一种增强遥感影像多尺度特征的自适应融合语义分割方法
文献发布时间:2023-06-19 18:35:48
技术领域
本发明涉及遥感影像语义分割技术领域,具体涉及一种增强遥感影像多尺度特征的自适应融合语义分割方法。
背景技术
遥感语义分割是在遥感图像上分割目标的同时给每个像素分配类别标签,通过遥感语义分割得到的结果可以满足城市土地管理、环境保护、和自然资源监测等应用领域对精确性的需求。
基于深度学习的遥感影像语义分割方法通常鲁棒性高,能够从大量数据中确获取知识,是遥感影像分割领域目前应用较多的手段。随着深度学习的发展,应用注意力机制改善算法效果成为主流方法。注意力机制是模仿人类处理信息时为信息分配权重的产物,它的核心是能够根据输入自适应地选择对信息进行增强或抑制。常用算法包括:SENet(参考文献1 Jie, H.; Li, S.; Gang, S.; Albanie, S. Squeeze-and-excitation networks.In Proceedings of the Proc.CVPR, 2018: 7132–7141)的核心是考虑模型中不同通道间的响应关系,通过压缩激励块为通道分配权重。DANet(参考文献2 Fu, J.; Liu, J.;Tian, H.; Li, Y.; Bao, Y.; Fang, Z.; Lu, H. Dual attention network for scenesegmentation. In Proceedings of the Proc. IEEE Conf. Comput. Vis. PatternRecognit., 2019: 3141-3149)则是对位置关系和通道关系都进行建模,从而获得特征的远程依赖关系。参考文献3 Li, S.; Liao, C.; Ding, Y.; Hu, H.; Jia, Y.; Chen, M.;Xu, B.; Ge, X.; Liu, T.; Wu, D. Cascaded Residual Attention Enhanced RoadExtraction from Remote Sensing Images. ISPRS International Journal of Geo-Information. 2022, 11, 9,将注意力机制和残差思想融合在模型中,用以提升在遥感影像上进行道路语义分割的精度。参考文献4 Panboonyuen, T.; Jitkajornwanich, K.;Lawawirojwong, S.; Srestasathiern, P.; Vateekul, P. Semantic segmentation onremotely sensed images using an enhanced global convolutional network withchannel attention and domain specific transfer learning. Remote Sens. 2019,11, 83,将注意力机制和迁移学习应用与全卷积深度学习模型,改善了遥感影像语义分割的效果。参考文献5张越,程春泉,杨书成,高瑞,常亚茹.融合双注意力机制模型的遥感影像建筑物提取[J].测绘科学,2022,47(04):129-136+174,融合双注意力机制(空间和通道)和残差模块,用于改善建筑物语义分割的准确性。参考文献6张津,魏峰远,冯凡,焦利伟,麻连伟.基于注意力机制和编码解码网络的遥感影像分类[J].测绘科学技术学报,2020,37(06):610-615,在注意力机制的基础上发展了一种特征精化模块,用于对特征进行精化重构,从而提升遥感影像语义分割精度。
上述算法主要侧重于应用注意力机制对特征图的通道关系和空间关系建模,而面向遥感影像中多种不同尺度的地物类型和特征复杂的目标时,难以实现同时对大尺度目标和小尺度目标的精确分割以及特征复杂地物边缘的完整提取。
因此,提供一种增强遥感影像多尺度特征的自适应融合语义分割方法,以解决上述存在的问题。
发明内容
本发明的目的是提供一种增强遥感影像多尺度特征的自适应融合语义分割方法,实现了跳跃连接与多种注意力机制(多尺度注意力、空间注意力、位置注意力)的融合,以提升多尺度特征识别和精确特征表达的能力。该方法在面向遥感影像中存在多尺度地物目标和特征复杂的地物时,能够实现高精度的语义分割。
本发明的目的是这样实现的:
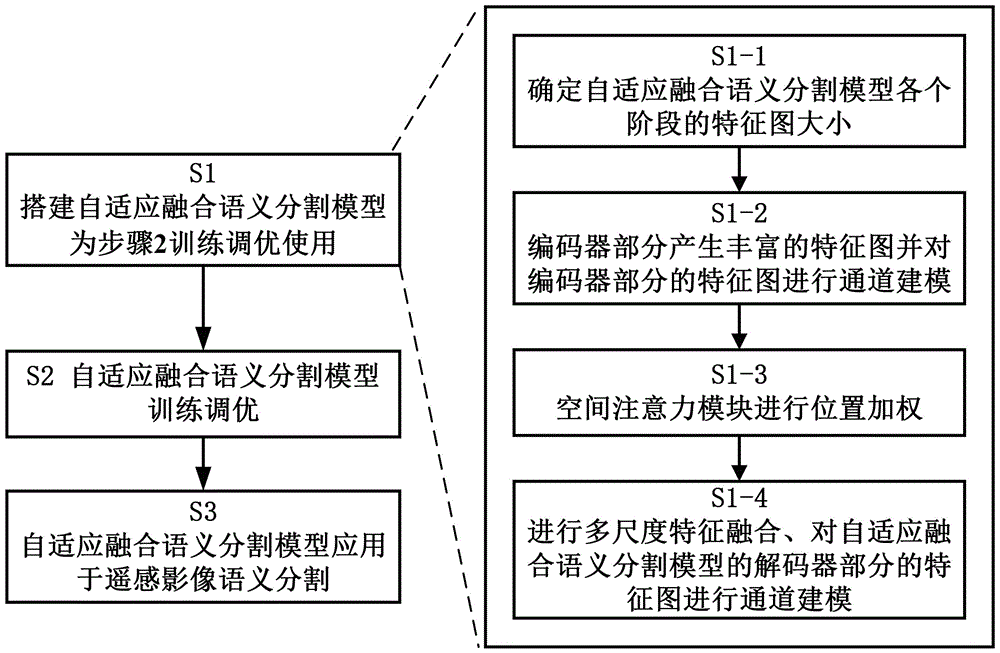
一种增强遥感影像多尺度特征的自适应融合语义分割方法,包括以下步骤:步骤1:搭建自适应融合语义分割模型,为步骤2训练调优使用;根据输入确定各阶段特征图的大小,构建自适应融合语义分割模型的核心模块,并确定核心模块内部对输入特征图的处理流程与各模块在模型中的使用位置,完成对自适应融合语义分割模型的搭建;核心模块包括通道注意力卷积块、空间注意力模块和自适应特征融合模块;通道注意力卷积块通过卷积组操作和压缩-激励操作对通道进行建模,空间注意力模块对位置进行加权,自适应特征融合模块对输入特征图进行融合;自适应融合语义分割模型的编码器部分使用了通道注意力卷积块和池化操作,自适应融合语义分割模型的解码器部分使用了通道注意力卷积块、自适应特征融合模块和上采样操作;具体的操作步骤如下:
步骤S1-1:确定自适应融合语义分割模型各个阶段的特征图大小;根据将要输入自适应融合语义分割模型的遥感影像尺寸确定自适应融合语义分割模型各个组成部分的大小;
步骤S1-2:编码器部分产生丰富的特征图并对编码器部分的特征图进行通道建模;产生的特征图将在步骤S1-3和S1-4进一步处理,编码器部分通过通道注意力卷积块和池化操作,完成对输入图像四次降采样和特征升维,得到尺寸小于原始大小的1024维的特征图,同时完成对自适应融合语义分割模型的编码器部分的特征图进行通道维的建模;具体的,通道注意力卷积块包括两次卷积组操作和一次压缩-激励操作串行,其中一次卷积组操作包括卷积-批标准化-Relu激活操作,在此过程中生成的5组特征图供自适应融合语义分割模型后续操作使用;
步骤S1-3:空间注意力模块进行位置加权;步骤S1-2得到的最后一组特征图输入空间注意力模块,得到对不同空间位置加权后的特征图;空间注意力模块根据输入特征图本身的值为每个位置赋予权重,此过程不改变特征图的维度和大小;
步骤S1-4:进行多尺度特征融合、对自适应融合语义分割模型的解码器部分的特征图进行通道建模,以达到增强多尺度特征和优化分割效果;解码器部分通过自适应特征融合模块、通道注意力卷积块和上采样操作,对步骤S1-2,步骤S1-3得到的特征图进行多次融合和对自适应融合语义分割模型的解码器部分的特征图进行通道建模,并能够增强被融合的多尺度特征,输出为与原始输入大小相同的语义分割结果图;具体操作如下,跳跃连接操作和自适应特征融合模块将当前特征图与编码器部分的特征图块融合,并为每个特征图块分配权重;上采样操作将特征图大小恢复至自适应融合语义分割模型输入影像相同大小便于输出最终语义分割结果。
步骤2:自适应融合语义分割模型训练调优;通过Potsdam数据集对步骤1搭建的自适应融合语义分割模型进行训练调优,参数优化后的自适应融合语义分割模型在步骤3应用;Potsdam数据集中存在多尺度目标和特征复杂的类型;具体的,将数据集分为训练集与测试集,按批次输入训练集数据计算损失值,通过损失值和优化器更新自适应融合语义分割模型参数,直到自适应融合语义分割模型的损失值不再下降;
步骤3:自适应融合语义分割模型应用于遥感影像语义分割;将步骤2调优后的自适应融合语义分割模型应用于遥感影像语义分割,调优后的自适应融合语义分割模型参数经过多次更新,此时自适应融合语义分割模型对分割多尺度特征的地物和特征复杂的地物有好的表现,将测试数据按照与训练数据相同的批次大小输入调优后的自适应融合语义分割模型输出对应的分割图,计算自适应融合语义分割模型输出结果的精度评价指标MIoU并进行自适应融合语义分割模型效果的可视化比较。
所述步骤S1-2中的压缩-激励操作具体为全局平均池化-全连接层-Relu激活层-全连接层-Sigmoid激活层串行;输入特征图通过上述串行操作后得到的特征图与原始特征图进行加法操作作为通道注意力卷积块的最终输出,类似的,该过程不改变输入特征图的大小和维数。
所述步骤S1-3中的空间注意力模块进行位置加权,包括4个步骤;步骤S1-3-1,对输入特征图F进行卷积操作,得到3个特征图A、B、C;特征图A、B、C的大小为H×W×C,H表示高度,W表示宽度,C表示通道数;步骤S1-3-2,通过重塑和转置将特征图A的形状变为N×C,N=H×W,通过重塑将特征图B的size变为C×N,对特征图A和特征图B进行矩阵乘法和Softmax激活得到大小为N×N的注意力权重图;步骤S1-3-3,通过重塑将特征图C的形状变为C×N,并与步骤S1-3-2得到的注意力权重图进行矩阵乘法,得到优化后的特征图;步骤S1-3-4,对优化后的特征图进行重塑操作并和原始特征图进行加法操作得到空间注意力模块的最终输出。
步骤S1-4中,对特征图的处理包括4个步骤,步骤S1-4-1,不同阶段特征图尺寸不同,对每个特征图块进行上采样或下采样,获得相同大小的特征图块;步骤S1-4-2,对每个特征图块进行通道降维,通过1*1卷积将所有卷积块降维至单通道;步骤S1-4-3,对单通道特征图进行池化、Relu激活得到表示每个通道的单值,接着将单值输入进全连接层、并进行Relu激活、然后再次输入全连接层、并进行Softmax激活,得到每个特征图块的权重值,步骤S1-4-4,将步骤S1-4-3得到的权重值与对应特征图块进行乘法操作得到自适应特征融合模块的输出结果。
所述步骤2中,训练调优过程中应用的损失函数是交叉熵损失,由其衡量模型输出的结果与真实标签的差距,并根据交叉熵损失值通过梯度下降算法进行模型参数更新,交叉熵损失的计算形式为:
其中
本发明的有益效果是:(1)达到了增强多尺度特征的效果。自适应融合语义分割模型中的自适应特征融合模块考虑了不同尺度特征间的差异,能够进行自适应权重分配,能够根据地物的尺度大小增强对应的特征,从而提升同时分割多尺度目标的精度;
(2)改善了具有复杂特征的易混淆目标地物的分割效果。提供的模型为编码器-解码器结构,通过跳跃连接使得编码器与解码器之间存在密集的信息流从而达到特征的多次融合,获得精确的特征表示,提升语义分割的特征融合能力,以改善复杂特征的地物分割效果;
(3)实现了较高精度的遥感影像像素级语义分割。通过特征的通道和空间位置建模,进一步优化自适应融合语义分割模型,在MIoU方面比DeepLabV3+提高了1.36%。
附图说明
图1为本发明步骤图;
图2为本发明提供的自适应融合语义分割模型总框架结构图;
图3为本发明自适应融合语义分割模型中的通道注意力卷积块示意图,左侧为通道注意力卷积块总框架结构图,右侧为压缩-激励操作示意图;
图4为本发明的空间注意力模块示意图;
图5为本发明的自适应特征融合模块示意图;
图6为本发明实施例的输入遥感影像样例示意图;
图7为本发明实施例的输出遥感影像结果图。
具体实施方式
以下结合附图和实施例对本发明作进一步说明。
如图1所示,一种增强遥感影像多尺度特征的自适应融合语义分割方法,包括以下步骤:步骤1:搭建自适应融合语义分割模型,为步骤2训练调优使用;自适应融合语义分割模型总框架如图2;根据输入确定各阶段特征图的大小,构建自适应融合语义分割模型的核心模块,并确定核心模块内部对输入特征图的处理流程与各模块在模型中的使用位置,完成对自适应融合语义分割模型的搭建;核心模块包括通道注意力卷积块、空间注意力模块和自适应特征融合模块;通道注意力卷积块通过卷积组操作和压缩-激励操作对通道进行建模,空间注意力模块对位置进行加权,自适应特征融合模块对输入特征图进行融合;自适应融合语义分割模型的编码器部分使用了通道注意力卷积块和池化操作,自适应融合语义分割模型的解码器部分使用了通道注意力卷积块、自适应特征融合模块和上采样操作;具体的;
步骤S1-1:确定自适应融合语义分割模型各个阶段的特征图大小;根据将要输入自适应融合语义分割模型的遥感影像尺寸确定自适应融合语义分割模型各个组成部分的大小;
步骤S1-2:编码器部分产生丰富的特征图并对编码器部分的特征图进行通道建模;产生的特征图将在步骤S1-3和S1-4进一步处理,编码器部分通过通道注意力卷积块和池化操作,完成对输入图像四次降采样和特征升维,得到尺寸小于原始大小的1024维的特征图,同时完成对自适应融合语义分割模型的编码器部分的特征图进行通道维的建模;具体的,通道注意力卷积块包括两次卷积组操作和一次压缩-激励操作串行,其中一次卷积组操作包括卷积-批标准化-Relu激活操作,在此过程中生成的5组特征图供自适应融合语义分割模型后续操作使用;自适应融合语义分割模型中的通道注意力卷积块如图3;步骤S1-2中的压缩-激励操作具体为全局平均池化-全连接层-Relu激活层-全连接层-Sigmoid激活层串行;输入特征图通过上述串行操作后得到的特征图与原始特征图进行加法操作作为通道注意力卷积块的最终输出,类似的,该过程不改变输入特征图的大小和维数。
步骤S1-3:空间注意力模块进行位置加权。步骤S1-2得到的最后一组特征图输入空间注意力模块,得到对不同空间位置加权后的特征图;空间注意力模块根据输入特征图本身的值为每个位置赋予权重,此过程不改变特征图的维度和大小;步骤S1-3中的空间注意力模块,如图4,包括4个步骤;步骤S1-3-1,对输入特征图F进行卷积操作,得到3个特征图A、B、C;特征图A、B、C的大小为H×W×C,H表示高度,W表示宽度,C表示通道数,步骤S1-3-2,通过重塑和转置将特征图A的形状变为N×C,N=H×W,通过重塑将特征图B的size变为C×N,对特征图A和特征图B进行矩阵乘法和Softmax激活得到大小为N×N的注意力权重图;步骤S1-3-3,通过重塑将特征图C的形状变为C×N,并与步骤S1-3-2得到的注意力权重图进行矩阵乘法,得到优化后的特征图;步骤S1-3-4,对优化后的特征图进行重塑操作并和原始特征图进行加法操作得到空间注意力模块的最终输出。
步骤S1-4:进行多尺度特征融合、对自适应融合语义分割模型的解码器部分的特征图进行通道建模,以达到增强多尺度特征和优化分割效果;解码器部分通过自适应特征融合模块、通道注意力卷积块和上采样操作,对步骤S1-2,步骤S1-3得到的特征图进行多次融合和对自适应融合语义分割模型的解码器部分的特征图进行通道建模,并能够增强被融合的多尺度特征,输出为与原始输入大小相同的语义分割结果图;具体操作如下,跳跃连接操作和自适应特征融合模块将当前特征图与编码器部分的特征图块融合,并为每个特征图块分配权重;上采样操作将特征图大小恢复至自适应融合语义分割模型输入影像相同大小便于输出最终语义分割结果。步骤S1-4中的自适应特征融合模块,如图5,对特征图的处理包括4个步骤,步骤S1-4-1,不同阶段特征图尺寸不同,对每个特征图块进行上采样或下采样,获得相同大小的特征图块;步骤S1-4-2,对每个特征图块进行通道降维,通过1*1卷积将所有卷积块降维至单通道;步骤S1-4-3,对单通道特征图进行池化、Relu激活得到表示每个通道的单值,接着将单值输入进全连接层、并进行Relu激活、然后再次输入全连接层、并进行Softmax激活,得到每个特征图块的权重值,步骤S1-4-4,将步骤S1-4-3得到的权重值与对应特征图块进行乘法操作得到自适应特征融合模块的输出结果
步骤2:自适应融合语义分割模型训练调优;通过Potsdam数据集对步骤1搭建的自适应融合语义分割模型进行训练调优,参数优化后的自适应融合语义分割模型在步骤3应用;Potsdam数据集中存在多尺度目标和特征复杂的类型;具体的,将数据集分为训练集与测试集,按批次输入训练集数据计算损失值,通过损失值和优化器更新自适应融合语义分割模型参数,直到自适应融合语义分割模型的损失值不再下降,训练调优过程中应用的损失函数是交叉熵损失,由其衡量模型输出的结果与真实标签的差距,并根据交叉熵损失值通过梯度下降算法进行模型参数更新,交叉熵损失的计算形式为:
其中
步骤3:自适应融合语义分割模型应用于遥感影像语义分割。将步骤2调优后的自适应融合语义分割模型应用于遥感影像语义分割,调优后的自适应融合语义分割模型参数经过多次更新,此时自适应融合语义分割模型对分割多尺度特征的地物和特征复杂的地物有很好的表现,将测试数据按照与训练数据相同的批次大小输入调优后的自适应融合语义分割模型输出对应的分割图,计算自适应融合语义分割模型输出结果的精度评价指标MIoU并进行自适应融合语义分割模型效果的可视化比较,输入样例及输出语义分割结果如图6、图7。为了验证自适应融合语义分割模型增强多尺度特征的效果,分别选取了图6中左上和左下的大尺度的建筑物以及右上的小尺度的汽车,通过自适应融合语义分割模型得到了图7的左上、左下及右上的语义分割结果,其结果表明自适应融合语义分割模型准确分割建筑物和汽车。为了验证自适应融合语义分割模型改善复杂特征的地物分割效果,选取了图6右下的样例,以特征复杂且易混淆的低矮植被和树木为输入样例,通过自适应融合语义分割模型得到了图7右下的结果,其结果表明自适应融合语义分割模型可以准确区分并分割低矮植被和树木。图7中语义分割结果还表明了多尺度和易混淆的复杂地物目标的分割均完整连续。
具体的应用实施例如下:
本实施例将6750张400*400的4通道遥感影像作为训练数据,1800张400*400的4通道遥感影像作为测试数据。遥感影像当中的目标被分为6类,包括:不透水面,建筑物,低矮植被,树木,汽车,背景。具体的,本实施例的具体步骤为:
步骤1:搭建自适应融合语义分割模型为步骤2训练调优使用。根据输入确定各阶段特征图的大小,构建自适应融合语义分割模型的核心模块,并确定核心模块内部对输入特征图的处理流程与各模块在模型中的使用位置,完成对自适应融合语义分割模型的搭建。
步骤S1-1:确定自适应融合语义分割模型各个阶段的特征图大小。由于模型输入图像大小为400*400,即附图2中的H=W=400,则自适应融合语义分割模型编码器部分的特征图块依次为400*400*64、200*200*128、100*100*256、50*50*512、25*25*1024,自适应融合语义分割模型解码器部分的特征图依次为50*50*512、100*100*256、200*200*128、400*400*64。
步骤S1-2:编码器部分产生丰富的特征图并对编码器部分的特征图进行通道建模。具体地,首先通过卷积操作将输入特征图通道数提升为64,后续对特征图的尺寸进行了四次调整,编码器部分的输出尺寸为25*25*1024。进一步的,编码器部分包括5个通道注意力卷积块,即在通过卷积、批标准化、激活和池化操作改变特征图尺寸大小的同时,也通过压缩-激励操作对自适应融合语义分割模型的编码器部分的特征图进行了通道维的建模。这使得自适应融合语义分割模型拥有在后续调优时能够自动强调对语义分割任务有益的特征通道的能力。
步骤S1-3:空间注意力模块进行位置加权。将步骤S1-2得到的最后一组特征图输入空间注意力模块,得到对不同空间位置加权后的特征图。通过空间注意力模块会对编码器部分输出的特征图进行空间位置的权重分配。进一步的,空间注意力模块的具体操作是:S1-3-1,分别对输入特征图进行卷积操作,得到三组特征图A、B、C,本实施例中它们的尺寸均与输入尺寸相同,为25*25*1024;步骤S1-3-2,通过张量转置和重塑操作将A的尺寸调整为625*1024,将B的尺寸调整为1024*625,对A和B进行矩阵乘法操作,得到尺寸大小为625*625的张量,对其进行Softmax激活即得到空间位置注意力权重图;步骤S1-3-3,通过张量转置和重塑操作将特征图C的尺寸调整为1024*625,并与步骤S1-3-2得到的空间位置注意力权重图进行矩阵乘法,即得到优化后的注意力权重图,尺寸为1024*625;步骤S1-3-4,通过重塑将上一步得到的特征图尺寸调整为25*25*1024,并与此模块的原始输入进行张量加法得到输出特征图,尺寸同样为25*25*1024。
步骤S1-4:进行多尺度特征融合、对自适应融合语义分割模型的解码器部分的特征图进行通道建模。解码器部分通过自适应特征融合模块、通道注意力卷积块和上采样操作,对步骤S1-2,步骤S1-3得到的特征图进行多次融合和对自适应融合语义分割模型的解码器部分的特征图进行通道建模,并增强被融合的多尺度特征,最终输出为与自适应融合语义分割模型原始输入影像大小的语义分割结果图。本实施例中,自适应特征融合模块需要处理5组特征图{B1、B2、B3、B4、B5},自适应融合语义分割模型的解码器部分共应用4次自适应特征融合模块和通道注意力卷积块,以此获得强大的自适应融合特征和增强多尺度特征的能力。
步骤2:自适应融合语义分割模型训练调优。通过Potsdam数据集对步骤1搭建的自适应融合语义分割模型进行训练调优,参数优化后的自适应融合语义分割模型在步骤3应用;为了增强自适应融合语义分割模型的鲁棒性,将输入的影像进行随机翻转,将输入数据集转化为批次大小为8的张量,即单次输入自适应融合语义分割模型的张量大小为8*400*400*3;将交叉熵损失作为目标损失函数,通过Adam优化器进行梯度下降达到参数更新的效果。
步骤3:自适应融合语义分割模型应用于遥感影像语义分割。将步骤2调优后的自适应融合语义分割模型应用于遥感影像语义分割,应用调优后的自适应融合语义分割模型对测试数据进行语义分割,输出张量的值类型包括:0,1,2,3,4,5,分别与数据中6类目标对应。
综合上述过程,本发明提供的自适应融合语义分割模型在未应用任何预训练权重的情况下,获得71.44%MIoU,与DeepLabV3+(70.08%MIoU)相比,自适应融合语义分割模型获得更好的语义分割精度和同时分割多尺度目标的效果。
- 一种共享多尺度对抗特征的高分遥感影像语义分割方法
- 一种自注意力多尺度特征融合的遥感图像语义分割方法