一种易于硬件实现的mipmap LOD处理方法
文献发布时间:2023-06-19 19:05:50
技术领域
本发明涉及图像渲染技术领域,特别涉及一种易于硬件实现的mipmap LOD处理方法。
背景技术
当前多级渐远纹理(mipmap)主流的LOD计算方式需同时获取X和Y两个方向邻近像素的纹理坐标(u,v)并计算出像素的在纹理坐标中和邻近像素的最大距离L,由此求得每个像素的LOD值,即图1中的D。
该算法需要每次同时获取右边和上边邻近像素的纹理坐标(U,V)。对于当前MVP(Model View Presente)的多核构架,一个纹理单元对应多个SP,多个SP同时处理想,纹理单元每次只接收一个流处理器SP(stream processor)处理像素的纹理坐标信息,无法同时获取邻近像素的信息;且纹理单元接收的像素是随机的,不一定是x或者y方向连续的像素。原因在于当前MVP构架的GPU有多个流处理器,并行处理像素数据,每个像素到达纹理单元的时间是随机的。硬件同时获取右边和上边邻近像素的纹理坐标(U,V),难度很大,要解决邻近像素信息同步到达纹理单元和信息存储的问题,硬件难于实现。
发明内容
本发明提供一种易于硬件实现的mipmap LOD处理方法,旨在解决现有多级渐远纹理主流的LOD计算方式存在的问题。
本发明提供一种易于硬件实现的mipmap LOD处理方法,包括以下步骤:
S1.纹理单元基于当前接收到的像素坐标信息(X,Y;U,V),以及前一个像素坐标信息(X,Y;U,V),计算差值得到dx、dy、du、dv;
S2.判断当前像素与前一个像素是否与屏幕坐标X或Y相邻,若不相邻则执行步骤S4,若相邻则计算当前像素的LOD值D_level,并执行步骤S3;
S3.当计算出另一方向连续像素点的LOD值小于或等于前次的计算值时,则用当前方向相邻像素点更新LOD值,并执行步骤S4;当计算出另一方向连续像素点的LOD值大于前次的计算值,则LOD取值调整为另一方向相邻像素点更新LOD值,并执行步骤S4;
S4.更新最终的LOD值为参考值Ref,并更新记录当前像素的(X,Y;U,V)坐标信息值为前次像素的坐标信息值,输出LOD值并结束本像素计算。
作为本发明的进一步改进,所述步骤S2中,若当前像素与前一个像素是否与屏幕坐标X相邻,计算当前像素的LOD值D_level后,执行的步骤S3包括以下步骤:
a1.若XYmajor==0,则用X相邻像素点更新LOD值,直接更新参考LOD值Ref为D_level,并设置lastHandleFlag为1,并执行步骤S4;否则执行步骤a2;
a2.若lastHandleFlag为2且D_level>ref,则当前用X相邻像素点计算的LOD值大于上次迭代用Y相邻点计算的LOD值,用X相邻点的LOD值更新后续LOD值,并执行步骤a3;否则直接执行步骤S4;
a3.用如下设置翻转XYmajor指示:
XYmajor=0
Ref=D_level
lastHandleFlag=1
设置后执行步骤S4。
作为本发明的进一步改进,所述步骤S2中,若当前像素与前一个像素是否与屏幕坐标Y相邻,计算当前像素的LOD值D_level后,执行的步骤S3包括以下步骤:
b1.若XYmajor==1,则用Y相邻像素点更新LOD值,直接更新参考LOD值Ref为D_level,并设置lastHandleFlag为2,并执行步骤S4;否则执行步骤b2;
b2.若lastHandleFlag为1且D_level>ref,则当前用Y相邻像素点计算的LOD值大于上次迭代用X相邻点计算的LOD值,用Y相邻点的LOD更新后续LOD值,并执行步骤b3;否则直接执行步骤S4;
b3.用如下设置翻转XYmajor指示:
XYmajor=1
Ref=D_level
lastHandleFlag=1
设置后执行步骤S4。
作为本发明的进一步改进,所述步骤S2中,计算当前像素的LOD值D_level,其计算过程为:
UVnorm=pow(pow(du,2)+pow(dv,2),0.5)
XYnorm=pow(pow(dx,2)+pow(dy,2),0.5)
L=UVnorm/XYnorm
if(L==0):D_level=0
else:D_leve=log2(L)。
作为本发明的进一步改进,执行步骤S1之前,还包括执行步骤S0:
如果当前像素是纹理单元处理的第一个像素,则将LOD参考值Ref设为0,并执行步骤S4;若当前像素不是第一个像素,则执行步骤S1。
作为本发明的进一步改进,所述步骤S4中,更新的像素坐标信息反馈回步骤S1作为下一次迭代的前一个像素坐标信息。
本发明的有益效果是:本处理方法可让纹理单元按每个像素流水处理,不用等邻近像素在SP处理完成且相关信息到达纹理单元后才能计算该像素LOD值,在大规模并行计算的图形渲染管线芯片如GPU中,减少了整体系统时延,提高了像素填充率,显著提高的硬件处理能力;对比传统计算方法,减少了X和Y邻近像素处理到达纹理单元时间同步,及多个像素信息存储的工作量,减轻了硬件负担,易于硬件实现。
附图说明
图1是本发明现有技术中每个像素LOD值的计算示意图;
图2是本发明中纹理单元的结构图;
图3是本发明中易于硬件实现的mipmap LOD处理方法的流程图。
具体实施方式
为了使本发明的目的、技术方案及优点更加清楚明白,以下结合附图及实施例,对本发明进行进一步详细说明。
如图2所示,当前构架中的纹理单元(Texture)结构图,Texture的上级为片段着色器(FS shader),FS shader由多个SP流处理器组成。多个流处理器并行处理像素信息,处理完成后发送像素信息给纹理单元用于每个像素LOD的计算。纹理单元每次随机接收一个SP处理之后的像素的信息进行LOD的计算。
由于mipmap主要解决像素在纹理空间中映射为方形区域的场景,X和Y方向相邻像素在纹理空间中的距离差异不是很大。可以先假定使用按X或Y某一个方向上连续的像素点计算出的LOD,对于非连续像素点,可以复用上一次连续像素点计算出的LOD。同时引入X和Y方向的纠偏机制,当某次计算出的另一方向连续像素点的LOD大于前次的计算值,可认为此时LOD取值需调整方向。基于此种策略,可以保证每个像素的LOD接近按传统方式计算的LOD值,每像素LOD平均绝对误差小于0.1。
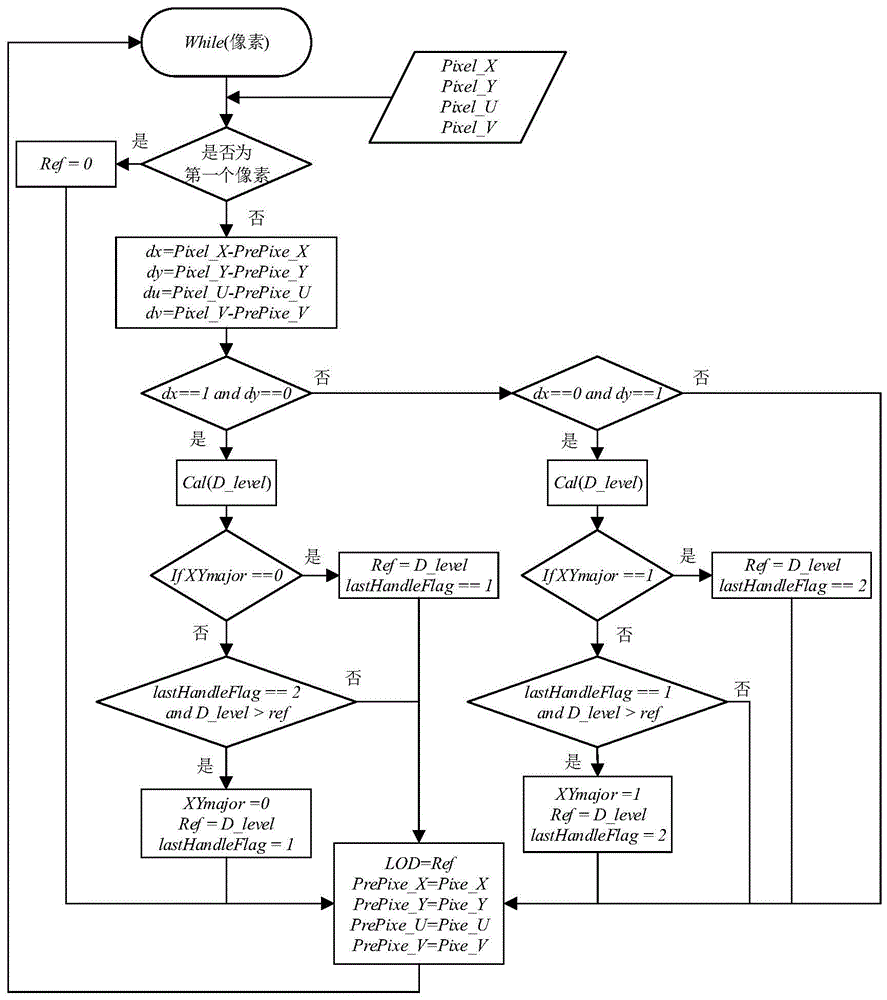
如图3所示,具体的计算方法如下:
Step1:如果当前像素是纹理单元处理的第一个像素,由于没有上一个像素信息,则将LOD参考值Ref设为0,并执行step11;若不是第一个像素,则执行step2。
Step2:基于当前像素及前一个像素坐标信息,计算dx,dy,du,dv:
dx=Pixel_X-PrePixel_X
dy=Pixel_Y-PrePixel_Y
du=Pixel_U-PrePixel_U
dv=Pixel_V-PrePixel_V。
Step3:判断当前像素与前一个像素是否为屏幕坐标X相邻,公式如下:
dx==1&&dy==0
若不相邻,执行step7;否则计算当前像素的LOD值D_level,计算公式如下:
UVnorm=pow(pow(du,2)+pow(dv,2),0.5)
XYnorm=pow(pow(dx,2)+pow(dy,2),0.5)
L=UVnorm/XYnorm
if(L==0):D_level=0
else:D_leve=log2(L)
计算完毕后执行Step4。式中,pow表示计算x的y次幂,pow(x,0.5)表示求x的0.5次幂,既求x的开方。
Step4:若XYmajor==0,表示应该用X相邻像素点更新LOD,直接更新参考LOD值Ref为D_level,并设置lastHandleFlag为1,并执行step11;否则执行step5。
Step5:若lastHandleFlag为2且D_level>ref,表明当前用X相邻像素点计算的LOD值大于上次迭代用Y相邻点计算的LOD值,之后应该用X相邻点的LOD更新后续LOD值,执行step6;否则直接执行step11。
Step6:用如下设置翻转XYmajor指示,之后执行step11。
XYmajor=0
Ref=D_level
lastHandleFlag=1
Step7:判断当前像素与前一个像素是否为屏幕坐标Y相邻,公式如下:
dx==0&&dy==1
若不紧排,执行step11;否则按Step3中的公式计算当前像素的LOD值D_level,并执行step8。
Step8:若XYmajor==1表示应该用Y相邻像素点更新LOD值,直接更新参考LOD值Ref为D_level,并设置lastHandleFlag为2,并执行step11;否则执行step9。
Step9:若lastHandleFlag为1且D_level>ref,表明当前用Y相邻像素点计算的LOD值大于上次迭代用X相邻点计算的LOD,之后应该用Y相邻点的LOD更新后续LOD值,执行step10;否则直接执行step11。
Step10:用如下设置翻转XYmajor指示,之后执行step11。
XYmajor=1
Ref=D_level
lastHandleFlag=1
Step11:更新最终的LOD值为参考值Ref,并更新记录当前pixel的(X,Y),(U,V)值为prePixel的值,用于下一次迭代的计算,输出LOD值并结束本像素的计算:
LOD=Ref
PrePixel_X=Pixel_X
PrePixel_Y=Pixel_Y
PrePixel_U=Pixel_U
PrePixel_V=Pixel_V。
上述步骤中,XYmajor指示用X还是Y相邻的点进行计算并更新,XYmajor=0表示用X相邻像素点进行更新,XYmajor=1表示用Y相邻的点进行计算并更新。
lastHandleFlag表示最新一次更新LOD值用的是X相邻的点还是Y相邻的点,初始值为0表示没有用X和Y相邻的点进行计算并更新过LOD,1表示最新一次是用X相邻的点进行的更新,2表示最新一次是用Y相邻的点进行的更新。
引入lastHandleFlag的目的在于限制一种场景,即系统刚运行的时候,运算的另一个方向的LOD时,直接就进行更新,算出来的LOD肯定比初始值ref=0大;例如指定的是XYmajor=0,但是系统一来就获得了两个Y相邻的点,直接算出来LOD>0,直接就进行了更新。为了让系统先计算更新X相邻的点,而不是一来就用Y相邻的点进行更新,因此采用lastHandleFlag进行限制,即当lastHandleFlag=1的时候再用Y相邻的点进行比较。
以上内容是结合具体的优选实施方式对本发明所作的进一步详细说明,不能认定本发明的具体实施只局限于这些说明。对于本发明所属技术领域的普通技术人员来说,在不脱离本发明构思的前提下,还可以做出若干简单推演或替换,都应当视为属于本发明的保护范围。
- 一种面向GPU硬件产生Mipmap多重细节层纹理算法的TLM微结构
- 一种易于硬件实现的图像清晰度评价方法