一种音频降噪方法、装置、设备及存储介质
文献发布时间:2023-06-19 19:07:35
技术领域
本公开涉及数据处理领域,尤其涉及一种音频降噪方法、装置、设备及存储介质。
背景技术
音频录制的过程中,往往会由于环境或者设备等原因,导致录制的音频中存在有噪声的情况,从而造成音频给用户的体验感较差。
目前,对音频进行降噪的工具少之甚少,且仅有的几款降噪工具对音频降噪的效果也不尽人意。
因此,如何实现音频降噪,从而提升音频的音质,是目前亟需解决的技术问题。
发明内容
为了解决上述技术问题或者至少部分地解决上述技术问题,本公开实施例提供了一种音频降噪方法,能够实现对音频进行降噪,从而较好的提升音频的音质。
第一方面,本公开提供了一种音频降噪方法,所述方法包括:
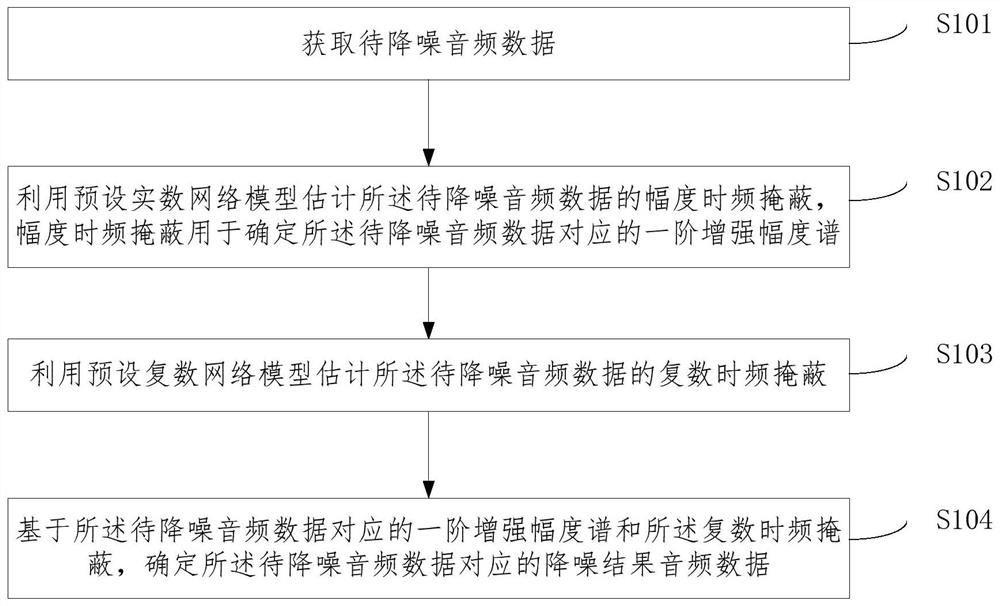
获取待降噪音频数据;
利用预设实数网络模型估计所述待降噪音频数据的幅度时频掩蔽;其中,所述幅度时频掩蔽用于确定所述待降噪音频数据对应的一阶增强幅度谱;
利用预设复数网络模型估计所述待降噪音频数据的复数时频掩蔽;
基于所述待降噪音频数据对应的一阶增强幅度谱和所述复数时频掩蔽,确定所述待降噪音频数据对应的降噪结果音频数据。
一种可选的实施方式中,所述利用预设复数网络模型估计所述待降噪音频数据的复数时频掩蔽,包括:
确定待降噪复数频谱;其中,所述待降噪复数频谱包括基于所述待降噪音频数据对应的一阶增强幅度谱和所述待降噪音频数据的原始相位谱确定的复数频谱,或者,基于所述待降噪音频数据的原始频谱和原始相位谱确定的复数频谱;
将所述待降噪复数频谱输入至预设复数网络模型,经过所述预设复数网络模型的处理后,输出所述待降噪音频数据对应的复数时频掩蔽。
一种可选的实施方式中,所述基于所述待降噪音频数据对应的一阶增强幅度谱和所述复数时频掩蔽,确定所述待降噪音频数据对应的降噪结果音频数据,包括:
基于所述复数时频掩蔽,确定幅度增益和相位增益;
基于所述相位增益和所述待降噪音频数据对应的原始相位谱,确定所述待降噪音频数据对应的相位增强谱;
以及,基于所述幅度增益和所述待降噪音频数据对应的一阶增强幅度谱,确定所述待降噪音频数据对应的二阶增强幅度谱;
基于所述二阶增强幅度谱和所述相位增强谱,确定所述待降噪音频数据对应的降噪结果音频数据。
一种可选的实施方式中,所述预设实数网络模型和所述预设复数网络模型用于构成双阶段时域卷积网络TCN模型。
一种可选的实施方式中,所述利用预设实数网络模型估计所述待降噪音频数据的幅度时频掩蔽之前,还包括:
利用采样率高于预设采样率阈值的音频训练样本,对所述双阶段TCN模型进行训练。
一种可选的实施方式中,所述利用采样率高于预设采样率阈值的音频训练样本,对所述双阶段TCN模型进行训练之前,还包括:
对所述音频训练样本进行预设数据增广处理,得到增广后音频训练样本;
相应的,所述利用采样率高于预设采样率阈值的音频训练样本,对所述双阶段TCN模型进行训练,包括:
利用所述增广后音频训练样本,对所述双阶段TCN模型进行训练;其中,所述增广后音频训练样本的采样率高于预设采样率阈值。
第二方面,本公开提供了一种音频降噪装置,所述装置包括:
获取模块,用于获取待降噪音频数据;
第一估计模块,用于利用预设实数网络模型估计所述待降噪音频数据的幅度时频掩蔽;其中,所述幅度时频掩蔽用于确定所述待降噪音频数据对应的一阶增强幅度谱;
第二估计模块,用于利用预设复数网络模型估计所述待降噪音频数据的复数时频掩蔽;
第一确定模块,用于基于所述待降噪音频数据对应的一阶增强幅度谱和所述复数时频掩蔽,确定所述待降噪音频数据对应的降噪结果音频数据。
第三方面,本公开提供了一种计算机可读存储介质,所述计算机可读存储介质中存储有指令,当所述指令在终端设备上运行时,使得所述终端设备实现上述的方法。
第四方面,本公开提供了一种设备,包括:存储器,处理器,及存储在所述存储器上并可在所述处理器上运行的计算机程序,所述处理器执行所述计算机程序时,实现上述的方法。
第五方面,本公开提供了一种计算机程序产品,所述计算机程序产品包括计算机程序/指令,所述计算机程序/指令被处理器执行时实现上述的方法。
本公开实施例提供的技术方案与现有技术相比至少具有如下优点:
本公开实施例提供了一种音频降噪方法,首先,获取待降噪音频数据,然后利用预设实数网络模型估计待降噪音频数据的幅度时频掩蔽,能够得到待降噪音频数据对应的一阶增强幅度谱。进而,利用预设复数网络模型估计该待降噪音频数据的复数时频掩蔽,并结合一阶增强幅度谱和复数时频掩蔽,确定待降噪音频数据对应的降噪结果音频数据。本公开实施例利用预设实数网络模型增强待降噪音频数据的幅度谱,以及利用预设复数网络模型同时增强待降噪音频数据的幅度谱和相位谱,可见,本公开实施例能够实现对待降噪音频数据的降噪处理,从而较好的提升音频的音质。
附图说明
此处的附图被并入说明书中并构成本说明书的一部分,示出了符合本公开的实施例,并与说明书一起用于解释本公开的原理。
为了更清楚地说明本公开实施例或现有技术中的技术方案,下面将对实施例或现有技术描述中所需要使用的附图作简单地介绍,显而易见地,对于本领域普通技术人员而言,在不付出创造性劳动性的前提下,还可以根据这些附图获得其他的附图。
图1为本公开实施例提供的一种音频降噪方法的流程图;
图2为本公开实施例提供的一种双阶段TCN模型的示意图;
图3为本公开实施例提供的一种音频降噪装置的结构示意图;
图4为本公开实施例提供的一种音频降噪设备的结构示意图。
具体实施方式
为了能够更清楚地理解本公开的上述目的、特征和优点,下面将对本公开的方案进行进一步描述。需要说明的是,在不冲突的情况下,本公开的实施例及实施例中的特征可以相互组合。
在下面的描述中阐述了很多具体细节以便于充分理解本公开,但本公开还可以采用其他不同于在此描述的方式来实施;显然,说明书中的实施例只是本公开的一部分实施例,而不是全部的实施例。
由于录制环境或者设备等原因,导致录制的音频中可能存在噪声,使得音频的音质较差,影响用户体验。其中,音频中的噪声可以分为平稳噪声和非平稳噪声至少两种,平稳噪声是指噪声统计特性不会随时间变化,常见的有白噪声和粉噪声等;而非平稳噪声是指噪声统计特性随时间变化,常见的如键盘声、鼠标点击声等。
目前,对音频进行降噪的工具可以采用人工智能AI降噪模型实现,但是,目前的AI降噪模型通常对于平稳噪声有较好的抑制作用,但是对非平稳噪声的抑制作用较弱,从而导致目前的降噪工具对音频的降噪效果不能保证用户的体验。
实际应用中,音频降噪工具往往采用单一的网络模型实现对音频的降噪,虽然网络模型的复杂度较低,但是难以保证对音频的降噪效果,例如尤其难以保证对音频中非平稳噪声的抑制效果。为此,本公开实施例提供了一种音频降噪方法,利用预设实数网络模型和预设复数网络模型分别对待降噪音频数据进行降噪处理,进而综合二者的降噪结果确定出待降噪音频数据对应的降噪结果音频数据,可见,相比于采用单一的网络模型对音频进行降噪,本公开实施例能够对非平稳噪声有较好的抑制效果,从而保证对音频整体的降噪效果,进而较好的提升音频的音质。
具体的,本公开实施例获取待降噪音频数据,然后利用预设实数网络模型估计待降噪音频数据的幅度时频掩蔽,能够得到待降噪音频数据对应的一阶增强幅度谱。进而,利用预设复数网络模型估计该待降噪音频数据的复数时频掩蔽,并结合一阶增强幅度谱和复数时频掩蔽,确定待降噪音频数据对应的降噪结果音频数据。
本公开实施例利用预设实数网络模型增强待降噪音频数据的幅度谱,以及利用预设复数网络模型同时增强待降噪音频数据的幅度谱和相位谱,可见,本公开实施例能够实现对待降噪音频数据的降噪处理,同时保证降噪效果,进而较好的提升音频的音质。
基于此,本公开实施例提供了一种音频降噪方法,参考图1,为本公开实施例提供的一种音频降噪方法的流程图,该方法包括:
S101:获取待降噪音频数据。
本公开实施例中的待降噪音频数据可以是任意的音频片段,其中,该音频片段也可以是从视频中提取出的音频片段等。本公开实施例对于待降噪音频数据不做限制。
实际应用中,本公开实施例可以在音频录制阶段对待降噪音频数据进行实时降噪处理,也可以在音频编辑阶段对待降噪音频数据进行降噪处理。本公开实施例对于降噪场景不做限制。
S102:利用预设实数网络模型估计所述待降噪音频数据的幅度时频掩蔽。
其中,所述幅度时频掩蔽用于确定所述待降噪音频数据对应的一阶增强幅度谱。
本公开实施例中,首先利用音频训练样本对预设实数网络模型进行训练,得到经过训练的预设实数网络模型,用于对待降噪音频数据进行幅度增强处理。其中,预设实数网络模型可以基于任一种AI模型实现,例如预设实数网络模型可以由时域卷积网络(Temporal Convolutional Network;TCN)实现,也可以由递归神经网络(RecurrentNeural Network;RNN)实现等。
本公开实施例中,在预设实数网络模型经过训练之后,可以将待降噪音频数据输入至该预设实数网络模型中进行处理,有该预设实数网络模型输出待降噪音频数据的幅度时频掩蔽。其中,幅度时频掩蔽用于表示增强幅度谱与原始幅度谱之间的比例关系。
在预设实数网络模型对待降噪音频数据的频谱进行幅度增强后,得到待降噪音频数据的幅度时频掩蔽,然后,通过将该幅度时频掩蔽与待降噪音频数据的原始幅度谱相乘,得到待降噪音频数据的增强幅度谱,作为一阶增强幅度谱。其中,该一阶增强幅度谱是待降噪音频数据的频谱经过预设实数网络模型进行幅度增强后的幅度谱。
S103:利用预设复数网络模型估计所述待降噪音频数据的复数时频掩蔽。
本公开实施例中,首先利用音频训练数据对预设复数网络模型进行训练,得到经过训练的预设复数网络模型,用于对待降噪音频数据进行幅度和相位的同时增强处理。其中,预设复数网络模型可以基于任一种AI模型实现,例如预设复数网络模型可以由时域卷积网络(Temporal Convolutional Network;TCN)实现,也可以由递归神经网络(RecurrentNeural Network;RNN)实现等。
一种可选的实施方式中,在利用经过训练的预设复数网络模型对待降噪音频数据进行降噪处理之前,首先将基于待降噪音频数据的原始频谱和原始相位谱确定的复数频谱,确定为待降噪复数频谱。然后,将该待降噪复数频谱输入至预设复数网络模型中进行处理,由预设复数网络模型输出待降噪音频数据对应的复数时频掩蔽。其中,复数时频掩蔽用于表征增强频谱与原始频谱之间的比例关系,复数时频掩蔽包括实部部分和虚部部分。
为了提升降噪的效果,本公开实施例还可以将基于待降噪音频数据对应的一阶增强幅度谱和原始相位谱确定的复数频谱,确定为待降噪复数频谱,以便预设复数网络模型能够在预设实数网络模型降噪的基础上,进一步的对待降噪音频数据的频谱的幅度和相位进行增强,从而进一步的提升降噪的效果。
具体的,一种可选的实施方式中,首先获取待降噪音频数据的原始相位谱,然后将基于待降噪音频数据对应的一阶增强幅度谱和原始相位谱确定的频谱,确定为待降噪复数频谱。进而,将该待降噪复数频谱输入至预设复数网络模型中进行处理,由预设复数网络模型输出待降噪音频数据对应的复数时频掩蔽。
S104:基于所述待降噪音频数据对应的一阶增强幅度谱和所述复数时频掩蔽,确定所述待降噪音频数据对应的降噪结果音频数据。
本公开实施例中,经过预设实数网络模型对待降噪音频数据的幅度增强,以及预设复数网络模型对待降噪音频数据的幅度和相位的同时增强之后,分别得到待降噪音频数据对应的一阶增强幅度谱以及复数时频掩蔽。然后,基于待降噪音频数据对应的一阶增强幅度谱和复数时频掩蔽,确定待降噪音频数据对应的降噪结果音频数据,实现对待降噪音频的降噪处理。
一种可选的实施方式中,首先,基于复数时频掩蔽确定幅度增益和相位增益。其中,幅度增益用于表征预设复数网络模型对待降噪音频数据的频谱的幅度增强情况,相位增益用于表征预设复数网络模型对待降噪音频数据的频谱的相位增强情况。然后,基于相位增益和待降噪音频数据对应的原始相位谱,确定待降噪音频数据对应的相位增强谱。以及,基于幅度增益和待降噪音频数据对应的一阶增强幅度谱,确定待降噪音频数据对应的二阶增强幅度谱。其中,所述二阶增强幅度谱为待降噪音频数据经过预设实数网络模型和预设复数网络模型进行幅度增强得到的幅度谱。进而,基于二阶增强幅度谱和相位增强谱,确定待降噪音频数据对应的增强频谱,并基于该增强频谱确定待降噪音频数据对应的降噪结果音频数据。
实际应用中,可以利用公式(1)和(2),分别计算幅度增益和相位增益,以下为公式(1)和(2):
其中,
另外,可以利用公式(3)计算待降噪音频数据对应的增强频谱,以下为公式(3):
其中,
在获取到待降噪音频数据对应的增强频谱之后,通过反傅里叶变换等处理,得到待降噪音频数据对应的降噪结果音频数据。
可见,本公开实施例提供的音频降噪方法中,首先,获取待降噪音频数据,然后利用预设实数网络模型估计待降噪音频数据的幅度时频掩蔽,能够得到待降噪音频数据对应的一阶增强幅度谱。进而,利用预设复数网络模型估计该待降噪音频数据的复数时频掩蔽,并结合一阶增强幅度谱和复数时频掩蔽,确定待降噪音频数据对应的降噪结果音频数据。本公开实施例利用预设实数网络模型增强待降噪音频数据的幅度谱,以及利用预设复数网络模型同时增强待降噪音频数据的幅度谱和相位谱,可见,本公开实施例能够实现对待降噪音频数据的降噪处理,从而较好的提升音频的音质。
由于TCN模型相比于其他网络模型在音频降噪领域具有更好的效果,因此,本公开实施例可以基于TCN模型实现预设实数网络模型和预设复数网络模型。另外,为了进一步提高音频降噪的效果,本公开实施例可以利用双阶段时域卷积网络TCN模型对音频进行降噪处理,从而较大程度的改善音频的音质。
参考图2,为本公开实施例提供的一种双阶段TCN模型的示意图。其中,双阶段TCN模型包括实数TCN模型和复数TCN模型,Y(n)用于表示待降噪音频数据。
实际应用中,在获取到Y(n)之后,先后对Y(n)进行短时傅立叶变换STFT和Log|.|的处理,并将处理结果输入至实数TCN模型中,经过实数TCN模型的处理后,输出Y(n)对应的幅度时频掩蔽;然后获取Y(n)的原始幅度谱,并计算原始幅度谱与幅度时频掩蔽的乘积,作为Y(n)对应的一阶增强幅度谱
值得注意的是,用于实现实数TCN模型和复数TCN模型的模型架构和参数等,本公开实施例不做限制。
实际应用中,在利用双阶段TCN模型对音频进行降噪之前,首先对双阶段TCN模型进行训练。具体的,可以利用采样率高于预设采样率阈值的音频训练数据,对双阶段TCN模型进行训练,以便经过训练的双阶段TCN模型能够对采样率较高的音频数据有较好的降噪效果。其中,预设采样率阈值可以为大于16K的数值。
一种可选的实施方式中,可以采用时域损失函数SISNR对双阶段TCN模型进行训练。其中,针对时域损失函数SISNR在此不做过多介绍。
另外,为了提升双阶段TCN模型的鲁棒性,在对双阶段TCN模型进行训练之前,可以对音频训练样本进行预设数据增广处理,以丰富音频训练样本的多样性。
其中,预设数据增广处理可以包括按一定的概率对音频训练样本进行高通、低通、带通、设置不同音量和/或均衡等处理操作。
实际应用中,在对音频训练样本进行预设数据增广处理,得到增广后音频训练样本之后,可以利用增广后音频训练样本,对双阶段TCN模型进行训练。
一种可选的实施方式中,增广后音频训练样本的采样率可以高于预设采样率阈值,以便保证双阶段TCN模型对高采样率的音频数据降噪处理的鲁棒性。
本公开实施例提供的音频降噪方法能够利用双阶段的TCN模型实现对音频的降噪,尤其对音频中的非稳定性噪声的抑制效果较好,进一步提升了降噪的效果,改善音频的音质,提升用户的体验。
基于上述方法实施例,本公开还提供了一种音频降噪装置,参考图3,为本公开实施例提供的一种音频降噪装置的结构示意图,所述装置包括:
获取模块301,用于获取待降噪音频数据;
第一估计模块302,用于利用预设实数网络模型估计所述待降噪音频数据的幅度时频掩蔽;其中,所述幅度时频掩蔽用于确定所述待降噪音频数据对应的一阶增强幅度谱;
第二估计模块303,用于利用预设复数网络模型估计所述待降噪音频数据的复数时频掩蔽;
确定模块304,用于基于所述待降噪音频数据对应的一阶增强幅度谱和所述复数时频掩蔽,确定所述待降噪音频数据对应的降噪结果音频数据。
一种可选的实施方式中,所述第二估计模块,包括:
第一确定子模块,用于确定待降噪复数频谱;其中,所述待降噪复数频谱包括基于所述待降噪音频数据对应的一阶增强幅度谱和所述待降噪音频数据的原始相位谱确定的复数频谱,或者,基于所述待降噪音频数据的原始频谱和原始相位谱确定的复数频谱;
第一处理子模块,用于将所述待降噪复数频谱输入至预设复数网络模型,经过所述预设复数网络模型的处理后,输出所述待降噪音频数据对应的复数时频掩蔽。
一种可选的实施方式中,所述确定模块,包括:
第二确定子模块,用于基于所述复数时频掩蔽,确定幅度增益和相位增益;
第三确定子模块,用于基于所述相位增益和所述待降噪音频数据对应的原始相位谱,确定所述待降噪音频数据对应的相位增强谱;
第四确定子模块,用于基于所述幅度增益和所述待降噪音频数据对应的一阶增强幅度谱,确定所述待降噪音频数据对应的二阶增强幅度谱;
第五确定子模块,用于基于所述二阶增强幅度谱和所述相位增强谱,确定所述待降噪音频数据对应的降噪结果音频数据。
一种可选的实施方式中,所述预设实数网络模型和所述预设复数网络模型用于构成双阶段时域卷积网络TCN模型。
一种可选的实施方式中,所述装置还包括:
训练模块,用于利用采样率高于预设采样率阈值的音频训练样本,对所述双阶段TCN模型进行训练。
一种可选的实施方式中,所述装置还包括:
增广模块,用于对所述音频训练样本进行预设数据增广处理,得到增广后音频训练样本;
相应的,所述训练模块,具体用于:
利用所述增广后音频训练样本,对所述双阶段TCN模型进行训练;其中,所述增广后音频训练样本的采样率高于预设采样率阈值。
本公开实施例提供的音频降噪装置中,首先,获取待降噪音频数据,然后利用预设实数网络模型估计待降噪音频数据的幅度时频掩蔽,能够得到待降噪音频数据对应的一阶增强幅度谱。进而,利用预设复数网络模型估计该待降噪音频数据的复数时频掩蔽,并结合一阶增强幅度谱和复数时频掩蔽,确定待降噪音频数据对应的降噪结果音频数据。本公开实施例利用预设实数网络模型增强待降噪音频数据的幅度谱,以及利用预设复数网络模型同时增强待降噪音频数据的幅度谱和相位谱,可见,本公开实施例能够实现对待降噪音频数据的降噪处理,从而较好的提升音频的音质。
除了上述方法和装置以外,本公开实施例还提供了一种计算机可读存储介质,计算机可读存储介质中存储有指令,当所述指令在终端设备上运行时,使得所述终端设备实现本公开实施例所述的音频降噪方法。
本公开实施例还提供了一种计算机程序产品,所述计算机程序产品包括计算机程序/指令,所述计算机程序/指令被处理器执行时实现本公开实施例所述的音频降噪方法。
另外,本公开实施例还提供了一种音频降噪设备,参见图4所示,可以包括:
处理器401、存储器402、输入装置403和输出装置404。音频降噪设备中的处理器401的数量可以一个或多个,图4中以一个处理器为例。在本公开的一些实施例中,处理器401、存储器402、输入装置43和输出装置404可通过总线或其它方式连接,其中,图4中以通过总线连接为例。
存储器402可用于存储软件程序以及模块,处理器401通过运行存储在存储器402的软件程序以及模块,从而执行音频降噪设备的各种功能应用以及数据处理。存储器402可主要包括存储程序区和存储数据区,其中,存储程序区可存储操作系统、至少一个功能所需的应用程序等。此外,存储器402可以包括高速随机存取存储器,还可以包括非易失性存储器,例如至少一个磁盘存储器件、闪存器件、或其他易失性固态存储器件。输入装置403可用于接收输入的数字或字符信息,以及产生与音频降噪设备的用户设置以及功能控制有关的信号输入。
具体在本实施例中,处理器401会按照如下的指令,将一个或一个以上的应用程序的进程对应的可执行文件加载到存储器402中,并由处理器401来运行存储在存储器402中的应用程序,从而实现上述音频降噪设备的各种功能。
需要说明的是,在本文中,诸如“第一”和“第二”等之类的关系术语仅仅用来将一个实体或者操作与另一个实体或操作区分开来,而不一定要求或者暗示这些实体或操作之间存在任何这种实际的关系或者顺序。而且,术语“包括”、“包含”或者其任何其他变体意在涵盖非排他性的包含,从而使得包括一系列要素的过程、方法、物品或者设备不仅包括那些要素,而且还包括没有明确列出的其他要素,或者是还包括为这种过程、方法、物品或者设备所固有的要素。在没有更多限制的情况下,由语句“包括一个……”限定的要素,并不排除在包括所述要素的过程、方法、物品或者设备中还存在另外的相同要素。
以上所述仅是本公开的具体实施方式,使本领域技术人员能够理解或实现本公开。对这些实施例的多种修改对本领域的技术人员来说将是显而易见的,本文中所定义的一般原理可以在不脱离本公开的精神或范围的情况下,在其它实施例中实现。因此,本公开将不会被限制于本文所述的这些实施例,而是要符合与本文所公开的原理和新颖特点相一致的最宽的范围。
- 一种音频设备的确定方法、装置、设备和存储介质
- 一种滤波降噪方法、装置、电子设备及存储介质
- 一种音频检测方法、装置、设备及计算机可读存储介质
- 一种音频信号的调节方法、装置、设备及计算机存储介质
- 一种音频播放方法、装置、设备及存储介质
- 音频降噪滤波方法、降噪滤波装置、电子设备及存储介质
- 音频降噪、音频降噪模型的处理方法、装置、设备和介质