一种基于告警语义的多步攻击检测模型预训练方法
文献发布时间:2023-06-19 18:37:28
技术领域
本发明涉及多步攻击检测模型预训练领域,具体涉及一种基于告警语义的多步攻击检测模型预训练方法。
背景技术
Ourston等人在2003年将隐马尔可夫模型首次应用于多步攻击检测,利用HMM对告警序列进行标注。Xue等人针对隐马尔可夫模型在多步攻击检测中观测值难以确定的问题,提出了一种多步攻击检测与预测方法。该文献通过Baum-Welch算法对现有的隐马尔可夫模型更新,然后使用Forward算法识别属于攻击场景的告警,最后使用Viterbi算法标注告警并预测下一个可能的告警。Ghafir等人首次提出了一种用于APT攻击检测和预测的新型入侵检测系统。该论文包含了两个部分,第一部分作者通过对杀链(Cyber Kill Chain)中包含的每个攻击阶段的流量特征进行检测,实现了攻击场景的重建。第二部分攻击解码,这个阶段利用隐马尔可夫模型(HMM)来确定最可能的APT阶段序列,并根据APT阶段序列来预测攻击者的下一步攻击。Tu等人针对隐马尔可夫模型无法预测多个攻击意图的问题,提出了一种基于隐马尔可夫模型和概率推理的概率模型在早期阶段检测到攻击意图。该模型使用在线参数更新规则,使其能更好地适应动态网络环境。Shawly等人对基于隐马尔可夫模型检测算法的检测准确性和预测准确性进行分析,覆盖了EM、spectral、Baum-Welch、differential evolution、K均值和分段K均值等算法。
尽管基于无监督学习的HMMs在MSA检测中的重要性已被该领域广泛认可,但仍存在以下问题,Baum-Welch算法对初始化值非常敏感。当前的Baum-Welch算法使用平均初始化方法来初始化HMM。然而,这种初始化方法容易导致多步攻击检测模型陷入局部最优解,降低模型检测的有效性。同一攻击阶段网络交互产生的告警描述具有较高的语义相似度,可用于区分各个攻击阶段。然而,目前基于HMM的MSA检测方法中,使用类别编码对告警描述属性进行编码,丢失了告警描述丰富的语义信息。
发明内容
针对现有技术的不足,本发明提供了一种基于告警语义的多步攻击检测模型预训练方法,通过采用语义聚类对属于同一攻击阶段的告警进行聚合,避免模型陷入局部最优解的问题。
为实现上述目的,本发明提供了一种基于告警语义的多步攻击检测模型预训练方法,包括:
利用离线告警序列得到告警描述嵌入向量;
利用所述告警描述嵌入向量对多步攻击检测模型进行预训练处理。
优选的,所述利用离线告警序列得到告警描述嵌入向量包括:
获取告警规则对应的告警文本;
利用所述告警文本基于基础词语进行划分处理得到告警单词文本;
利用所述告警单词文本基于停用词表进行停用词去除处理得到告警单词基础文本;
利用所述告警单词基础文本得到告警描述嵌入模型;
利用所述告警单词基础文本输入告警描述嵌入模型得到告警描述嵌入向量;
其中,停用词表为停用语气助词词表。
进一步的,利用所述告警单词基础文本得到告警描述嵌入模型包括:
利用所述告警单词基础文本作为训练集;
利用所述训练集为输入,所述训练集中告警单词基础文本对应的告警描述嵌入向量为输出,基于Doc2Vec的PV-DBOW版本进行训练得到告警描述嵌入模型。
优选的,利用所述告警描述嵌入向量对多步攻击检测模型进行预训练处理包括:
利用所述告警描述嵌入向量根据当前多步攻击阶段建立当前多步攻击阶段的告警嵌入向量隶属度矩阵;
利用所述当前多步攻击阶段的告警嵌入向量隶属度矩阵计算当前多步攻击阶段的簇中心;
利用所述当前多步攻击阶段的簇中心迭代更新计算告警嵌入向量隶属度矩阵;
利用所述告警嵌入向量隶属度矩阵获取对应多步攻击阶段位置;
利用告警嵌入向量隶属度矩阵计算HMM发射概率矩阵;
利用所述HMM发射概率矩阵得到预训练结果。
进一步的,利用所述当前多步攻击阶段的嵌入向量隶属度矩阵计算当前多步攻击阶段的簇中心的计算式如下:
其中,C
进一步的,利用所述当前多步攻击阶段的簇中心迭代更新计算告警嵌入向量隶属度矩阵的计算式如下:
其中,U
进一步的,利用所述告警嵌入向量隶属度矩阵获取对应多步攻击阶段位置:
判断U
利用迭代更新后的告警嵌入向量隶属度矩阵根据各攻击簇中的最早告警得到攻击簇的多步攻击阶段;
利用所述攻击簇的多步攻击阶段作为对应多步攻击阶段位置;
其中,ε为经验常数。
进一步的,所述利用告警嵌入向量隶属度矩阵计算HMM发射概率矩阵的计算式如下:
其中,B为HMM发射概率矩阵,u
进一步的,利用所述HMM发射概率矩阵得到预训练结果包括:
利用所述HMM发射概率矩阵得到多步攻击阶段对应的告警描述嵌入向量的概率;
利用所述告警描述嵌入向量的概率作为预训练结果。
与最接近的现有技术相比,本发明具有的有益效果:
本专利解决了当前Baum-Welch初始化方法容易导致模型陷入局部最优解的问题。基于同一攻击阶段产生的告警具有较高语义相似度的思想,所提方法采用语义聚类对属于同一攻击阶段的告警进行聚合,然后将每个攻击阶段的告警向量隶属度转换为每个攻击阶段产生警报的概率。最后,将Baum-Welch的初始值替换为经过告警语义知识优化的初始值,以避免模型陷入局部最优解的问题。
附图说明
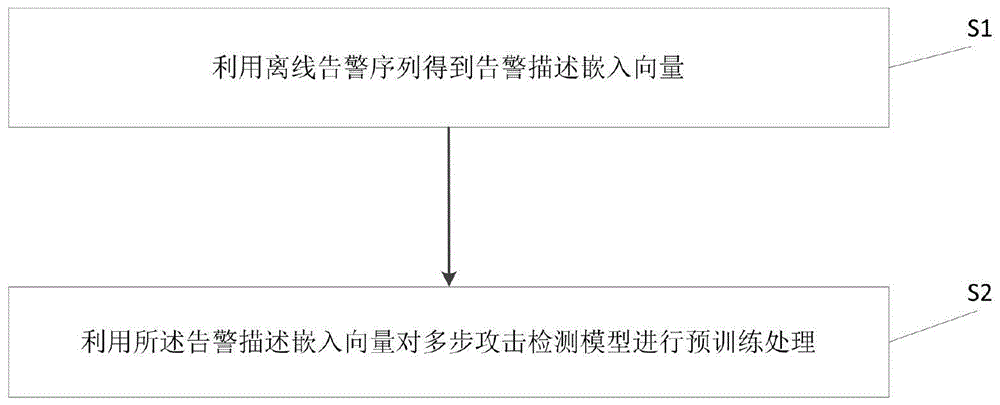
图1是本发明提供的一种基于告警语义的多步攻击检测模型预训练方法的流程图;
图2是本发明提供的一种基于告警语义的多步攻击检测模型预训练实际应用方法的流程图。
具体实施方式
下面结合附图对本发明的具体实施方式作进一步的详细说明。
为使本发明实施例的目的、技术方案和优点更加清楚,下面将结合本发明实施例中的附图,对本发明实施例中的技术方案进行清楚、完整地描述,显然,所描述的实施例是本发明一部分实施例,而不是全部的实施例。基于本发明中的实施例,本领域普通技术人员在没有做出创造性劳动前提下所获得的所有其它实施例,都属于本发明保护的范围。
实施例1:
本发明提供了一种基于告警语义的多步攻击检测模型预训练方法,如图1所示,包括:
S1、利用离线告警序列得到告警描述嵌入向量;
S2、利用所述告警描述嵌入向量对多步攻击检测模型进行预训练处理。
S1具体包括:
S1-1、获取告警规则对应的告警文本;
S1-2、利用所述告警文本基于基础词语进行划分处理得到告警单词文本;
S1-3、利用所述告警单词文本基于停用词表进行停用词去除处理得到告警单词基础文本;
S1-4、利用所述告警单词基础文本得到告警描述嵌入模型;
S1-5、利用所述告警单词基础文本输入告警描述嵌入模型得到告警描述嵌入向量;
其中,停用词表为停用语气助词词表。
本实施例中,一种基于告警语义的多步攻击检测模型预训练方法,基础词语包括实词与虚词。
S1-4具体包括:
S1-4-1、利用所述告警单词基础文本作为训练集;
S1-4-2、利用所述训练集为输入,所述训练集中告警单词基础文本对应的告警描述嵌入向量为输出,基于Doc2Vec的PV-DBOW版本进行训练得到告警描述嵌入模型。
S2具体包括:
S2-1、利用所述告警描述嵌入向量根据当前多步攻击阶段建立当前多步攻击阶段的告警嵌入向量隶属度矩阵;
S2-2、利用所述当前多步攻击阶段的告警嵌入向量隶属度矩阵计算当前多步攻击阶段的簇中心;
S2-3、利用所述当前多步攻击阶段的簇中心迭代更新计算告警嵌入向量隶属度矩阵;
S2-4、利用所述告警嵌入向量隶属度矩阵获取对应多步攻击阶段位置;
S2-5、利用告警嵌入向量隶属度矩阵计算HMM发射概率矩阵;
S2-6、利用所述HMM发射概率矩阵得到预训练结果。
S2-2的计算式如下:
其中,C
S2-3的计算式如下:
其中,U
S2-4具体包括:
S2-4-1、判断U
S2-4-2、利用迭代更新后的告警嵌入向量隶属度矩阵根据各攻击簇中的最早告警得到攻击簇的多步攻击阶段;
利用所述攻击簇的多步攻击阶段作为对应多步攻击阶段位置;
其中,ε为经验常数。
本实施例中,一种基于告警语义的多步攻击检测模型预训练方法,所述迭代更新告警嵌入向量隶属度矩阵为返回S2-1重新处理。
S2-5的计算式如下:
其中,B为HMM发射概率矩阵,u
S2-6具体包括:
S2-6-1、利用所述HMM发射概率矩阵得到多步攻击阶段对应的告警描述嵌入向量的概率;
S2-6-2、利用所述告警描述嵌入向量的概率作为预训练结果。
实施例2:
一种基于告警语义的多步攻击检测模型预训练实际应用方法,如图2所示,包括:
由于同一攻击阶段产生的告警描述具有较高的相似度,使得这些告警在语义向量空间内的距离更近,则可通过模糊C均值聚类算法,将隶属于同一攻击阶段的告警聚在一起。然后将这种距离关系映射到模型初始参数上,得到更为接近实际攻击场景的初始参数,在此初始参数上进行无监督训练,可以避免模型陷入局部最优解的问题。因此,利用告警嵌入以及参数预训练步骤,提取告警语义信息,优化多步攻击检测模型的初始参数。
一、基于Doc2vec的告警嵌入:
为了解决目前One-Hot编码无法捕获告警描述语义关系的问题,告警嵌入模块采用Doc2vec模型将告警描述转换为低维度的连续值,将语义相近的告警描述映射到向量空间中相近的位置,实现告警描述中语义知识的提取。
目前,Doc2vec包括PV-DM和PV-DBOW两种训练方式。因告警中包含的描述较少时PV-DBOW得到的词向量更准确,故本文选择PV-DBOW训练告警嵌入模型。告警描述嵌入模型的具体训练流程如下:
1.获取告警规则集中所有告警文本;
2.将告警文本进行切分,获取告警文本包含的所有单词;
3.利用停用词表去除告警文本中的停用词;
4.利用去除停用词的告警文本训练Doc2vec模型。
二、基于模糊C均值的模型参数预训练:
模糊C均值算法是一种基于隶属度的聚类算法,其思想是使得被划分至同一簇的向量之间相似度最大,而不同簇之间的向量相似度最小。参数预训练步骤则利用模糊C均值算法将隶属同一攻击阶段的告警嵌入向量进行聚合。聚类算法收敛后,得到每个告警嵌入向量对所有类(攻击阶段)的隶属度。进而可根据聚类结果,将告警向量与各类(攻击阶段)的隶属度矩阵转化为攻击阶段产生告警的概率矩阵,得到更为接近实际攻击场景的初始告警描述转移概率矩阵。其主要步骤如下:
1.确定类个数N。其中,N表示多步攻击的N个攻击阶段。
2.随机初始化隶属度矩阵U
3.更新簇中心C,利用U
4.更新隶属度矩阵中各元素:
5.若‖U
6.攻击阶段确定。在第5步骤后,每个攻击簇都包含一定数量的告警。根据每个攻击簇中最早的告警确定每个簇所属的攻击阶段。
7.HMM发射概率矩阵计算。每个告警嵌入向量对攻击阶段的隶属度转换为多步攻击阶段产生告警描述的概率(HMM发射概率矩阵),完成对隐马尔可夫模型参数的预训练:
本领域内的技术人员应明白,本发明的实施例可提供为方法、系统、或计算机程序产品。因此,本发明可采用完全硬件实施例、完全软件实施例、或结合软件和硬件方面的实施例的形式。而且,本发明可采用在一个或多个其中包含有计算机可用程序代码的计算机可用存储介质(包括但不限于磁盘存储器、CD-ROM、光学存储器等)上实施的计算机程序产品的形式。
本发明是参照根据本申请实施例的方法、设备(系统)、和计算机程序产品的流程图和/或方框图来描述的。应理解可由计算机程序指令实现流程图和/或方框图中的每一流程和/或方框、以及流程图和/或方框图中的流程和/或方框的结合。可提供这些计算机程序指令到通用计算机、专用计算机、嵌入式处理机或其他可编程数据处理设备的处理器以产生一个机器,使得通过计算机或其他可编程数据处理设备的处理器执行的指令产生用于实现在流程图一个流程或多个流程和/或方框图一个方框或多个方框中指定的功能的装置。
这些计算机程序指令也可存储在能引导计算机或其他可编程数据处理设备以特定方式工作的计算机可读存储器中,使得存储在该计算机可读存储器中的指令产生包括指令装置的制造品,该指令装置实现在流程图一个流程或多个流程和/或方框图一个方框或多个方框中指定的功能。
这些计算机程序指令也可装载到计算机或其他可编程数据处理设备上,使得在计算机或其他可编程设备上执行一系列操作步骤以产生计算机实现的处理,从而在计算机或其他可编程设备上执行的指令提供用于实现在流程图一个流程或多个流程和/或方框图一个方框或多个方框中指定的功能的步骤。
最后应当说明的是:以上实施例仅用以说明本发明的技术方案而非对其限制,尽管参照上述实施例对本发明进行了详细的说明,所属领域的普通技术人员应当理解:依然可以对本发明的具体实施方式进行修改或者等同替换,而未脱离本发明精神和范围的任何修改或者等同替换,其均应涵盖在本发明的权利要求保护范围之内。