基于集成深度学习的污水处理过程软测量建模方法
文献发布时间:2023-06-19 19:28:50
技术领域
本发明涉及工业污水处理过程软测量建模领域,尤指基于集成深度学习的污水处理过程关键水质参数的软测量建模方法。
背景技术
废水处理过程非常复杂,涉及复杂的动态物理反应过程、生物反应过程和化学反应过程,具有很强的非线性、不确定性、时变特性和广泛的滞后,难以建立准确的模型。为了保持污水处理系统良好的环境,保证控制系统的稳定性、运行速度和可靠性测试等,同时使污水排放质量高,达到排放标准,需要对污水处理过程中水表、水质参数和环境参数等几个重要技术过程进行实时检查和监测。但在实际应用中,由于缺乏在线测量仪器和相应的测量传感器,或者它们需要在极其恶劣的环境中工作,其购买和维护成本高昂,导致工业过程中的一些质量变量可能很难实现实时测量。软测量技术通过建立过程中易测变量(辅助变量)与难以直接测量的变量(主导变量)之间的数学模型,可以实现对主导变量的实时监测和控制。它具有维护方便、时延低的优点,得到了迅速的发展。
深度学习具有比传统模型更复杂的多层结构,具有更多的信息、更好的数据提取和更强的非线性特征表达能力,能够准确地映射出工业数据下隐藏的复杂映射关系。利用深度学习的优点,结合软测量,可以充分提取数据特征信息,提高模型的预测精度。深度学习的发展到目前为止,各种深度学习模型不断发展,并引入了很多新的深度模型,但是,单一的软测量模型存在着诸多问题,比如局部最优、精度不足。鉴于数据中包含的大量隐含数据特征,集成各种算法和网络模型,结合各自的优势,提高模型的整体精度和泛化能力,已经成为复杂工业过程软测量建模中一个新的研究方向。
发明内容
发明目的:针对污水处理过程水质指标生化需氧量难以实现在线测量的问题,提出了一种基于集成深度学习的污水处理过程软测量建模方法,该方法与传统模型相比稳定性更好,有更强的泛化能力,不仅具有理论研究意义,还具有很大的实际应用价值。
技术方案:本发明公开了一种基于集成深度学习发污水处理过程软测量建模方法,包括以下步骤:
S1.获取污水数据并进行数据预处理;
S2.使用KPCA将处理好的数据进行特征选择,选取合适的辅助变量,从而构造软测量数据样本集;
S3.将S2中处理好的污水数据集作为Stacking集成框架中的第一层基学习器的原始输入,其中第一层的基学习器包括双向长短期记忆网络BiLSTM、极限梯度提升XGBoost和最小二乘支持向量机LSSVM,第一层基学习器的预测结果是通过对每个基学习器进行5折交叉验证获得的;
S4.第二层采用ELM作为元学习器,将从第一层基学习器获得的结果用作第二层元学习器的训练集,以完成第二层元学习器的训练;
S5.采用改进的爬行动物搜索算法对基学习器的模型参数进行优化,所述改进的爬行动物搜索算法包括:采用拉丁超立方初始化,在迭代过程中,采用非线性方法改进进化意义ES值,利用黄金正弦和翻筋斗策略改进个体寻优方式,利用优化后的模型进行软测量,得到生化需氧量的预测结果;
S6采用ELM对初始预测结果进行误差校正,得到最终预测结果。
进一步地,所述步骤S1中所述污水数据,包括悬浮物浓度SS、总氮TN、氨氮NH3-N、总磷TP、化学需氧量COD和历史时刻的生化需氧量BOD。
进一步地,所述步骤S2中使用KPCA对数据进行特征提取,具体步骤为:
S3.1设训练集样本数据为X=(x
S3.2计算特征空间的协方差矩阵C:
S3.3计算协方差矩阵的特征方程:
λ
其中,λ
S3.4定义核矩阵K:
K=φ(x
S3.5计算核矩阵K的特征方程:
其中,
S3.6将协方差矩阵C和核矩阵K代入到核矩阵K的特征方程中,则协方差矩阵C的特征向量ξ
其中,
S3.7计算核矩阵K的特征值
S3.8依次计算这些特征值的贡献率η
S3.9选取累计贡献率P≥85%的特征作为污水软测量模型输入的主要辅助变量。
进一步地,所述步骤S3中,建立双向长短期记忆网络预测模型的步骤如下:
S4.1将确定好的辅助变量作为网络的输入向量x;
S4.2设前向隐含层状态为
S4.3将y
进一步地,所述步骤S3中,建立极限梯度提升预测模型的步骤如下:
S5.1设训练数据集为T={(x
其中,L(φ)是线性空间上的表示,i是第i个样本,k是第k棵树,
S5.2利用每一棵树的预测结果去拟合上一颗树预测结果的残差:
S5.3上一步得到第t棵树的预测结果,在数值上等于前面t-1棵树的预测结果,加上第t棵树的表现,对于第t棵树,目标函数为:
S5.4把式(14)用泰勒展开来近似原来的目标,定义
则式(14)可化为:
S5.5求得目标函数的最优解为:
其中
S5.6算出增益值Gain,更新最大增益Gain_max,更新分隔点,最终得到最优的分隔点;
S5.7重复上述过程递归建树直到终止条件。
进一步地,所述步骤S3中,建立最小二乘支持向量机预测模型的步骤如下:
S6.1优化目标,定义损失函数为:
具有约束条件:
其中,ω是权重,ξ
S6.2引入拉格朗日乘子,式(18)可以转化为:
其中,拉格朗日乘子a
S6.3求解最优条件
S6.4综合上述公式得到最优回归函数如下:
其中,K(x
进一步地,所述步骤S4中元学习器预测模型计算公式如下:
其中,L是隐层单元的数量,N是训练样本的数量,β是第i个隐藏层和输出层之间的权重向量,w是输入和输出之间的权重向量,g是激活函数,b是偏置向量,x是输入向量。
进一步地,所述步骤S5中改进的爬行动物搜索算法的步骤如下:
S5.1使用拉丁超立方抽样初始化代替RSA算法的随机初始化,设置IRSA的搜索上下界、种群大小和迭代次数;
S5.2包围阶段,鳄鱼个体开始包围猎物,其数学模型如下:
η
其中,B
S5.3对公式(26)的进化意义参数进行改进,改进后的进化意义表达式如下:
S5.4狩猎阶段,鳄鱼个体开始捕猎,其数学模型如下:
S5.5对位置更新公式(30)引入黄金正弦和翻筋斗策略,改进后的公式如下:
其中,γ
x
x
其中,a和b为黄金分割比率搜索初始值,
进一步地,所述步骤S5中,使用改进的爬行动物搜索算法优化模型的参数包括:双向长短期记忆网络BiLSTM的学习率和隐藏层节点数、极限梯度提升XGBoost的权重和学习率,最小二乘支持向量机LSSVM的最优惩罚系数和核函数宽度值。
进一步地,所述步骤S6中,使用ELM进行误差修正步骤如下:
S6.1将集成模型得到的初始预测值与原始观测值进行相减,构造误差序列;
S6.2利用ELM网络预测误差序列;
S6.3将初始预测序列和误差预测序列线性相加,得到最终预测结果。
有益效果:
本发明提出的基于深度和集成学习方法兼顾了不同算法的训练原理差异,充分发挥每种模型在预测过程中的优势。基学习器的学习能力越强,相互之间的关联程度越小,最终的预测效果就越好。针对模型超参数难以确定的问题,引入爬行动物搜索算法对模型进行优化,选择最优的模型参数。并提出算法改进以提升算法的寻优能力,所提改进如下:首先,针对算法的随机初始化无法使种群均匀分布在整个寻优空间的问题,引入拉丁超立方初始化保证初始种群均匀覆盖整个分布空间;其次,在迭代过程中,由于进化意义ES值在-2到2之间随机递减策略不能完全解释实际的收敛优化过程,故采用非线性策略进行改进,使算法能更有效地平衡全局和局部搜索能力,提高算法的收敛精度。最后利用黄金正弦和翻筋斗策略改进个体寻优方式,使普通个体在每次迭代中都会与最优个体交换信息,彻底吸收与最优个体的位置差距信息,提高算法搜索性能和搜索准确率。与传统单模型预测相比,本发明的基于深度和集成学习的污水处理过程软测量建模方法有着较高的精度和泛化能力。
附图说明
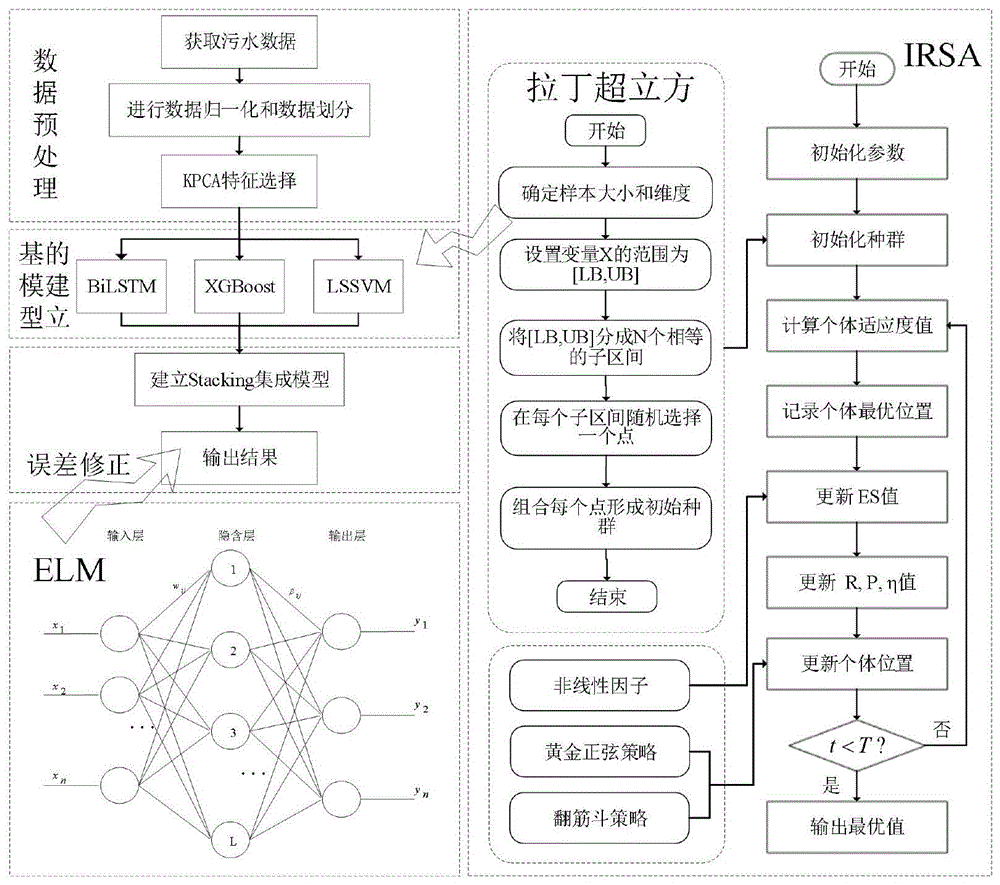
图1是本发明所提供的基于集成深度学习的污水处理过程软测量建模方法多模型训练框架示意图;
图2是本发明提供的基于集成深度学习的污水处理过程软测量建模方法中算法优化模型参数的流程图;
图3是本发明所提供的基于集成深度学习的污水处理过程软测量建模方法的流程图。
具体实施方式
下面结合附图对本发明的实施方式作进一步说明。
如图1所示,本发明提供一种基于集成深度学习的污水处理过程软测量建模方法,包括下列步骤:
S1.从国际基准BSM 1仿真平台获取污水数据并进行数据预处理。
S1.1从国际基准仿真平台获取污水数据,包括氨氮NH3-N、悬浮物浓度SS、化学需氧量COD、总氮TN、总磷TP和历史时刻的生化需氧量BOD。
S1.2对获取的污水数据进行预处理为对数据进行归一化处理,公式如下:
式中,S
S2.使用KPCA将处理好的数据进行特征选择,选取最合适的辅助变量,从而构造软测量数据样本集。
S2.1设训练集样本数据为X=(x
S2.2计算特征空间的协方差矩阵C:
S2.3计算协方差矩阵的特征方程:
λ
式中,λ
S2.4定义核矩阵K:
K=φ(x
S2.5计算核矩阵K的特征方程:
式中,
S2.6将协方差矩阵C和核矩阵K代入到核矩阵K的特征方程中,则协方差矩阵C的特征向量ξ
式中,
S2.7计算核矩阵K的特征值
S2.8依次计算这些特征值的贡献率η
S2.9选取累计贡献率P≥85%的特征作为污水软测量模型输入的主要辅助变量。
S3.将S2中处理好的污水数据集作为Stacking集成框架中的第一层基学习器的原始输入,其中第一层的基学习器包括双向长短期记忆网络BiLSTM、极限梯度提升XGBoost和最小二乘支持向量机LSSVM,第一层基学习器的预测结果是通过对每个基学习器进行5折交叉验证获得的。
S3.1建立双向长短期记忆网络预测模型。
S3.1.1将确定好的辅助变量作为网络的输入向量x。
S3.1.2设前向隐含层状态为
S3.1.3将y
S3.2建立极限梯度提升预测模型。
S3.2.1训练数据集为T={(x
式中,L(φ)是线性空间上的表示,i是第i个样本,k是第k棵树,
S3.2.2利用每一棵树的预测结果去拟合上一颗树预测结果的残差,使整体的树模型效果越来越好;
S3.2.3上一步得到第t棵树的预测结果,在数值上等于前面t-1棵树的预测结果,加上第t棵树的表现。对于第t棵树,目标函数为:
S3.2.4把式(14)用泰勒展开来近似原来的目标,定义
则式(14)可化为:
S3.2.5求得目标函数的最优解为:
式中
S3.2.6算出增益值Gain,更新最大增益Gain_max,更新分隔点,最终得到最优的分隔点。
S3.2.7重复上述过程递归建树直到终止条件。
S3.3建立最小二乘支持向量机预测模型。
S3.3.1优化目标,定义损失函数为:
具有约束条件:
式中,ω是权重,ξ
S3.3.2引入拉格朗日乘子,式(18)可以转化为:
式中,拉格朗日乘子a
S3.3.3求解最优条件
S3.3.4综合上述公式得到最优回归函数如下:
式中,K(x
S4.将从第一层基学习器获得的结果用作第二层元学习器的训练集,以完成第二层元学习器的训练,其中元学习器预测模型为ELM,计算公式如下:
式中,L是隐层单元的数量,N是训练样本的数量,β是第i个隐藏层和输出层之间的权重向量,w是输入和输出之间的权重向量,g是激活函数,b是偏置向量,x是输入向量。
S5.采用改进的爬行动物搜索算法对基学习器的模型参数进行优化,利用优化后的模型进行软测量,得到生化需氧量的预测结果。
S5.1使用拉丁超立方抽样初始化代替RSA算法的随机初始化,设置IRSA的搜索上下界、种群大小和迭代次数。
其中拉丁超立方抽样初始化的步骤如下:
S5.1.1确定种群大小A和维度D。
S5.1.2设置变量A的区间为[low,up],up和low分别是变量A的上界和下界。
S5.1.3将变量A的区间分为N个相等的子区间。
S5.1.4从每个维度的每个子区间中随机选择一个点。
S5.1.5将所选择的每个点组合起来,形成初始种群。
S5.2包围阶段,鳄鱼个体开始包围猎物,其数学模型如下:
η
式中,B
S5.3对公式(26)的进化意义参数进行改进,改进后的进化意义表达式如下:
S5.4狩猎阶段,鳄鱼个体开始捕猎,其数学模型如下:
S5.5对位置更新公式(30)引入黄金正弦和翻筋斗策略,改进后的公式如下:
式中,γ
x
x
其中,a和b为黄金分割比率搜索初始值,
S5.6使用改进的爬行动物搜索算法优化模型BiLSTM的学习率和隐藏层节点数、XGBoost的权重和学习率、LSSVM的最优惩罚系数和核函数宽度值。
S6.采用ELM对初始预测结果进行误差校正,得到最终预测结果。
S6.1将集成模型得到的初始预测值与原始观测值进行相减,构造误差序列。
S6.2利用ELM网络预测误差序列。
S6.3将初始预测序列和误差预测序列线性相加,得到最终预测结果。
S7.基于QT、Python和MATLAB共同搭建污水处理软测量平台,包括用户登录界面、污水数据监测以及在线预测模块,实现软测量系统可视化的目标。
本发明还实现了BOD软测量智能系统,系统包括数据采集模块、数据处理模块、模型训练模块、参数优化模块、误差校正模块、在线监测模块。
数据采集模块:用于获取污水数据,包括氨氮NH3-N、悬浮物浓度SS、化学需氧量COD、总氮TN、总磷TP和历史时刻的生化需氧量BOD。
数据处理模块:使用KPCA方法对采集到的污水数据进行特征提取,选取相关性高的特征,筛选出最适合模型输入的辅助变量。
模型训练模块:建立了基于Stacking方法的集成模型,该方法将BiLSTM、XGBoost、LSSVM进行Stacking集成,缓解过拟合的同时提升模型效果。
参数优化模块:使用IRSA算法对模型的参数进行优化,包括BiLSTM的学习率和隐藏层节点数,XGBoost的权重和学习率,LSSVM的最优惩罚系数和核函数宽度值。
误差矫正模块:用使用ELM对初次预测结果进行基于误差序列的矫正。
在线监测模块:包括用户登录界面、污水数据监测以及在线预测模块,实现软测量系统可视化的目标。
本发明并不局限于上述具体实施案例,凡是依据本发明的技术实质对以上实施例所做的任何简单修改、等同变化与修饰,均属于发明技术方案的范围内。
- 基于混沌-烟花混合算法的污水处理过程软测量建模方法
- 基于混沌-烟花混合算法的污水处理过程软测量建模方法