基于多粒度视频信息提取的人员再识别模型、方法、装置
文献发布时间:2023-06-19 19:28:50
技术领域
本发明属于视频识别领域,具体的说,涉及了一种基于多粒度视频信息提取的人员再识别模型、方法、装置。
背景技术
人员再识别(Re-ID)旨在从非重叠场景摄像机拍摄的一组行人图像/视频中检索感兴趣的人员。随着视频捕获系统的普及,基于视频的人物识别最近引起了越来越多的关注。与图像数据相比,视频数据包含更丰富的空间和时间线索,可以利用这些线索来减少识别错误,从而实现更稳健的Re-ID。如图1所示,虽然视频可以提供更全面的信息,但它也带来了更多的问题,如光线变化、复杂的背景和人的遮挡。因此,基于视频的行人身份识别技术的研究仍然存在许多挑战。
以前的方法侧重于挖掘有效的时空特征以提高识别精度。对于空间线索,大多数方法只关注一些突出的特征,而忽略了一些细粒度线索的影响。有一些方法试图通过多种注意力机制来解决这个问题。例如,J.Yang,W.-S.Zheng,Q.Yang,Y.-C.Chen,Q.Tian,Spatial-temporal graph convolutional network for video-based person re-identification,in:Proceedings of the IEEE/CVF conference on computer visionand pattern recognition,2020,pp.3289–3299.采用了多种注意力机制,并迫使他们将注意力集中在图像的不同区域。但是这些注意力模块仍然有重叠的注意力区域,没有挖掘更细粒度的线索;
对于时间线索,相邻帧之间的短期时间线索有助于区分视觉上相似的行人,而长期时间线索有助于缓解视频序列中的遮挡和噪声。以前的大多数方法只对短期或长期时间关系建模,而没有考虑它们的互补性。也有一些方法,例如R.Zhao,W.Ouyang,X.Wang,Learning mid-level filters for person re-identification,in:Proceedings of theIEEE conference on computer vision and pattern recognition,2014,pp.144–151,以及D.Chen,Z.Yuan,B.Chen,N.Zheng,Similarity learning with spatial constraintsfor person re-identification,in:Proceedings of the IEEE conference oncomputer vision and pattern recognition,2016,pp.1268–1277,试图联合捕捉短期和长期时间关系,但并没有考虑不同时间关系的不同重要性。
为了解决上述问题,需要提出一种新的基于视频的人员再识别方法。
发明内容
本发明的目的是针对现有技术的不足,提供一种基于多粒度视频信息提取的人员再识别模型、方法、装置。
为了实现上述目的,本发明所采用的技术方案是:
本发明第一方面提供一种基于多粒度视频信息提取的行人再识别模型,采用以下方法训练获得:
步骤1,将2D resnet-50神经网络框架扩展至3D resnet-50神经网络框架;
步骤2,对于一个视频片段,依次输入3D resnet-50的Stage1和Stage2进行视频级特征提取,得到相应的特征F;
步骤3,将Stage2提取出的特征F送入时间核注意模块TKAM进行特征提取,以捕捉视频中的短期和长期时间关系;
步骤4:将时间核注意模块TKAM模块提取出的特征送入3D resnet-50的Stage3,再将Stage3输出的特征传入特征分离空间注意力模块FDSA进行特征提取,以挖掘视频中不同粒度的空间线索;
步骤5:将特征分离空间注意力模块FDSA输出的特征依次输入3Dresnet-50的剩余Stage,最后通过Global Pooling层得到一个2048维特征向量;
步骤6:根据Triplet与Cross entropy Loss函数将2048维特征向量反向传播进行模型训练。
本发明第二方面提供一种基于多粒度视频信息提取的行人再识别方法,包括:
构建所述的基于多粒度视频信息提取的行人再识别模型;
基于所构建的模型,进行视频的行人再识别。
本发明第三方面提供一种基于多粒度视频信息提取的行人再识别装置,包括:
存储器;以及
耦接至所述存储器的处理器,所述处理器被配置为基于存储在所述存储器中的指令执行所述的基于多粒度视频信息提取的行人再识别方法。
本发明第四方面提供一种非瞬时性计算机可读存储介质,其上存储有计算机程序,该程序被处理器执行时实现所述的基于多粒度视频信息提取的行人再识别方法。
本发明相对现有技术具有突出的实质性特点和显著进步,具体的说:
1、本发明在进行行人再识别时,将时间信息和空间信息分开处理,创建了时间核注意模块TKAM和特征分离空间注意力模块FDSA两个新模块;
2、本发明的特征分离空间注意力模块FDSA对视频中的空间信息,不仅考虑了突出特征对识别的作用,也考虑了一些细微特征的影响。
3、本发明的时间核注意模块TKAM对视频中的时间信息,同时考虑了长期和短期时间依赖关系,并能根据视频序列的不同,对各个时间关系分配不同的权重。
4、本发明通过时间核注意模块TKAM和特征分离空间注意力模块FDSA的配合,使模型拥有更好的效果。
附图说明
图1是现有的基于视频的人员再识别结果(数据源是MARS)。
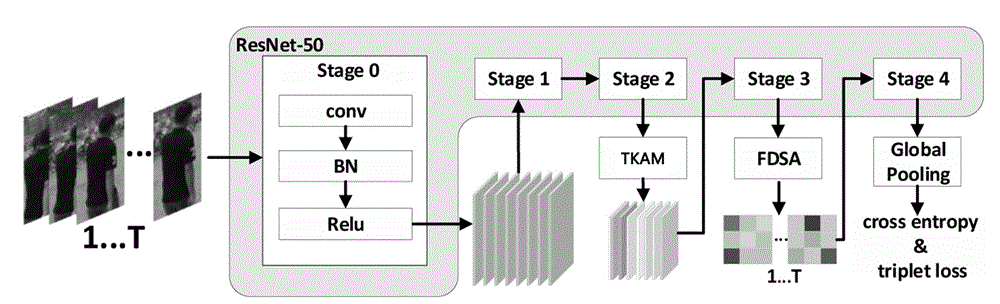
图2是本发明模型的结构原理图。
图3本发明模型中时间核注意模块TKAM的结构原理图。
图4是本发明模型中特征分离空间注意力模块FDSA的结构原理图。
图5是本发明实验过程中,在MARS上可视化的所提出模型的信道激活图。
具体实施方式
下面通过具体实施方式,对本发明的技术方案做进一步的详细描述。
实施例1
如图2所示,本实施例提供一种基于多粒度视频信息提取的行人再识别模型MSTN(Multi-granular Spatial and Temporal Network),采用以下方法训练获得:
步骤1,将2D resnet-50神经网络框架扩展至3D resnet-50神经网络框架。
步骤2,对于一个视频片段,依次输入3D resnet-50的Stage1和Stage2进行视频级特征提取,得到相应的特征F。
步骤3,将Stage2提取出的特征F送入时间核注意模块TKAM进行特征提取,以捕捉视频中的短期和长期时间关系。
3D卷积可以沿着时间维度滑动来建模时间信息,因此它被广泛应用于视频问题。但受卷积核大小的限制,它们只能捕获固定长度的时间关系。这限制了网络提取时间特征的能力。为了进一步探索视频中的时间信息,设计了一个时间核注意模块TKAM,以在多个尺度上同时建模时间关系。
TKAM模块的结构如图3所示,TKAM将连续帧的特征图作为输入,并执行以下步骤以获得输出:
分区操作
由于不完美的人物检测结果和姿势变化,在基于视频的人物重新识别中,时间信息出现错位是不可避免的,为了解决这个问题并降低计算复杂性,采用了以下分区策略:
将输入特征F∈R
F
扩展时间金字塔卷积
将区域特征F
f
其中,DConv
通道注意力机制
对于不同的视频序列,不同的时间关系应该具有不同的权重。因此,对扩展时间金字塔卷积模块DTP中的不同空洞卷积路径执行global average pooling和通道注意机制,以调整每路空洞卷积的权重;
/>
其中,Conv1
而后对所有空洞卷积路径的输出进行求和,其中通道注意力机制的输出z定义为:
采用邻近插值法对经过扩展时间金字塔卷积模块DTP后的视频帧先进行上采样获得上采样特征Z;
Z=upsample(z)
其中,Z包含丰富的长期和短期时间信息;
时空注意力机制
在视频中,不同的帧可能具有不同的质量和视觉信息,平等对待不同的空间和时间线索是不合理的。因此,需要在输入特征上实现时空注意力机制,为不同的时空线索分配不同的权重。设计了时空注意力机制,将输入特征F执行时空注意力机制输出掩码M
为了降低掩码M
M
其中,C
时间注意力
时空注意力机制中,时间注意力首先使用一个池化层来聚合空间和通道线索;
然后,使用两个1×1卷积来生成时间掩码映射T
T
空间注意力
时空注意力机制中,空间注意力首先使用一个池化层来聚合时间线索;
然后,使用3×3卷积层conv1生成单通道注意力图,再使用一个1×1卷积层,用于学习比例参数以进行进一步融合,获得空间掩码映射S
S
通道注意力
时空注意力机制中,通道注意力使用一个池化层来聚集空间和时间信息,然后,使用两个1×1卷积层生成通道掩码映射C
C
其中,Conv1
最后,将生成的掩码M
F’=F×M
其中,F′是TKAM模块的输出特征,TKAM模块能够提取丰富的时间关系并为每个视频帧分配不同的权重,可以有效地挖掘视频中的时间线索。
步骤4:将时间核注意模块TKAM模块提取出的特征送入3D resnet-50的Stage3,再将Stage3输出的特征传入特征分离空间注意力模块FDSA进行特征提取,以挖掘视频中不同粒度的空间线索。
在基于视频的Re-ID中,注意力机制被广泛用于挖掘显著的区域特征。然而,现有的基于注意力的方法过于关注特定区域,而忽略了细粒度线索。为了缓解这个问题,提出了一个特征分离空间注意力模块FDSA,如图4所示。FDSA模块可以将空间特征划分为两个互补的特征,并使用注意机制将注意力集中在各自的区域。
特征分离
对输入的特征F
F
F
将F
将扩展的
相关掩码M
其中,M
将相关掩码M
通道和空间注意力
将高相关特征F
其中,Mc和Ms分别是通道注意机制和空间注意力机制输出的掩码,定义为:
其中,
其中,
离散特征融合
将相关特征
F
步骤5:将特征分离空间注意力模块FDSA输出的特征依次输入3Dresnet-50的剩余Stage,最后通过Global Pooling层得到一个2048维特征向量;
步骤6:根据Triplet与Cross entropy Loss函数将2048维特征向量反向传播进行模型训练。
验证实验
数据集和评估协议
MARS,是一个基于视频的大型行人Re-ID数据集,包含来自1261个身份的17503个小轨迹和另外3248个低质量小轨迹,这些小轨迹是由6个摄像机捕获的干扰物。它的训练集包含625个身份,测试集包含636个身份,至少由2个摄像机采集;
DukeMTMC-VID,是另一个行人重新识别数据集。它来自DukeMTMC数据集。它有4832个轨迹和1812个标识,其中2196个轨迹中的702个标识用于训练,702个身份中的3338个轨迹用于测试;
对于评估协议,采用平均平均精度(mAP)和累积匹配特征(CMC)作为评估指标。
具体的验证过程
本次实验所有模型都是使用PyTorch进行训练和微调的。实验设备包括Intel i5-6500 CPU和NVIDIA RTX TITAN GPU(24G内存)。为了生成训练序列,对每个视频序列随机采样8帧(步幅大小设置为4)以形成视频片段。对于每个帧,将其调整为256×128,并使用水平翻转和随机擦除。在ImageNe上预先训练的3D resnet-50被用作主干网络。在训练期间,使用Adam以0.0005的权重衰减来更新参数。初始学习率设置为0.00035,并遵循学习率衰减策略。在测试过程中,将每个视频序列分成8帧视频片段并提取其特征。最后的视频特征是所有剪辑的平均表示。之后,使用余弦相似性来测量查询和图库之间的距离。
与现有技术的比较
将本发明模型与其他最先进的模型在两个基于视频的人员重新识别基准上进行比较。实验结果如表1所示。在MARS数据集上,本发明模型的mAP和Rank-1准确率分别为86.1%和91.0%。在mAP评估指标上,本发明模型分别优于BiCnet-TKS、GRL和STMN 0.1%、1.3%和1.6%。在等级1评估指标上,本发明模型也取得了优异的性能,分别比BiCnet-TKS、STRF和STMN的性能好0.8%、0.7%和0.5%。虽然STRF和GRL分别在mAP和Rank-1度量上的结果与本发明模型相似,但本发明模型在另一个度量上有更好的性能。在DukeMTMC-VID数据集上,本发明模型的mAP和Rank-1评估指标的准确率分别为96.5%和96.9%。在mAP评估指标上,本发明模型取得了最佳结果。
表1
消融研究
进行消融研究实验,以验证本发明模型的有效性。所有模型都在MARS上进行训练和评估。基线模型采用3D resnet-50,并使用交叉熵和三重态损失进行训练。
关键部件的影响
关键部件的消融结果如表2所示。“+FDSA”表示在基线上添加了FDSA模块。FDSA(F
表2
放置TKAM的有效位置
TKAM模块保持输入大小,可以插入主干的任何阶段,以提取多粒度空间特征。主干网络是3D resnet-50,它有4个阶段。表3比较了将TKAM模块放置在3D resnet-50的不同阶段的结果。可以看出,本发明提出的TKAM模块在插入第2阶段时获得了最佳结果。尽管TKAM模块在第3阶段也获得了竞争性结果,但它导致了模型参数的大幅增加。因此,选择stage2作为TKAM模块的插入位置。
表3
DTP中并行路径数的影响
DTP卷积有N条平行路径,每条路径由具有不同扩张速率的扩张卷积组成。实验结果如表4所示。将表中的所有模块插入第2阶段。探索了三条路径及其组合,其中p1、p2、p3表示路径使用扩张率分别为1、2和3的扩张卷积。可以发现,使用多条路径时,模型性能显著提高,远远超过仅使用一条路径的性能。这一现象证明了联合使用长期和短期时间信息的有效性。此外,还可以发现,拥有更多的路径并不会带来更多的性能增益,使用路径p1和p2可以获得更好的结果。
表4
有效定位FDSA
FDSA模块也可以插入到主干网的任何阶段。表5比较了将FDSA模块放置到膨胀的resnet50的不同阶段的结果。可以看出,在阶段3中放置一个FDSA模块的效果最好。与插入阶段2相比,插入到阶段3只需要增加少量的参数,但可以取得更好的效果。但是将FDST模块放在阶段1将导致严重的性能下降,这是由于低级特性大大增加了计算复杂性。此外,低级特征阶段1可能不足以提供精确的语义信息。
表5
可视化分析
在MARS上可视化了所提出模型的信道激活图。如图5所示,第二行和第三行分别表示获得的高相关性和低相关性特征。高相关特征和低相关特征所关注的区域明显不同。高相关特征往往集中在空间上更突出的区域,而低相关特征往往关注一些细微的线索。第四行和第五行代表了两个特征的注意力机制所获得的结果。可以看出,在注意力机制之后,这两个特征得到了进一步优化。最后一行表示高相关性和低相关性特征的融合结果。融合的特征将两种特征的优点结合在一起,既可以关注空间上重要的区域,也可以挖掘一些细粒度的线索。视觉地图进一步验证了本发明模型的有效性。
实施例2
本实施例提供一种基于多粒度视频信息提取的行人再识别方法,包括:
构建实施例1所述的基于多粒度视频信息提取的行人再识别模型;
基于所构建的模型,进行视频的行人再识别。
实施例3
本实施例提供一种基于多粒度视频信息提取的行人再识别装置,包括:
存储器;以及
耦接至所述存储器的处理器,所述处理器被配置为基于存储在所述存储器中的指令执行实施例2所述的基于多粒度视频信息提取的行人再识别方法。
本实施例装置还可以包括输入输出接口、网络接口、存储接口等。这些接口以及存储器和处理器之间例如可以通过总线连接。其中,输入输出接口为显示器、鼠标、键盘、触摸屏等输入输出设备提供连接接口。网络接口为各种联网设备提供连接接口。存储接口为SD卡、U盘等外置存储设备提供连接接口。
实施例4
本实施例提供一种非瞬时性计算机可读存储介质,其上存储有计算机程序,该程序被处理器执行时实现实施例2所述的基于多粒度视频信息提取的行人再识别方法。
本领域内的技术人员应当明白,本发明的实施例可提供为方法、系统、或计算机程序产品。因此,本发明可采用完全硬件实施例、完全软件实施例、或结合软件和硬件方面的实施例的形式。而且,本发明可采用在一个或多个其中包含有计算机程序代码的计算机非瞬时性可读存储介质(包括但不限于磁盘存储器、CD-ROM、光学存储器等)上实施的计算机程序产品的形式。
本发明是参照根据本发明实施例的方法、设备(系统)、和计算机程序产品的流程图和/或方框图来描述的。应理解为可由计算机程序指令实现流程图和/或方框图中的每一流程和/或方框、以及流程图和/或方框图中的流程和/或方框的结合。可提供这些计算机程序指令到通用计算机、专用计算机、嵌入式处理机或其他可编程数据处理设备的处理器以产生一个机器,使得通过计算机或其他可编程数据处理设备的处理器执行的指令产生用于实现在流程图一个流程或多个流程和/或方框图一个方框或多个方框中指定的功能的装置。
这些计算机程序指令也可存储在能引导计算机或其他可编程数据处理设备以特定方式工作的计算机可读存储器中,使得存储在该计算机可读存储器中的指令产生包括指令装置的制造品,该指令装置实现在流程图一个流程或多个流程和/或方框图一个方框或多个方框中指定的功能。
这些计算机程序指令也可装载到计算机或其他可编程数据处理设备上,使得在计算机或其他可编程设备上执行一系列操作步骤以产生计算机实现的处理,从而在计算机或其他可编程设备上执行的指令提供用于实现在流程图一个流程或多个流程和/或方框图一个方框或多个方框中指定的功能的步骤。
最后应当说明的是:以上实施例仅用以说明本发明的技术方案而非对其限制;尽管参照较佳实施例对本发明进行了详细的说明,所属领域的普通技术人员应当理解:依然可以对本发明的具体实施方式进行修改或者对部分技术特征进行等同替换;而不脱离本发明技术方案的精神,其均应涵盖在本发明请求保护的技术方案范围当中。
- 基于视频获取人脸识别模型训练数据的方法、装置和介质
- 基于肌电信号的步态识别模型建立方法、识别方法及装置
- 基于声纹识别的视频参数调整方法、装置及读存储介质
- 基于深度学习编码模型的人员再识别方法
- 一种面向在线视频学习的基于细粒度特征与TCN模型的情感识别方法