一种用于加速相似文本搜索的新型高效过滤方法
文献发布时间:2023-06-19 18:58:26
技术领域
本发明涉及数据库领域,具体而言涉及一种用于加速相似文本搜索的新型高效过滤方法。
背景技术
随着开放性数据时代的到来,越来越多的数据库被不断地发布,同时这些数据库随着不断更新变得十分庞大,这些大型数据库也正被广泛地运用在诸多应用中(如数据挖掘、数据清洗、文档搜索),因此,人们对于如何在大型数据库快速进行相似文本搜索的问题产生了越来越浓厚的兴趣。
相似文本搜索可以转化为阈值交集势查询问题,而GB-KMV sketch技术可以用来高效地完成阈值交集势搜索问题,GB-KMV sketch方法充分考虑了数据的分布关系特点(即集合大小分布和元素频率分布),在保证执行阈值交集势查询获得快速响应的同时,也相较KMV sketch技术大幅度提高了阈值交集势查询的准确度。
由于GB-KMV sketch要对每一条文本的高频部分和低频部分都和查询文本进行比较,因此相对来说比较耗时。需要设计过滤器来对过滤掉部分元素进行加速处理。
发明内容
发明目的:针对上述现有技术存在的问题和不足,本发明的目的是提出一种用于加速相似文本搜索的新型高效过滤方法,解决相似文本搜索性能不高的问题。
技术方案:为实现上述发明目的,本发明提供一种用于加速相似文本搜索查询的新型高效过滤方法,包含如下步骤:
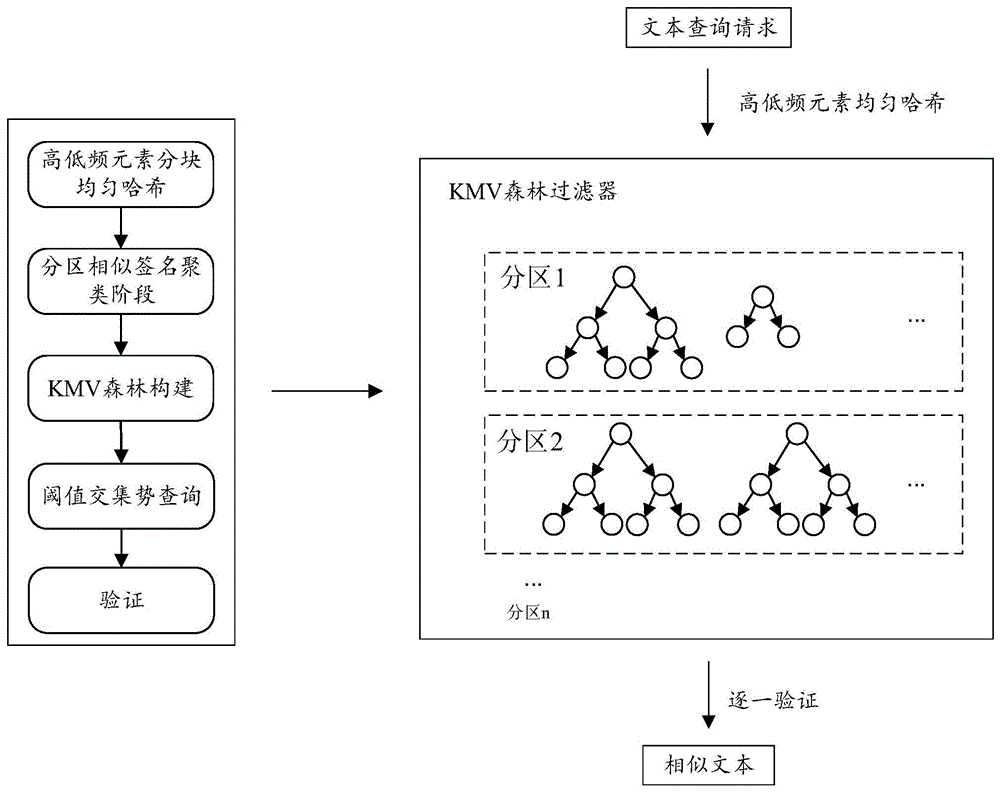
(1)高低频元素分块均匀哈希:对于需要查询的文本数据集,统计文本数据集中所有元素的频率,选出前B个元素作为文本的高频部分,剩余元素为作为低频部分,所述高频部分使用位图表示,所述低频部分截取一部分作为K最小值,所述K最小值为KMV签名,将重新表示完毕的文本传入步骤(2);
(2)分区相似签名聚类阶段:利用低频部分的KMV签名,根据KMV签名长度划分为不同的分区,每个分区中包含低频部分签名长度相等的文本;在每一个分区内部,使用聚类算法,随机选取簇中心,分别计算其它文本与簇中心的相似度,将相似度高的文本的高频部分和低频部分的KMV签名组成一个簇,如果簇的大小满足要求,则保留簇,否则重新选取簇中心,将聚类好的簇传入步骤(3);
(3)KMV森林构建阶段:对每一个分区中的每一个簇,都构建一颗完全二叉树,所述二叉树的叶子节点由簇内的若干文本构成,记录下文本的高频部分和低频部分;每个父节点都包含所述叶子节点的全部文本信息,高频部分位图为两个叶子节点的并集,依次向上构建,最终根节点包含簇内的所有文本的信息;
(4)阈值交集势查询:根据每一个待查询的文本和对应的相似度阈值,在KMV森林中的每一棵树中,从根节点往下递归查询,如果当前节点的交集势不满足相似度阈值,则不再进行后续查询;如果递归到叶子节点仍然满足交集势要求,则将满足交集势要求的叶子节点传入步骤(5);
(5)验证阶段:对每一个叶子节点中包含的文本,均执行交集势计算操作来判断所述文本是否是符合相似度要求的相似文本。
进一步的,所述步骤(2)中,文本根据低频KMV签名长度划分为不同的分区,使得在同一个分区中的所有文本的低频KMV签名的低频元素的个数是相等的;并且每个分区中利用聚类方法根据相同长度签名之间的相似度将签名组成不同的簇;签名的相似度指的是高频部分位图和低频部分共同组成的相似度,即估计的交集势/文本的长度,估计的交集势的计算方式为高频部分位图交集势以及低频部分交集势乘以修正系数之和。
进一步的,所述步骤(2)中,可以对于聚类方法设置不同的相似度阈值,分别聚类出相似度更高的簇和相似度略低一点的簇,最大程度上让更多的元素加入到簇中,同时保证簇间相似度尽可能高。
进一步的,所述步骤(3)中,将不同的簇构建成为一颗完全二叉树,二叉树的每个节点包含:一个指针数组,其存放了对应的多个文本对应的高频部分位图,和KMV签名的指针;一个数组,其记录自身保存的文本的低频KMV签名中包含的所有不同元素;一个位图,用来保存所有文本的高频部分;完全二叉树的构建包含如下步骤:首先,对于每一个分区中的每一个簇,从叶子节点开始,在簇中选取若干个文本共同构成一个叶子节点,构成叶子节点的方法是,高频部分位图为所有文本的高频部分位图的取或,元素数组为所有文本的KMV签名中包含的所有不同元素。最后,利用这些叶子节点依次向上合并从而构成一颗完全二叉树。
进一步的,所述步骤(3)中,两个二叉树节点向上合并构成父节点的方法是,父节点的指针数组为两个子节点的并集,元素数组为两个子节点的元素数组的取不含重复元素并集并排序,高频部分位图仍然取两个子节点位图的或(并集)。
进一步的,所述步骤(3)中,可以通过调整二叉树的最大文本存储数和每个叶子节点包含的文本数来对树的高度,以及过滤的细粒度进行调整,针对不同的数据集产生最好的效果,同时也能够控制内存的开销。
进一步的,所述步骤(3)中,为了减少查询过程中的Cache miss,KMV森林中所有的叶子节点中KMV的内存应该尽量紧密分配,以在验证阶段得到最高的查询效率。
进一步的,所述步骤(4)中,利用KMV森林进行过滤操作时,具体步骤如下,1、从根节点开始依次递归开始对比高频部分位图和元素数组,利用两者与查询文本计算出估计的交集势。2、如果估计的交集势小于相似度阈值,则过滤掉节点包含的全部记。3、否则递归的对两个子节点进行1、2步操作,过滤过程可以使用前缀过滤进行加速。4、若当前节点已经是叶子节点,且不能被过滤,则进行逐个验证,验证过程为计算待验证文本与查询文本的估计的交集势与相似度阈值进行比较。
有益效果:本发明提出的在相似文本搜索问题中利用聚类方法,并结合KMV森林构建,提出了有效、分层次利用这些簇来加速阈值交集势查询操作的方法:第一,充分考虑了数据集中数据分布以及文本之间的相似度,将过滤器设计成按照相似度构建的森林,使得在树节点能够一次过滤掉多个相似元素,降低了相似文本搜索的查询延迟。第二,考虑到Cache miss问题,将KMV森林的叶子节点中的KMV所占用的内存紧密分配,提高了验证效率,进一步降低相似文本搜索的查询延迟。
附图说明
图1为本发明的总体流程示意图;
图2为本发明所述分区相似签名聚类阶段示意图;
图3为本发明所述KMV森林结构示意图;
图4为本发明所述阈值交集势查询阶段示意图。
具体实施方式
下面结合附图和具体实施例,进一步阐明本发明,应理解这些实施例仅用于说明本发明而不用于限制本发明的范围,在阅读了本发明之后,本领域技术人员对本发明的各种等价形式的修改均落于本申请所附权利要求所限定的范围。
本发明提供一种用于加速相似文本查询的新型高效过滤方法,解决了相似文本搜索性能不高的问题。如图1所示,本发明的完整流程包括高低频元素分块均匀哈希阶段、分区相似签名聚类阶段、KMV森林构建阶段、阈值交集势查询阶段、验证阶段5个部分。具体的实施方式分别说明如下:
高低频元素分块均匀哈希阶段对应技术方案步骤(1)。具体实施方式为:首先,统计数据集中所有元素的频次,按照频次高低进行排序,选取前B个高频元素作为高频部分,其余元素构成低频部分。对于这B个高频元素,对每一条文本,选出其中的高频元素组成高频缓冲区(位图)。这个高频部分位图一共由B个比特组成,每个比特位标志着这个高频元素是否存在于这个文本中。其次,利用均匀哈希函数将每个文本中的低频元素均匀哈希到固定区间[0,1]。最后,根据每个文本中低频元素哈希值的大小对其进行排序,组成低频区。
分区相似签名聚类阶段对应技术方案步骤(2)。具体实施方式为:首先将将文本按照签名的低频部分的长度划分为不同的分区,每个分区中包含长度相等的签名。在每个分区的签名中随机选取签名作为簇头,计算其它文本与簇头的相似度,例如文本A和文本B的相似度sim(A,B)的具体计算方式为
其中H
其中L
随后找出所有与该文本相似度大于等于设定相似度阈值的文本,如果总数量大于等于我们设置的最小簇大小,我们就将该部分签名组成一个簇。否则重新选取簇头,重复上述操作。这个阶段以后,我们得到了多个分区,每个分区中包含若干个簇,每个簇直接都保证了簇中心和其它文本的相似度大于设定相似度阈值。换句话说,每个簇中的元素相互之间都较为相似。
图2通过一个例子展示了最终得到的各分区的大致情况,包括一个簇头和多个与之相似的文本。
KMV森林构建阶段对应技术方案步骤(3)。具体实施方式为:首先,要确定叶子节点的大小,即包含多少个文本,这由输入参数决定。然后,对于步骤(2)中得到的每一个簇,我们将其组合成为多个叶子节点,然后利用这些叶子节点构建一颗完全二叉树。
其中,二叉树的叶子节点由簇内不同的文本构成,记录下所有的签名元素和高频部分的信息。节点包含的内容如图3所示:
1)一个指针数组,其存放了对应的多个文本对应的高频部分位图,以及KMV签名的指针
2)一个数组,其记录了自身保存的多个文本的低频KMV签名中包含的所有不同元素
3)一个位图,用来保存多个文本的所有高频部分中的元素。
考虑到减少最后叶子节点验证时的Cache miss问题,我们尽量将KMV森林的叶子节点中存放数据的内存紧密分配。构建好每个叶子节点后,我们向上构建一棵完全二叉树。父节点都包含子节点全部的文本信息,高频部分位图为两个子节点的并集,依次向上构建,最终根节点会包含簇内的所有文本的高频和低频部分的信息。
最后,我们得到了若干个分区,其中每个分区包含若干颗由文本组成的完全二叉树。
阈值交集势查询阶段对应技术方案步骤(4)。具体实施方式为:对于每一个待查询的文本和对应的相似度阈值,我们都将待查询的文本也按照步骤(1)中所述,分成高频部分位图和低频KMV签名。对于KMV森林中的每一颗二叉树,我们都从根节点开始,递归地依次查询高频交集以及低频交集,估计出文本总的交集势,计算方式如下:
其中A为待查询文本,TreeNode表示树的节点,L
如果不满足相似度阈值要求,则整个节点中包含的所有文本都将被过滤,如果满足则查询其子节点。
过滤的具体步骤如下,图4的流程图阐述了过滤的操作流程:
1、从根节点开始依次递归开始对比高频部分位图和元素数组,利用两者与查询文本计算出估计的交集势。
2、如果估计的交集势小于相似度阈值,则过滤掉节点包含的全部文本。
3、否则递归的对两个子节点进行1、2步操作,过滤过程可以使用前缀过滤进行加速。
4、若当前节点已经是叶子节点,转入步骤(5)进行验证。
验证阶段对应技术方案步骤(5)。具体实施方式为:将步骤(4)中无法得到过滤的文本所对应的高频部分和低频部分,分别与查询文本对应的高频和低频部分取交集势,估计出文本间的交集势来最终确认该文本是否为相似文本。