一种基于图像的视线落点估计方法、装置
文献发布时间:2023-06-19 18:35:48
技术领域
本发明涉及图像检测领域,特别地,涉及一种基于图像的视线落点估计方法。
背景技术
基于图像的视线落点估计是对图像中双目的注视点估计,即估算双目视线聚焦的落点。其一般场景是估计双目视线在一个二维平面上的注视点。这个二维平面可以是手机屏幕,pad屏幕和电视屏幕等。
现有基于图像的视线落点估计方法,大部分是对整幅面部信息进行训练来判断视线落点的位置,这引入了一些无关的信息导致最终判断结果出现偏差,同时也会使得模型更加复杂,不易训练,并且对硬件设备的要求较高,例如,需要大量的内存以及高性能CPU支持,部分方案甚至需要搭配专业的设备才能确定视线落点的位置,这导致现有基于图像的视线落点估计方法难以落地实施,在实际应用中受限。
发明内容
本发明提供了一种基于图像的视线落点估计方法,以提高视线落点估计的可实施性。
本发明提供了一种基于图像的视线落点估计方法,该方法包括:
获取图像数据,
对所述图像数据进行面部检测,得到面部检测结果,
基于面部检测结果,进行面部姿态检测,得到姿态检测结果,其中,姿态检测结果包括:符合注视姿态条件的第一姿态,和,符合非注视姿态条件的第二姿态,从具有第一姿态的姿态检测结果所对应的面部检测结果中,获取眼部区域信息,
基于眼部区域信息,进行视线落点估计,得到视线落点估计结果,
其中,
具有第二姿态的姿态检测结果所对应的面部检测结果被放弃用于进行视线落点估计。
较佳地,所述基于面部检测结果,进行面部姿态检测,包括:
基于面部检测结果,获取面部姿态角度信息,其中,面部姿态角度信息包括:用于表征面部沿上下方向俯仰的俯仰角信息、用于表征面部沿左右方向倾斜的倾斜角信息、以及用于表征面部沿前后方向扭转的扭转角信息;
根据俯仰角信息以及扭转角信息,识别第一姿态和第二姿态;
该方法进一步包括:
根据所获取的倾斜角信息,判断倾斜角是否大于设定的倾斜角阈值,如果是,则对面部检测结果进行校正。
较佳地,所述根据俯仰角信息以及扭转角信息,识别第一姿态和第二姿态,包括:
根据所获取的俯仰角信息,判断俯仰角是否在设定的俯仰角阈值内,且,根据所获取的扭转角信息,判断扭转角是否在设定的扭转角阈值内,
如果是,则判定为第一姿态,
如果俯仰角不在设定的俯仰角阈值内,或扭转角不在设定的扭转角阈值内,则判定为第二姿态;
所述对面部检测结果进行校正包括:将面部检测结果中的面部区域在左右方向上校正至水平。
较佳地,所述基于面部检测结果,获取面部姿态角度信息,包括:
对面部检测结果中的面部区域进行裁剪和归一化处理,得到预处理后的面部图像数据,
将所述预处理后的面部图像数据输入至面部关键点检测模型,利用面部关键点检测模型进行关键点检测,得到关键点位置信息,
基于关键点位置信息和面部姿态角度之间的转换关系,进行面部姿态角度计算,得到姿态角度信息,
其中,
所述转换关系包括:
由俯仰角系数、第一俯仰角参数、第二俯仰角参数所确定的俯仰角转换关系,
由扭转角系数、第一扭转角参数、第二扭转角参数所确定的扭转角转换关系,由左外眼角关键点、右外眼角关键点位置信息所确定的倾斜角转换关系;
所述俯仰角系数、扭转角系数通过关键点位置信息与面部姿态角度之间的线性拟合确定;
所述将面部检测结果中的面部区域在左右方向上校正至水平,包括:
根据面部区域中可表征面部左右方向倾斜角度的关键点信息,将面部检测结果中的面部区域在左右方向上校正至与在图像坐标系中的u方向保持平行;
其中,可表征面部倾斜角度的关键点包括具有左右对称性的关键点。
较佳地,所述对所述图像数据进行面部检测,得到面部检测结果,包括:
利用面部检测模型,对图像数据进行面部检测;
所述从具有第一姿态的姿态检测结果所对应的面部检测结果中,获取眼部区域信息,包括:
根据双瞳关键点位置信息,确定双瞳间距,
基于双瞳间距以及第一比例,确定用于裁剪眼部区域的第一尺寸,
基于双瞳间距以及第二比例,确定用于裁剪眼部区域的第二尺寸,
其中,第一比例大于第二比例,
根据双瞳关键点的位置信息,以第一尺寸和第二尺寸所确定的矩形区域,从所述面部检测结果中裁剪出眼部区域。
较佳地,所述基于面部检测结果,进行面部姿态检测,进一步包括:
在面部检测结果包括有多个面部信息的情况下,以单帧模式进行视线落点估计;
在面部检测结果未包括有面部信息或单个面部信息的情况下,以多帧模式进行视线落点估计;
所述基于眼部区域信息,进行视线落点估计,得到视线落点估计结果,包括:
在单帧模式下,利用视线落点估计模型对眼部区域进行注视识别,基于注视识别结果,确定视线落点的位置信息;
在多帧模式下,对输入视线落点估计模型并且具有眼部区域的帧数进行注视识别,在输入视线落点估计模型的帧数达到第一数量阈值、并且满足识别结果为注视识别结果所对应的眼部区域图像帧数达到设定的第二数量阈值的情况下,判定视线落点在目标区域内。
较佳地,所述视线落点估计模型包括:依次相连的第一卷积层、第一特征提取层、第二特征提取层、第三特征提取层、第四特征提取层、第五特征提取层、第六特征提取层、第七特征提取层、第八特征提取层、第九特征提取层、第十特征提取层、第二卷积层、池化层、铺平层、以及全连接层,
其中,
第一特征提取层的输出与第二特征提取层的输出进行第一合并,第一合并的结果输入至第三特征提取层,并且,第一合并结果与第三特征提取层的输出进行第二合并,第二合并的结果输入至第四特征提取层,
第四特征提取层的输出与第五特征提取层的输出进行第三合并,第三合并结果输入至第六特征提取层,并且,第三合并结果与第六特征提取层的输出进行第四合并,第四合并结果输入至第七特征提取层,并且,第四合并结果与第七特征提取层的输出进行第五合并,第五合并结果输入至第八特征提取层;
第八特征提取层的输出与第九特征提取层的输出进行第六合并,第六合并结果输入至第十特征提取层,并且,第六合并结果与第十特征提取层的输出进行第七合并,第七合并结果输入至第二卷积层,
第二卷积层的输出结果依次经池化层、铺平层、全连接层处理后,得到所述视线落点估计模型的输出结果。
较佳地,每层所述特征提取层包括n个卷积层,每个卷积层的卷积核小于等于3,其中,n为小于等于3的自然数;
所述面部检测模型、面部关键点检测模型、视线落点估计模型为训练后的模型,其中,用于训练的样本集中包括佩戴眼镜的样本图像数据。
本申请还提供了一种基于图像的视线落点估计装置,该装置包括存储器和处理器,所述存储器存储有计算机程序,所述处理器被配置为执行所述计算机程序实现任一所述视线落点估计方法的步骤。
本申请又提供了一种计算机可读存储介质,所述存储介质内存储有计算机程序,所述计算机程序被处理器执行时实现任一所述视线落点估计方法的步骤。
本申请提供的一种基于图像的视线落点估计方法,通过面部姿态检测,能够过滤到不符合注视姿态条件的姿态,降低了不必要的资源消耗,减少视线落点估计的误报,仅利用眼部区域信息来进行视线落点估计,能够充分提取眼睛区域的细节信息,响应速度快,对硬件资源的要求低。
附图说明
图1为本申请实施例基于图像的视线落点估计方法的一种流程示意图。
图2为本申请实施例基于图像的视线落点估计方法的一种流程示意图。
图3为用于描述人脸姿态的俯仰角、倾斜角、扭转角的一种示意图。
图4为确定眼部区域的一种示意图。
图5为本申请实施例视线落点估计模型结构的一种示意图。
图6为本申请实施例视线落点估计装置的一种示意图。
图7为本申请实施例视线落点估计装置的另一种示意图。
具体实施方式
为了使本申请的目的、技术手段和优点更加清楚明白,以下结合附图对本申请做进一步详细说明。
本申请基于普通RGB摄像头所拍摄的图像帧,经由面部检测获得面部区域坐标信息,通过面部姿态检测,过滤掉不符合注视姿态的面部检测结果,从符合注视姿态的面部区域中获取眼部区域信息,基于眼部区域信息进行视线落点估计。
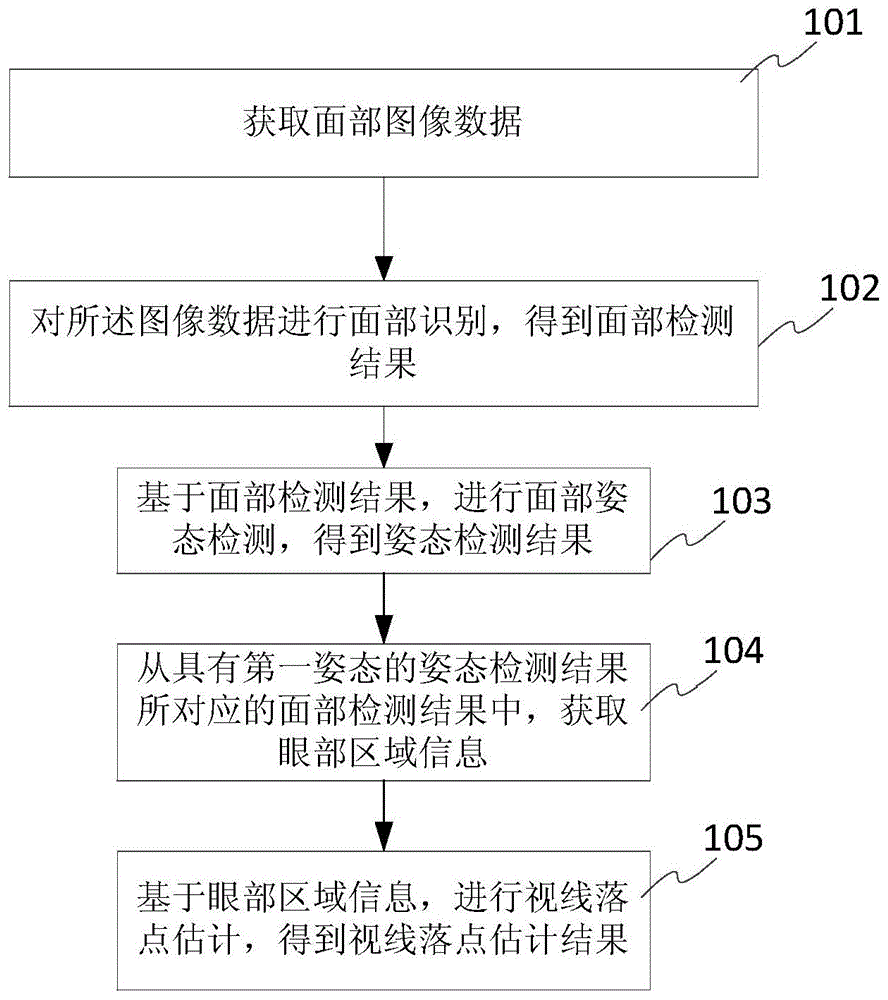
参见图1所示,图1为本申请实施例基于图像的视线落点估计方法的一种流程示意图。该方法包括:
步骤101,获取面部图像数据,
步骤102,对图像数据进行面部检测,得到面部检测结果,
步骤103,基于面部检测结果,进行面部姿态检测,得到姿态检测结果,其中,姿态检测结果包括:符合注视姿态条件的第一姿态,和,符合非注视姿态条件的第二姿态,
步骤104,从具有第一姿态的姿态检测结果所对应的面部检测结果中,获取眼部区域信息,
步骤105,基于眼部区域信息,进行视线落点估计,得到视线落点估计结果,
其中,
具有第二姿态的姿态检测结果所对应的面部检测结果被放弃用于进行视线落点估计。
本申请实施例不需要额外的硬件支撑,基于普通RGB摄像头拍摄的图像,即可快速准确地判断视线落点,是一种对注视状态进行快速响应的非接触式视线落点估计方法。当视线落点的判断应用在硬件设备上时,可通过视线注视触发设备的激活与响应,丰富了一些智能陪护产品的交互方式,可以有效提升用户体验。同时,也可作为面部识别等检测系统的前置算法,避免非注视情况下的面部识别,降低面部识别系统的资源消耗。
为便于理解本申请实施例,以下以基于人脸的图像数据来说明视线落点估计方法。
在以下实施例中,图像帧经由人脸检测模块得到人脸区域坐标以及5个关键点坐标信息,包括左眼瞳孔中心,右眼瞳孔中心,鼻尖,左嘴角,右嘴角。根据左右眼瞳孔中心坐标计算得到双瞳间距,基于双瞳间距裁剪得到包含左右眼的眼部区域信息。在进行视线落点判断之前,进行人脸姿态检测与校正,只对符合注视姿态的图像帧进行眼部区域裁剪,对不符合注视姿态的图像帧则判定为非注视姿态。基于具有注视姿态的图像帧,结合眼部区域信息进行视线落点估计,放弃对非注视姿态的图像帧进行视线落点估计。
参见图2所示,图2为本申请实施例基于图像的视线落点估计方法的一种流程示意图。该方法包括:
步骤201,获取人脸图像数据;
步骤202,对所述图像数据进行人脸检测;
作为一种示例,该步骤具体包括:
步骤2021,对所获取图像数据中的图像帧进行尺寸归一化,边界填充等预处理,并将处理后的图像数据输入至人脸检测模型,得到人脸检测模型的输出结果,该输出结果包括所检测到的人脸的检测边界框;
作为一种示例,人脸检测模型可以基于RetinaFace网络框架实现,该框架融合了特征金字塔网络(FPN)和上下文检测模块,例如SSH(Single Stage Headless)网络,FPN的引入使得模型可以适用于检测不同尺寸大小的人脸图像,更好地适应复杂的应用场景,增强算法的鲁棒性。SSH网络可以扩张预检测区域的上下文信息,使得人脸检测模型最后输出的结果更加准确。
为了防止冗余计算,删除重叠较大的检测边界框,避免出现对同一目标进行多次检测导致的资源消耗,针对人脸检测模型的输出结果进行如下处理:
步骤2022,对检测边界框进行交并比(IOU)计算,并进行非极大值抑制(NMS)处理;其中,
交并比是指两个检测边界框相交的面积除以两个检测边界框合并所占的总面积;
非极大值抑制处理是:先将所有检测边界框按照面积大小进行排序,选中最大面积的检测边界框,然后遍历其余的检测边界框,如果当前遍历的检测边界框与当前最大面积的检测边界框的IOU大于设定的交并比阈值,则删除当前遍历的检测边界框,随后从未遍历的检测边界框中继续选取下一个最大面积的检测边界框,重复上述过程。
步骤203,判断人脸检测模型的输出结果中是否是多个人脸,
如果是,则进入单帧判别模式,即,步骤204~207;
否则,则进入多帧判别模式,即,步骤210~216;
步骤204,确定目标框的位置信息。
作为一种示例,从步骤2022处理后的人脸检测模型的输出结果中,获取目标框的位置信息,
进一步地,通过人脸检测模型,还可获取关键点位置信息,包括:左眼瞳孔中心,右眼瞳孔中心,鼻尖,左嘴角,右嘴角。
步骤205,基于人脸检测结果,进行人脸姿态检测,得到姿态检测结果。
作为一种示例,检测过程包括:
步骤2051,根据目标框的位置信息,从图像帧中裁剪得到目标人脸图像;
步骤2052,对获取到的目标人脸图像进行预处理操作,包括图像尺寸归一化,数据标准化处理等一系列操作,以对图像数据进行优化;
步骤2053,将预处理后的目标人脸图像,利用人脸关键点检测模型进行人脸关键点检测,并基于人脸关键点和人脸角度之间的线性转换模型,进行人脸姿态的计算,得到用于表征人脸上下方向俯仰的俯仰角信息、用于表征人脸左右方向倾斜的倾斜角信息、以及用于表征人脸前后方向扭转的扭转角信息,分别记为yaw,roll以及pitch三个角度。参见图3所示,图3为用于描述人脸姿态的俯仰角、倾斜角、扭转角的一种示意图。
人脸关键点检测模型是基于MobileNetV3框架;根据图像帧的特点对输入至人脸关键点检测模型的输入数据进行优化,这样,基于一个轻量级的人脸关键点模型检测模型,便可得到人脸关键点信息,例如,得到106个关键点,该关键点包括有左眼瞳孔中心,右眼瞳孔中心,鼻尖,左嘴角,右嘴角;
在得到人脸关键点信息后,通过人脸角度以及关键点信息,拟合了一个线性模型。基于该线性模型可以直接得到人脸姿态yaw,roll和pitch三个维度的角度信息。
以106个人脸关键点检测为例,基于关键点和人脸角度之间的数学转换模型,进行人脸姿态角度的计算,得到yaw,pitch以及roll三个角度,转换关系用数学式表达如下:
yaw=yaw
pitch=pitch
roll=arctan((P
其中,
公式1为由扭转角系数yaw
公式2为由俯仰角系数pitch
公式3为由左外眼角关键点、右外眼角关键点位置信息所确定的倾斜角转换关系,
所述yaw
步骤2054,根据预先设定的姿态阈值来识别目标人脸是否为符合注视姿态条件的第一姿态,以便有效筛除一些明显不属于注视姿态的目标人脸,从而减少一些无用的计算,降低资源消耗。
作为一种示例,根据俯仰角信息以及扭转角信息,识别第一姿态和符合非注视姿态条件的第二姿态;例如,根据俯仰角信息判断俯仰角是否在设定的俯仰角阈值内,且根据扭转角信息判断扭转角是否在设定的扭转角阈值内,
如果是,则判定为第一姿态,
如果俯仰角不在设定的俯仰角阈值内,或扭转角不在设定的扭转角阈值内,则判定为第二姿态。
这样,就可以将仰视、俯视、扭头之一或其组合的目标人脸予以剔除而不进行视线落点估计。
步骤2055,对于目标人脸姿态为第一姿态的目标人脸,则进行姿态校正,以为视觉落点估计提供较优的数据基础,从而提高视觉落点估计的准确性。
作为一种示例,根据所获取的倾斜角信息,判断倾斜角是否大于设定的倾斜角阈值,如果是,则对面部检测结果进行校正。
校正时,可根据检测得到的可用于表征人脸左右方向倾斜角度的人脸关键点位置信息,进行倾斜角roll角度的校正,使得校正后的目标人脸图像与在图像坐标系中的u方向保持平行,例如,左右眼能够保持在同一水平线上。其中,可用于表征人脸左右方向倾斜角度的人脸关键点为具有左右对称性的关键点,包括且不限于:左右眼部关键点、左右嘴角关键点、左右鼻翼关键点至少之一。
在进行目标人脸的姿态校正后,更新目标人脸的位置信息、以及人脸关键点位置信息,为后续进行视线落点估计奠定良好的基础。
步骤206,从具有第一姿态的姿态检测结果所对应的面部检测结果中,获取眼部区域信息,
作为一种示例,基于校正后的目标人脸图像以及校正后重新计算得到的双眼瞳孔中心位置信息,根据双瞳间距,设定相对比例,进行眼部区域的图像截取;
例如,基于双瞳间距以及第一比例,确定用于裁剪眼部区域的第一尺寸,基于双瞳间距以及第二比例,确定用于裁剪眼部区域的第二尺寸,其中,第一比例大于第二比例,这样,第一尺寸便为双目连线方向上的长度,第二尺寸便为与双目连线垂直的方向上的高度;根据双瞳的位置信息,以第一尺寸和第二尺寸所确定的矩形区域,从所述目标人脸图像中裁剪出眼部区域图像。眼部区域的位置信息可用数学式表达为:
L=x±a z
H=y±b z
其中,L为第一尺寸,H为第二尺寸,x、y为双瞳连线中心的坐标,a为第一比例,b为第二比例,z为双瞳间距。
参见图4所示,图4为确定眼部区域的一种示意图。
步骤207,基于眼部区域信息,进行视线落点估计,得到视线落点估计结果,
作为一种示例,将眼部区域图像输入至视线落点估计模型中,以得到用户的视线落点估计结果,该结果可以是对视线是否落在目标区域内的判决结果,其中,视线落点估计模型可以是基于MobileNetV2框架改进的轻量级残差网络模型,在网络框架设计部分,可以是基于MobileNetV2框架进行改进的,将视线落点估计作为一个二分类的任务。
由于输入是眼睛区域信息,图像尺寸较小,原MobileNetV2模型的网络过深,因此本申请基于MobileNetV2框架进行了简化,并且重新调整了网络架构,在卷积核的尺寸设计方面仍然采用小卷积核尺寸,可以更好地提取眼睛区域的细节信息,同时有效减少了计算量以及参数量,使得最终得到的模型更加的轻量级,而残差网络结构的设计可以使得模型更加快速的收敛。
参见图5所示,图5为本申请实施例视线落点估计模型结构的一种示意图。该模型包括依次相连的第一卷积层、第一特征提取层、第二特征提取层、第三特征提取层、第四特征提取层、第五特征提取层、第六特征提取层、第七特征提取层、第八特征提取层、第九特征提取层、第十特征提取层、第二卷积层、池化层、铺平层、以及全连接层,每层特征提取层包括n个卷积层,例如n等于3,较佳地,n为小于等于3的自然数,每个卷积层的卷积核小于等于3,其中,
第一特征提取层的输出与第二特征提取层的输出进行第一合并,第一合并的结果输入至第三特征提取层,并且,第一合并结果与第三特征提取层的输出进行第二合并,第二合并的结果输入至第四特征提取层,
第四特征提取层的输出与第五特征提取层的输出进行第三合并,第三合并结果输入至第六特征提取层,并且,第三合并结果与第六特征提取层的输出进行第四合并,第四合并结果输入至第七特征提取层,并且,第四合并结果与第七特征提取层的输出进行第五合并,第五合并结果输入至第八特征提取层;
第八特征提取层的输出与第九特征提取层的输出进行第六合并,第六合并结果输入至第十特征提取层,并且,第六合并结果与第十特征提取层的输出进行第七合并,第七合并结果输入至第二卷积层,
该第二卷积层的输出结果依次经池化层、铺平层、全连接层处理后,得到该模型的输出结果,该输出结果可表征每个像素点的浮点值,所述浮点值包括两个不同浮点值。基于输出结果的分布可得到注视点的位置信息。
相比目前现有的一些采用整幅图像输入视线落点估计模型进行判断的方法,本实施例将眼睛区域作为整体图像而不拆分地输入至视线落点估计模型,这样可以让视线落点估计模型更加专注于眼睛区域特征的提取,降低无关信息的干扰,同时输入尺寸的缩小,使得资源的消耗也会更低,实时性会更好。
所应理解的是,视线落点估计模型结构可不限于此,基于该结构的变形、调整同样可以。
在以下步骤为多帧判别模式:
步骤210,判断多帧图像数据中是否有人脸图像,
如果是,则执行步骤211~213,其中,步骤211~213与步骤204~206相同,然后执行步骤214,
否则,直接执行步骤214;
步骤214,判断具有第一姿态的姿态检测结果中所具有的眼部区域的帧数是否达到设定的第一数量阈值,如果是,则执行步骤215,否则,判定为中间帧,结束本流程;
步骤215,基于每帧眼部区域信息,进行视线落点估计,得到视线落点估计结果,该步骤与步骤207相同。
步骤216,判断注视识别结果所对应的眼部区域图像的帧数是否达到设定的第二数量阈值,如果是,则基于每帧眼部区域的注视识别结果,确定视线落点的位置信息,例如,融合每帧眼部区域的注视识别结果来确定视线落点的位置信息,或者,判定视线落点在目标区域内;否则,结束本流程。
在本实施例中,人脸检测模型、人脸关键点检测模型、视线落点估计模型为训练后的模型,其中,用于训练的样本集中包括佩戴眼镜的样本图像数据,这样,本实施例对于佩戴眼镜的情况也可以进行视线落点估计,避免了用户佩戴眼镜情况下出现误报,提高了鲁棒性。
本实施例通过人脸检测、人脸姿态检测与校正以及视线落点估计进行视线落点检测,在用户注视的情况下,智能设备可以快速进行响应,丰富了用户与设备互动的方式,提升用户体验;
通过一个轻量级的人脸关键点检测模型,并根据关键点与姿态之间的线性转换模型,基于关键点得到人脸姿态三个维度的角度信息,可以快速将一些非注视情况进行滤除,在降低不必要资源消耗的同时,可以有效减少该种情况下的误报。
通过人脸检测定位左右眼瞳孔中心坐标,并根据姿态检测结果对符合要求的图像帧进行roll角度校正,再根据双瞳间距比例裁剪得到眼睛区域信息,为后续进行视线落点估计奠定了良好的基础;
通过一个轻量级的基于残差网络结构的视线落点估计模型,并且仅将眼睛区域的信息输入模型进行训练,在网络结构方面采用小卷积核尺寸来提取眼睛区域的信息,可充分提取眼睛区域的细节信息,并可根据提取到的特征信息对用户视线是否落在目标区域内进行正确判决;
多帧检测以及单帧检测两种选择模式,可以根据应用场景的不同进行模式切换,满足不同场景对不同指标的要求;
本实施例可完全采用深度学习算法的方式实现,相较于传统方式,算法具有更强的鲁棒性以及泛化能力,并且采用的都是轻量级的模型,因此算法的适用性较强。
参见图6所示,图6为本申请实施例视线落点估计装置的一种示意图。该装置包括:
图像获取模块,用于获取图像数据,
面部检测模块,用于对所述图像数据进行面部检测,得到面部检测结果,
面部姿态检测模块,用于基于面部检测结果,进行面部姿态检测,得到姿态检测结果,其中,姿态检测结果包括:符合注视姿态条件的第一姿态,和,符合非注视姿态条件的第二姿态,
视线落点估计模块,用于从具有第一姿态的姿态检测结果所对应的面部检测结果中,获取眼部区域信息,基于眼部区域信息,进行视线落点估计,得到视线落点估计结果。
该装置还包括姿态校正模块,用于根据面部姿态检测模块所获取的倾斜角信息,判断倾斜角是否大于设定的倾斜角阈值,如果是,则对面部检测结果进行校正。
该装置还包括模式选择模块,用于在面部检测结果包括有多个面部信息的情况下,以单帧模式进行视线落点估计;在面部检测结果未包括有面部信息或者包括单个面部信息的情况下,以多帧模式进行视线落点估计。
所述面部姿态检测模块被配置为基于面部检测结果,获取面部姿态角度信息,其中,面部姿态角度信息包括:用于表征面部沿上下方向俯仰的俯仰角信息、用于表征面部沿左右方向倾斜的倾斜角信息、以及用于表征面部沿前后方向扭转的扭转角信息;根据俯仰角信息以及扭转角信息,识别第一姿态和第二姿态;
所述面部姿态检测模块还被配置为根据所获取的俯仰角信息,判断俯仰角是否在设定的俯仰角阈值内,且,根据所获取的扭转角信息,判断扭转角是否在设定的扭转角阈值内,如果是,则判定为第一姿态,如果俯仰角不在设定的俯仰角阈值内,或扭转角不在设定的扭转角阈值内,则判定为第二姿态;
所述面部姿态检测模块又被配置为对面部检测结果中的面部区域进行裁剪和归一化处理,得到预处理后的面部图像数据,将预处理后的面部图像数据输入至面部关键点检测模型,利用面部关键点检测模型进行关键点检测,得到关键点位置信息,基于关键点位置信息和面部姿态角度之间的转换关系,进行面部姿态角度计算,得到姿态角度信息。
所述视线落点估计模块被配置为根据双瞳关键点位置信息,确定双瞳间距,
基于双瞳间距以及第一比例,确定用于裁剪眼部区域的第一尺寸,
基于双瞳间距以及第二比例,确定用于裁剪眼部区域的第二尺寸,
根据双瞳关键点的位置信息,以第一尺寸和第二尺寸所确定的矩形区域,从面部检测结果中裁剪出眼部区域。
所述面部检测模块被配置为利用面部检测模型,对图像数据进行面部检测。
所述视线落点估计模块被配置为在单帧模式下,利用视线落点估计模型对眼部区域进行注视识别,基于注视识别结果,确定视线落点的位置信息;
在多帧模式下,对输入视线落点估计模型并且具有眼部区域的帧数进行注视识别,在输入视线落点估计模型的帧数达到第一数量阈值、并且满足识别结果为注视识别结果所对应的眼部区域图像帧数达到设定的第二数量阈值的情况下,判定视线落点在目标区域内。
所述姿态校正模块被配置为根据面部区域中可表征面部左右方向倾斜角度的关键点信息,将面部检测结果中的面部区域在左右方向上校正至与在图像坐标系中的u方向保持平行。
参见图7所示,图7为本申请实施例视线落点估计装置的另一种示意图。该装置包括:图像采集装置、存储器以及处理器,所述存储器存储有计算机程序,所述处理器被配置为执行所述计算机程序实现任一所述视线落点估计方法的步骤。
存储器可以包括随机存取存储器(Random Access Memory,RAM),也可以包括非易失性存储器(Non-Volatile Memory,NVM),例如至少一个磁盘存储器。可选的,存储器还可以是至少一个位于远离前述处理器的存储装置。
上述的处理器可以是通用处理器,包括中央处理器(Central Processing Unit,CPU)、网络处理器(Network Processor,NP)等;还可以是数字信号处理器(Digital SignalProcessing,DSP)、专用集成电路(Application Specific Integrated Circuit,ASIC)、现场可编程门阵列(Field-Programmable Gate Array,FPGA)或者其他可编程逻辑器件、分立门或者晶体管逻辑器件、分立硬件组件。
本发明实施例还提供了一种计算机可读存储介质,所述存储介质内存储有计算机程序,所述计算机程序被处理器执行时实现任一所述视线落点估计方法的步骤。
对于装置/网络侧设备/存储介质实施例而言,由于其基本相似于方法实施例,所以描述的比较简单,相关之处参见方法实施例的部分说明即可。
在本文中,诸如第一和第二等之类的关系术语仅仅用来将一个实体或者操作与另一个实体或操作区分开来,而不一定要求或者暗示这些实体或操作之间存在任何这种实际的关系或者顺序。而且,术语“包括”、“包含”或者其任何其他变体意在涵盖非排他性的包含,从而使得包括一系列要素的过程、方法、物品或者设备不仅包括那些要素,而且还包括没有明确列出的其他要素,或者是还包括为这种过程、方法、物品或者设备所固有的要素。在没有更多限制的情况下,由语句“包括一个……”限定的要素,并不排除在包括所述要素的过程、方法、物品或者设备中还存在另外的相同要素。
以上所述仅为本发明的较佳实施例而已,并不用以限制本发明,凡在本发明的精神和原则之内,所做的任何修改、等同替换、改进等,均应包含在本发明保护的范围之内。
- 检测视线落点的方法、装置、存储介质和终端设备
- 一种基于关键点匹配的视线估计方法
- 一种基于深度学习的视线估计方法及视线估计装置
- 一种基于人眼差分图像的视线角度估计方法