一种用于支撑辅助诊疗模型研发的方法
文献发布时间:2023-06-19 19:27:02
技术领域
本发明涉及医学人工智能技术,具体是一种用于支撑辅助诊疗模型研发的方法。
背景技术
人工智能医疗器械是指采用AI(Artificial Intelligence,简称AI)技术实现医疗用途的医疗器械,现在越来越多的人工智能技术被应用在医学领域上了。AI技术在辅助治疗、医学影像处理等领域的应用愈发广泛,已成为医疗器械行业的热点和焦点。例如使用传统AI技术的辅助诊疗系统已经有多款产品注册上市了,如乳腺癌、肺结节、结肠息肉等辅助识别软件和心电图分析软件。医学 AI 技术作为当前提升医疗健康服务、降低医疗成本的、最有潜力的技术获得了广泛的关注。然而,使用深度学习等新一代AI技术的辅助诊疗医疗器械却难以在现实临床场景中应用和推广。因为目前研究人员研发一个辅助诊疗AI模型的时候,首先需要去了解,并网上寻找合适的,公开的大规模数据集,其次需要一个一个的下载全部数据,最后再手工组织和预处理数据构成一个场景用于研发AI模型。但是目前研发辅助诊疗AI模型的传统场景和应用辅助诊疗AI模型的真实世界场景有很大的差异:(1)目前传统场景的数据集的特征是:a:所有受试者的类型是已知的;b:所有受试者的数据类型都是相同的,即所有的受试者都是使用同一种诊断策略;c:默认所有的医疗机构具有相同的医疗资源,由于传统场景中的数据集都是有以上特征,所以称传统场景为封闭场景;然而,真实世界场景的数据的特征是:a:只有部分的受试者的类型是已知的;b:受试者的数据类型不完全相同;c:各个医疗机构的医疗资源也有差异;(2)封闭场景的深度学习模型评价指标并不能真正的体现模型的临床价值。因此,使用深度学习等新一代AI技术的辅助诊疗医疗器械难以在现实临床场景中应用和推广,所以提出了一个用于支撑辅助诊疗模型研发的系统,研究人员可以在该系统上构建各种场景去研发各种模型。
发明内容
本发明的目的是针对现有技术的不足,而提供一种用于支撑辅助诊疗模型研发的方法,这种方法提供了多种医疗数据集、数据预处理函数、疾病分类模型和新的临床评价指标,以解决收集大规模数据及其整理、整合等困难,并且研究人员可以构建各种场景用于研发各类模型。
实现本发明目的的技术方案是:
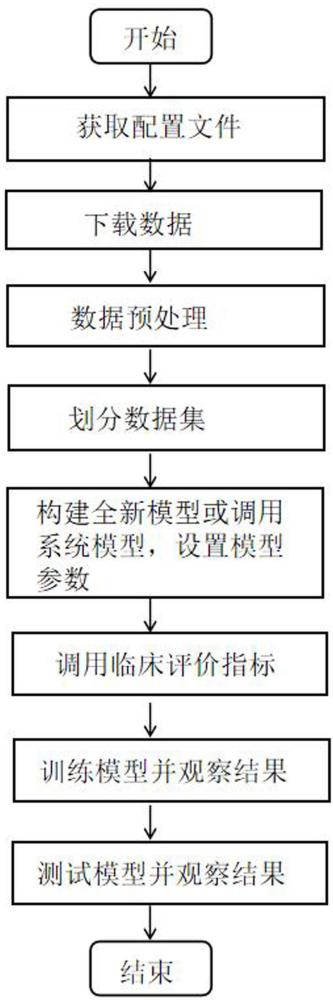
一种用于支撑辅助诊疗模型研发的方法, 包括如下步骤:
1)场景配置:场景配置用于根据用户上传的场景配置文件生成场景需求数据,场景配置文件是高度可配置的、并且系统提供3种场景类型和3种疾病数据集,其中3种场景类型是:封闭场景、数据孤岛场景、开放场景,3种疾病数据集是:阿尔茨海默病神经成像倡议数据集ADNI(Alzheimer's Disease Neuroimaging Initiative,简称ADNI)、 2019新型冠状病毒感染数据集COVID-19(Corona Virus Disease 2019,简称COVID-19)、牙齿数据集Dental,其中,场景配置文件为.ini格式:由一组段section组成、每个段包含一组关键字key及相应的值value, 段的格式为:[SectionName]、KeyName=Value,
SectionName是段名、KeyName是关键字名、Value是关键字对应的设定值,而且,段名必须用“[ ]”括起来,单独占一行,关键字后面紧跟“=”,“=”后面为空或多个值,单独占一行,对文字进行注释时,必须以“;”开头配置文件中具体的各个段及其键值对的含义为:段名information内的关键字定义的是配置文件的信息、关键字name定义的是配置文件的名称、段名dataset内的关键字定义的是需求及其对应的要求、关键字files定义的是下载哪个文件里面的数据、关键字joinorder定义的是文件的合并顺序、 关键字connection定义的是某列的列名作为合并的主键、关键字columns定义的是需要下载的数据、关键字rows定义的是对行数据设定条件、关键字label定义的是标签、关键字partition_number定义的是client数、关键字assigment定义的是在数据孤岛场景中划分client数的条件、关键字fillna定义的是填充空值的指定值、关键字controls 定义的是下载疾病类别的数量、关键字image定义的是下载图像;
2)数据下载:数据下载用于下载场景配置过程生成的场景数据,数据下载功能是基于Flask框架实现从服务器上下载数据到指定路径;
3)数据预处理:数据预处理用于处理场景配置过程生成的场景数据,数据预处理提供以下头部.nii格式图像数据预处理API:重定向到标准空间、图像配准、颅骨剥离函数、偏置场校正、组织分割,需要说明的是:这些API都是系统独立封装的函数,可以单独使用,如果用户要使用系统提供的数据预处理,使用的时候直接调用相应函数名即可;
4)数据划分:数据划分用于根据配置文件选定的数据划分方式去将数据进行划分,数据划分方式有2种:按照预设的划分比例划分为不同的数据集、称随机划分;按照医疗机构的不同划分为不同的数据集、称区域划分,其中,封闭场景和开放场景中的数据集是按预设比例随机划分的、且partition_number=1,数据孤岛场景是按医疗机构的不同进行划分的、且partition_number>1;
5)模型生成:模型生成用于训练、验证和测试模型,模型生成过程提供2种类别的疾病分类模型:图像模型和多模态模型,这些模型都是系统独立封装的类函数,可以单独使用,如果用户要使用系统提供的模型,使用的时候直接调用相应函数名即可,如果用户不使用系统提供的模型,用户可以将自己搭建的模型封装成类函数,使用的时候调用自己的模型函数名;
6)模型评价:模型评价用于评价模型的实际的临床价值,包括:
6-1)受试者收益评价指标:即评价受试者在诊疗过程中身体状况的改善状况,用阿尔茨海默病认知评估量表ADAS-Cog(Alzheimer Disease Assessment Scale-Cognitive, 简称ADAS-Cog)指标来量化模型的临床价值;
6-2)受试者花费评价指标:即评价受试者在诊疗过程中的费用;
6-3)受试者身体损害评价指标:即评价受试者在诊疗过程中受到的损害值,损害值分5个等级,最低损害等级0,最高损害等级5;
7)模型训练:模型训练用于训练已设置好的模型;
8)模型测试:模型测试用于测试已训练好的模型。
与现有技术相比,本技术方案具有如下优点:
1.在本技术方案中,提供了一个高度可配置的场景文件,可以在场景配置文件中填写所需数据及其要求,从而形成不同的场景,且解决了手工组织数据,步骤繁琐,效率低下等困难,且本技术方案提供了多种医疗数据集:ADNI、COVID-19和牙齿数据集,解决了收集大规模数据及其整理、整合等困难,以此方便研究人员可以构建各种场景,从而方便研发不同的AI模型;
2.在本技术方案中,提供了多个可以体现临床价值的新评价指标;
3.本技术方案提供了多种头部.nii格式图像预处理API,用户无需另外学习MRI图像预处理等软件,可以直接调用系统提供的图像预处理API即可,可以免去学习.nii格式图像处理软件的过程。
这种方法提供了多种医疗数据集、数据预处理函数、疾病分类模型和新的临床评价指标,以解决收集大规模数据及其整理、整合等困难,并且研究人员可以构建各种场景用于研发各类模型。
附图说明
图1为实施例中用于支撑辅助诊疗模型研发的系统的总体框架示意图;
图2为实施例中系统的通用的场景配置文件示意图;
图3为实施例的方法流程示意图;
图4为实施例中封闭临床场景配置文件的用例示意图;
图5为实施例中核磁共振图像预处理前后的效果示意图,其中,从左到右依次是原图、图像配准、颅骨剥离图像。
实施方式
下面结合附图和实施例对本发明的内容做进一步的阐述,但不是对本发明的限定。
实施例
一种用于支撑辅助诊疗模型研发的方法, 包括如下步骤:
参照图1、图3,1)场景配置:场景配置用于根据用户上传的场景配置文件生成场景需求数据,场景配置文件是高度可配置的、并且系统提供3种场景类型:封闭场景、数据孤岛场景、开放场景,其中:
场景配置文件为.ini格式:由一组段section组成、每个段包含一组关键字key及相应的值value, 段的格式为:[SectionName]、KeyName=Value,
SectionName是段名、KeyName是关键字名、Value是关键字对应的设定值,而且,段名必须用“[ ]”括起来,单独占一行,关键字后面紧跟“=”,“=”后面为空或多个值,单独占一行,对文字进行注释时,必须以“;”开头;
如图2所示,系统通用的场景配置文件中具体的各个段及其键值对的含义:
段名information内的关键字定义的是配置文件的信息;
关键字name定义的是配置文件的名称;
段名dataset内的关键字定义的是需求及其对应的要求;
关键字files定义的是下载哪个文件里面的数据;
关键字joinorder定义的是文件的合并顺序;
关键字connection定义的是某列的列名作为合并的主键;
关键字columns定义的是需要下载的数据;
关键字rows定义的是对行数据设定条件;
关键字label定义的是标签;
关键字partition_number定义的是client数;
关键字assigment定义的是在数据孤岛场景中划分client数的条件;
关键字fillna定义的是填充空值的指定值;
关键字controls 定义的是下载疾病类别的数量;
关键字image定义的是下载图像;
所述封闭场景为:封闭场景是目前研发模型最常用的场景,包括:所有受试者类型的已知的、所有受试者的数据类型都是相同的即所有的受试者都是使用同一种诊断策略、默认所有的医疗机构具有相同的医疗资源;
所述数据孤岛场景是由于临床数据较为敏感、且难以以公开集中的方式为研发人员研发深度学习模型提供支撑,所以基于对受试者的隐私,数据的安全和价值所延伸的场景,包括:受试者类型和数据类型都类似封闭场景、根据医疗机构的不同将形成不同的数据集,从而形成自然的数据孤岛临床场景;
所述开放场景是为了保持真实场景的主要特征,包括:只有部分的受试者的类型是已知的、受试者的数据类型不完全相同、各个医疗机构的医疗资源也不完全相同,本例中,场景为封闭场景,如图4所示,封闭场景配置文件为:
段名:information内的:
关键字name定义了配置文件的名称为closed clinical setting,即封闭临床场景;
段名:dataset段内的:
关键字files定义使用merger@/home/user/ADNI/ADNIMERGE_without_bad_value.csv,image@/home/user/ADNI/image_information.csv两个文件,其中设置merger作为ADNIMERGE_without_bad_value.csv文件的别名,设置image作为image_information.csv文件的别名,需要说明的是,本例中,使用的是ADNI数据集文件;
关键字joinorder定义文件的合并顺序为merger, image;
关键字connection定义merger文件中的RID、VISCODE和image文件中的RID、Visit作为主键合并文件;
关键字columns定义下载merger文件里的RID、VISICODE、SITE、DX、PTGENDER、APOE4、MMSE、AGE和image文件里的RID、Visit、Modelity、Sequence、SavePath;
关键字rows定义Modality列值为MRI的行,选择DX列值不为空的行,选择Sequence列值为1的行;
关键字label定义merger文件里的DX列作为数据集的标签;
关键字partition_number定义值为1,即这是封闭临床常见,一个client;
关键字fillna定义-4填充空值;
关键字controls 定义下载300组认知正常的数据(Normal control,CN)、280组阿尔茨海默症的数据(Alzheimer's disease,AD);
关键字image定义下载实际的图像;
2)数据下载:数据下载用于下载场景配置过程生成的场景数据,数据下载是基于Flask框架实现从服务器上下载数据到指定路径,本例中,系统利用步骤1)生成的580组样本数据下载到用户指定路径;
3)数据预处理:数据预处理用于处理场景配置过程生成的场景数据,数据预处理提供以下头部.nii格式图像数据预处理API:重定向到标准空间、图像配准、颅骨剥离函数、偏置场校正、组织分割,需要说明的是:这些API都是系统独立封装的函数,可以单独使用,如果用户要使用系统提供的数据预处理,使用的时候直接调用相应函数名即可,本例中,系统将步骤2)下载得到数据中不用于训练的Modelity、Sequence列删除,将PTGENDER列中的Male变成1、Female变成0,DX列中的Dementia变成1、CN变成0,将.nii格式的图像进行图像配准和颅骨剥离,图像处理后的效果如图5所示;
4)数据划分:数据划分用于根据配置文件选定的数据划分方式去将数据进行划分,数据划分方式有2种:按照预设的划分比例划分成不同的数据集、称随机划分;按照医疗机构的不同划分成不同的数据集、称区域划分,其中,封闭场景和开放场景中的数据集是按预设比例随机划分的、且partition_number=1,数据孤岛场景是按医疗机构的不同进行划分的、且partition_number>1,本例中,采用随机划分,首先将数据580组数据打乱,然后按照8:2的比例,将数据集划分为训练集和测试集;
5)模型生成:模型生成用于训练、验证和测试模型,模型生成提供3种类别的疾病分类模型:非图像模型、图像模型和多模态模型,这些模型都是系统独立封装的类函数,可以单独使用,如果用户要使用系统提供的模型,使用的时候直接调用相应函数名即可,如果用户不使用系统提供的模型,用户可以自己搭建新的模型,做相应的调用即可,本例中,采用的是多模态模型中函数名为MLP_A,该模型设置的参数有:learning_rate为0.01、drop_rate为0.5、batch_size为10、train_epochs为300、loss_function为torch.nn.CrossEntropyLoss();
6)模型评价:模型评价用于评价模型的实际的临床价值,包括:
6-1)受试者收益评价指标:即评价受试者在诊疗过程中身体状况的改善状况, 用阿尔茨海默病认知评估量表ADAS-Cog指标来量化模型的临床价值;
6-2)受试者花费评价指标:即评价受试者在诊疗过程中的费用;
6-3)受试者身体损害评价指标:即评价受试者在诊疗过程中受到的损害值,损害值分5个等级,最低损害等级0,最高损害等级5,本例中,采用系统提供的收益指标、花费指标和损害指标用于评价模型;
7)模型训练:模型训练用于训练已设置好的模型,以上步骤完成后,载入训练集去训练模型直至损失函数收敛,并观察训练时收益指标、花费指标和损害指标的结果,如果指标未达到预设要求,则需要调整模型结构或参数,直至训练得到一个达到预设指标要求的模型,最后得到训练后的模型;
8)模型测试:模型测试用于测试已训练好的模型,载入测试集去测试步骤7)训练好的模型,并观察测试时收益指标、花费指标和损害指标的结果,如果指标未达到预设要求,则需要重新训练模型,直到得到一个符合预设要求的模型;
至此, 研发出一个完整的阿尔茨海默症分类模型。
- 一种用于汽车前舱盖支撑的支撑结构及其使用方法
- 一种用于微距摄影机的三脚架辅助支撑装置
- 一种分级诊疗支撑服务方法和平台
- 诊疗辅助信息的生成方法、模型训练方法、装置、设备以及存储介质
- 诊疗辅助信息的生成方法、模型训练方法、装置、设备以及存储介质