一种基于行人形体结构的行人属性识别方法
文献发布时间:2023-06-19 18:34:06
技术领域
本发明属于视频结构化和图像智能分析技术领域,涉及一种面向监控场景中行人目标的属性识别方法。
背景技术
视频监控中的行人属性识别,是对行人图像的多个属性进行预测,作为视频监控中的语义描述,如年龄、性别、衣着等。
近年来,行人属性识别因其在现实世界中的巨大应用潜力,如行人重识别、行人搜索等,而受到越来越多的关注。随着人们对安防问题日益关注,大量的监控摄像头安装在商场、交通枢纽、影院和公园广场等人群密集且易发生公共安全事件的场所。行人属性识别技术可以识别监控场景中行人的一些外部属性信息。
与许多视觉任务类似,行人属性识别方法分为两大类:人工提取特征方法和深度学习方法。由于监控视频中的行人图像易受运动模糊影响,且分辨率较低,因此传统手工特征方法识别的准确率不高。近年来,基于深度卷积神经网络的方法通过从图像中自主学习强大的特征,在行人属性识别方面取得了很大的成功。现有的一些方法将行人属性识别作为一个多标签分类问题,仅从整个输入图像中提取特征表示,这些整体方法通常依赖于全局特征,但区域特征对于细粒度属性分类更为重要;也有一些方法虽然考虑了局部区域的特征,但是采用属性不可知的视觉注意或启发式的身体部位定位机制来增强局部特征表达,而忽略了利用属性来定义局部特征区域。
发明内容
本发明的目的在于克服现有技术的不足,提出一种基于行人形体结构的行人属性识别方法,直接利用属性来对行人局部位置进行定位,有效提升行人属性识别模型的识别效果。
本发明的技术方案如下:
一种基于行人形体结构的行人属性识别方法,其特征在于包括以下步骤:
步骤1,构造数据集,以RGB行人图像作为输入,通过Resnet50主干网络进行特征提取,得到空间维度为N×C×10H×W的行人语义特征,其中N、C、10H和W分别代表样本数量、通道数量、特征高度和宽度;
步骤2,使用步骤1中行人语义特征后接全局池化层和全连接层进行行人属性识别预训练,以此行人语义特征进行初始化;
步骤3,将步骤2所得初始化后的行人语义特征在水平方向上均匀拆分为10等份,各个部分之间选取边界特征进行复用;10等份中由上而下前三份为头部特征,记为 N×C×3H×W;第2份至第7份共计6份作为上半身特征,记为N×C×6H×W;第6份至第10份共计5份作为下半身特征,记为N×C×5H×W;
步骤4,对步骤3中所得头部特征、上半身特征和下半身特征分别使用独立的Non-Local 模块进行特征增强,此处Non-Local模块不改变特征的空间维度;
步骤5,对步骤4中所得增强后的头部特征、上半身特征和下半身特征分别使用全局均值池化操作得到压缩后的头部特征、上半身特征和下半身特征,后分别使用独立的全连接层输出各部分属性分类结果,此处各部分属性分类类别数为数据集中全部属性类别数;
步骤6,在训练阶段,从每个部分得到的分类结果中挑选出该区域匹配到的M个独用标签,和N个复用标签,分别计算模型预测结果与各个标签之间的损失,选取最小的M个损失进行梯度回传;在推理阶段,直接将各个区域得到的分类结果按位比较取最大值。
本发明将行人特征水平切分为三个部分,直接利用属性来对行人局部位置进行定位,在训练阶段,利用行人形体结构的知识先验,对每个部分分配合理的属性标签,通过最小化匹配标签的分类损失使得模型在训练过程中自发的选择最合适的属性进行学习;在推理阶段,对三个部分的预测结果进行合并,得到最终的行人属性分类结果。相比于现有的使用注意力定位来学习属性识别中的局部判别力特征或者借助额外的计算资源来进行复杂的局部定位,本发明能有效提升行人属性识别模型的识别效果。
附图说明
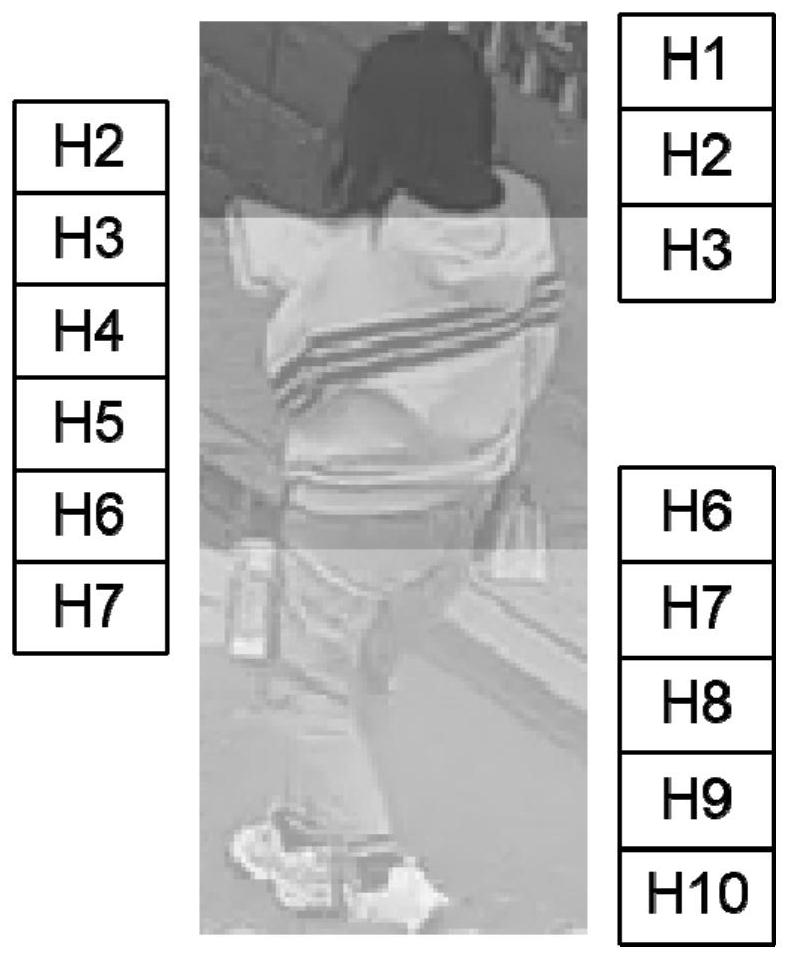
图1是本发明对行人不同区域的划分示意图。
具体实施方式
通常对行人属性的观察,当识别行人发型时,应当主要关注与头部相关的区域,同样的,当识别行人裤子款式时,应主要关注与腿部相关的区域。
如图1所示,本发明基于上述观察,将行人特征从上到下依次水平切分为头部区域、上半身区域、下半身区域三个部分。使用摘除最后一层均值池化层和全连接层的Resnet50作为特征提取网络,将提取出的特征按水平方向非均匀切分为三部分,且每相邻两部分间复用边界特征。每个部分后接一个独立的Non-Local注意力模块。不同于标准卷积模块仅基于特征局部区域进行操作,Non-Local通过计算特征图中任意两个位置的信息交互来获取长距离依赖,从而对局部特征进行增强。然后将三个部分增强的局部特征送入三个独立的分类器中进行属性分类。
在训练阶段,利用行人形体结构的知识先验,对每个部分分配合理的属性标签,通过最小化匹配标签的分类损失使得模型在训练过程中自发的选择最合适的属性进行学习。具体来说,首先将训练数据集中的属性标签按人体结构划分为三部分,分别对应行人头部区域、上半身区域和下半身区域,划分后的每个区域的标签又可分为两类:独用标签和复用标签。其中复用标签对应前述复用特征,即多个区域共有的标签,比如对于长款羽绒服来说,模型有理由关注头部区域的帽子、上半身的衣袖和下半身的衣尾;独用标签意味着单个区域独有的标签,比如对于鞋子的款式和颜色来说,模型仅仅需要关注下半身区域。
记三个部分的独用标签和复用标签分别为:头部区域独用标签H
在推理阶段,对三个部分的预测结果进行合并,得到最终的行人属性分类结果。
本发明的具体实施方式如下:
步骤1,构造数据集,以RGB行人图像作为输入,通过Resnet50主干网络进行特征提取,得到空间维度为N×C×10H×W的行人语义特征,其中N、C、10H和W分别代表样本数量、通道数量、特征高度和宽度;
步骤2,为了方便模型拟合,使用步骤1中行人语义特征后接全局池化层和全连接层进行行人属性识别预训练,以此行人语义特征进行初始化;
步骤3,如图1所示,将步骤2所得初始化后的行人语义特征在水平方向上均匀拆分为 H1到H10共10等份,为了减少对特征图的硬拆分带来的不利影响,各个部分之间选取边界特征进行复用,10等份中由上而下前三份为头部特征(N×C×3H×W)、第2份至第7份共计6份作为上半身特征(N×C×6H×W)、第6份至第10份共计5份作为下半身特征 (N×C×5H×W);
步骤4,对步骤3中所得头部特征、上半身特征和下半身特征分别使用独立的Non-Local 模块进行特征增强,此处Non-Local模块不改变特征的空间维度;
步骤5,对步骤4中所得增强后的头部特征、上半身特征和下半身特征分别使用全局均值池化操作得到压缩后的头部特征(N×C×1×1)、上半身特征(N×C×1×1)和下半身特征 (N×C×1×1),后分别使用独立的全连接层输出各部分属性分类结果,此处各部分属性分类类别数为数据集中全部属性类别数;
步骤6,在训练阶段,从每个部分得到的分类结果中挑选出该区域匹配到的独用标签(数量为M)和复用标签(数量为N),分别计算模型预测结果与各个标签之间的损失,选取最小的M个损失进行梯度回传;在推理阶段,直接将各个区域得到的分类结果按位比较取最大值。