一种洪水救援场景下深度学习数据集的制作方法及系统
文献发布时间:2023-06-19 19:27:02
技术领域
本发明涉及深度学习技术领域,尤其涉及一种洪水救援场景下深度学习数据集的制作方法及系统。
背景技术
深度学习技术三要素,也即三大支柱:算法、数据、算力。在这三要素中,科研人员大多聚焦于算法,算力通过经费购买GPU硬件或租用云计算资源达成,而数据往往是容易忽视的环节。
优良的数据集能让算法训练出来的模型泛化性能优良、识别率高。对于目标检测识别任务,优良的数据集,在算法不变的情况下能让模型识别效果更好,场景适应性更好。
对于洪水救援场景,本申请发明人在实施本发明的过程中,发现现有技术中存在如下难题和技术问题:
首先是数据来源的问题,现今很多网站为防护数据、保护隐私,对爬虫进行的技术性屏蔽,致使爬虫工具无法使用;然后是数据样本数量的问题,虽然对于洪水救援场景的图片数量较多,但是存在重复的图片,或者图片不适合标注等,从而导致数据集制作十分困难,并且效率较低。
发明内容
本发明提供了一种洪水救援场景下深度学习数据集的制作方法及系统,用以解决或者至少部分解决现有技术中存在的数据集制作困难和效率较低的技术问题。
为了解决上述技术问题,本发明采用的技术方案如下:
第一方面提供了一种洪水救援场景下深度学习数据集的制作方法,包括:
使用网页元素获取技术采集洪水救援场景下的图片数据;
采用预先训练好的目标检测模型对采集的图片数据进行检测,分为落水人员图片和其他图片,分别保存至正样本文件夹和洪水场景文件夹中;
对正样本文件夹中包含的落水人员图片进行预处理;
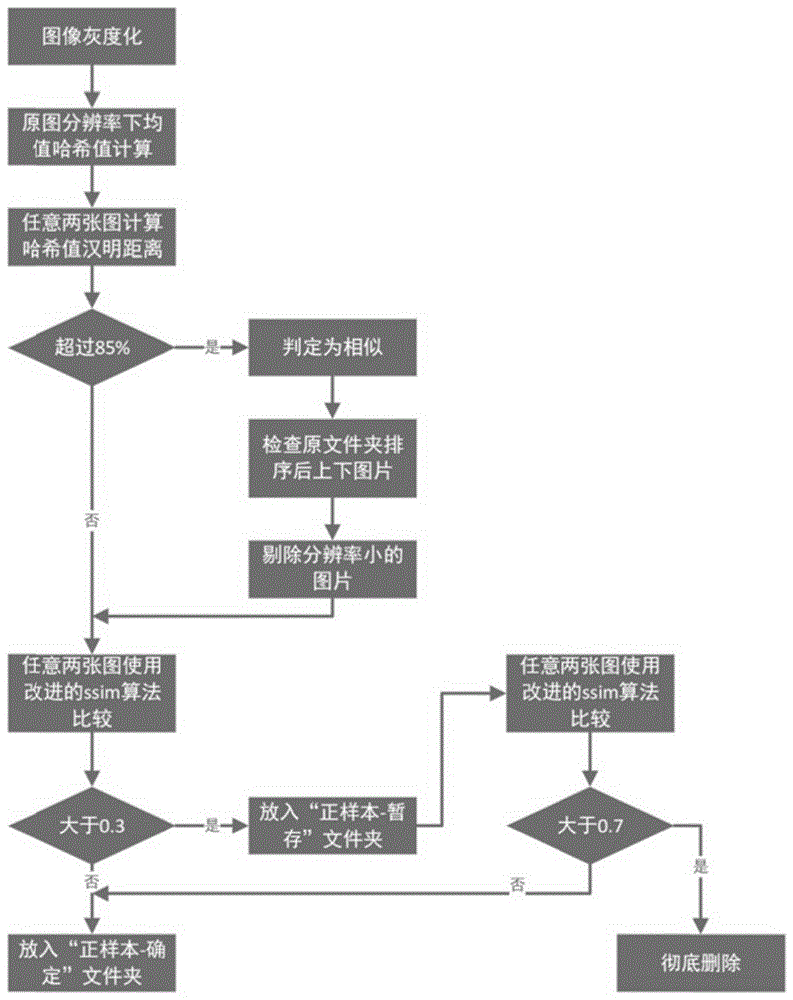
采用均值哈希和结构相似性的方法对预处理后的落水人员图片进行去重,具体包括:将落水人员图片的尺寸调整为500*500,对尺寸调整后的图片进行灰度化处理,并计算图像灰度平均值,根据每个像素的灰度值与图像灰度平均值之间的关系,得到每个像素的哈希值,并进一步得到图片的指纹;根据两张图片的指纹大小,计算两张图片的汉明距离,如果两张图片的汉明距离大于距离阈值,则判定为两张图片相似,并根据两张图片的分辨率确定剔除哪一张图片;采用改进的结构对比函数对保留的图片两两进行计算,根据结构相似性阈值与计算的函数值之间的关系以及分辨率的大小,判断删除哪一张图片,其中,改进的结构对比函数中,亮度对比函数的指数设置为0.5,对比度对比函数的指数设置为1,结构对比函数的指数设置为1.5;
对正样本文件夹中保留下的落水人员图片作为正样本,洪水场景文件夹中包含的图片作为负样本,并采用基于多标签信息融合的方式对正样本和负样本进行标注;
采用图像数据扩增的方式对标注后的样本进行处理,得到最终的深度学习数据集。
在一种实施方式中,在采用预先训练好的目标检测模型对采集的图片数据进行检测,分为落水人员图片和其他图片之后,所述方法还包括:
对正样本文件夹中的图片进行检查确认。
在一种实施方式中,对正样本文件夹中包含的落水人员图片进行预处理,包括:
将正样本文件夹中包含的图片按照分辨率大小进行排序;
依次探测排序后的图片的边是否存在黑边,如果存在黑边,则将对应的图片移动至待去除黑边文件夹;
对待去除黑边文件夹中的图片进行黑边去除;
对保留在正样本文件夹中的图片以及待去除黑边文件夹中经过黑边去除后的图片进行字符探测,如果图片的字符数超过字符数量阈值,则将对应的图片剪切到待去除字幕文件夹;
对待去除字幕文件夹中的图片进行字幕去除;
将进行字幕去除后的图片剪切至正样本文件夹中。
在一种实施方式中,结构相似性阈值包括第一阈值和第二阈值,且第二阈值大于第一阈值,计算的函数值包括第一函数值和第二函数值,根据结构相似性阈值与计算的函数值之间的关系以及分辨率的大小,判断删除哪一张图片,包括:
如果计算的第一函数值大于第一阈值,则将其中分辨率较小的图片剪切到正样本-暂存文件夹;
对正样本-暂存文件夹的图片采用改进的结构对比函数两两进行计算,判断计算得到的第二函数值是否大于第二阈值,如果大于,则将第二函数值对应的两张图片都删除,否则,将第二函数值对应的两张图片复制到正样本文件夹。
在一种实施方式中,采用基于多标签信息融合的方式对正样本和负样本进行标注,包括:
对正样本和负样本中的图片中的困难目标,进一步分为遮挡和模糊两种属性,其中困难目标为标注情况复杂的目标。
基于同样的发明构思,本发明第二方面提供了一种洪水救援场景下深度学习数据集的制作系统,包括:
图片数据获取模块,用于使用网页元素获取技术采集洪水救援场景下的图片数据;
图片检测模块,用于采用预先训练好的目标检测模型对采集的图片数据进行检测,分为落水人员图片和其他图片,分别保存至正样本文件夹和洪水场景文件夹中;
预处理模块,用于对正样本文件夹中包含的落水人员图片进行预处理;
采用均值哈希和结构相似性的方法对预处理后的落水人员图片进行去重,具体包括:将落水人员图片的尺寸调整为500*500,对尺寸调整后的图片进行灰度化处理,并计算图像灰度平均值,根据每个像素的灰度值与图像灰度平均值之间的关系,得到每个像素的哈希值,并进一步得到图片的指纹;根据两张图片的指纹大小,计算两张图片的汉明距离,如果两张图片的汉明距离大于距离阈值,则判定为两张图片相似,并根据两张图片的分辨率确定剔除哪一张图片;采用改进的结构对比函数对保留的图片两两进行计算,根据结构相似性阈值与计算的函数值之间的关系以及分辨率的大小,判断删除哪一张图片,其中,改进的结构对比函数中,亮度对比函数的指数设置为0.5,对比度对比函数的指数设置为1,结构对比函数的指数设置为1.5;
对正样本文件夹中保留下的落水人员图片作为正样本,洪水场景文件夹中包含的图片作为负样本,并采用基于多标签信息融合的方式对正样本和负样本进行标注;
采用图像数据扩增的方式对标注后的样本进行处理,得到最终的深度学习数据集。
基于同样的发明构思,本发明第三方面提供了一种计算机可读存储介质,其上存储有计算机程序,该程序被处理器执行时实现第一方面所述的方法。
相对于现有技术,本发明的优点和有益的技术效果如下:
本发明的方法使用网页元素获取技术采集洪水救援场景下的图片数据,可以避免采用爬虫获取数据的局限性,并且采用预先训练好的目标检测模型对采集的图片数据进行了初步检测;然后对正样本文件夹中包含的落水人员图片进行预处理;进一步采用均值哈希和结构相似性的方法对预处理后的落水人员图片进行去重,从而可以删除相似的图片,提高样本的质量,再采用基于多标签信息融合的方式对正样本和负样本进行标注;采用图像数据扩增的方式对标注后的样本进行处理,得到最终的深度学习数据集,上述方法可以快速制作洪水救援场景下的深度学习数据集。
附图说明
为了更清楚地说明本发明实施例或现有技术中的技术方案,下面将对实施例或现有技术描述中所需要使用的附图作简单地介绍,显而易见地,下面描述中的附图是本发明的一些实施例,对于本领域普通技术人员来讲,在不付出创造性劳动的前提下,还可以根据这些附图获得其他的附图。
图1为本发明实施例中图片收集的流程图;
图2为本发明实施例中图片预处理的流程图;
图3为本发明实施例中采用均值哈希和结构相似性的方法对预处理后的落水人员图片进行去重的流程图;
图4为本发明实施例中采用基于多标签信息融合的方式的标签属性设置示意图;
图5为本发明实施例中图像数据扩增的处理示意图。
具体实施方式
本发明公开了一种洪水救援场景下深度学习数据集的制作方法及系统,用以改善现有技术中存在的数据集制作困难和效率较低的技术问题。
为使本发明实施例的目的、技术方案和优点更加清楚,下面将结合本发明实施例中的附图,对本发明实施例中的技术方案进行清楚、完整地描述,显然,所描述的实施例是本发明一部分实施例,而不是全部的实施例。基于本发明中的实施例,本领域普通技术人员在没有做出创造性劳动前提下所获得的所有其他实施例,都属于本发明保护的范围。
实施例一
本发明实施例提供了一种洪水救援场景下深度学习数据集的制作方法,包括:
使用网页元素获取技术采集洪水救援场景下的图片数据;
采用预先训练好的目标检测模型对采集的图片数据进行检测,分为落水人员图片和其他图片,分别保存至正样本文件夹和洪水场景文件夹中;
对正样本文件夹中包含的落水人员图片进行预处理;
采用均值哈希和结构相似性的方法对预处理后的落水人员图片进行去重,具体包括:将落水人员图片的尺寸调整为500*500,对尺寸调整后的图片进行灰度化处理,并计算图像灰度平均值,根据每个像素的灰度值与图像灰度平均值之间的关系,得到每个像素的哈希值,并进一步得到图片的指纹;根据两张图片的指纹大小,计算两张图片的汉明距离,如果两张图片的汉明距离大于距离阈值,则判定为两张图片相似,并根据两张图片的分辨率确定剔除哪一张图片;采用改进的结构对比函数对保留的图片两两进行计算,根据结构相似性阈值与计算的函数值之间的关系以及分辨率的大小,判断删除哪一张图片,其中,改进的结构对比函数中,亮度对比函数的指数设置为0.5,对比度对比函数的指数设置为1,结构对比函数的指数设置为1.5;
对正样本文件夹中保留下的落水人员图片作为正样本,洪水场景文件夹中包含的图片作为负样本,并采用基于多标签信息融合的方式对正样本和负样本进行标注;
采用图像数据扩增的方式对标注后的样本进行处理,得到最终的深度学习数据集。
具体实施过程中,对于洪水救援场景数据集的制作时,发现现有的方法存在如下难点和技术问题:
1、标注的数据样本规模要大于10000张。标注一万张图片,首先要找到符合特定场景的图片一万张以上,经实际操作发现,特定场景图片是远大于一万张的(约20000张),因为很多符合特定场景的图片并不适合标注,或者标注出来不适用于样本训练。在搜索这二万张图片的过程中发现,既要符合洪水、江河湖泊等特定救援环境,也要符合有人员落水待救援,通过检索词在各种搜索引擎中查找发现,同时满足条件的图片并不多,每次搜索只有几十张。
2、下载问题。一开始准备爬虫工具,在网上爬取数据。现今很多网站为防护数据、保护隐私,对爬虫进行的技术性屏蔽,致使爬虫工具无法使用。
3、图片重复问题。在前200张的数据收集过程中,就碰到过搜索到的图片为重复图片,当时重复地并不多;而在随后的数据收集中,随着图片数据规模越来越大,重复的图片越来越多,且呈现非线性上升,高峰时收集的一组图片,重复率在20%。且真正的难点,还不是相同的图片,而是相似的图片,完全相同的图片很少,大多数情况下是相似图片;这些图片有的因网站压缩传播色彩有细微不同,有的因网络各渠道转发进行了剪切操作,有的甚至是同一场景同一落水人员记者从相近角度进行拍摄;在这些情况下,常用的文件对比、图像对比软件是失效的。
4、图片预处理问题。大多数图片来源于新闻报道视频,还有部分来源于抖音等短视频平台,因此截取的图片是带有水印、字幕、甚至很大的黑边的,这些均是场景中不该有的元素,如果不去除这些元素,将极大影响算法训练出的模型的正确性。
5、多人协同问题。为获得1万张标注的数据图片,我们共搜索下载了12万多张图片,441份视频,这些海量的数据图片需要人工筛选、人工标注,因数据量十分庞大,在图片筛选的过程中也出现有的人较为严格,1000张只留了20多张,有的人则筛出100多张,判断界限十分模糊;标注过程也是,对落水人员目标拉框标准也不同。
由此,导致数据集的制作较为困难,且进展缓慢,基于此,本发明提供了一种洪水救援场景下深度学习数据集的制作方法。
爬虫工具经研究发现,很难突破网站的技术性屏蔽,且不同网站攻克方法不同,太耗费人力时间。更何况,通过爬虫获取的数据,经分析发现,大多数并不是我们所需要的“在洪水场景下,人员落水等待救援”的场景,出现很多无关、或有点关系,但并不符合的图片,这给后期的筛选带来很大的工作量。因此放弃爬虫的方法获取图片。
本发明使用网页元素获取技术进行图片下载,且考虑到多人协同问题,使用腾讯在线表格管理,对多人协同工作进行检索词互斥。具体操作如图1所示,包括如下步骤:
(1)每个人分配到不同的国家服务器,例如某1号人员检索美国的洪灾,2号人员检索澳洲的洪灾;且关键是必须登录到对应国家的服务器上去检索,不能在百度上检索美国的洪灾,因为一是图片资源不多,二是分辨率特别小只有100*100;而在用美国的服务器在谷歌上检索美国的洪灾,资源多,图片分辨率大于500*500,近几年发生的洪灾,分辨率可达3000*3000以上,属于高清图片。
(2)同时考虑到重复率问题,每个人以详细地点为检索词分别进行检索。
某人在中国本土服务器上,使用edge浏览器,并使用必应搜索引擎,搜索江西的洪水。为避免重复,在检索词江西后添加具体地点,如“江西上饶”;同时为避免搜索到的内容,经过几次下一页翻找趋同,同时也会变换最后面的检索词,如“内涝”“水灾”“洪水”“落水”等等交叉使用。如果使用“江西上饶洪水”、“江西九江洪水”……,前面搜索出来的图片是不一样的,而后面的图片逐渐变得重复率越来越高,即趋同为江西发生的所有洪水灾害。
(3)启动IA图片助手工具(一款浏览器插件),在网页上搜索出相关图片,并不停往后下拉翻找,直到出现大量无关图片停止。点击IA图片助手菜单中的“提取本页图片”,并进行分辨率设置、图片格式转换设置、保存路径文件夹设置,然后点击“全选”按钮,在点击“下载选中”按钮,即可将图片保存到预设的文件夹中,该文件夹取名为“洪水场景”。
(4)预先训练好的目标检测模型采用EasyDL模型,在文件夹中识别人,然后将识别到有人的图片剪切(跟拷贝不同)到另一个文件夹,取名为“正样本”文件夹,等待人工筛选。
经过筛选,“正样本”文件夹中是落水的人图片,“洪水场景”文件夹是被筛选掉的其它图片。
在一种实施方式中,在采用预先训练好的目标检测模型对采集的图片数据进行检测,分为落水人员图片和其他图片之后,所述方法还包括:
对正样本文件夹中的图片进行检查确认。
具体来说,“正样本”文件夹中理论上应该全是“在洪水场景下,人员落水等待救援”的场景图片,但实际上里面还是有不少错误。
典型的错误有:①人并没有落水,站在岸上或者水边;②不是洪水场景,而是洪水过后的场景,有很多黄色的泥巴;③“洪水场景”文件夹有许多没有识别出来的人,一种是人太小例如远处人只露了个头,另一种是人的头和脸没有露出在水面,只有肢体在水面上,还有一种是有严重遮挡,将人体遮挡了大部分,上述情况都会使目标检测-人的EasyDL模型失效,致使没有识别出落水的人。除了上述典型错误外,还有极个别情况造成识别错误,因此需要人工浏览一遍进行筛查。
经过检查确定后,“正样本”文件中就都是“在洪水场景下,人员落水等待救援”的场景图片。
在一种实施方式中,对正样本文件夹中包含的落水人员图片进行预处理,包括:
将正样本文件夹中包含的图片按照分辨率大小进行排序;
依次探测排序后的图片的边是否存在黑边,如果存在黑边,则将对应的图片移动至待去除黑边文件夹;
对待去除黑边文件夹中的图片进行黑边去除;
对保留在正样本文件夹中的图片以及待去除黑边文件夹中经过黑边去除后的图片进行字符探测,如果图片的字符数超过字符数量阈值,则将对应的图片剪切到待去除字幕文件夹;
对待去除字幕文件夹中的图片进行字幕去除;
将进行字幕去除后的图片剪切至正样本文件夹中。
请参见图2,为本发明实施例中图片预处理的流程图。
具体实施过程中,实现流程如下:
(1)对正样本文件夹中包含的图片按照分辨率大小进行排序。因为很多相似图片都是来自同一段新闻,分辨率基本趋同。
(2)分别读取图片顶部10行像素、底部10行像素、左边10列、右边10列。
对4个不同的边做像素灰度值均值化处理,如果灰度值<=10,即认为接近黑色,有黑边存在。将该类图片剪切(即移动)到另一个文件夹,另一个文件夹命名为“待去除黑边”。
(3)使用光影魔术手软件,对待去除黑边文件夹中的图片进行批量黑边去除;
(4)启动百度飞浆Paddle-OCR工具,对保留在正样本文件夹中的图片以及待去除黑边文件夹中经过黑边去除后的图片进行扫描,如果发现识别出的字符超过10个,则将该类图片剪切(移动)到另一个文件夹,另一个文件夹命名为“待去除字幕”。
(5)人工对待去除字幕文件夹中的图片进行字幕抹除;
(6)将进行字幕去除后的图片剪切至正样本文件夹中。
(7)人工浏览一遍,避免错误发生。由于第(1)步中按分辨率将图片进行了排序操作并标注了序号,因此,参考“待去除黑边”文件夹和“待去除字幕”文件夹的图片序号,在原剔除了黑边图片和剔除了字幕图片的“正样本”文件夹中,图片序号相近的上下位置进行人工检查,可以较快地发现是否有错误。对个别错误进行修正。
在“待去除黑边”文件夹和“待去除字幕”文件夹中,出处相同的图片大多在一起,使用“光影魔术手”软件进行批量剪切,可以较好的消除图片黑边和字幕。此外,对于水印就比较困难,可以按对图片场景内容整体影响大小,对有水印的图片做人工判断,如果影响不大则不处理,如果影响较大,则用PS工具进行人工抹除。
经过上述的处理操作,将剔除了黑边图片和剔除了字幕图片的“正样本”文件夹中的所有图片也拷贝到“正样本2”文件夹中。
在一种实施方式中,结构相似性阈值包括第一阈值和第二阈值,且第二阈值大于第一阈值,计算的函数值包括第一函数值和第二函数值,根据结构相似性阈值与计算的函数值之间的关系以及分辨率的大小,判断删除哪一张图片,包括:
如果计算的第一函数值大于第一阈值,则将其中分辨率较小的图片剪切到正样本-暂存文件夹;
对正样本-暂存文件夹的图片采用改进的结构对比函数两两进行计算,判断计算得到的第二函数值是否大于第二阈值,如果大于,则将第二函数值对应的两张图片都删除,否则,将第二函数值对应的两张图片复制到正样本文件夹。
具体实施过程中,本发明采用一种均值哈希和ssim混合的算法。如图3所示,实现步骤如下:
(1)图像灰度化。为防止色彩带来的影响,首先将彩色图像灰度化。
(2)计算图像灰度平均值,假设为a,然后参照均值哈希算法aHash,根据像素均值计算指纹(初始化输入图片的ahash=“”。从左到右一行一行地遍历矩阵G每一个像素,如果第i行j列元素G(i,j)>=a,则ahash+="1"如果第i行j列元素G(i,j) (3)得到图片的ahash值后,比较两张图片ahash值的汉明距离,同时将其归一化到[0,1]区间。设定阈值为85%,即0.85。假设A、B两张图片归一化汉明距离大于0.85,则判定为相似。查找原图像分辨率,如果A分辨率大于B,则保留分辨率较大的图片A,剔除分辨率较小的图片B。 (4)对步骤(3)保留下来的图片,进行ssim算法比较。我们对ssim算法进行了改进。ssim算法从亮度,对比度和结构三个方面进行度量: 亮度对比函数: 对比度对比函数: 结构对比函数: 将上述三个函数组合起来,得到SSIM指数函数: 其中,μ 常规的方法中,取值如下:α=β=γ=1,C (5)将ssim的第一阈值设定为0.3。只要大于0.3的就剔除,剪切分辨率较小的图片到文件夹“正样本-暂存”,保留分辨率最大的图片在文件夹“正样本-确定”;将小于0.3的图片进行保留,拷贝到“正样本-确定”文件夹。“正样本-确定”文件夹里面的图片,确定是绝对不相似的图片。 (6)“正样本-暂存”文件夹中,是ssim值大于0.3,被剔除的图片,这些图片中有误删的部分,我们在该文件夹中重新执行步骤(4),将第二阈值调整到0.7,即大于0.7的图片,认为是相似图片,彻底删除,小于0.7的图片,认为是不相似误删的图片,拷贝回“正样本-确定”文件夹。 经过上述步骤(1)-(6),我们获得了“正样本-确定”文件夹,里面的图片基本不重复,极个别相似的图片,在后续的标注过程中手动删除。相似发生率0.46%,即10000张图片中,只有46张相似。 在一种实施方式中,采用基于多标签信息融合的方式对正样本和负样本进行标注,包括: 对正样本和负样本中的图片中的困难目标,进一步分为遮挡和模糊两种属性,其中困难目标为标注情况复杂的目标。 具体来说,获取了样本图片之后,接下来进行图片标注。图片标注的难点有两个,一个是拉框要精准,一个是对洪水这种特定场景内人落水等待救援状况的精确判断。 1、对于普通目标,或者称为好标注的图像,拉框精准是很容易的。但对于某些特殊情况,例如有些图片中,后面的脚是落水人的,但由于被水分割,所以不能框入,只能对前面露出水面的部分进行精准拉框;在一些图片中,虽然能看到人的下肢,但因水中折射变形,同样不能框入,只能对水面上的人体部分进行精确拉框。再考虑到洪水场景水质差不透明,江河湖海场景水质较好比较透明,为使多人协同标注标准能统一,定义只标注水面上的部分。 2、对于场景精确判断。我们只对处于危险境地下的目标进行拉框标注,如果图片中的人没有处于危险情况中,则对这类图片进行排除。 具体实施过程中,编写了两套标注软件,一套为“基于多标签信息融合的图像标注软件”,另一套为“图像数据去重-扩增多元信息标注软件”。 1、“基于多标签信息融合的图像标注软件”的创新点为: (1)本软件对图像中标注困难的目标进行了标签细化,使某一目标可以有多重标签信息。使后期的训练算法能够针对不同类型的目标进行分化处理。 对于里面人员十分密集,且有遮挡,远处的人还特别模糊的图片。经典的labelimg软件对图像中标注起来较为困难的目标,并且仅有difficult困难一个指标选项,而洪水救援场景下要细分为遮挡、模糊两种不同的difficult困难类型。本实施例的标注方法细化了difficult困难类型,进一步细分为“occlusion遮挡”和“definition模糊”两种,因此本软件增设了这两种标签属性,这两种属性从属于“difficult困难”。如图4所示。 (2)软件集成标注结果可视化图像生成功能,标注完大量图像后,可批量生成可视化效果,并在文件夹中批量检查。 (3)软件即可生成每个样本对应一个xml文件,也可批量将多个xml信息合并为单一json格式文档,方便后期的训练算法以多种形式调用。 (4)使用Python语言进行编写,PyQt5 GUI套件开发多功能界面,作为开源软件可随后期深度学习的算法做灵活调整。 “图像数据去重-扩增多元信息标注软件”在第一套软件的基础上,增加了图像去重功能和数据集扩充功能,创新点为: (1)增加了去重功能。 (2)增加了图像数据扩增功能,不仅仅有传统的色彩抖动、旋转、灰度化等扩增,关键增加了HSV掩模功能。对样本图像进行HSV色彩模型转换,提取H通道特征,以此制作掩模,滤除杂乱背景干扰,保存为新的样本图像,增扩样本数据,如图5所示。 上图左边是原图,原图经过HSV色彩模型转换,提取H通道特征后,以目标物的H值作为特征值,然后以特征值为中心,左右10个灰度值,即假设特征值为a,则区间范围为[a-10,a+10],将不在区间范围内的灰度值作为背景灰度值,制作黑色背景掩膜,将掩膜与左边的原图做与操作,得到右边的图。 该种方式做样本标注,可以减少训练样本干扰,提高样本的质量。 实施例二 基于同样的发明构思,本实施例提供了一种洪水救援场景下深度学习数据集的制作系统,包括: 图片数据获取模块,用于使用网页元素获取技术采集洪水救援场景下的图片数据; 图片检测模块,用于采用预先训练好的目标检测模型对采集的图片数据进行检测,分为落水人员图片和其他图片,分别保存至正样本文件夹和洪水场景文件夹中; 预处理模块,用于对正样本文件夹中包含的落水人员图片进行预处理; 采用均值哈希和结构相似性的方法对预处理后的落水人员图片进行去重,具体包括:将落水人员图片的尺寸调整为500*500,对尺寸调整后的图片进行灰度化处理,并计算图像灰度平均值,根据每个像素的灰度值与图像灰度平均值之间的关系,得到每个像素的哈希值,并进一步得到图片的指纹;根据两张图片的指纹大小,计算两张图片的汉明距离,如果两张图片的汉明距离大于距离阈值,则判定为两张图片相似,并根据两张图片的分辨率确定剔除哪一张图片;采用改进的结构对比函数对保留的图片两两进行计算,根据结构相似性阈值与计算的函数值之间的关系以及分辨率的大小,判断删除哪一张图片,其中,改进的结构对比函数中,亮度对比函数的指数设置为0.5,对比度对比函数的指数设置为1,结构对比函数的指数设置为1.5; 对正样本文件夹中保留下的落水人员图片作为正样本,洪水场景文件夹中包含的图片作为负样本,并采用基于多标签信息融合的方式对正样本和负样本进行标注; 采用图像数据扩增的方式对标注后的样本进行处理,得到最终的深度学习数据集。 由于本发明实施例二所介绍的系统为实施本发明实施例一中洪水救援场景下深度学习数据集的制作方法所采用的系统,故而基于本发明实施例一所介绍的方法,本领域所属人员能够了解该系统的具体结构及变形,故而在此不再赘述。凡是本发明实施例一中方法所采用的系统都属于本发明所欲保护的范围。 实施例三 基于同一发明构思,本发明还提供了一种计算机可读存储介质,其上存储有计算机程序,该程序被执行时实现如实施例一中所述的方法。 由于本发明实施例三所介绍的计算机可读存储介质为实施本发明实施例一中洪水救援场景下深度学习数据集的制作方法所采用的计算机可读存储介质,故而基于本发明实施例一所介绍的方法,本领域所属人员能够了解该计算机可读存储介质的具体结构及变形,故而在此不再赘述。凡是本发明实施例一的方法所采用的计算机可读存储介质都属于本发明所欲保护的范围。 本领域内的技术人员应明白,本发明的实施例可提供为方法、系统、或计算机程序产品。因此,本发明可采用完全硬件实施例、完全软件实施例、或结合软件和硬件方面的实施例的形式。而且,本发明可采用在一个或多个其中包含有计算机可用程序代码的计算机可用存储介质(包括但不限于磁盘存储器、CD-ROM、光学存储器等)上实施的计算机程序产品的形式。 本发明是参照根据本发明实施例的方法、设备(系统)、和计算机程序产品的流程图和/或方框图来描述的。应理解可由计算机程序指令实现流程图和/或方框图中的每一流程和/或方框、以及流程图和/或方框图中的流程和/或方框的结合。可提供这些计算机程序指令到通用计算机、专用计算机、嵌入式处理机或其他可编程数据处理设备的处理器以产生一个机器,使得通过计算机或其他可编程数据处理设备的处理器执行的指令产生用于实现在流程图一个流程或多个流程和/或方框图一个方框或多个方框中指定的功能的装置。 尽管已描述了本发明的优选实施例,但本领域内的技术人员一旦得知了基本创造性概念,则可对这些实施例做出另外的变更和修改。所以,所附权利要求意欲解释为包括优选实施例以及落入本发明范围的所有变更和修改。 显然,本领域的技术人员可以对本发明实施例进行各种改动和变型而不脱离本发明实施例的精神和范围。这样,倘若本发明实施例的这些修改和变型属于本发明权利要求及其等同技术的范围之内,则本发明也意图包含这些改动和变型在内。
- 一种在联邦学习场景下的数据集划分方法及系统
- 一种并行计算场景下分布式数据集合计算方法和系统