一种基于无监督学习的视频去模糊方法
文献发布时间:2023-06-19 19:28:50
技术领域
本发明属于视频去模糊计算领域,具体涉及一种基于无监督学习的视频去模糊方法。
背景技术
在计算机视觉领域中,视频作为图像在时间维度上的拓展,包含了更多的信息,有助于提升各类任务的性能。然而,受限于硬件设备、拍摄场景和拍摄技术,无人驾驶和机器人领域中,相机抖动和物体运动会造成拍摄的视频出现模糊,导致算法的性能降低。模糊的本质是相机单个感光元件在曝光时间内接收到了不同物体的光,经过相机响应函数后像素的值发生了偏差。此外,相机拍摄的过程将三维世界中的信息投影到二维成像平面上,该过程丢失了一个维度的信息。因此,去模糊问题是一个非适定问题。这也导致了深度学习方法在视频去模糊领域的效果远超传统去模糊方法。
深度学习作为一项数据驱动型方法,其效果的好坏很大程度上依赖于数据集的质量。为了提高深度学习方法的鲁棒性,通常要使用庞大的数据集进行训练。然而,在视频去模糊领域,无论使用的数据集多庞大,始终无法涵盖真实世界情况下的方方面面。例如,数据集如果都是在城市环境中采集得到,那用它训练出来的模型在自然环境中的效果可能会大打折扣。除此之外,深度学习的监督学习要求提供真实标签,而目前的相机无法在拍摄模糊视频的同时获得其对应的清晰视频。现有的大多数数据集通过拍摄超高帧率的清晰视频,然后合成得到模糊视频。这种合成模糊数据集跟真实模糊数据集存在一定的区别。综上,用于监督学习的数据集和真实世界中存在的域上的差异,导致使用深度学习的视频去模糊算法效果收到限制。基于无监督的视频去模糊算法则可以直接使用真实情况下采集的模糊视频训练网络,减小了域上的差异。
发明内容
针对现有技术中存在的不足,本发明提供一种基于无监督学习的视频去模糊方法。
本发明旨在提供一种有用的解决方案。为此,本发明的目的在于解决视频去模糊问题,其输入为模糊的视频,输出为其对应的清晰视频,发明中的方法使用无监督学习的方法,从输入视频中构建数据集训练去模糊网络。
一种基于无监督学习的视频去模糊方法,包括以下步骤:
步骤(1)、构建去模糊网络;
步骤(2)、根据输入视频中每一帧图像的边缘信息,将视频中图像块归类成清晰和不清晰两类;
步骤(3)、使用不清晰的图像块生成数据集,对去模糊网络进行训练;
步骤(4)、使用清晰的图像块生成数据集,对去模糊网络进行训练;
步骤(5)、使用训练好的去模糊网络对输入视频进行去模糊,得到清晰视频;
进一步的,步骤(1)具体方法如下;
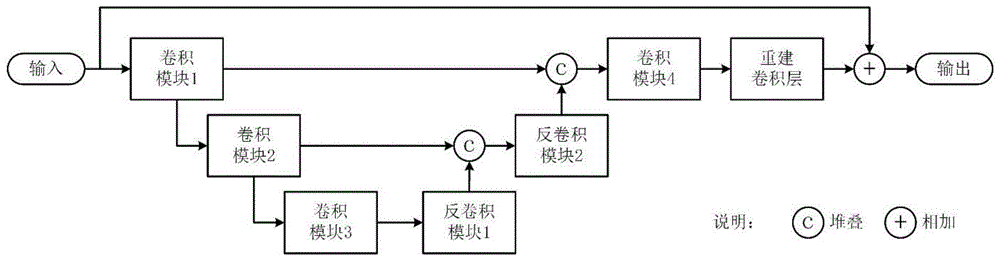
1-1、去模糊网络的结构,整个网络采用UNet结构,由4个卷积模块,分别为卷积模块1、卷积模块2、卷积模块3、卷积模块4、3个反卷积模块,分别为反卷积模块1、反卷积模块2、反卷积模块3和1个重建卷积层构成。卷积模块1、卷积模块2、卷积模块3和反卷积模块1串联,然后卷积模块2的输出和反卷积模块1的输出经过连接后输入反卷积模块2,而卷积模块1的输出和反卷积模块2的输出经过连接后输入卷积模块4,接着输入重建卷基层,最后与网络的输入求和得到最终的输出。每个卷积模块由1个卷积层和6个残差块串联而成,残差块依次包括1个卷积层、1个ReLU激活函数和1个卷积层,并且最后卷积层的输出会跟残差块的输入相加,得到残差块最终的输出。反卷积模块则在卷积模块最后的串联上了1个反卷积层。重建卷积层为普通的卷积层。整个去模糊网络中,除了卷积模块2和卷积模块3的第一个卷积层的步长为2,其余所有的卷积层的步长都为1,而所有反卷积层的步长都为1;所有的卷积层的卷积核大小为3,填充宽度为1;所有的反卷积层的卷积核大小为4,填充宽度为1;;
1-2、去模糊网络输入一帧模糊图像,依次经过3个卷积模块后,经过反卷积模块1,然后跟卷积模块2的输出在通道维度上堆叠后经过反卷积模块2,接着跟卷积模块1的输出在通道维度上堆叠后经过卷积模块4,再经过重建卷积层,最后与输入的图像图像相加,就可以得到去模糊后的清晰图像;
进一步的,步骤(2)具体方法如下;
2-1、假设输入的模糊视频B中共有N帧图像,每一帧图像表示为B
2-2、将边缘图像E
其中,H和W表示输入视频的高和宽,a和b分别表示1到x和1到y之间的所有整数。为了加速积分图的计算过过程,可以使用增量的方式计算,即:
S
2-3、使用积分图S
P
P
2-4、根据阈值t,将P
/>
进一步的,步骤(3)具体方法如下;
3-1、选择除了第一张和最后一张外所有的M
L
其中,sum()为求和函数。
3-2、对于集合w
3-3、将步骤3-2得到的所有图像作为数据集
进一步的,步骤(4)具体方法如下;
4-1、选择除了第一张和最后一张外所有的M
L
4-2、对于集合w
4-2-1、选取图像块
4-2-2、随机生成5个模糊核。每个模糊核大小为31像素*31像素,模糊轨迹线性且过模糊核的中心,并且关于模糊核中心对称。模糊轨迹使用运动矢量表示,即m=(l,θ),l∈[0,15]表示模糊轨迹在水平方向投影长度的一半,θ∈[0°,180°]表示模糊轨迹与水平右方向的角度。使用随机生成的5个模糊核分别卷积图像块
4-3、将步骤4-2得到的所有图像作为数据集
本发明的特点及有益效果:
本发明实现了一种基于无监督学习的视频去模糊方法,对视频去模糊有较大意义。本发明无需模糊视频对应的真实清晰视频,而是从输入视频中构建数据集训练去模糊网络,减小数据集和真实情况的差异,提升视频去模糊性能。
此技术可以在普通PC机或工作站等硬件系统上实现。
附图说明
图1为本发明实施例去模糊网络的结构示意图;
图2为本发明实施例卷积模块的结构示意图;
图3为本发明实施例残差块的结构示意图;
图4为本发明实施例反卷积模块的结构示意图;
图5为本发明实施例模糊核的示意图;
具体实施方式
为使本发明的上述目的、特征和优点能够更加明显易懂,下面结合附图和具体实施方式对本发明作进一步详细的说明。
本发明提出的基于无监督学习的视频去模糊方法,包括以下步骤:
步骤(1)、构建去模糊网络;
1-1、去模糊网络的结构如图1所示,整个网络采用UNet结构,由4个卷积模块,分别为卷积模块1、卷积模块2、卷积模块3、卷积模块4、3个反卷积模块,分别为反卷积模块1、反卷积模块2、反卷积模块3和1个重建卷积层构成。卷积模块1、卷积模块2、卷积模块3和反卷积模块1串联,然后卷积模块2的输出和反卷积模块1的输出经过连接后输入反卷积模块2,而卷积模块1的输出和反卷积模块2的输出经过连接后输入卷积模块4,接着输入重建卷基层,最后与网络的输入求和得到最终的输出。每个卷积模块由1个卷积层和6个残差块串联而成,如图2所示。残差块依次包括1个卷积层、1个ReLU激活函数和1个卷积层,并且最后卷积层的输出会跟残差块的输入相加,得到残差块最终的输出,如图3所示。反卷积模块则在卷积模块最后的串联上了1个反卷积层,如图4所示。重建卷积层为普通的卷积层。整个去模糊网络中,除了卷积模块2和卷积模块3的第一个卷积层的步长为2,其余所有的卷积层的步长都为1,而所有反卷积层的步长都为1;所有的卷积层的卷积核大小为3,填充宽度为1;所有的反卷积层的卷积核大小为4,填充宽度为1;各个卷积层和反卷积层的输入输出通道数见表1(表中每一格的数据表示输入通道数/输出通道数,且每个残差块中的卷积层的输入输出通道数都相等);表1卷积层和反卷积层的输入输出通道数
1-2、去模糊网络输入一帧模糊图像,依次经过3个卷积模块后,经过反卷积模块1,然后跟卷积模块2的输出在通道维度上堆叠后经过反卷积模块2,接着跟卷积模块1的输出在通道维度上堆叠后经过卷积模块4,再经过重建卷积层,最后与输入的图像图像相加,就可以得到去模糊后的清晰图像;
步骤(2)、根据输入视频中每一帧图像的边缘信息,将视频中图像块归类成清晰和不清晰两类;
2-1、假设输入的模糊视频B中共有N帧图像,每一帧图像表示为B
2-2、将边缘图像E
其中,H和W表示输入视频的高和宽,a和b分别表示1到x和1到y之间的所有整数。为了加速积分图的计算过过程,可以使用增量的方式计算,即:
S
2-3、使用积分图S
P
P
2-4、根据阈值t,将P
具体实践中,阈值t=13000,可以根据实际情况进行微调。
步骤(3)、使用不清晰的图像块生成数据集,对去模糊网络进行训练;
3-1、选择除了第一张和最后一张外所有的M
L
其中,sum()为求和函数。
3-2、对于集合w
3-3、将步骤3-2得到的所有图像作为数据集
步骤(4)、使用清晰的图像块生成数据集,对去模糊网络进行训练;
4-1、选择除了第一张和最后一张外所有的M
L
4-2、对于集合w
4-2-1、选取图像块
4-2-2、随机生成5个模糊核。每个模糊核大小为31像素*31像素,示意图如图5,模糊轨迹(图中白色实线)线性且过模糊核的中心,并且关于模糊核中心对称。模糊轨迹使用运动矢量表示,即m=(l,θ),l∈[0,15]表示模糊轨迹在水平方向投影长度的一半,θ∈[0°,180°]表示模糊轨迹与水平右方向的角度。使用随机生成的5个模糊核分别卷积图像块
4-3、将步骤4-2得到的所有图像作为数据集
步骤(5)、使用训练好的去模糊网络对输入视频进行去模糊,得到清晰视频。
- 一种基于无监督学习的单目视觉定位方法
- 一种用于视频去模糊的无监督学习方法
- 一种基于无监督学习的监控视频异常检测方法