一种鉴别突变型P53基因的方法及装置
文献发布时间:2023-06-19 19:28:50
技术领域
本发明涉及生物技术领域,具体为一种鉴别突变型P53基因的方法及装置。
背景技术
直肠癌是指从齿状线至直肠乙状结肠交界处之间的癌,是消化道最常见的恶性肿瘤之一。直肠癌位置低,容易被直肠指诊及乙状结肠镜诊断。但因其位置深入盆腔,解剖关系复杂,手术不易彻底,术后复发率高。中下段直肠癌与肛管括约肌接近,手术时很难保留肛门及其功能是手术的一个难题,也是手术方法上争论最多的一种疾病。我国直肠癌发病年龄中位数在45岁左右。青年人发病率有升高的趋势。
近年来研究发现,野生型P53基因在正常细胞中维持在较低水平,并调节基因转录,以应对导致直肠癌基因信号激活。突变型P53基因具有较长的半衰期和较强的稳定性,可在细胞核内不断积累,使人体失去对细胞的监测作用。并且,突变型P53基因在恶性细胞肿瘤中作为癌基因,能够促进癌细胞进行侵袭、转移、增殖和存活。
在直肠癌患者产生突变型P53基因后,50%-75%的病例为阳性。突变型P53基因与结直肠癌近端淋巴管浸润相关,与远端淋巴管和血管浸润显著相关。与野生型P53基因相比,具有突变型P53基因的直肠癌患者化疗耐药程度更高,预后较差。但是,在真实小样本高维临床医疗数据问题中,样本数量少,特征数量大,会导致各种特征的冗余和相似。因此,本领域需要一种能够提高鉴别突变型P53基因准确率的方法及装置。
发明内容
本发明旨在提供一种鉴别突变型P53基因的方法及装置,其能够解决上述技术问题。
根据本发明的一个方面,提供了一种鉴别突变型P53基因的方法,包括:将多名病例的多个体征参数集划分成为多个训练集和多个验证集,其中该体征参数集包括定量特征的参数和变量特征的参数;根据该多个训练集对该多个体征参数集进行训练,得到多个信息价值(Information Value,简称IV)值;确定该多个IV值中的最大值对应的该定量特征和该变量特征作为最优特征集;以及根据该最优特征集,鉴别突变型P53基因。
优选地,在将多名病例的该多个体征参数集划分成为该多个训练集和该多个验证集之前,还包括:对该定量特征和该变量特征进行分选排序,得到无偏估计量的定量特征组和变量特征组;对该定量特征组和该变量特征组进行证据权重(Weight of Evidence,简称WOE)变换,得到该多个体征参数集。
优选地,使用该训练集对该体征参数集进行训练,得到该多个IV值,包括:基于过滤特征选择法,得到IV
得到该IV值;其中,i表示该IV值和R值的序数,R表示权重百分比。
优选地,该过滤特征选择法包括:第二公式
优选地,该影响因素β包括:该影响因素β的初始值为1,该序数i=1,2,…,n,该n小于20;当该序数i为1时,该影响因素β的值为1;当该序数i为n时,该影响因素β的值为1+0.1*n。
优选地,该过滤特征选择法包括:第三公式
优选地,该影响因素β包括:该影响因素β的初始值为2,该序数i=1,2,…,n,该n小于20;当该序数i为1时,该影响因素β的值为2;当该序数i为n时,该影响因素β的值为2-0.1*n。
优选地,该过滤特征选择法包括:第四公式
优选地,确定该多个IV值中的最大值包括:基于第五公式
根据本发明的另一个方面,还提供了一种鉴别突变型P53基因的装置,该装置包括:划分模块,用于将多名病例的多个体征参数集划分成为多个训练集和多个验证集,其中该体征参数集包括定量特征的参数和变量特征的参数;训练模块,用于根据该多个训练集对该多个体征参数集进行训练,得到多个IV值;确定模块,用于确定该多个IV值中的最大值对应的该定量特征和该变量特征作为最优特征集;鉴别模块,用于根据该最优特征集,鉴别突变型P53基因。
本发明将多名病例的多个体征参数集划分成为多个训练集和多个验证集,然后基于体征参数集对训练集进行训练,根据IV值得到最优特征集,能够提高鉴别突变型P53基因的准确率。
附图说明
此处所说明的附图用来提供对本发明的进一步理解,构成本申请的一部分,本发明的示意性实施例及其说明用于解释本发明,并不构成对本发明的不当限定。在附图中:
图一为根据本发明实施例的鉴别直肠癌突变型P53基因的方法的流程图;
图二为根据本发明实施例的验证集的准确率的示意图;
图三为根据本发明实施例的验证集的Kappa值的示意图;以及
图四为根据本发明实施例的鉴别直肠癌突变型P53基因的装置的结构框图。
具体实施方式
本发明实施例针对医学上鉴别直肠癌突变型P53基因提出了一种深度学习方法。与普通技术不同,本发明实施例不需要使用复杂的医学手段进行确定,本发明将多名直肠癌患者的多个体征参数集划分成为多个训练集和多个验证集,然后基于体征参数集对训练集进行训练,根据IV值得到最优特征集,能够快速地鉴别直肠癌突变型P53基因。与复杂且成本高昂的传统技术相比,本发明实施例仅需采集直肠癌患者的体征参数即可鉴别直肠癌突变型P53基因,进一步提高了准确率。
需要说明的是,在不冲突的情况下,本申请中的实施例及实施例中的特征可以相互组合。下面将参考附图并结合实施例来详细说明本发明。
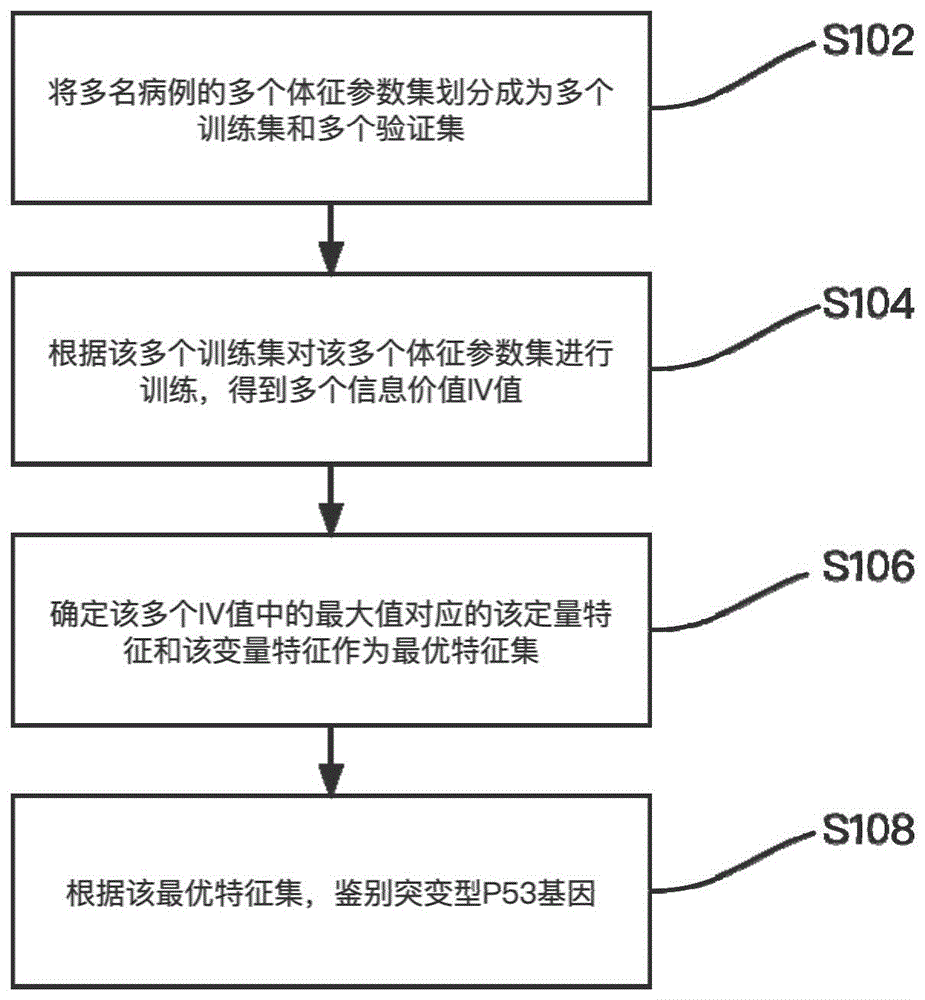
本发明实施例提供了一种鉴别直肠癌突变型P53基因的方法。图一是根据本发明实施例的鉴别直肠癌突变型P53基因的方法的流程图。如图一所示,包括如下的步骤S102至步骤S108。
步骤S102,将多名直肠癌患者的多个体征参数集划分成为多个训练集和多个验证集,其中该体征参数集包括定量特征的参数和变量特征的参数。
步骤S104,根据该多个训练集对该多个体征参数集进行训练,得到多个IV值。
步骤S106,确定该多个IV值中的最大值对应的该定量特征和该变量特征作为最优特征集。
步骤S108,根据该最优特征集,鉴别直肠癌突变型P53基因。
在真实小样本高维临床医疗数据问题中,样本数量少,特征数量多,会导致特征量的冗余和相似。本发明实施例中,仅需将多名直肠癌患者的多个体征参数集划分成为多个训练集和多个验证集,然后基于体征参数集对训练集进行训练,根据IV值得到最优特征集,即可提高鉴别直肠癌突变型P53基因的准确率。
根据本发明的实施例,在将多名直肠癌患者的该多个体征参数集划分成为该多个训练集和该多个验证集之前,还包括:对该定量特征和该变量特征进行分选排序,得到无偏估计量的定量特征组和变量特征组;对该定量特征组和该变量特征组进行WOE变换,得到该多个体征参数集。
本实施例详细描述了定量参数和变量参数转换为体征参数集的过程。该过程的特点至少包括以下两点。第一,针对定量特征和变量特征,采用了一种有监督的变量排序技术,通过递归和统计假设检验的方法实现无偏变量排序技术,使特征排序更为科学。第二,针对体征参数集的确定,采用WOE变换,从而确认每个定量、变量的重要程度。WOE编码使参数更加健壮,并能够提高结果的可解释性。
根据本发明的实施例,使用该训练集对该体征参数集进行训练,得到该多个IV值,包括:基于过滤特征选择法,得到IV
本实施例详细描述了IV值的计算方法,该计算方法的特点至少包括以下两点。第一,基于过滤特征选择法,得到IV
根据本发明的实施例,该过滤特征选择法包括:第二公式
本实施例详细描述了IV
根据本发明的实施例,该过滤特征选择法还包括:第三公式
本实施例详细描述了IV
根据本发明的实施例,该过滤特征选择法包括:第四公式
本实施例详细描述了IV
根据本发明的实施例,确定该多个IV值中的最大值包括:基于第五公式
本实施例详细描述了最大值IV值的计算方法,该计算方法的特点至少包括以下两点。第一,利用了聚类的优点,即类内相似度最大、类间差异最大;第二,利用了IV的优点,即结果高效且易于解释。该方法首先对变量集进行无监督聚类学习,划分一些目标聚类,然后从目标聚类中选取IV值最大的特征作为代表,最后将这些代表特征进行组合,得到所选特征集。
根据本发明的实施例,提供了一种鉴别直肠癌突变型P53基因的装置,该装置包括:划分模块,用于将多名直肠癌患者的多个体征参数集划分成为多个训练集和多个验证集,其中该体征参数集包括定量特征的参数和变量特征的参数;训练模块,用于根据该多个训练集对该多个体征参数集进行训练,得到多个IV值;确定模块,用于确定该多个IV值中的最大值对应的该定量特征和该变量特征作为最优特征集;鉴别模块,用于根据该最优特征集,鉴别直肠癌突变型P53基因。
本实施例详细描述了鉴别直肠癌突变型P53基因的装置,该装置主要包括划分模块、训练模块、确定模块、鉴别模块。本装置不需要采用侵入性操作,仅需将多名直肠癌患者的多个体征参数集划分成为多个训练集和多个验证集,然后基于体征参数集对训练集进行训练,根据IV值得到最优特征集,即可提高鉴别直肠癌突变型P53基因的准确率。
下面将结合实例对本发明实施例的实现过程进行详细描述。同时,本说明书中未作详细描述的内容均属于本领域技术人员公知的现有技术。
将定量特征设定为年龄、性别,变量特征设定为基于影像学做小波处理衍生的系列特征、血清肿瘤标志物特征、其他临床特征、野生型P53基因和突变型P53基因。同时采集这些特征的参数,形成原始体征参数集。
本实施例应用了一种最优变量划分技术,即条件推理树。条件推理树属于一种有监督的变量排序技术,能够通过递归和统计假设检验的方法实现无偏变量排序技术。
在得到无偏变量的排序结果后,对每个定量特征组和变量特征组分组进行WOE编码,WOE是对原始特征的一种编码形式。通过WOE编码,可以将原始数据集映射到一个新的数据集,即体征参数集,体征参数集中的数据更加健壮,结果的可解释性高。
将上述体征参数集,均带入以下三个IV
第二公式
第三公式
第四公式
可以得到三套相同体征参数集的不同的IV
将上述三套体征参数集的IV
第一公式
本实施例中,由于具有3套IV
将上述每个体征参数集的IV值带入第五公式
在本实施例中,筛选出每个体征参数集中IV值最大的特征,作为最优特征集,使用最优特征集,即可准确鉴别突变型P53基因。
在本实施例中,还设定了验证集,使用10倍交叉验证方法评估LR模型在不同特征集下的准确率和Kappa值,对上述结果进行验证。
在本实施例中,使用混淆矩阵计算准确率,混淆矩阵可以定义准确率、精度和召回率,其中,准确率是所有预测的正确比例。根据样本的真实类别和分类器预测类别的组合,样本可分为真阳性(TP)、假阳性(FP)、真阴性(TN)、假阴性(FN)四种情况。代入公式
在本实施例中,同样使用Kappa值进行一致性检验,即模型预测结果与实际分类结果是否一致,可以得到如图三所示的Kappa值曲线。Kappa值计算公式为
根据上述验证结果,可以发现,直肠癌突变型P53基因的鉴别能力均有提升,准确率相对于传统IV检测分别提升4.4%和2.0%和5.8%,Kappa值分别提升了21.8%、8.6%和22.4%。
另外,本实施例还提供了一种鉴别直肠癌突变型P53基因的装置,该装置包括:划分模块,用于将多名直肠癌患者的多个体征参数集划分成为多个训练集和多个验证集,其中该体征参数集包括定量特征的参数和变量特征的参数;训练模块,用于根据该多个训练集对该多个体征参数集进行训练,得到多个IV值;确定模块,用于确定该多个IV值中的最大值对应的该定量特征和该变量特征作为最优特征集;鉴别模块,用于根据该最优特征集,鉴别直肠癌突变型P53基因。
综上所述,本发明仅需将多名病例的多个体征参数集划分成为多个训练集和多个验证集,然后基于体征参数集对训练集进行训练,根据IV值得到最优特征集,即可提高鉴别突变型P53基因的准确率。
本申请是参照根据本申请实施例的方法、装置(设备)和计算机程序产品的流程图和/或方框图来描述的。应理解可由计算机程序指令实现流程图和/或方框图中的每一流程和/或方框、以及流程图和/或方框图中的流程和/或方框的结合。可提供这些计算机程序指令到通用计算机、专用计算机、嵌入式处理机或其他可编程数据处理设备的处理器以产生一个机器,使得通过计算机或其他可编程数据处理设备的处理器执行的指令产生用于实现在流程图一个流程或多个流程和/或方框图一个方框或多个方框中指定的功能的装置。
这些计算机程序指令也可存储在能引导计算机或其他可编程数据处理设备以特定方式工作的计算机可读存储器中,使得存储在该计算机可读存储器中的指令产生包括指令装置的制造品,该指令装置实现在流程图一个流程或多个流程和/或方框图一个方框或多个方框中指定的功能。
这些计算机程序指令也可装载到计算机或其他可编程数据处理设备上,使得在计算机或其他可编程设备上执行一系列操作步骤以产生计算机实现的处理,从而在计算机或其他可编程设备上执行的指令提供用于实现在流程图一个流程或多个流程和/或方框图一个方框或多个方框中指定的功能的步骤。
尽管已描述了本申请的优选实施例,但本领域内的技术人员一旦得知了基本创造性概念,则可对这些实施例作出另外的变更和修改。所以,所附权利要求意欲解释为包括优选实施例以及落入本申请范围的所有变更和修改。
显然,本领域的技术人员可以对本申请进行各种改动和变型而不脱离本申请的精神和范围。这样,倘若本申请的这些修改和变型属于本申请权利要求及其等同技术的范围之内,则本申请也意图包含这些改动和变型在内。
- 靶向突变型p53基因的硼酸铅纳米颗粒在癌症治疗中的用途及这些纳米颗粒的制备方法
- 突变型p53基因反义表达载体及其制备方法