一种联合U2-Net和LaMa模型的光滑表面高光快速去除方法及系统
文献发布时间:2023-06-19 18:46:07
技术领域
本发明涉及计算机视觉和图像处理领域,具体涉及一种联合U
背景技术
自然场景中的大多数材料在光照条件下其表面都会呈现出镜面高光现象,该现象在表面光滑材料上尤为明显,镜面高光的去除一直以来都是计算机视觉和图像处理中的一个关键问题。在实际的工业应用中,高光的存在对生产中的许多环节都会造成严重的影响。最常见的影响即:镜面高光的存在会给原始图像带来噪声和干扰,从而降低某些任务的性能,例如小目标检测、跟踪和识别。具体而言,一些基于计算机视觉的自动化技术,例如图像分割、目标检测、跟踪和识别均在很大程度上依赖于图像自身的颜色或饱和强度信息。多区域复杂高光的存在会严重降低图像质量并不可预期地篡改像素的原始信息和强度值,导致这些自动化技术的性能急剧下降。例如,一个与待检测目标相似的高光区域可能被错误识别为目标进行检测;比如酒瓶表面存在大面积高光,可能一定程度上导致了对酒瓶表面划痕缺陷的错误识别。
现有技术方案及缺陷:
1、传统的基于双色反射模型的方法,基于各种形式下的阈值进行操作,这些阈值操作主要将最亮的像素视为高光,此方法处理对象大都整体表面昏暗,材质表面光滑程度一般,不具备随机现实场景下高光物体的特点,因此这类方法在面对现实场景中表面鲜明且高光与待检测目标颜色信息较为相似的图像而言,高光定位难、处理速度慢、实用价值意义一般;
2、一种高质量像素聚类方法,该方法首先估计出每个像素的最小和最大色度值;然后,分析这些值在最小-最大色度空间中的分布模式,以提出一种有效地像素聚类方法;最后,估计出每个簇的强度比以分离漫反射和镜面反射分量,从而允许从单个图像中实时去除镜面高光。相比于一般基于双色反射模型的去高光算法,该算法实时性更好,处理速度快,处理结果质量高,但是针对表面光滑鲜明的材质以及物体表面上高光与待检测目标颜色信息较为相似的真实图像而言,被检测分离出的高光区域像素信息被破坏,没有保留原始图片该有的颜色特征;
3、一种基于反射分量分离(RCS)和优先区域填充理论的新算法,首先通过比较像素参数找到图像中的镜面高光像素。然后,反射分量被分离和处理。但是对于表面鲜明光滑,容易呈现出强高光的物体,RCS理论会因为较大的高光反射分量而改变高光像素的颜色信息。在这种情况下,优先区域填充理论被用来恢复颜色信息,此方法应用到表面的高光待填充区域数量较为庞大且表面纹理复杂的处理对象上,处理速度慢,视觉效果一般;
4、一个基于深度学习的镜面高光检测网络(SHDNet),利用多尺度上下文对比特征来准确检测不同尺度的镜面高光。而后他们又在此基础上提出了一种新颖联合高光检测和去除的多任务网络,旨在检测并去除自然图像中的亮点,并在他们的数据集上取得了优异的效果。但是该方法现有公开的测试模型基于SHIQ数据集进行训练,该数据集更具一般性,在面对针对性较强的高光图像时,无法较好地发挥网络的性能,因此不适用于具有表面材质光滑、反射性强、高光区域密集特点的研究对象。
发明内容
为了解决上述现有技术中存在的问题,本发明拟提供了一种联合U
一种联合U
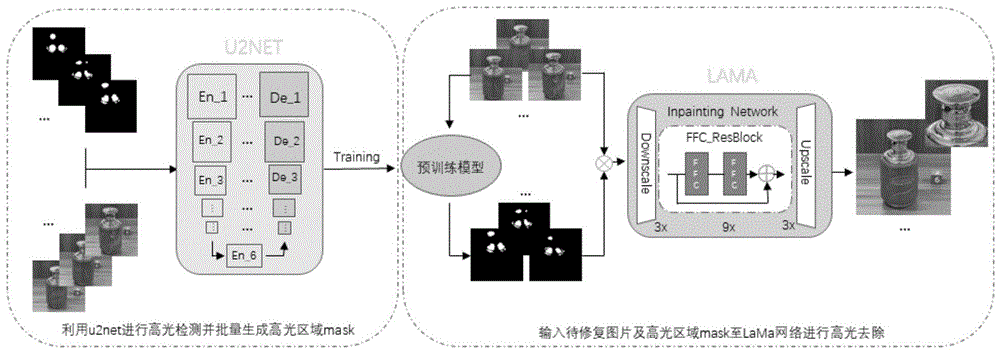
步骤1:将存在密集高光的光滑物体表面图像和针对高光区域进行人工标记生成的掩膜图输入至U
步骤2:利用步骤1所得高光检测模型对存在密集高光的光滑物体表面图像进行高光检测并自动批量地生成高光区域对应的掩膜图;
步骤3:将步骤2所得的掩膜图与相应的光滑物体表面图像同时输入至LaMa网络,依靠LaMa网络去除光滑物体表面图像的高光。
优选的,在所述步骤1中,所述U
(i)输入卷积层,用于局部特征提取的普通卷积层,将输入特征图
(ii)类似于U-Net的高度为L的对称编码器-解码器结构,它以中间特征图
(iii)融合局部特征和多尺度特征的残差连接:
优选的,所述U
优选的,所述U
其中,
对于每个l,采用标准的二值交叉熵损失函数:
其中,(r,c)代表像素坐标、(H,W)代表图像分辨率大小、P
优选的,所述U
优选的,所述样本数据具有表面材质光滑、反射性强、高光区域密集的特点。
优选的,所述LaMa网络的具体内容如下:
采用基于具有高感受野的语义分割网络的感知损失,促进了全局形状结构的一致性,高感受野感知损失(HRF PL)使用了高感受野基础模型φ
其中M代表顺序两阶段均值运算、φ
D
LaMa的最终损失函数使用了
其中,L
一种联合U
优选的,所述数据存储模块存储内容包括训练集,所述高光检测模块由U
本发明的有益效果包括:
本发明以一种全新的高光去除思路提出了一种联合U
附图说明
图1为实施例1一种联合U
图2为实施例1U
图3为实施例1高光检测模型在自制数据集上的精确召回曲线和综合评价指标曲线。
图4为实施例1高光检测模型对真实表面高光酒瓶图像的部分检测结果展示。
图5为实施例1一种联合U
其中,(a)-(d)是其他现有技术高光去除效果,(e)是实施例1方法高光去除效果。
图6为实施例2一种联合U
具体实施方式
为使本申请实施例的目的、技术方案和优点更加清楚,下面将结合本申请实施例中附图,对本申请实施例中的技术方案进行清楚、完整地描述,显然,所描述的实施例仅是本申请一部分实施例,而不是全部的实施例。通常在此处附图中描述和示出的本申请实施例的组件可以各种不同的配置来布置和设计。因此,以下对在附图中提供的本申请的实施例的详细描述并非旨在限制要求保护的本申请的范围,而是仅仅表示本申请的选定实施例。基于本申请的实施例,本领域技术人员在没有做出创造性劳动的前提下所获得的所有其他实施例,都属于本申请保护的范围。
实施例1
下面结合附图1到附图6对本发明的具体实施例做详细的说明,其中附图1是一种联合U
将存在表面高光的酒瓶图像和针对高光区域利用Labelme软件进行人工标记生成的掩膜图输入至U
RSU块结构参考附图2所示,M表示RSU内部层的通道数,这种架构使我们能够从头开始训练网络,满足我们对酒瓶表面高光检测的需求,RSU块提取特征包括以下步骤:
输入卷积层,用于局部特征提取的普通卷积层,将输入特征图
类似于U-Net的高度为L的对称编码器-解码器结构,它以中间特征图
融合局部特征和多尺度特征的残差连接:
U
对于U
具体地,U
其中,
对于每个l,采用标准的二值交叉熵损失函数:
其中,(r,c)代表像素坐标、(H,W)代表图像分辨率大小、P
我们将网络训练到损失收敛为止,此过程大约1500次迭代,迭代过程中每次从200张真实图像中批量提取样本数量大小为12,并且不使用以往方法的验证集部分,整个训练过程大约需要6小时。在测试期间,输入图像大小被调整为320×320并输入网络以获得预测显著图,大小为320×320的预测显著图又被调整回与输入图像相同的大小,在调整大小的过程中使用双线性插值方法。最终获得的高光检测模型以F-measure作为主要评估对酒瓶表面高光的检测性能的标准,具体参考附图3;高光检测模型对真实表面高光酒瓶图像的部分检测结果参考附图4。
在U
采用快速傅里叶卷积模型(FFC)而非传统的全卷积模型,大大提升了卷积运算的效率并允许网络在更早的阶段开始考虑全局上下文信息,覆盖整个图像的感受野;
采用基于具有高感受野的语义分割网络的感知损失,促进了全局形状结构的一致性,高感受野感知损失(HRF PL)使用了高感受野基础模型φ
其中M代表顺序两阶段均值运算、φ
D
LaMa的最终损失函数使用了
其中,L
并且LaMa网络在训练过程中采用一种更有效的掩码生成策略,利用宽而大的掩码从而使网络充分发挥模型的高感受野和损失函数的性能。
本实施例中使用现有的训练好的Big LaMa模型,该模型在pycharm软件中基于Pytorch深度学习框架运行,在搭配好运行环境的基础上,将Big LaMa模型导入即可。BigLaMa-Fourier与标准模型LaMa-Fourier不同的三个方面在于:(i)生成器的深度,共有18个基于FFC的残差块;(ii)训练数据集,Big LaMa模型是在Places-Challenge数据集中约450万张图像上进行训练的;(iii)批次的大小,Big LaMa使用大小为120的更大的batchsize。它在8块NVidia V100 GPU上训练了大约240小时。
本方法相较现技术方案针对酒瓶高光处理效果有较好的提升,具体参考表1和附图5。
表1、实施例1(ours)和其他现有方法处理的酒瓶表面高光数据对比结果
本发明以一种全新的高光去除思路提出了一种联合U
实施例2
参照附图6,附图6所示一种联合U
本发明以一种全新的高光去除思路提出了一种联合U
以上所述实施例仅表达了本申请的具体实施方式,其描述较为具体和详细,但并不能因此而理解为对本申请保护范围的限制。应当指出的是,对于本领域的普通技术人员来说,在不脱离本申请技术方案构思的前提下,还可以做出若干变形和改进,这些都属于本申请的保护范围。