一种多源异构数据的治理方法及系统
文献发布时间:2023-06-19 18:37:28
技术领域
本发明涉及数据库技术领域,具体涉及一种多源异构数据的治理方法及系统。
背景技术
随着互联网行业的飞速发展,业务、应用数据量不断暴涨。为了解决大数据带来的性能挑战,键值数据库、文档数据库、宽列数据库、时序数据库等专业数据库相继出现,使得业务成为可能。
但,在数据应用过程中,无法实现数据的统一共享,每一个数据库就相当于一个数据孤岛,应用需要去各个数据库抓取数据到内存,再进行各个数据的处理。
发明内容
为了解决背景技术中提出的问题,本发明提供一种多源异构数据的治理方法及系统,通过封装数据引擎,消除数据孤岛,以实现数据共享。
本发明的技术方案是这样实现的:
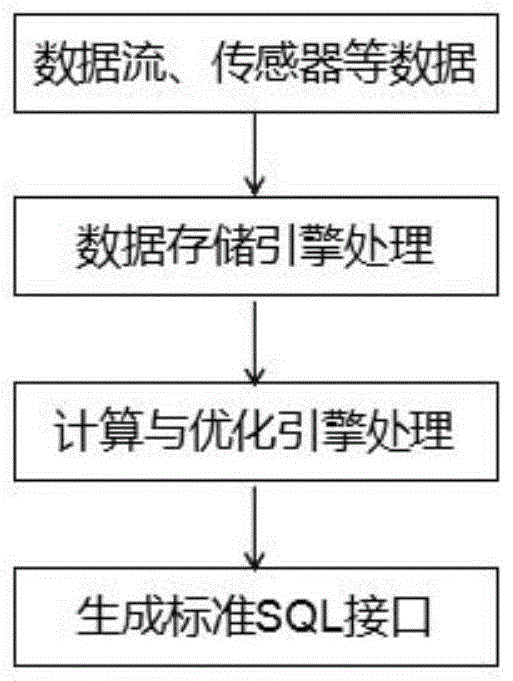
一种多源异构数据的治理方法,包括:
步骤S1、确认数据来源、数据结构与数据类型;
步骤S2、对数据进行对应存储引擎处理;
步骤S3、对所存储数据进行计算与优化处理;
步骤S4、对处理后的数据生成标准SQL接口。
进一步地方案为:所述步骤S1中,根据源表信息确认所述数据来源与所述数据结构,根据源表字段判断所述数据类型。
进一步地方案为:所述步骤S3中,具体包括:
S301、根据数据类型,对数据进行关联、聚集、合并与计算;
S302、根据不同数据结构与数据类型,选择RLE算法、哈夫曼算法、Delta2、XOR编码、Snappy算法或Rice算法对数据进行高效压缩;
S303、建立倒排索引或位图索引。
进一步地方案为:所述标准SQL接口根据JDBC标准,并通过指定Token或者用户名、密码生成。
同时,本发明的技术方案是这样实现的:
一种多源异构数据的治理系统,包括:
信息确认模块:用于确认数据来源、数据接口和数据类型;
存储引擎模块:用于根据数据结构与数据类型,选择存储引擎对数据进行存储;
计算引擎模块:用于对数据进行关联、聚集、合并与计算;
优化引擎模块:用于根据不同数据结构与数据类型,选择RLE算法、哈夫曼算法、Delta2、XOR编码、Snappy算法或Rice算法对数据进行高效压缩,并建立倒排索引或位图索引;
接口生成模块:用于对计算引擎模块和优化引擎模块进行处理后的数据生成标准SQL接口。
采用了上述技术方案,本发明的有益效果为:
本发明将不同来源的不同结构数据进行存储、计算与优化处理,生成标准SQL接口,消除数据孤岛,实现数据共享,快速的响应业务和应用开发的需求,提升开发运维效率。
附图说明
为了更清楚地说明本发明实施例或现有技术中的技术方案,下面将对实施例或现有技术描述中所需要使用的附图作简单地介绍。
图1为本发明实施例的一种多源异构数据的治理方法流程图;
图2为本发明实施例的源表信息图;
图3为本发明实施例的一种多源异构数据的治理系统示意图。
具体实施方式
下面结合本发明实施例的附图对本发明实施例的技术方案进行解释和说明,但下述实施例仅仅为本发明的优选实施例,并非全部。基于实施方式中的实施例,本领域技术人员在没有做出创造性劳动的前提下所获得其它实施例,都属于本发明的保护范围。
实施例1;
如图1-2所示,本实施例的一种多源异构数据的治理方法,具体步骤如下:
步骤S1、确认数据来源、数据结构与数据类型:
根据源表信息确认数据来源与数据结构;根据源表字段判断数据类型。
具体的,根据如图2所示的源表信息确认数据为工厂设备实时采集数据,判断出所确认数据为时序数据,根据时序数据特点:measurement、tag keys、tag values、fieldkeys数据类型为字符串,field values数据类型为浮点型;本实施例中,通过信息确认模块中对数据来源、数据接口及数据类型进行确认。
步骤S2、对数据进行对应存储引擎处理:
根据数据结构与数据类型选择存储引擎进行处理。
本实施例中,选择时序存储引擎模块,通过新建meachine_data,设置tag与field字段,对数据进行存储。
步骤S3、对所存储数据进行计算与优化处理:
具体的,对所存储数据进行计算与优化处理,包括:
S301、根据数据类型,对数据进行关联、聚集、合并与计算;
S302、根据不同数据结构与数据类型,选择RLE算法、哈夫曼算法、Delta2、XOR编码、Snappy算法或Rice算法对数据进行高效压缩;
S303、建立倒排索引或位图索引,提高多维组合查询效率。
本实施例中,在计算引擎模块中,通过Continuous Query(CQ)连续查询计算出每小时机器的平均温度,存储到新的average_temperatures中;
CREATE CONTINUOUS QUERY"cq_basic"ON"transportation"
BEGIN
select mean("temperature")into"average_temperatures"from"meachine_data"group by time(1h)
END
在优化引擎模块中,根据average_temperatures中不同数据类型,选择Delta2压缩时间戳数据,使用XOR编码对浮点数据进行无损压缩,采用Snappy算法对字符串数据进行高效压缩;
通过保留策略Retention Policy(RP)设置老旧数据保留时间为4周,定期自动清理过期数据,节约磁盘存储空间。
create retention policy"four_weeks"on"food_data"duration4wreplication 1。
步骤S4、对处理后的数据生成标准SQL接口:
具体的,标准SQL接口根据JDBC标准,并通过指定Token或者用户名、密码生成。
本实施例中,在接口生成模块中通过指定用户名、密码生成如下SQL接口,供研发直接调用:
"http://localhost:8086/write?u=admin&p=abc@123!%40%23&db=mydb&precision=s"。
本实施例中,工业时序数据通过上述步骤进行存储、聚合、计算、优化、压缩,最后根据用户名和密码生成标准SQL接口,供应用研发直接调用。常用关系数据、非关系数据以及空间数据也根据不同的存储引擎进行存储处理,后续生成对应的sql接口,供研发直接调用,从而提高项目开发运维效率。
实施例2;
如图3所示,一种多源异构数据的治理系统,包括:
信息确认模块:用于确认数据来源、数据接口和数据类型;
存储引擎模块:用于根据数据结构与数据类型,选择存储引擎对数据进行存储;本实施例中,存储引擎包括:时序数据引擎、关系数据引擎、非关系数据引擎和几何数据引擎等。
计算引擎模块:用于对数据进行关联、聚集、合并与计算;
优化引擎模块:用于根据不同数据结构与数据类型,选择RLE算法、哈夫曼算法、Delta2、XOR编码、Snappy算法或Rice算法对数据进行高效压缩,并建立倒排索引或位图索引;
接口生成模块:用于对计算引擎模块和优化引擎模块进行处理后的数据生成标准SQL接口。
本发明针对应用分别到不同数据库调用数据进行关联、计算等效率低、响应慢问题,通过多源异构数据的治理系统将不同来源的不同结构数据进行存储、计算与优化处理,生成标准SQL接口,消除数据孤岛,实现数据共享,快速的响应业务和应用开发的需求,提升开发运维效率。
以上所述实施例仅表达了本发明的具体实施方式,其描述较为具体和详细,但并不能因此而理解为对本发明专利范围的限制。应当指出的是,对于本领域的普通技术人员来说,在不脱离本发明构思的前提下,还可以做出若干变形和改进,这些都属于本发明的保护范围。