二代测序的靶向序列捕获探针设计策略选择方法、系统及终端
文献发布时间:2023-06-19 18:35:48
技术领域
本发明涉及生物行业分子检测领域,特别是涉及一种二代测序的靶向序列捕获探针设计策略选择方法、系统及终端。
背景技术
目前分子检测常用的技术有生物芯片法、荧光定量PCR法、ddPCR法、一代测序法、NGS(高通量测序)方法等。NGS高通量测序技术又称第二代测序技术,相对于其他分子检测技术,NGS方法具有通量高(可对几百万到数十亿的DNA分子一次性实现并行测序)、覆盖检测变异类型种类多(可同时检测SNV、Indel、CNV、Fusion、MSI、TMB等biomarker)、样本利用率高(不用将一份样本分成多份检测,尤其是对于本身较低含量的样本)、检测灵敏度及特异性均较高(在某些变异类型检测上略低于ddPCR法,如SNV、Indel)、可检测未知变异(有利于发现新的变异位点)、性价比相对较高(平均至单个样本或单个位点或单种变异类型)等优势。而其中基于探针捕获技术的靶向测序方法,相对于全基因组测序或全外显子组测序,具有性价比更高、交付周期更短等优势。
探针捕获测序的原理是通过设计合成有效的特异性探针,与基因组DNA进行杂交,将目标区域序列进行捕获并富集后,建库并在测序仪上进行高通量测序及后续的结果分析。探针捕获测序法最关键的环节是探针设计及铺设策略,由于基因组序列特征的复杂多样性,包括GC含量不均、重复序列特征、回文序列结构特征等都将可能会影响探针的杂交过程,进而影响探针捕获效率和基因组区域的覆盖深度。目前的探针设计铺设思路主要有三种:1)平铺式探针设计;2)叠瓦式探针设计;3)基于正负链设计的双链探针。现有的策略一般是采用无差异的固定的1-3重不等的探针覆盖层数,从而导致某些特殊特征区域达不到很好的捕获效果,后续再根据建库下机结果对相应区域的探针覆盖层数进行优化调整,从而达到较好的产品性能。这一策略虽然最终可以得到相对较好的性能结果,但由于该过程是基于实验结果导向的优化,因此研究者会花费大量时间去进行优化实验进而指导铺设探针的设计优化,效率较低。如果能够在早期就可以预测出哪些靶标区域会导致探针捕获效率低,研究者就能够根据这一预测结果对探针设计及铺设策略早期进行调整,从而减少实验优化时间,将大大提高panel优化效率。虽然目前已经有研究表明GC含量是影响探针杂交捕获效率的重要因素,然而由于基因序列的复杂多样性,仍然可能会有其他的未知因素会影响这一过程。如何全面评估靶标序列的复杂多样性对探针捕获效率带来的影响,从而更好地指导上游的探针设计及铺设策略,需要更加科学合理的评估方式,这也是本领域需要解决的技术难题。
发明内容
鉴于以上所述现有技术的缺点,本发明的目的在于提供一种二代测序的靶向序列捕获探针设计策略选择方法、系统及终端,用于解决现有技术中以上技术问题。
为实现上述目的及其他相关目的,本发明提供一种二代测序的靶向序列捕获探针设计策略选择方法,所述方法包括:获取待进行探针设计策略选择的目标序列;基于构建的探针捕获区域分类模型,根据输入的目标序列获得对应的探针捕获区域分类结果;其中,所述探针捕获区域分类结果的类型包括:对应探针捕获高效率区域的探针捕获高效率结果以及对应探针捕获低效率区域的探针捕获低效率结果;根据所述探针捕获区域分类结果选择与其对应的探针设计策略。
于本发明的一实施例中,所述探针捕获区域分类模型的构建方式包括:选取多个无差别固定层数的探针覆盖靶向样本区域;基于区域捕获效率判断规则,将各探针覆盖靶向样本区域分为对应探针捕获高效率区域的高效率样本区域组以及对应探针捕获低效率区域的低效率样本区域组;其中,所述高效率样本区域组包括:多个高效率样本区域;所述低效率样本区域组包括:多个低效率样本区域;提取所述高效率样本区域组以及低效率样本区域组中各样本区域的靶标区域序列特征,以获得特征训练矩阵;利用所述特征训练矩阵训练获得所述探针捕获区域分类模型。
于本发明的一实施例中,所述提取各高效率样本区域以及各低效率样本区域的靶标区域序列特征,以获得特征训练矩阵包括:将各高效率样本区域以及各低效率样本区域分别行无序k-mer遍历,获得各样本区域分别对应多个k-mer的特征数据;基于各k-mer的特征数据作为特征数据训练模型的验证结果对特征数据进行筛选,将各样本区域对应筛选后的一k-mer的特征数据作为其各自对应的靶标区域序列特征,以获得特征训练矩阵。
于本发明的一实施例中,所述验证结果包括:召回率、精准率、精确度以及F1_score。
于本发明的一实施例中,所述探针捕获区域分类模型经过采用十折交叉验证方法进行优化获得。
于本发明的一实施例中,所述根据所述探针捕获区域分类结果选择与其对应的探针设计策略包括:若所述探针捕获区域分类结果为所述探针捕获高效率结果,则选择常规探针铺设策略;若所述探针捕获区域分类结果为所述探针捕获低效率结果,则选择多重差异探针铺设策略。
于本发明的一实施例中,所述常规探针铺设策略为3重探针覆盖策略;所述多重差异探针铺设策略为5重探针覆盖策略。
为实现上述目的及其他相关目的,本发明提供一种二代测序的靶向序列捕获探针设计策略选择系统,所述系统包括目标序列获取模块,用于获取待进行探针设计策略选择的目标序列;探针捕获区域分类模块,连接所述目标序列获取模块,用于基于构建的探针捕获区域分类模型,根据输入的目标序列获得对应的探针捕获区域分类结果;其中,所述探针捕获区域分类结果的类型包括:对应探针捕获高效率区域的探针捕获高效率结果以及对应探针捕获低效率区域的探针捕获低效率结果;策略选择模块,连接所述探针捕获区域分类模块,用于根据所述探针捕获区域分类结果选择与其对应的探针设计策略。
为实现上述目的及其他相关目的,本发明提供一种二代测序的靶向序列捕获探针设计策略选择终端,包括:一或多个存储器及一或多个处理器;所述一或多个存储器,用于存储计算机程序;所述一或多个处理器,连接所述存储器,用于运行所述计算机程序以执行所述二代测序的靶向序列捕获探针设计策略选择方法。
如上所述,本发明是一种二代测序的靶向序列捕获探针设计策略选择方法、系统及终端,具有以下有益效果:本发明通过基于构建的探针捕获区域分类模型,根据输入的目标序列获得对应的探针捕获区域分类结果,并根据所述探针捕获区域分类结果选择与其对应的探针设计策略。本发明通过模型对靶标区域序列特征的预测,可以对不同区域进行分组,针对性地采取不同的探针设计和铺设策略,从而可以缩短后续实验的优化过程,节约时间成本;还可在实际应用中可有效提高捕获检测panel的整体性能,节约研发成本,保证临床样本的准确稳定检出。
附图说明
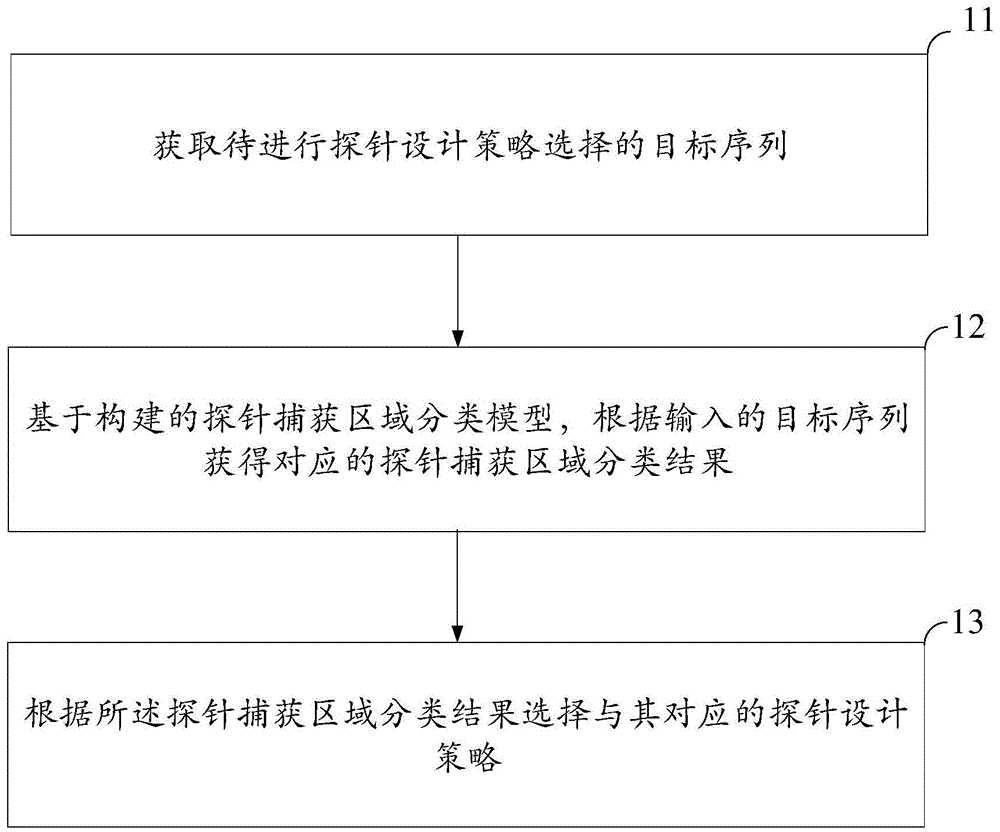
图1显示为本发明一实施例中的二代测序的靶向序列捕获探针设计策略选择方法的流程示意图。
图2显示为本发明一实施例中的探针设计策略选择方法的流程示意图。
图3显示为本发明一实施例中的10例样本的两组探针设计方案探针捕获效率差异统计结果示意图。
图4显示为本发明一实施例中的二代测序的靶向序列捕获探针设计策略选择系统的结构示意图。
图5显示为本发明一实施例中的二代测序的靶向序列捕获探针设计策略选择终端的结构示意图。
具体实施方式
以下通过特定的具体实例说明本发明的实施方式,本领域技术人员可由本说明书所揭露的内容轻易地了解本发明的其他优点与功效。本发明还可以通过另外不同的具体实施方式加以实施或应用,本说明书中的各项细节也可以基于不同观点与应用,在没有背离本发明的精神下进行各种修饰或改变。需说明的是,在不冲突的情况下,以下实施例及实施例中的特征可以相互组合。
需要说明的是,在下述描述中,参考附图,附图描述了本发明的若干实施例。应当理解,还可使用其他实施例,并且可以在不背离本发明的精神和范围的情况下进行机械组成、结构、电气以及操作上的改变。下面的详细描述不应该被认为是限制性的,并且本发明的实施例的范围仅由公布的专利的权利要求书所限定。这里使用的术语仅是为了描述特定实施例,而并非旨在限制本发明。空间相关的术语,例如“上”、“下”、“左”、“右”、“下面”、“下方”、““下部”、“上方”、“上部”等,可在文中使用以便于说明图中所示的一个元件或特征与另一元件或特征的关系。
在通篇说明书中,当说某部分与另一部分“连接”时,这不仅包括“直接连接”的情形,也包括在其中间把其它元件置于其间而“间接连接”的情形。另外,当说某种部分“包括”某种构成要素时,只要没有特别相反的记载,则并非将其它构成要素,排除在外,而是意味着可以还包括其它构成要素。
其中提到的第一、第二及第三等术语是为了说明多样的部分、成分、区域、层及/或段而使用的,但并非限定于此。这些术语只用于把某部分、成分、区域、层或段区别于其它部分、成分、区域、层或段。因此,以下叙述的第一部分、成分、区域、层或段在不超出本发明范围的范围内,可以言及到第二部分、成分、区域、层或段。
再者,如同在本文中所使用的,单数形式“一”、“一个”和“该”旨在也包括复数形式,除非上下文中有相反的指示。应当进一步理解,术语“包含”、“包括”表明存在所述的特征、操作、元件、组件、项目、种类、和/或组,但不排除一个或多个其他特征、操作、元件、组件、项目、种类、和/或组的存在、出现或添加。此处使用的术语“或”和“和/或”被解释为包括性的,或意味着任一个或任何组合。因此,“A、B或C”或者“A、B和/或C”意味着“以下任一个:A;B;C;A和B;A和C;B和C;A、B和C”。仅当元件、功能或操作的组合在某些方式下内在地互相排斥时,才会出现该定义的例外。
本发明提供一种二代测序的靶向序列捕获探针设计策略选择方法、系统及终端,通过基于构建的探针捕获区域分类模型,根据输入的目标序列获得对应的探针捕获区域分类结果,并根据所述探针捕获区域分类结果选择与其对应的探针设计策略。本发明通过模型对靶标区域序列特征的预测,可以对不同区域进行分组,针对性地采取不同的探针设计和铺设策略,从而可以缩短后续实验的优化过程,节约时间成本;还可在实际应用中可有效提高捕获检测panel的整体性能,节约研发成本,保证临床样本的准确稳定检出。
下面以附图为参考,针对本发明的实施例进行详细说明,以便本发明所述技术领域的技术人员能够容易地实施。本发明可以以多种不同形态体现,并不限于此处说明的实施例。
如图1展示本发明实施例中的一种二代测序的靶向序列捕获探针设计策略选择方法的流程示意图。
所述方法包括:
步骤S11:获取待进行探针设计策略选择的目标序列。
步骤S12:基于构建的探针捕获区域分类模型,根据输入的目标序列获得对应的探针捕获区域分类结果。
详细来说,所述探针捕获区域分类结果的类型包括:对应探针捕获高效率区域的探针捕获高效率结果以及对应探针捕获低效率区域的探针捕获低效率结果。
具体的,将目标序列输入所述探针捕获区域分类模型,以获得对应探针捕获高效率区域的探针捕获高效率结果或对应探针捕获低效率区域的探针捕获低效率结果。
在一实施例中,所述探针捕获区域分类模型的构建方式包括:选取多个无差别固定层数的探针覆盖靶向样本区域;基于区域捕获效率判断规则,将各探针覆盖靶向样本区域分为对应探针捕获高效率区域的高效率样本区域组以及对应探针捕获低效率区域的低效率样本区域组;其中,所述高效率样本区域组包括:多个高效率样本区域;所述低效率样本区域组包括:多个低效率样本区域;提取所述高效率样本区域组以及低效率样本区域组中各样本区域的靶标区域序列特征,以获得特征训练矩阵;利用所述特征训练矩阵训练获得所述探针捕获区域分类模型。
需要说明的是,高效率样本区域的靶标区域序列特征对应标记有探针捕获高效率区域标签;低效率样本区域的靶标区域序列特征对应标记有探针捕获低效率区域标签;
总结来说,本方案通过对不同探针覆盖深度的靶标区域的序列特征进行机器学习,利用支持向量机SVM方法构建一种分类器,对于做出标记的两组样本向量,给出一个最优分割超曲面把这两组向量分割到两边,使得两组向量中离此超平面最近的向量(即所谓支持向量)到此超平面的距离都尽可能远。该方法建立的分类模型,可以将我们的目标序列分类成探针捕获高效区和低效区两个组别,不同组别采用不同的探针设计和铺设策略,从而可以更加高效地辅助panel的性能优化。
在一实施例中,所述区域捕获效率判断规则包括:当探针覆盖靶向样本区域的测序深度不小于平均测序深度与标准差的差值,则将该探针覆盖靶向样本区域作为高效率样本区域;当探针覆盖靶向样本区域的测序深度小于平均测序深度与标准差的差值,则将该探针覆盖靶向样本区域作为低效率样本区域。
举例来说,选取无差别固定层数的探针覆盖靶向区域558个,其中将测序深度大于等于mean(平均测序深度)-1sd(标准差)的区域定为捕获效率高的区域,合计得到472个探针捕获效率高的区域;将测序深度小于mean(平均测序深度)-1sd(标准差)的区域定为捕获效率低的区域,合计得到87个探针捕获效率低的区域;即将558个区域划分为探针捕获效率高和探针捕获效率低两个组别。并且可将所述558个区域中70%作为模型的训练集,剩余30%作为模型的测试集。
在一具体实施例中,提取各高效率样本区域以及各低效率样本区域的靶标区域序列特征,以获得特征训练矩阵包括:将各高效率样本区域以及各低效率样本区域分别行无序k-mer遍历,获得各样本区域分别对应多个k-mer的特征数据;基于各k-mer的特征数据作为特征数据训练模型的验证结果对特征数据进行筛选,将各样本区域对应筛选后的一k-mer的特征数据作为其各自对应的靶标区域序列特征,构成特征训练矩阵。
具体的,将各高效率样本区域以及各低效率样本区域分别进行无序k-mer遍历,每一种碱基组合下的k-mer作为一个特征,k-mer种类记为n,其含量作为该特征取值。每个区域转换成为一个1*n维数组,最终数据输入形式为样本区域个数*n矩阵。基于各k-mer的特征数据作为特征数据训练模型的验证结果对特征数据进行筛选,筛选出一k-mer,将各样本区域对应筛选后的一k-mer的特征数据作为其各自对应的靶标区域序列特征,以获得特征训练矩阵。
在一具体实施例中,所述验证结果包括:召回率、精准率、精确度以及F1_score。即选取验证结果最好的k-mer值。
举例来说,针对k-mer特征值进行选取优化,具体操作为遍历不同的k-mer值(3-mer、5-mer、7-mer、9-mer、10-mer)并各k-mer值的特征数据作为特征数据训练模型的验证结果,其内容如下表:
表1:各k-mer的特征数据作为特征数据训练模型的验证结果
根据以上验证结果,最终选取7-mer的特征值的向量机模型。
在一实施例中,所述探针捕获区域分类模型经过采用十折交叉验证方法进行优化获得。所述十折交叉验证方法,英文名叫做10-fold cross-validation,用来测试算法准确性。是常用的测试方法。将数据集分成十份,轮流将其中9份作为训练数据,1份作为测试数据,进行试验。每次试验都会得出相应的正确率(或差错率)。10次的结果的正确率(或差错率)的平均值作为对算法精度的估计,一般还需要进行多次10折交叉验证(例如10次10折交叉验证),再求其均值,作为对算法准确性的估计。
步骤S13:根据所述探针捕获区域分类结果选择与其对应的探针设计策略。
在一实施例中,所述根据所述探针捕获区域分类结果选择与其对应的探针设计策略包括:若所述探针捕获区域分类结果为所述探针捕获高效率结果,则选择常规探针铺设策略;若所述探针捕获区域分类结果为所述探针捕获低效率结果,则选择多重差异探针铺设策略。
即本方案的整体思路如图2所示,靶标区域输入探针捕获区域分类模型模型进行预测,根据预测结果将靶标区域分为两组,预测结果显示探针捕获效率高的区域采用常规探针铺设策略,预测结果显示探针捕获效率低的区域采用多重差异探针铺设策略。
优选的,所述常规探针铺设策略为3重探针覆盖策略;所述多重差异探针铺设策略为5重探针覆盖策略。
为了更好的说明上述二代测序的靶向序列捕获探针设计策略选择方法,本发明提供以下具体实施例。
实施例1:一种探针设计及铺设策略。
利用本发明的探针设计方案,选取肿瘤相关的40个基因的全部外显子区域作为靶标区域,将靶标区域输入预测模型进行预测,根据预测结果将靶标区域分为两组,预测结果显示探针捕获效率高的区域采用常规的3重探针覆盖策略,预测结果显示探针捕获效率低的区域采用5重探针覆盖策略,增加的2重采用基于互补链的探针设计,并且增加和临近区域探针的交叠。作为对照组,采用无差别的所有区域固定3重覆盖探针。探针长度均为120bp单链RNA探针,采用同样的血液样本进行实验对比两种设计策略的性能差异。
实施例2:血液组织样本DNA的变异检测。
检测技术方案主要包括以下实施步骤:
1、基因组DNA(gDNA)的提取;样本类型是人外周血液,血液样本体积应不小于200μL,核酸提取流程参照试剂盒说明书(DP304-天根血液/细胞/组织基因组DNA提取试剂盒)进行操作,对提取的gDNA用Qubit
2、预文库的构建;该过程是将gDNA转换成Illumina高通量测序平台专用文库。主要流程参照说明书内容(ND627-
3、杂交捕获;1)预文库样本每个取500ng,将1-6个预文库等量混合到一个新的离心管内,将离心管放入真空浓缩仪,干燥时间5-30min,干燥后加入5μL Nuclease-freeWater充分震荡混匀,离心后静置备用。2)取新的离心管放置于常温管架上进行杂交混合液的配制,依次加入试剂,然后上下颠倒2次后使用旋涡混匀仪震荡2秒混匀,快速离心5秒将管壁液体离心至管底,配制成单个或多个杂交混合液,放置于常温备用。3)将配制好的杂交混合液按照每个反应31μL加入到1)中5μL预文库中,并使用移液器轻轻吹打混匀。将预文库杂交混合液放置于杂交用的PCR仪上进行PCR反应。4)将在室温已平衡30min的链霉亲和素磁珠充分震荡混匀,向每个离心管内分装加入50μL,然后再向每个离心管加入150μL的洗涤缓冲液Ⅰ,混匀后放在磁力架上去掉上清,重复操作加入洗涤缓冲液Ⅰ,总共3次清洗,仅保留磁珠在管底。最后每个离心管内加入150μL的洗涤缓冲液Ⅰ重悬磁珠,并标记样本信息。5)预文库杂交混合液65℃孵育~16小时后,在PCR仪上打开PCR管,用移液器将4)中150μL磁珠重悬液加入到杂交混合液中,并使用移液器轻轻吹打8次。然后将包含磁珠和杂交体系的混合液全部再转移回4)中标记的磁珠离心管中。将上述包含磁珠杂交混合液的离心管放置在垂直旋转仪上并固定好,室温旋转孵育30分钟。。6)30分钟后从旋转仪或震荡金属浴上取下离心管,快速离心5秒,放置磁力架2-5分钟,确保液体清澈,吸弃上清。从磁力架上取下离心管,每个孔加入150μL的洗涤缓冲液Ⅱ来重悬磁珠,移液器轻轻吹打10次,室温孵育15分钟,每间隔5分钟,上下快速颠倒15次。洗涤缓冲液Ⅱ室温孵育完成后,快速离心5秒后放置磁力架上待液体清澈后,吸弃上清液,放置在65℃的杂交用的PCR仪上,立即用移液器加入150μL的已65℃预热好的洗涤缓冲液Ⅲ,在PCR仪上吹吸10次使磁珠充分混匀,盖上管盖65℃孵育10分钟。待65℃孵育10分钟结束后,从PCR仪上取下放置在磁力架上,待液体清澈后吸弃上清。重复用洗涤缓冲液Ⅲ清洗共3次。7)上述3次清洗完成后,快速离心10秒,再次放置于磁力架上用10μL移液器尽可能吸走全部残余液体,最后加入20μL Nuclease-free Water重悬磁珠,移液器轻轻吹打8次,并吸取全部磁珠混悬液加入配好的Post-PCR反应体系中,再次轻轻吹打混匀8次,确保磁珠和PCR反应体系混合均匀,然后将混合体系放置于PCR仪上进行PCR扩增反应。8)上述PCR完成后,用0.8X(40μL)纯化磁珠进行纯化,最后用20μL的Low TE进行洗脱,得到的终文库经浓度测定后,总量应不小于20ng,且经Agilent Bioanalyzer 2100或Labchip质检后,观察到的文库主峰约为250~400bp。
4、上机测序与数据分析;1)测序数据预处理与质控;终文库在Illumina测序平台进行PE150测序,每个样本测序数据量应不小于500Mb。获得测序数据BCL文件后,使用bcl2fastq v2.17.1.14软件将测序下机文件(BCL格式)转换为序列文件(FASTQ格式),在获得fastq格式的下机数据后,使用Trimmomatic(v0.36)软件去除建库过程中引入的接头序列以及低质量碱基片段,过滤掉经长度小于50bp的reads。序列比对模块基于软件bwa(v0.7.10),将过滤后的fastq文件中的序列比对到hg19人类参考基因组和融合参考基因组上,生成相应的bam文件,根据基因组坐标,对生成的bam文件进行排序。并统计目标区域(即每个外显子区域)内平均测序深度信息(depth)。2)评估两组探针设计方案的捕获效率及整体性能;选取10例样本分别统计两组探针设计方案探针捕获效率差异,下机数据量已经均一化到200Mb,从下图中可以看出使用新的探针设计方案后样本各区域测序深度更均一,从图3中可以看出对于预测探针捕获效率低的区域,本发明所提供的探针设计策略所体现的覆盖深度等性能指标显著优于传统的无差别探针铺设策略,并且两组区域的测序覆盖深度接近,有助于提高panel整体的性能,有利于临床变异的稳定准确检出。另外,本发明所提供的探针设计策略可以大大缩短研发对于panel性能的实验优化过程,可以显著提高产品研发效率。
与上述实施例原理相似的是,本发明提供一种二代测序的靶向序列捕获探针设计策略选择系统。
以下结合附图提供具体实施例:
如图4展示本发明实施例中的一种二代测序的靶向序列捕获探针设计策略选择系统的结构示意图。
所述系统包括:
目标序列获取模块41,用于获取待进行探针设计策略选择的目标序列;
探针捕获区域分类模块42,连接所述目标序列获取模块41,用于基于构建的探针捕获区域分类模型,根据输入的目标序列获得对应的探针捕获区域分类结果;其中,所述探针捕获区域分类结果的类型包括:对应探针捕获高效率区域的探针捕获高效率结果以及对应探针捕获低效率区域的探针捕获低效率结果;
策略选择模块43,连接所述探针捕获区域分类模块42,用于根据所述探针捕获区域分类结果选择与其对应的探针设计策略。
需说明的是,应理解图4系统实施例中的各个模块的划分仅仅是一种逻辑功能的划分,实际实现时可以全部或部分集成到一个物理实体上,也可以物理上分开。且这些单元可以全部以软件通过处理元件调用的形式实现;也可以全部以硬件的形式实现;还可以部分单元通过处理元件调用软件的形式实现,部分单元通过硬件的形式实现。
由于该二代测序的靶向序列捕获探针设计策略选择系统的实现原理已在前述实施例中进行了叙述,因此此处不作重复赘述。
可选的,所述探针捕获区域分类模型的构建方式包括:选取多个无差别固定层数的探针覆盖靶向样本区域;基于区域捕获效率判断规则,将各探针覆盖靶向样本区域分为对应探针捕获高效率区域的高效率样本区域组以及对应探针捕获低效率区域的低效率样本区域组;其中,所述高效率样本区域组包括:多个高效率样本区域;所述低效率样本区域组包括:多个低效率样本区域;提取所述高效率样本区域组以及低效率样本区域组中各样本区域的靶标区域序列特征,以获得特征训练矩阵;利用所述特征训练矩阵训练获得所述探针捕获区域分类模型。
可选的,所述区域捕获效率判断规则包括:当探针覆盖靶向样本区域的测序深度不小于平均测序深度与标准差的差值,则将该探针覆盖靶向样本区域作为高效率样本区域;当探针覆盖靶向样本区域的测序深度小于平均测序深度与标准差的差值,则将该探针覆盖靶向样本区域作为低效率样本区域。
可选的,所述提取各高效率样本区域以及各低效率样本区域的靶标区域序列特征,以获得特征训练矩阵包括:将各高效率样本区域以及各低效率样本区域分别行无序k-mer遍历,获得各样本区域分别对应多个k-mer的特征数据;基于各k-mer的特征数据作为特征数据训练模型的验证结果对特征数据进行筛选,将各样本区域对应筛选后的一k-mer的特征数据作为其各自对应的靶标区域序列特征,以获得特征训练矩阵。
可选的,所述验证结果包括:召回率、精准率、精确度以及F1_score。
可选的,所述探针捕获区域分类模型经过采用十折交叉验证方法进行优化获得。
可选的,所述根据所述探针捕获区域分类结果选择与其对应的探针设计策略包括:若所述探针捕获区域分类结果为所述探针捕获高效率结果,则选择常规探针铺设策略;若所述探针捕获区域分类结果为所述探针捕获低效率结果,则选择多重差异探针铺设策略。
可选的,所述常规探针铺设策略为3重探针覆盖策略;所述多重差异探针铺设策略为5重探针覆盖策略。
如图5展示本发明实施例中的二代测序的靶向序列捕获探针设计策略选择终端10的结构示意图。
所述二代测序的靶向序列捕获探针设计策略选择终端50包括:存储器51及处理器52所述存储器51用于存储计算机程序;所述处理器52运行计算机程序实现如图1所述的二代测序的靶向序列捕获探针设计策略选择方法。
可选的,所述存储器51的数量均可以是一或多个,所述处理器52的数量均可以是一或多个,而图5中均以一个为例。
可选的,所述二代测序的靶向序列捕获探针设计策略选择终端50中的处理器52会按照如图1所述的步骤,将一个或多个以应用程序的进程对应的指令加载到存储器51中,并由处理器52来运行存储在第一存储器51中的应用程序,从而实现如图1所述二代测序的靶向序列捕获探针设计策略选择方法中的各种功能。
可选的,所述存储器51,可能包括但不限于高速随机存取存储器、非易失性存储器。例如一个或多个磁盘存储设备、闪存设备或其他非易失性固态存储设备;所述处理器52,可能包括但不限于中央处理器(Central Processing Unit,简称CPU)、网络处理器(Network Processor,简称NP)等;还可以是数字信号处理器(Digital SignalProcessing,简称DSP)、专用集成电路(Application Specific Integrated Circuit,简称ASIC)、现场可编程门阵列(Field-Programmable Gate Array,简称FPGA)或者其他可编程逻辑器件、分立门或者晶体管逻辑器件、分立硬件组件。
可选的,所述处理器52可以是通用处理器,包括中央处理器(Central ProcessingUnit,简称CPU)、网络处理器(Network Processor,简称NP)等;还可以是数字信号处理器(Digital Signal Processing,简称DSP)、专用集成电路(Application SpecificIntegrated Circuit,简称ASIC)、现场可编程门阵列(Field-Programmable Gate Array,简称FPGA)或者其他可编程逻辑器件、分立门或者晶体管逻辑器件、分立硬件组件。
本发明还提供计算机可读存储介质,存储有计算机程序,所述计算机程序运行时实现如图1所示的二代测序的靶向序列捕获探针设计策略选择方法。所述计算机可读存储介质可包括,但不限于,软盘、光盘、CD-ROM(只读光盘存储器)、磁光盘、ROM(只读存储器)、RAM(随机存取存储器)、EPROM(可擦除可编程只读存储器)、EEPROM(电可擦除可编程只读存储器)、磁卡或光卡、闪存、或适于存储机器可执行指令的其他类型的介质/机器可读介质。所述计算机可读存储介质可以是未接入计算机设备的产品,也可以是已接入计算机设备使用的部件。
综上所述,本发明的二代测序的靶向序列捕获探针设计策略选择系统,通过基于构建的探针捕获区域分类模型,根据输入的目标序列获得对应的探针捕获区域分类结果,并根据所述探针捕获区域分类结果选择与其对应的探针设计策略。本发明通过模型对靶标区域序列特征的预测,可以对不同区域进行分组,针对性地采取不同的探针设计和铺设策略,从而可以缩短后续实验的优化过程,节约时间成本;还可在实际应用中可有效提高捕获检测panel的整体性能,节约研发成本,保证临床样本的准确稳定检出。所以,本发明有效克服了现有技术中的种种缺点而具高度产业利用价值。
上述实施例仅示例性说明本发明的原理及其功效,而非用于限制本发明。任何熟悉此技术的人士皆可在不违背本发明的精神及范畴下,对上述实施例进行修饰或改变。因此,但凡所属技术领域中具有通常知识者在未脱离本发明所揭示的精神与技术思想下所完成的一切等效修饰或改变,仍应由本发明的权利要求所涵盖。
- 捕获探针的设计方法、捕获探针、捕获探针组和试剂盒
- 基于二代测序的捕获探针设计方法及应用
- 基于二代测序的捕获探针设计方法及应用