一种基于有监督长程相关的遥感图像语义分割方法
文献发布时间:2023-06-19 19:28:50
技术领域
本发明涉及一种有监督长程相关的遥感图像语义分割方法,实现了光学遥感影像的像素级图像分类,可用于地理信息制图,城市规划和管理,环境监测以及城市变化监测。
背景技术
语义分割是计算机视觉和遥感中的一个基本任务,它在城市环境监测、土地利用规划、作物估产、城市变化检测等方面都具有极为重要的作用。当前,语义分割任务中使用的主流网络是基于编码器-解码器风格的全卷积网络。但是,与自然图像不同,遥感影像通常覆盖更大的场景范围,这就导致遥感影像中的同类对象可能呈现出较大的类内差异,而不同类别的对象间呈现出较小的类间差异。这种情况随着影像中不同像素/区域间距离的增加而更显著。在先前的研究中,为了应对大范围遥感影像中地物对象类内方差大而类间方差小的难点,注意力机制和Transformer模型都已经被尝试和使用。这些研究通过对影像中不同区域间的特征进行信息交互,提高卷积神经网络分割模型像素级分割的精度。但是这些方法仅使用矩阵运算对不同像素/区域的特征进行相关,在训练过程中无监督的相关性学习方式可能限制了语义分割精度的进一步提升。
另一方面,为了可靠地判定遥感影像中的地物类别,综合利用多尺度的信息进行像素类别判定也被广泛关注。但是先前的研究多在特征层次上进行多尺度信息提取,在原始输入影像层次上进行多尺度信息捕获的研究较少。部分研究使用两个不同尺度的影像作为输入,但是在对不同尺度的影像进行信息提取的过程中又没有考虑到每个尺度的影像中不同地物对象尺寸的差异。大尺度的地物对象应该使用具有较大感受野的卷积层去捕获其特征,小尺度的对象则应该使用小感受野的卷积层进行特征提取。研究和实现自适应地从多尺度输入影像中有效地捕获不同尺寸物体的特征对于提升遥感影像像素级分割的精度也很有意义。
发明内容
本发明针对现有遥感影像语义分割方法中长程相关性学习仅使用无监督的方式,以及多尺度特征提取设计不够灵活的缺点,提出了一种有监督长程相关的遥感图像语义分割方法。它能够可靠和准确地对遥感影像执行像素级语义分割任务,对于易于混淆的图像像素做出正确的类别预测结果。
实现本发明目的采用的技术方案是:步骤1,构建有监督长程相关的语义分割网络(Supervised Long-range Correlation semantic segmentation Network,SLCNet),该网络用于学习遥感影像上不同类别地物要素的特征,并建立学习到的特征与像素级类别图间的映射关系;步骤2,利用光学遥感影像数据和像素级语义类别真值图数据构建样本库,使用样本库和深度学习框架训练网络模型。通过加载训练好的网络模型权重对新的遥感影像进行预测,可实现遥感影像的像素级类别预测。
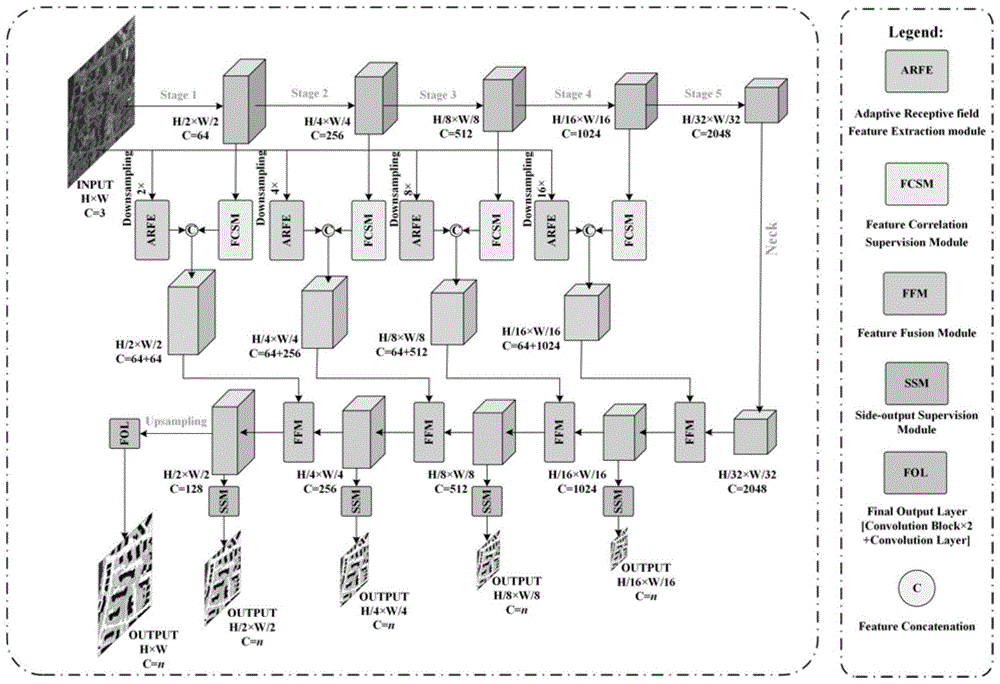
进一步的,步骤1所述的有监督长程相关的语义分割网络包括特征提取主干(features extraction backbone),长程相关监督模块(long-range correlationsupervision module),自适应感受野特征提取模块(adaptive receptive field featureextraction module)多尺度侧边输出模块(multi-scale side-output module)和最终输出层(final output layer),共5个部分组成。特征提取主干采用当前流行的残差网络(Residual Network,ResNet),它以原始影像作为输入,由浅到深地进行特征提取,在这个过程中特征图的尺寸逐级下降(相对于原始影像2倍,到4倍,8倍,16倍,32倍下采样)。特征提取主干提取出的2倍,到4倍,8倍,16倍下采样的特征图分别被输入到长程相关监督模块中进行长程信息交互;2倍,到4倍,8倍,16倍下采样的原始影像分别被输入到自适应感受野特征提取模块中提取不同尺寸物体的特征;32倍下采样特征经两组顺序堆叠的3×3的卷积(Convolution)+批归一化层(Batch Normalization layer)+修正线性单元(RectifiedLinear Unit,ReLU)后进行自顶向下的上采样和特征融合;在每个尺度上,长程信息交互后的特征和对物体尺寸具有自适应性的特征被串联,然后与自顶向下的特征经上采样后进行融合;融合后的2倍,4倍,8倍,16倍特征被输入到侧边输出模块中预测对应尺度的预测图(即像素级语义类别概率图);2倍特征被进一步上采样,然后经过最终输出层处理,输出与输入影像分辨率保持一致的最终像素级语义类别概率图。逐像素计算像素级语义类别概率图沿着通道方向最大概率值的索引,根据索引与预先定义的类别间的对应关系可获得图像中每个像素所属的类别。
进一步的,所述的长程相关监督模块,采用基于监督学习的自注意力模型实现。它分解特征图上任意两个位置特征的相关性计算,为垂直方向(即每一列分别执行相关性计算)和水平方向(即每一行分别执行相关性计算)的相关性计算;即长程相关监督模块先对特征图的每一列执行有监督的自注意力模型,再对特征图的每一行执行有监督的自注意力模型;通过将2维相关分解为2个1维相关,在减少运算过程显存占用的同时,仍然可以进行长距离的相关。在每个有监督的自注意力模型中,给定输入特征图F
进一步的,所述的自适应感受野特征提取模块,以降采样的原始影像作为输入,输出与输入影像分辨率一致的特征图。在适应感受野特征提取模块中,,通过一个卷积层和三个标准的残差模块对输入影像I
进一步的,所述的侧边输出模块包含一个3×3的卷积(Convolution),一个批归一化层(Batch Normalization layer),一个修正线性单元(Rectified Linear Unit,ReLU)和一个3×3的卷积(Convolution);侧边输出模块负责将输入特征图F
进一步的,所述的最终输出层包含一个1×1的卷积(Convolution),负责将输入特征图F
进一步的,所述的在每个尺度上,长程信息交互后的特征F
进一步的,所述的2倍特征被进一步上采样,然后经过最终输出层处理,输出与输入影像分辨率保持一致的最终像素级语义类别概率图中的上采样操作由一个2×2的转置卷积层(transposed convolution layer)和两组顺序堆叠的3×3的卷积(Convolution)+一批归一化层(Batch Normalization layer)+修正线性单元(Rectified Linear Unit,ReLU)组成。
进一步的,步骤2的具体实现包括如下子步骤,
步骤2.1,标注遥感影像上的每个像素所属的类别,生成语义类别真值栅格图。将原始大尺度的遥感影像和对应的语义类别真值栅格图裁剪为网络模型支持的标准大小,即512×512像素,生成训练样本集。
步骤2.2,训练有监督长程相关的语义分割网络。将步骤2.1中生成的裁剪影像块和对应的裁剪语义类别真值栅格图作为训练数据,迭代训练有监督长程相关的语义分割网络直到模型收敛。
步骤2.3,给定待预测的新遥感影像,以一定的步长重叠裁剪原始大尺度遥感影像并输入到已加载训练权重的网络模型中,得到每个裁剪影像上的像素级预测结果。将所有裁剪影像的像素级预测结果映射回原始遥感影像上,得到整幅大尺度遥感影像的像素级类别预测结果。
本发明具有如下优点:1)不需要复杂的手工设计特征的过程,通过简单的、端到端的可训练模型,完成遥感影像像素级类别预测。2)可复用性强,可以在附加数据上继续进行模型的训练,可以用于连续在线学习,可持续不断迭代优化。3)具有可扩展性,训练好的神经元网络模型经过调整,可应用于其他用途,如基于遥感影像的地物变化检测,基于遥感影像的兴趣地物目标提取等。4)鲁棒性强,网络模型嵌入了有监督的长程相关性学习模式,自适应感受野特征提取模块,对于遥感影像中的各种地物要素都可以获得很好的像素级预测结果。
附图说明
图1是本发明提出的有监督长程相关的语义分割网络结构示意图。
图2是本发明提出的长程相关监督模块结构示意图。
图3是本发明提出的自适应感受野特征提取模块结构示意图。
具体实施方式
下面通过实施例,并结合附图,对本发明的技术方案作进一步的具体说明。
本发明提出了一种基于卷积神经元网络的适用于遥感影像像素级类别预测任务的语义分割算法,包括如下步骤:
步骤1,构建有监督长程相关的语义分割网络(Supervised Long-rangeCorrelation semantic segmentation Network,SLCNet),该网络用于学习遥感影像上不同类别地物要素的特征,并建立学习到的特征与像素级类别图间的映射关系;步骤2,利用光学遥感影像数据和像素级语义类别真值图数据构建样本库,使用样本库和深度学习框架训练网络模型。通过加载训练好的网络模型权重对新的遥感影像进行预测,可实现遥感影像的像素级类别预测。
进一步的,步骤1所述的有监督长程相关的语义分割网络包括特征提取主干(features extraction backbone),长程相关监督模块(long-range correlationsupervision module),自适应感受野特征提取模块(adaptive receptive field featureextraction module)多尺度侧边输出模块(multi-scale side-output module)和最终输出层(final output layer),共5个部分组成。特征提取主干采用当前流行的残差网络(Residual Network,ResNet),它以原始影像作为输入,由浅到深地进行特征提取,在这个过程中特征图的尺寸逐级下降(相对于原始影像2倍,到4倍,8倍,16倍,32倍下采样)。特征提取主干提取出的2倍,到4倍,8倍,16倍下采样的特征图分别被输入到长程相关监督模块中进行长程信息交互;2倍,到4倍,8倍,16倍下采样的原始影像分别被输入到自适应感受野特征提取模块中提取不同尺寸物体的特征;32倍下采样特征经两组顺序堆叠的3×3的卷积(Convolution)+批归一化层(Batch Normalization layer)+修正线性单元(RectifiedLinear Unit,ReLU)后进行自顶向下的上采样和特征融合;在每个尺度上,长程信息交互后的特征和对物体尺寸具有自适应性的特征被串联,然后与自顶向下的特征经上采样后进行融合;融合后的2倍,4倍,8倍,16倍特征被输入到侧边输出模块中预测对应尺度的预测图(即像素级语义类别概率图);2倍特征被进一步上采样,然后经过最终输出层处理,输出与输入影像分辨率保持一致的最终像素级语义类别概率图。逐像素计算像素级语义类别概率图沿着通道方向最大概率值的索引,根据索引与预先定义的类别间的对应关系可获得图像中每个像素所属的类别。
进一步的,所述的长程相关监督模块,采用基于监督学习的自注意力模型实现。它分解特征图上任意两个位置特征的相关性计算,为垂直方向(即每一列分别执行相关性计算)和水平方向(即每一行分别执行相关性计算)的相关性计算;即长程相关监督模块先对特征图的每一列执行有监督的自注意力模型,再对特征图的每一行执行有监督的自注意力模型;通过将2维相关分解为2个1维相关,在减少运算过程显存占用的同时,仍然可以进行长距离的相关。在每个有监督习的自注意力模型中,给定输入特征图F
进一步的,所述的自适应感受野特征提取模块,以降采样的原始影像作为输入,输出与输入影像分辨率一致的特征图。在适应感受野特征提取模块中,通过一个卷积层和三个标准的残差模块对输入影像I
进一步的,所述的侧边输出模块包含一个3×3的卷积(Convolution),一个批归一化层(Batch Normalization layer),一个修正线性单元(Rectified Linear Unit,ReLU)和一个3×3的卷积(Convolution);侧边输出模块负责将特征图F
进一步的,所述的最终输出层包含一个1×1的卷积(Convolution),负责将特征图F
进一步的,所述的在每个尺度上,长程信息交互后的特征F
进一步的,所述的2倍特征被进一步上采样,然后经过最终输出层处理,输出与输入影像分辨率保持一致的最终像素级语义类别概率图中的上采样操作由一个2×2的转置卷积层(transposed convolution layer)和两组顺序堆叠的3×3的卷积(Convolution)+一批归一化层(Batch Normalization layer)+修正线性单元(Rectified Linear Unit,ReLU)组成。
进一步的,步骤2的具体实现包括如下子步骤,
步骤2.1,标注遥感影像上的每个像素所属的类别,生成语义类别真值栅格图。将原始大尺度的遥感影像和对应的语义类别真值栅格图裁剪为网络模型支持的标准大小,即512×512像素,生成训练样本集。
步骤2.2,训练有监督长程相关的语义分割网络。将步骤2.1中生成的裁剪影像块和对应的裁剪语义类别真值栅格图作为训练数据,迭代有监督长程相关的语义分割网络直到模型收敛。
步骤2.3,给定待预测的新遥感影像,以一定的步长重叠裁剪原始大尺度遥感影像并输入到已加载训练权重的网络模型中,得到每个裁剪影像上的像素级预测结果。将所有裁剪影像的像素级预测结果映射回原始遥感影像上,得到整幅大尺度遥感影像的像素级类别预测结果。
下面通过一个例子说明本发明方法的效果:首先按照本发明方法构建有监督长程相关的遥感图像语义分割网络(Supervised Long-range Correlation semanticsegmentation Network,SLCNet)。然后获取训练样本数据,使用样本数据训练网络模型。实施例中使用的样本数据为ISPRS Vaihingen 2D语义分割数据,包含11张训练影像和5张测试影像,包括不透水面(Imp.surf),建筑物(Building),低矮植被(Low veg),树木(Tree)车辆(car)和背景类(Background,所占比例极小,在精度评估中被忽略),共6个类别;影像尺寸从1996×1995像素到3816×2550像素不等;其中每张影像的像素类别都由人工标注生成。我们将训练集中的原始影像和对应的标注影像以128像素为步长,裁剪成512×512像素大小的影像块,输入到网络模型中进行迭代训练,直到模型收敛得到最优权重文件。模型训练完成后,将待预测的测试遥感影像输入到训练好的网络模型中,进行语义分割,得到影像上每个像素的类别预测结果,并于人工标注的真值进行对比。
为了验证本发明方法的有效性和先进性,我们将提出的方法与其他先进的语义分割算法进行对比。包括在各种语义分割任务中表现突出的U-Net,PSPNet,RefineNet,DeepLabv3+,DANet,Swin-UNet,Trans-UNet和ST-UNet语义分割算法。所有的方法在相同的硬件环境(一台装有NVIDIA TITAN RTX 24GB GPU、Intel Core i9-9900K CPU,Windows操作系统的个人电脑)上,使用相同的训练数据进行模型训练。所有方法的预测结果依据像素级评价测度IoU分数和F1分数依次每个类别进行定量评估,并记录在表1中。统计所有类别的平均IoU分数(mean IoU,mIoU)和平均F1分数(average F1,Ave F1)作为精度评价的主指标。从表1的平均IoU分数和平均F1分数主指标来看,本发明方法的效果优于其它几种先进的语义分割方法。mIoU指标上,我们的方法与其他已有方法相比具有至少1.5%的优势,AveF1指标上,我们的方法与其他已有方法相比具有至少1.1%的优势。与这些已有的方法对比,证明了本发明的方法具有更好的鲁棒性并能够得到更加准确的像素级语义类别预测结果。因此,本发明的方法具有较好的工程实用价值。
表1本发明方法与其它先进的语义分割方法精度比较
本文中所描述的具体实施仅仅是对本发明精神作举例说明。本发明所属技术领域的技术人员可以对所描述的具体实施例做各种各样的修改或补充或采用类似的方式替代,但并不会偏离本发明的精神或者超越所附权利要求书所定义的范围。
- 一种基于空间金字塔掩盖池化的弱监督图像语义分割方法
- 一种基于深度卷积网络和弱监督学习的SAR图像语义分割方法
- 一种基于强变换下的半监督遥感图像语义分割方法及设备
- 一种基于监督自注意力网络的高分遥感图像语义分割方法