于电警数据的交叉口自适应交通信号控制系统及其工作方法