一种用于语义分割的对比学习方法及系统
文献发布时间:2023-06-19 18:37:28
技术领域
本发明涉及目标分割技术领域,尤其涉及一种用于语义分割的对比学习方法及系统。
背景技术
语义分割是一项基本的计算机视觉任务,需要对给定图像进行逐像素预测。近年来,随着深度神经网络的发展,语义分割取得了显著进展。然而,由于域转移问题,当测试数据的分布与训练数据不同时,最先进的方法仍然存在显著的性能下降。同时,在目标域中标记像素级大规模语义分割既耗时又昂贵。所以亟需更好的方法用于语义分割。
现多数研究技术人员由于技术的原因,语义分割方法还是采用基于对抗训练的方法,而这些检测的方法存在以下问题:(1)不能保证目标域中属于不同语义类别的像素能够很好地分离,模型的泛化能力差。(2)没有考虑源域和目标域之间表征结构的一致性,不能从源域中标记的数据中学到充分的表示。
发明内容
本发明的第一目的在于提出一种用于语义分割的对比学习方法,通过引入不同类别特征的约束,并采用对比的学习方法用于语义分割,使分割模型取得了比较好的性能。
本发明的第二目的在于提出一种用于语义分割的对比学习系统。
为达此目的,本发明采用以下技术方案:
一种用于语义分割的对比学习方法,包括以下步骤:
S1、以有监督的方式在标记的源域上训练分割模型;其中分割模型由特征提取器F和分类器C组成;
S2、获得在标记的源域上训练的分割模型,对分割模型进行初始化;
S3、执行对比度适应操作:给定目标域的图像,通过分类器产生伪标签和特征提取器提取相应的特征,将伪标签提取的特征和其对应的分割模型对应,再计算特征
S4、根据损失,用混合域方式更新分割模型,得到更新后的分割模型。
优选的,在S1前,还包括S0、设定模型参数操作,其中模型参数包括初始学习率、动量、权重衰减速率、学习速率和目标域的伪标签阈值。
优选的,在S2中,所述对分割模型进行初始化,包括采用初始化公式对分割模型进行初始化,所述初始化公式表示为:
式中,
优选的,在S3中,所述计算特征和每个对应的分割模型之间的损失,包括采用标准交叉熵公式计算特征和每个对应的分割模型之间的损失,所述标准交叉熵公式表示为:
式中,N
优选的,在S4中,所述用混合域方式更新分割模型,包括采用混合域更新公式更新分割模型,所述混合域更新公式表示为:
式中,m是一个超参数,它定义为训练期间源模型和目标模型更新的恒定速率;
一种用于语义分割的对比学习系统,采用如上述所述的一种用于语义分割的对比学习方法,包括:
模型训练模块,用于以有监督的方式在标记的源域上训练分割模型;
初始化模块,用于获得在标记的源域上训练的分割模型,对分割模型进行初始化;
特征对应模块,用于执行对比度适应操作:给定目标域的图像,通过分类器产生伪标签和特征提取器提取相应的特征,将伪标签提取的特征和其对应的分割模型对应,再计算特征和每个对应的分割模型之间的相似性和损失;
混合更新模块,根据损失,用混合域方式更新分割模型,得到更新后的分割模型。
优选的,还包括设定参数模块,所述设定参数模块用于执行设定模型参数操作。
优选的,所述初始化模块包括初始化子模块,所述初始化子模块用于执行采用初始化公式对分割模型进行初始化,所述初始化公式表示为:
式中,
优选的,所述特征对应模块包括特征对应子模块,所述特征对应子模块用于执行采用标准交叉熵公式计算特征和每个对应的分割模型之间的损失,所述标准交叉熵公式表示为:
式中,N
优选的,所述混合更新模块包括混合更新子模块,所述混合更新子模块用于执行采用混合域更新公式更新分割模型,所述混合域更新公式表示为:
式中,m是一个超参数,它定义为训练期间源模型和目标模型更新的恒定速率;
上述技术方案中的一个技术方案具有以下有益效果:不仅能够证目标域中属于不同语义类别的像素能够很好地分离,从而提高模型的泛化能力,而且考虑到源域和目标域之间表征结构的一致性,能从源域中标记的数据中学到充分的表示,使分割模型取得优越的语义分割性能。
附图说明
图1是本发明在一种用于语义分割的对比学习方法的流程示意图;
图2是本发明在一种用于语义分割的对比学习系统的结构示意图;
附图中:模型训练模块1、初始化模块2、特征对应模块3、混合更新模块4、设定参数模块5。
具体实施方式
下面结合附图并通过具体实施方式来进一步说明本发明的技术方案。
如图1所示,一种用于语义分割的对比学习方法,包括以下步骤:
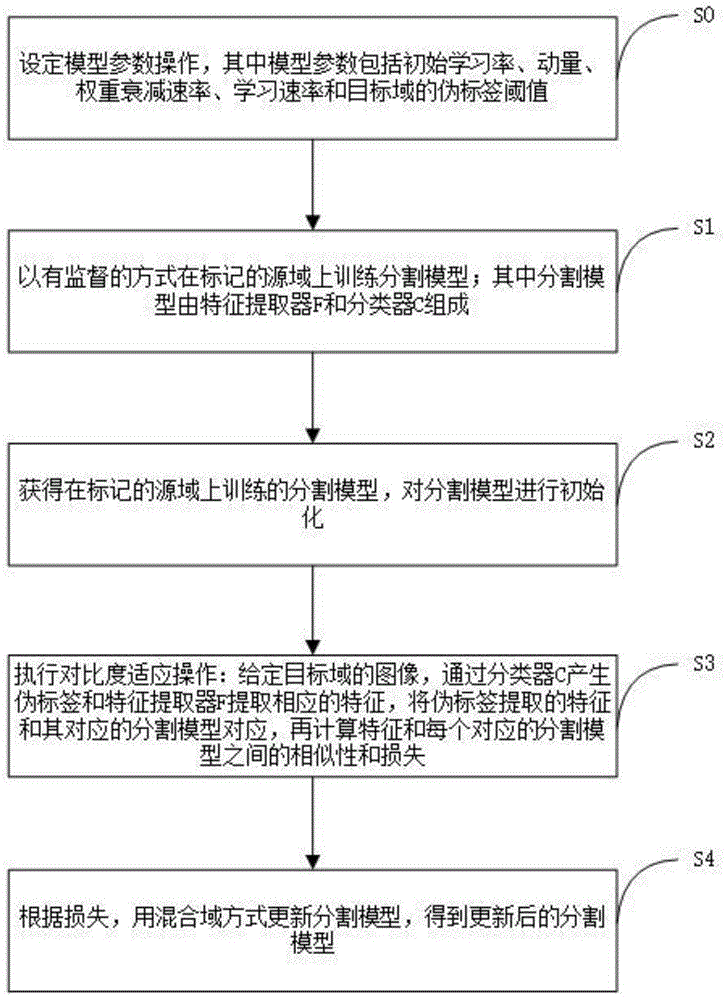
S0、设定模型参数操作,其中模型参数包括初始学习率、动量、权重衰减速率、学习速率和目标域的伪标签阈值。在具体的实施例中,实验数据集为GTA5,训练时采用SGD优化器,初始学习率为2.5*10-4,动量为0.9,权重衰减速率为5.0*10-4,使用幂为0.9的多项式调节学习速率。在S3中,目标域的伪标签阈值设置为0.9。
S1、以有监督的方式在标记的源域上训练分割模型;其中分割模型由特征提取器F和分类器C组成;
S2、获得在标记的源域上训练的分割模型,对分割模型进行初始化;
S3、执行对比度适应操作:给定目标域的图像,通过分类器C产生伪标签和特征提取器F提取相应的特征,将伪标签提取的特征和其对应的分割模型对应,再计算特征和每个对应的分割模型之间的相似性和损失;
S4、根据损失,用混合域方式更新分割模型,得到更新后的分割模型。
本发明提供了一种用于语义分割的对比学习方法,该方法首先以有监督的方式在有标记的源域上训练分割模型,其中分割模型由特征提取器F和分类器C组成,用于预测给定图像的像素级预测;其次初始化多个分割模型以表示每个类别;然后采用对比自适应操作来约束类间关系;最后根据损失函数,在源域和目标域上用混合域方式更新模型,以增强域不变表示。更新后的分割模型就可以用于分割,分割效果更好,更新次数是多次,获取损失较小下的模型。
通过本方法,不仅能够证目标域中属于不同语义类别的像素能够很好地分离,从而提高模型的泛化能力,而且考虑到源域和目标域之间表征结构的一致性,能从源域中标记的数据中学到充分的表示,使分割模型取得优越的语义分割性能。
更进一步的说明,在S2中,所述对分割模型进行初始化,包括采用初始化公式对分割模型进行初始化,所述初始化公式表示为:
式中,
更进一步的说明,在S3中,所述计算特征
式中,N
更进一步的说明,在S4中,所述用混合域方式更新分割模型,包括采用混合域更新公式更新分割模型,所述混合域更新公式表示为:
式中,m是一个超参数,它定义为训练期间源模型和目标模型更新的恒定速率;
一种用于语义分割的对比学习系统,采用如上述所述的一种用于语义分割的对比学习方法,包括:
设定参数模块5,用于执行设定模型参数操作;
模型训练模块1,用于以有监督的方式在标记的源域上训练分割模型;
初始化模块2,用于获得在标记的源域上训练的分割模型,对分割模型进行初始化;
特征对应模块3,用于执行对比度适应操作:给定目标域的图像,通过分类器C产生伪标签和特征提取器F提取相应的特征
混合更新模块4,根据损失,用混合域方式更新分割模型,得到更新后的分割模型。
通过本系统,不仅能够证目标域中属于不同语义类别的像素能够很好地分离,从而提高模型的泛化能力,而且考虑到源域和目标域之间表征结构的一致性,能从源域中标记的数据中学到充分的表示,使分割模型取得优越的语义分割性能。
更进一步的说明,所述初始化模块2包括初始化子模块,所述初始化子模块用于执行采用初始化公式对分割模型进行初始化,所述初始化公式表示为:
式中,
更进一步的说明,所述特征对应模块3包括特征对应子模块,所述特征对应子模块用于执行采用标准交叉熵公式计算特征
式中,N
更进一步的说明,所述混合更新模块4包括混合更新子模块,所述混合更新子模块用于执行采用混合域更新公式更新分割模型,所述混合域更新公式表示为:
式中,m是一个超参数,它定义为训练期间源模型和目标模型更新的恒定速率;
以上结合具体实施例描述了本发明的技术原理。这些描述只是为了解释本发明的原理,而不能以任何方式解释为对本发明保护范围的限制。基于此处的解释,本领域的技术人员不需要付出创造性的劳动即可联想到本发明的其它具体实施方式,这些等同的变型或替换均包含在本申请权利要求所限定的范围内。