一种基于FPGA的HEVC熵编码硬件加速器
文献发布时间:2023-06-19 18:34:06
技术领域
本发明涉及高效视频编码HEVC熵编码领域,特别是一种基于FPGA的HEVC熵编码硬件加速器。
背景技术
随着智能手机和短视频的普及,视频在全网数据流量占比已接近70%。2013年,为了满足人们对视频更高质量的要求,国际电联(ITU)正式批准通过了新一代高效视频编码(high efficiency video coding, HEVC)标准,该标准较H.264/AVC的编码效率大约提高50%[1]。熵编码作为HEVC的最后一个环节,可以很大程度压缩视频的熵冗余。CABAC作为HEVC保留的唯一熵编码方式,虽然具有编码效率的优势,但是其计算复杂度也成倍增加。
高吞吐量熵编码器的实现需要有足够的语法元素输入,以确保熵编码器能够持续工作。随着CABAC吞吐量的提高,语法元素作为CABAC的输入,其生成速度成为熵编码实际吞吐量的瓶颈。
文献[2]将熵编码的硬件架构分成数据预处理模块、二值化模块、上下文建模模块和算数编码模块,其中数据预处理模块用于产生语法元素(sytnax element,SE)。该架构可以采用三路并行架构同时进行CTU的编码,极大提高了熵编码的吞吐量。但该架构熵编码吞吐量的提高并没有针对语法元素的生成结构进行优化,而是通过巨大的的电路资源消耗换取。文献[3]提出的四路残差语法元素方案可以提高残差语法元素的速度,但是设计复杂,并且没有考虑到语法元素的存储消耗问题。
发明内容
本发明的目的在于提供一种基于FPGA的HEVC熵编码硬件加速器,本发明提出的预头信息编码、预初始化和编码单元预处理优化策略,可以加快语法元素的产生,以供自适应二进制算术编码器使用;本发明设计的残差编码控制架构和部分上下文索引流水计算方案,可以在保持高吞吐量的同时,可以减少由复杂计算带来的路径延迟,提高工作频率。
为实现上述目的,本发明的技术方案是:一种基于FPGA的HEVC熵编码硬件加速器,其执行预头信息编码、预上下文模型初始化CMI、编码单元CU预处理优化策略、残差编码控制架构和部分上下文索引流水计算方案;所述预头信息编码是指编码器启动时,即编码头信息;所述预上下文模型初始化CIM是指编码器启动时,即计算好B 、P、和I Slice的初始上下文模型并存储到对应存储器中;所述编码单元CU预处理优化策略是指并行处理CU、PU和TU层信息,并在CU层增加两个FIFO用于存储PU和TU层产生的语法元素信息;所述残差编码控制架构是指将残差编码控制架构设计成4级流水线;所述部分上下文索引流水计算方案是使用三级流水线计算部分语法元素上下文索引,提高熵编码吞吐量。所述HEVC熵编码硬件加速器具体执行如下步骤:
步骤 S01、当检测到视频编码器启动时,就马上启动熵编码的预头信息编码和预上下文模型初始化CMI(context model initialization);完成片头信息编码和CMI后,等待第一个编码树单元CTU信息的到来,跳转步骤S02;
步骤S02、若相应CTU是某个片Slice的第一个CTU,但该Slice不是视频的第一个Slice时,则编码器在完成片头信息编码和CMI后,跳转到步骤S03;否则,直接跳转到步骤S03;
步骤S03、编码环路滤波LP (loop filter)模块的语法元素 SE(syntaxelement);完成LP 的SE编码后,跳转到步骤S04;
步骤S04、根据输入的编码单元CU(coding unit)的划分标志cu_spilt_flag对CTU进行四叉树划分,跳转到步骤S05;
步骤S05、编码CU的SE,并同时启动预测单元PU(prediction unit)和变换单元TU(transform unit)信息的预处理;编码完CU的SE后,跳转到步骤S06;
步骤S06、编码PU的语法元素;编码完PU的语法元素,跳转到步骤S06;
步骤S07、编码TU的语法元素;编码完TU的语法元素,跳转到步骤S08;
步骤S08、重复步骤S04-S07,直至编码完一个CTU全部信息,跳转到步骤S09;
步骤S09、如果相应CTU不是最后一个CTU,则等待下一个待编码的CTU信息传入,重复步骤S02-S08;否则,跳转到步骤S10;
步骤S10、如果相应CTU 是相应Slice的最后一个 CTU,但该Slice不是视频最后一个Slice,则需要将编码器的区间下限信息输出并清空,并计算下一个Slice的cabac_init_flag;完成后,等待下一个待编码的CTU信息传入,返回步骤S02;否则,跳转到步骤S11;
步骤S11、若相应CTU是视频最后一个Slice的最后一个CTU,只需要将编码器的区间下限信息输出并清空,至此,一个视频序列的熵编码流程结束。
在本发明一实施例中,所述步骤S01具体包括以下步骤:
步骤S011、编码视频的高级SE,包括视频参数集VPS(video parameter set)、序列参数集SPS(sequence parameter set)和图片参数集PPS(picture parameter set);
步骤S012、编码Slice的头信息Slice_header;
步骤S013、计算3种Slice所对应的初始上下文模型context_init_I、context_init_B、context_init_P;因为第一个Slice的类型一定是I Slice,所以将用于实时更新的上下文模型contex_update初始化为context_init_I。
在本发明一实施例中,所述步骤S02中,若相应CTU不是视频第一个Slice的第一个CTU时,上下文模型初始化具体实现方式为:
根据cabac_init_flag和Slice_type选择context_init_I、context_init_B、context_init_P其中的一个初始上下文模型,并直接将它用于初始化contex_update。
在本发明一实施例中,所述步骤S05具体实现方式为:
同时开启对CU、PU和TU信息的预处理;其中CU的语法元素信息直接输出,而PU和TU的语法元素信息分别存放在存储器FIFO_PU和FIFO_TU中,由CU的状态机控制输出;输出的SE传给熵编码的顶层cabac_top模块,cabac_top模块将SE再存到FIFO中,等待送入上下文建模模块进行建模,最后进行二进制算术编码BAC(binary arithmetic coding),并输出码流。
在本发明一实施例中,所述步骤S07具体包括以下步骤:
步骤S071、据残差系数块的扫描方式和大小,通过查表确定残差系数组CG(coefficient group)的位置;
步骤S072、向顶层传递CG的位置,查询该CG的残差系数;
步骤S073、根据CG的残差系数和扫描方式计算最后非零系数的位置;
步骤S074、CG编码。
在本发明一实施例中,所述步骤S074中的CG编码,包括计算语法元素sig_coeff_flag即SIG和coeff_abs_level_greater1_flag即GR1的上下文索引,具体实现步骤如下:
步骤S0741、根据扫描类型和像素点的索引Res_idx,查找像素点所在的位置;
步骤S0742、由像素点的位置、相邻CG的CSBF和TU的大小计算上下文基础索引Sig_Base_Ctx或Gr1_Base_Ctx;
步骤S0743、第三级流水线中,由YUV分量和基础索引计算上下文索引增量Sig_Icr_Ctx和Gr1_Base_Ctx并编码。
其中步骤 S01提到的高级语法元素和片头信息(Slice_header)具有以下特征:
(1)VPS主要用于传输视频分级信息,有利于兼容标准在可分级或多视点视频编码的扩展;
(2)SPS主要为所有SS提供了公共参数,如图像的格式信息、编码参数信息等;
(3)PPS包含同一帧图像的编码工具的可用性标志如:是否使用去方块滤波标志、Tansform skip 模式等;
(4)Slice_header主要用于编码当前Slice的参数配置信息。
(5)参数集不需要计算,可以从配置信息中获取。Slice_header除了编码器的配置参数之外,还需要输入Slice的类型。但是由于第一个Slice一定是I Slice,所以可以将Slice_type初始化为I Slice。
其中有上下文模型具体包括以下特征:
(1)不同类别的Slice的用于计算每个字符的上下文模型的初始值(InitValue)不同;
(2)每个Slice共用一个上下文模型;
(3)根据初始值、视频的量化值QP、Slice的类别可以计算出Slice的全部字符的初始上下文模型;
其中步骤S07的变换单元的编码具体包括以下特征:
(1)与变换系数有关的语法元素占总语法元素的65%-72%;
(2)在HEVC中,变换块将被划分成若干个4x4大小的系数组(Coefficient Group,CG),并按照一定的扫描顺序,依次对每个CG的系数进行编码;
(3)扫描顺序中的对角扫描规律复杂,硬件较难实现;
(4)部分残差语法元素的上下文模型计算过程较为复杂;
其中残差编码控制架构的4级流水线具体包括以下特征:
(1)第一级流水线中,根据残差系数块的扫描方式和大小,通过查表确定CG的位置。本发明将每个CG块的位置信息和CG块的跳转都记录在表里。因此,只需要一个Clk就可以实现CG位置的获取和CG的跳转。
(2)第二级流水线中,向顶层传递CG的位置,查询该CG的残差系数,该过程消耗2个Clk。
(3)第三级流水线中,根据CG的残差系数和扫描方式计算最后非零系数的位置,该过程消耗1个Clk。
(4)第四级流水线中,为了减少由语法元素上下文复杂计算带来的多路径延迟,本发明将残差系数编码独自划分一个模块,只有当CG的残差系数不为全零才进入该模块。
其中语法元素SIG和GR1的上下文索引计算具体包括以下特征:
(1)计算规则复杂并且数量占比大;
(2)SIG表示该像素点的系数是否为零,一个CG中最多编码16次SIG。GR1表示该像素点的系数是否大于1,一个CG中最多编码8次GR1;
(3)SIG和GR1的上下文索引由像素点的位置、YUV分量、变换块的大小和相邻CG的语法元素coded_sub_block_flag (CSBF)的值决定。
其中语法元素SIG和GR1的上下文索引计算架构具体包括以下特征:
(1)第一级流水线中,根据扫描类型和像素点的索引Res_idx,查找像素点所在的位置。同样,本发明将16个像素点的位置和Res_idx记录在表内。
(2)第二级流水线中,由像素点的位置、相邻CG的CSBF和TU的大小计算上下文基础索引Sig_Base_Ctx和Gr1_Base_Ctx。
(3)第三级流水线中,由YUV分量和基础索引计算上下文索引增量Sig_Icr_Ctx和Gr1_Base_Ctx并编码。
相较于现有技术,本发明具有以下有益效果:本发明设计的残差编码控制架构和部分上下文索引流水计算方案,可以在保持高吞吐量的同时,可以减少由复杂计算带来的路径延迟,提高工作频率。
附图说明
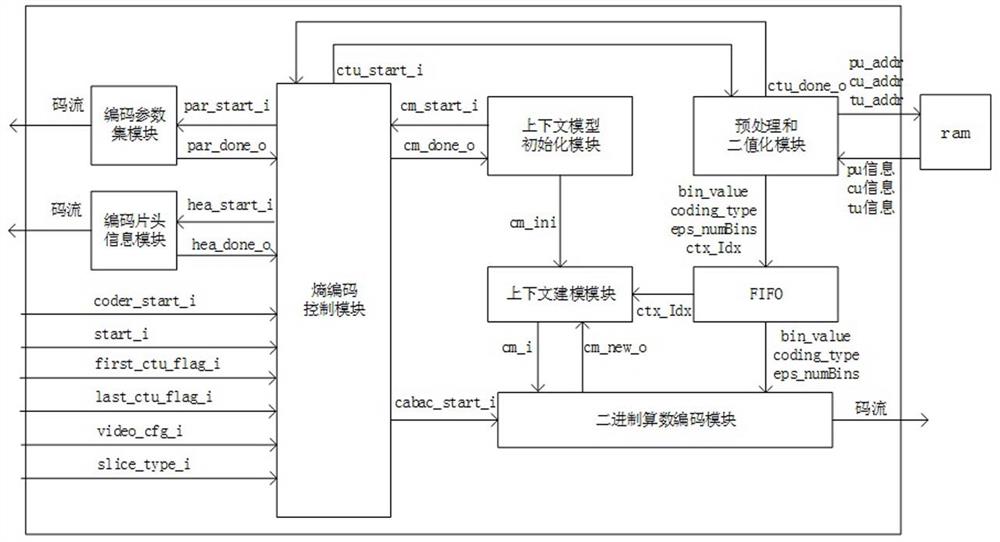
图1是本发明实施例系统结构框图。
图2是本实例中HEVC的码流结构。
图3是本发明实施例中的cabac_top的状态机转换图。
图4是本发明实施例的上下文初始化的结构图。
图5是本发明实施例中步骤S5的CU、PU和TU并行编码的结构。
图6是本发明实施例中步骤S54的残差编码流水架构。
图7是本发明实施例中步骤S55的部分上下文索引流水计算架构。
具体实施方式
下面结合附图,对本发明的技术方案进行具体说明。
一种基于FPGA的HEVC熵编码硬件加速器,其执行预头信息编码、预上下文模型初始化CMI、编码单元CU预处理优化策略、残差编码控制架构和部分上下文索引流水计算方案;所述预头信息编码是指编码器启动时,即编码头信息;所述预上下文模型初始化CIM是指编码器启动时,即计算好B 、P、和I Slice的初始上下文模型并存储到对应存储器中;所述编码单元CU预处理优化策略是指并行处理CU、PU和TU层信息,并在CU层增加两个FIFO用于存储PU和TU层产生的语法元素信息;所述残差编码控制架构是指将残差编码控制架构设计成4级流水线;所述部分上下文索引流水计算方案是使用三级流水线计算部分语法元素上下文索引,提高熵编码吞吐量。所述HEVC熵编码硬件加速器具体执行如下步骤:
步骤 S01、当检测到视频编码器启动时,就马上启动熵编码的预头信息编码和预上下文模型初始化CMI(context model initialization);完成片头信息编码和CMI后,等待第一个编码树单元CTU信息的到来,跳转步骤S02;
步骤S02、若相应CTU是某个片Slice的第一个CTU,但该Slice不是视频的第一个Slice时,则编码器在完成片头信息编码和CMI后,跳转到步骤S03;否则,直接跳转到步骤S03;
步骤S03、编码环路滤波LP (loop filter)模块的语法元素 SE(syntaxelement);完成LP 的SE编码后,跳转到步骤S04;
步骤S04、根据输入的编码单元CU(coding unit)的划分标志cu_spilt_flag对CTU进行四叉树划分,跳转到步骤S05;
步骤S05、编码CU的SE,并同时启动预测单元PU(prediction unit)和变换单元TU(transform unit)信息的预处理;编码完CU的SE后,跳转到步骤S06;
步骤S06、编码PU的语法元素;编码完PU的语法元素,跳转到步骤S06;
步骤S07、编码TU的语法元素;编码完TU的语法元素,跳转到步骤S08;
步骤S08、重复步骤S04-S07,直至编码完一个CTU全部信息,跳转到步骤S09;
步骤S09、如果相应CTU不是最后一个CTU,则等待下一个待编码的CTU信息传入,重复步骤S02-S08;否则,跳转到步骤S10;
步骤S10、如果相应CTU 是相应Slice的最后一个 CTU,但该Slice不是视频最后一个Slice,则需要将编码器的区间下限信息输出并清空,并计算下一个Slice的cabac_init_flag;完成后,等待下一个待编码的CTU信息传入,返回步骤S02;否则,跳转到步骤S11;
步骤S11、若相应CTU是视频最后一个Slice的最后一个CTU,只需要将编码器的区间下限信息输出并清空,至此,一个视频序列的熵编码流程结束。
以下为本发明具体实施实例。
如图1所示,本实例提供了一种基于FPGA的HEVC熵编码硬件加速器,所述系统包括编码参数集模块、编码片头信息模块、熵编码控制模块、预处理和二值化模块、上下文建模模块、二进制算数编码模块、FIFO模块。其中熵编码控制模块位于熵编码模块的顶层,用于协调其他所有模块的工作。由产生语法元素信息的预处理模块产生的语法元素信息将存入FIFO模块中,FIFO中的数据不为空且BAE模块可流水的情况下,将会读出FIFO中的数据bin_value、coding_type、ctx_Idx、eps_numBins。常规编码模式下,字符(bin)需要通过上下文索引ctx_Idx查找对应的上下文模型cm_i。将bin_value、coding_type、cm_i一起送入二进制算数编码模块进行编码。而旁路编码采用等概率编码,不需要进行上下文建模将bin_value、coding_type、eps_numBins一起送入二进制算数编码模块进行编码即可。最后将更新的上下文cm_new_o写入context_update,完成上下文更新过程。
图2是本实例中HEVC的码流结构,首先,整个码流前端是参数集相关信息;其次,每个片的前端是片头信息;最后,每个CTU的码流信息构成了一个Slice的码流信息,是整个视频码流的主体。对于每个CTU的编码,首先,编码器将对环路滤波模块的语法元素进行编码。其次,根据CTU的四叉树划分情况,编码器将遍历每个CU,在CU层将依次对CU、预测单元和变换单元的语法元素进行编码。
图3是本实例的熵编码器状态机转换图,一共包含7个状态,分别是原始状态(IDLE)、编码高级语法元素状态(PARA)、编码片头信息状态(Slice_Header)、上下文初始化状态(Context _Model_Init)、编码CTU状态(CTU)、清空编码器缓存状态(Slice_End)和生成cabac_init_flag状态(Determine)。当检测到编码器的启动标志coder_start_i的上升沿时,将启动参数集(PARA)和片头(Slice_Header)信息的编码,并分别对三种类别的Slice进行上下文初始化;头信息编码和上下文初始化结束后,回到原始状态,并输出header_cm_done表示上下文初始化和头信息编码已经完成,下一次Slice的首个CTU进来时,无需头信息编码和上下文初始化。当检测到start_i信号并且条件1为真时,即表示该CTU是非第一帧的首个CTU,将并行片头信息编码、上下文初始化和CTU编码。当检测到start_i时并且条件1为假时,则会进入编码CTU的状态,若该CTU不是Slice的最后一个CTU,则CTU编码结束后直接进入原始状态,等待下一个CTU数据的到来,否则end_of_slice_flag置1,进入Slice_End状态清空算数编码器的缓存,接着进入Determine状态计算cabac_init_flag,该标志决定了下一个Slice的B Slice和P Slice的上下文是否互换。
图4是本实例的上下文初始化电路图。其中,context_init_B、context_init_P、context_init_I用来存储B Slice、P Slice、I Slice的初始上下文模型;contex_update用来存储编码器实时的上下文模型。该模块启动时,控制模块将控制上下文初始化电路产生三个Slice的上下文模型,并将结果存储到context_init_B、context_init_P、context_init_I。值得一提的是,第一个Slice一定是I Slice,所以初始化过程中直接将context_init_I赋值给context_update。这样编码第一个Slice时,可以跳过上下文初始化,直接进入编码CTU状态。此后的上下文初始化过程只需要一个时钟(Clk)周期,根据Slice的类别(Slice_type_i)选择对应的context_init赋值给contex_update即可。
如图5所示,CU层输出的信息SE_t是由CU的状态机状态决定。PU和TU的CU的状态机控制启动。CU在编码的同时,将PU和TU产生的bin分别放到fifo_pu和fifo_tu中。其中state_out的计算规则如下:
(1) 编码CU内部的语法元素时,state_o等于cu_state;
(2)CU内部的语法元素已经全部编码结束后,state_o等于pu_state,直到FIFO_PU为空并且PU模块空闲时;
(3)PU的语法元素已经全部编码结束后,state_out等于tu_state,直到FIFO_TU为空并且TU模块空闲时,结束该CU的编码。
图6是本实施例中残差编码流水架构。图7是本实施例中部分上下文索引流水计算架构。
参考文献:
[1]SULLIVAN G J,OHM JR,HAN W J,et al.Overview of the high efficiencyvideo coding(HEVC)standard[J]. IEEE Trans-actions on Circuits and Systems forVideo Technology,2012,22(12):1649-1668.
[2]周小朋,梁峰,李冰. 高吞吐率的高效视频编码熵编码并行硬件架构设计[J].西安交通大学学报,2020,54(07):180-186.
[3]Ramos F L L,Saggiorato A V P,Zatt B,et al. Residual syntaxelements analysis and design targeting high-throughput HEVC CABAC[J]. IEEETransactions on Circuits and Systems I:Regular Papers, 2019, 67(2):475-488.。
以上是本发明的较佳实施例,凡依本发明技术方案所作的改变,所产生的功能作用未超出本发明技术方案的范围时,均属于本发明的保护范围。
- 一种基于FPGA的二维多通道卷积硬件加速器
- 一种基于FPGA硬件加速器的三维重建方法及系统