一种面向电信欺诈案件受害者的人格特征检测方法
文献发布时间:2023-06-19 18:37:28
技术领域
本发明属于人格特征预测领域,具体涉及一种面向电信欺诈案件受害者的人格特征检测方法。
背景技术
传统刑侦方式从犯罪手段层面进行分析,不利于理解犯罪的案发规律,对欺诈案件的防范具有一定的滞后性。而每位欺诈受害者在被欺诈过程中都有不同的心理特质,从欺诈犯罪心理层面对犯罪行为进行探究,可以深入理解被欺诈时受害者的心理状态。而人格特征是一个人所有行为、动机、思维方式以及情绪的组合特性,对于每个人平时的所做选择以及生活都产生了巨大的影响。通过得到各类案件中受害者的人格特征,能分析出各类型受害者对何种引诱信息具有偏好,进而从普通民众的心理层面采取相应措施防范欺诈案件的发生。目前已有一些研究通过文本信息分析用户人格特征,但是这些研究大多基于词频法,矩阵分解以及主题模型等方法。这些方法的局限性在于检测性能依赖于研究者的先验知识,对于复杂样本的检测缺少可靠性。还有一些研究者提出了基于深度学习的人格特征检测,比如分层CNN模型以及多任务学习等方法。虽然这些方法在精度上有了较大的提升,但是这些方法在不同群体的样本检测中精度差异性较大,存在可解释性较差的情况。
发明内容
为解决上述技术问题,本发明提出一种面向电信欺诈案件受害者的人格特征检测方法,包括:
S1,对案件文本数据信息进行预处理;
S2,按照预定义的脱敏规则对预处理后的数据信息进行隐私保护处理;
S3、建立人格特征检测模型,将隐私保护处理后的数据信息输入人格特征检测模型获取相应的大五人格特征得分。
优选的,对案件文本数据信息进行预处理,包括:利用Python内置的jieba 库对案件文本信息数据进行停用词处理。
优选的,对数据隐私保护处理,包括:
S21:建立自定义的脱敏规则;
所述脱敏规则包括:剔除案件文本信息中的身份证号、电话号码以及住址等用户隐私信息;
S22:通过建立的脱敏规则对数据信息的文本进行脱敏处理。
优选的,所述人格特征检测模型,包括:Bert层、多分类层;
所述多分类层:组合多个二分类器,得到多分类器,并预设五大人格特征,将数据输入多分类器,实现五大人格的分类;
所述五大人格特征包括:外向性、神经质性、宜人性、尽责性、开放性。
优选的,将隐私保护处理后的数据信息输入人格特征检测模型获取相应的大五人格特征得分,包括:
S31:将隐私处理之后的数据信息输入到Bert层中进行文档划分,将数据信息的文档长度大于512的进行截断,文档长度不足512的用无用词填充,并转换为句向量;
S32:将句向量与Francois Mairesse开发的具有84个特征组成的人格特征检测数据集进行连接,得到整个案件信息的文档特征向量;
S33:将整个案件信息的文档特征向量输入多分类层,第一层SVM分类器中进行二分类判断,得出人格特征的偏好得分,根据偏好得分判断是否属于五大人格的某种人格特征,如果不是就再输入到下一层SVM中进行相应的判断,直至判断出相应的大五人格特征为止;
S34:将多分类层的输出的对应人格的人格特征偏好得分取平均数,得到最终的人格特征的偏好得分。
进一步的,Bert层将数据信息转换为词向量,包括:
通过从输入数据信息的一句话中提取15%的次进行预测,同时随机抹除部分数据,将这些数据以80%的概率使用特殊符号[MASK]进行替换,10%的概率使用任意词替换,剩下的10%概率保持原词不变,得到将数据信息转化为具有上下文关联的词向量,按顺序将词向量拼接得到每行数据的句向量。
本发明的有益效果:
1.本发明所提出的方法具有较强的可解释性以及可复用性。
2.相较于现有的人格特征检测模型,本发明提高了人格特征检测精度。
附图说明
图1为本发明的整体框图;
图2为Bert的结构表示图;
图3为SVM模型的线性分类图;
图4为数据预处理与脱敏规则流程图。
具体实施方式
下面将结合本发明实施例中的附图,对本发明实施例中的技术方案进行清楚、完整地描述,显然,所描述的实施例仅仅是本发明一部分实施例,而不是全部的实施例。基于本发明中的实施例,本领域普通技术人员在没有做出创造性劳动前提下所获得的所有其他实施例,都属于本发明保护的范围。
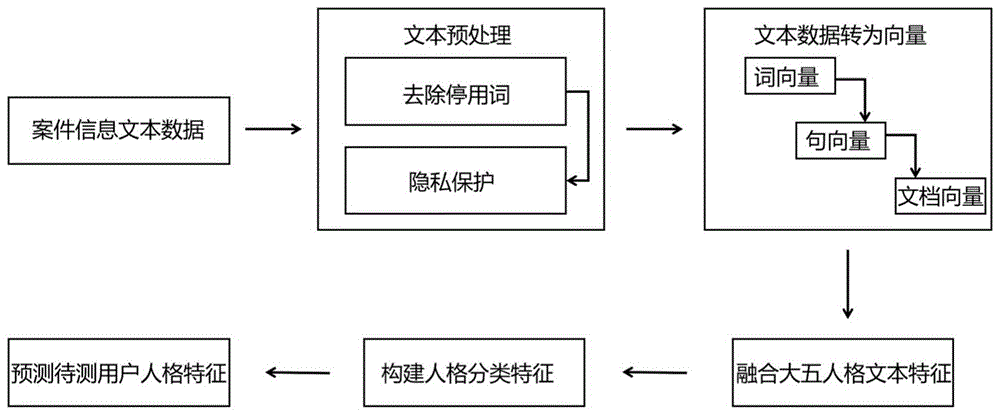
一种面向电信欺诈案件受害者的人格特征检测方法,如图1所示,包括:
S1,对案件文本数据信息进行预处理;
S2,按照预定义的脱敏规则对预处理后的数据信息进行隐私保护处理;
S3、建立人格特征检测模型,将隐私保护处理后的数据信息输入人格特征检测模型获取相应的大五人格特征得分。
大五人格:大五人格特征模型是心理学中的一个模型,它包含了五种不同的人格特征,包括EXT(Extroversion,外向性),NEU(Neuroticism,神经质性), AGR(Agreeableness,宜人性),CON(Conscientiousness,尽责性),OPN (Openness,开放性)。
开放性(Openness):具有想象、审美、情感丰富、求异、创造、智慧等特质。
责任心(Conscientiousness):显示胜任、公正、条理、尽职、成就、自律、谨慎、克制等特点。
外倾性(Extraversion):表现出热情、社交、果断、活跃、冒险、乐观等特质。
宜人性(Agreeableness):具有信任、利他、直率、依从、谦虚、移情等特质。
神经质性(Neuroticism):难以平衡焦虑、敌对、压抑、自我意识、冲动、脆弱等情绪的特质,即不具有保持情绪稳定的能力。
一个人通过大五人格模型的得分在各项上均有不同。例如外向性评分明显较高则表示其喜欢与人接触,充满活力,经常感受到积极的情绪,神经质性得分明显较高则表示其有较大的心理压力,有太多不现实的想法、过多的要求和冲动,更容易体验到诸如愤怒、焦虑、抑郁等消极的情绪。虽然这些得分可能存在例外的情况,但从平均角度来看,开放性得分较高则表示偏爱抽象思维,兴趣广泛。
文本预处理:是指文字信息输入到人格特征检测模型之前进行规范化处理,使文字数据符合模型的输入要求。
隐私保护:隐私保护是指使个人或集体等实体不愿被其他人知道的信息得到应有的保护。
Bert:Bert是Bidirectional Encoder Representation from Transformers(双向 Transformer的编码器)的缩写,它是由Google开发的自然语言处理模型,可学习文本的双向表示,显著提升在情境中理解许多不同任务中的无标记文本的能力。
Bert的结构表示图如图2所示,Bert(Bidirectional Encoder Representationsfrom Transformers)是自然语言处理通用模型,使用的是双向Transformer。 Transformer模型的双向自注意力(self-attention),其基础是Attention机制, Attention机制的提出是为了解决RNN无法并行等缺点。多个Transformer模型的Encoder结构堆叠组成Bert。Bert使用规模较大的语料进行无监督的学习方式,最终得到一个预训练模型。Bert模型的基本原理是利用模型各层中的上下文进行深度双向预训练。它主要基于Transformer中的Encoder,多层Transformer结构经过堆叠形成的深度神经网络就是Bert模型的主体结构。Bert的输入内容包含标记嵌入(Token Embeddings)、段嵌入(Segment Embeddings)以及位置嵌入(Position Embeddings)。标记嵌入的作用是在每个序列开头插入分类 token[CLS],使得[CLS]对应的最后一个Transformer层的输出用来聚集整个序列表征信息。段嵌入插入到每个句子后,用来分开不同的句子。位置嵌入表示每个字的顺序,保障训练过程中字段顺序不会出错。使用者可以在具体的自然语言处理任务中直接使用此模型或者微调后使用。
词向量:词向量(Word Embedding),自然语言处理中的一组语言建模和特征学习技术的统称,其中来自词汇表的单词或短语被映射到实数的向量。
句向量:句向量是一个句子中的所有词向量的集合。
文档向量:文档向量是一个案例中所有句向量的集合。
SVM:SVM是Support Vector Machine(支持向量机)的缩写,它是一类按监督学习方式对数据进行二元分类的广义线性分类器。
如图3所示,Bagging-SVM的原理是利用多个SVM进行模型的训练,再利用Bagging的思想对结果进行投票或者求平均值的处理过程。其中SVM是 Support Vector Machine(支持向量机)的简称,SVM是一种二分类模型,它是从线性可分情况下的最优分类面发展而来。最优分类面就是要求分类线不但能将两类正确分开(训练错误率为0),且使分类间隔最大。SVM考虑寻找一个满足分类要求的超平面,并且使训练集中的点距离分类面尽可能的远,也就是寻找一个分类面使它两侧的空白区域(margin)最大。假设超平面可描述为:
ωx+b=0,ω∈R
其分类间隔等于:
其中,ω表示平面的法向量,它的指向由具体的值而定,x表示一个向量,它可以看作是原点到平面上任一点的连线向量,b表示平面的偏移量。
学习策略是使数据间的间隔最大化,最终可转化为一个凸二次规划问题的求解。
分类器的损失函数为:
L(ω;x,y):=max(0,1-yω
其中,ω表示平面的法向量,它的指向由具体的值而定,x表示一个向量,它可以看作是原点到平面上任一点的连线向量,,y是分类标签,ω
SVM模型会根据ω
对案件文本数据信息进行预处理,包括:利用Python内置的jieba库对案件文本信息数据进行停用词处理。
如图4所示,对数据隐私保护处理,包括:
S21:建立自定义的脱敏规则;
所述脱敏规则包括:剔除案件文本信息中的身份证号、电话号码以及住址等用户隐私信息;
S22:通过建立的脱敏规则对数据信息的文本进行脱敏处理。
所述人格特征检测模型,包括:Bert层、多分类层;
所述多分类层:组合多个二分类器,得到多分类器,并预设五大人格特征,将数据输入多分类器,实现五大人格的分类;
所述五大人格特征包括:外向性、神经质性、宜人性、尽责性、开放性。
将隐私保护处理后的数据信息输入人格特征检测模型获取相应的大五人格特征得分:
S31:将隐私处理之后的数据信息输入到Bert层中进行文档划分,将数据信息的文档长度大于512的进行截断,文档长度不足512的用无用词填充,并转换为句向量;
S32:将句向量与Francois Mairesse开发的具有84个特征组成的人格特征检测数据集进行连接,得到整个案件信息的文档特征向量;
S33:将整个案件信息的文档特征向量输入多分类层,第一层SVM分类器中进行二分类判断,得出人格特征的偏好得分,根据偏好得分判断是否属于五大人格的某种人格特征,如果不是就再输入到下一层SVM中进行相应的判断,直至判断出相应的大五人格特征为止;
S34:将多分类层的输出的对应人格的人格特征偏好得分取平均数,得到最终的人格特征的偏好得分。
Bert层将数据信息转换为词向量,包括:
通过从输入数据信息的一句话中提取15%的次进行预测,同时随机抹除部分数据,将这些数据以80%的概率使用特殊符号[MASK]进行替换,10%的概率使用任意词替换,剩下的10%概率保持原词不变,得到将数据信息转化为具有上下文关联的词向量,按顺序将词向量拼接得到每行数据的句向量。
尽管已经示出和描述了本发明的实施例,对于本领域的普通技术人员而言,可以理解在不脱离本发明的原理和精神的情况下可以对这些实施例进行多种变化、修改、替换和变型,本发明的范围由所附权利要求及其等同物限定。