一种融合视觉情境的富语义对话生成方法
文献发布时间:2023-06-19 19:28:50
技术领域
本发明属于深度学习技术领域,具体涉及一种融合视觉情境的富语义对话生成方法。
背景技术
在人工智能飞速发展的今天,要实现机器与人类的自然交互仍是一项极具挑战性的任务,其中一个重要原因是现有的对话系统大多是基于单模态的文本来进行的,虽然文本是人类之间表达信息和相互交流的重要手段,但现实世界是自然多模态的,除了文本之外,人们会持续接收视频、音频、图像等多模态的信息,并针对这些特定的场景信息给出更加个性化和多样化的处理和交互方式。因此,视听说是智能系统实现自然交互的必备能力,基于多模态数据(文本、图像、视频等)的对话系统将是实现真正拟人化对话系统的重要途经。通过理解视觉情境信息,对话系统可以生成信息丰富且高质量的回复,以更加自然的方式与人类进行对话交互。未来多模态对话系统将是众多复杂的人工智能系统与应用中不可或缺的组成部分,例如盲人导航系统可以通过对话的方式帮助视力受损用户了解他们的周围情况或社交媒体内容,提高生活质量。
相比于基于文本或者语音的对话系统,视觉情境融合的人机对话系统目标是根据给定的输入视觉情境信息(视频内容)以及自然语言文本形式的对话内容(历史对话,视频摘要,当前问题)进行理解和推理,最后生成与问题相对应的自然语言形式的回复,整个过程不仅需要对复杂的视觉场景信息进行处理,还需要考虑历史上下文中的语言信息,并对两个模态的信息进行充分融合,才能生成符合当前视觉场景并且正确流畅的对话内容。挑战在于如何将这些侧重点不同的关键技术合为一体帮助对话系统获得情境敏感和认知推理能力,从而使对话系统能够更加深刻和全面的理解现实世界,实现更加和谐的人机交互。
发明内容
为了克服现有技术的不足,本发明提供了一种融合视觉情境的富语义对话生成方法,收集具有挑战性的视听场景感知数据集对模型进行训练,整体模型在Transformer的基础上设计并实现了多步交叉模态注意力机制,细粒度捕捉时空维度上的不同模态间异构语义关联,而后将多模态特征表示联合构建成时空图结构并使用图卷积网络进行跨模态学习推理,最后解码生成符合当前情境,内容丰富准确的对话回复。本发明通过多模态数据的融合和跨模态交互捕捉多角度细粒度渐进式特征交互和模态间语义关联,实现视觉-语言跨模态语义对齐,提升模型语义理解和推理能力,最终生成信息丰富且高质量的回复。
本发明解决其技术问题所采用的技术方案包括如下步骤:
步骤1:收集视频对话相关开源数据集,并对数据进行预处理,划分训练集、验证集与测试集;
步骤2:数据预处理;
视频内容中存在四种类型的多模态特征表示,即视频静态特征、视频动态特征、当前问题特征和历史对话与总结信息拼接的文本特征;进行特征提取时加入位置编码,得到最终模型的输入表示,如下:
其中PE(pos,2i)代表句子序列中第pos个单词的第2i个维度上的值,PE(pos,2i+1)代表句子序列中第pos个单词的第2i+1个维度上的值;
步骤3:模型构建;
(1)首先构建基于编解码架构的对话系统,通过对视频中的帧信息使用预训练模型进行特征提取,获取到静态和动态的视频语义信息,然后将其与对话文本内容分别进行编码,并建模细粒度的模态内上下文语义信息;
(2)使用基于交叉模态的多步注意力机制进行多模态数据的融合和跨模态交互,捕捉多角度细粒度渐进式特征交互和模态间语义关联,实现视觉-语言跨模态语义对齐;
(3)将多模态特征表示联合构建成时空图结构,基于动态时空场景进行图推理得到跨模态融合特征后,解码生成对话回复;
步骤4:编码阶段;
对于编码部分,使用4个标准Transformer编码器,对不同模态输入特征进行语义编码,包括视频静态特征、视频动态特征、历史对话与视频摘要特征和当前问题特征;其中,同属文本模态的历史对话与视频摘要特征和当前问题特征所使用的编码器将共享权重;
首先通过多头注意力模块根据上下文对句子序列中的单词向量进行更新,如下:
MultiHead(Q,K,V)=Concat(head
head
其中Q,K,V分别由三个不同的权重矩阵W
然后经过前馈神经网络层得到编码阶段的输出,如下:
FFN(Z)=max(0,Z,W
其中Z代表多头注意力层的输出内容,W
编码阶段中的多头注意力层和前馈神经网络层后都附加有残差连接和层归一化过程,如下:
SubLayer
其中SubLayer指多头注意力层或前馈神经网络层,x表示输入;
步骤5:多步交叉模态注意机制;
将注意力机制从单步扩展到多步,在不同的注意力计算中,查询向量依次来源于其中一个模态类型数据,其余三个模态类型数据分别用于计算键向量和值向量,实现其中一个特征维度与其余三个维度之间的交叉注意;对于每一次的注意力机制计算,采用重复两次反复交互的策略,以三组六次的交叉模态注意力计算,多步交叉注意计算的具体更新和操作公式如下:
a
M
其中,a
同理计算当前模态与其余模态之间的相互作用,将所有计算得到的相互作用进行拼接后经过线形层映射到同一维度,最后与当前模态特征相加,得到与其他模态的融合更新后的当前模态特征表示;
步骤6:跨模态推理;
采用图卷积网络GCN进行跨模态推理工作,在先前的特征表示和融合步骤中得到语言模态和视觉模态的交叉嵌入特征,对该特征构建无向异构图,即一个包含所有视觉和语言向量的异构输入矩阵,在异构图中进行基于图的对齐,得到基于语义相似度加权的跨模态对齐邻接矩阵,进一步使用GCN在图上执行关系推理;具体为,通过图中相邻节点和自身节点的线性变换进行节点值的更新,图中边的权值由对齐的邻接矩阵指定,将一层GCN表示如下:
X
其中X
步骤7:解码阶段;
解码部分的输入经过多头掩码注意力机制和相同结构的编-解码注意力机制,最后经过前馈神经网络层生成最终的回复序列;解码阶段每个子层后同样附加有残差连接和层归一化过程;使用最小化生成序列的负对数似然函数损失来学习模型的参数,得到多轮对话内容生成模型,如下:
其中t
优选地,所述数据集为Audio Visual Scene-Aware Dialog数据集。
本发明的有益效果如下:
本发明基于Transformer架构对视觉情境融合的对话系统进行建模,设计了多步交叉模态注意力机制对视频时空特征、音频、文本模态数据进行跨模态特征融合和交互,提升系统场景感知和定位关键信息的能力,而后使用GCN进行跨模态推理从而获取到细粒度的多模态图表征用于后续解码过程,促使系统生成信息丰富,语义准确的自然对话内容。实验结果表明本发明提出的视频对话模型在各大评估指标上取得了更加先进的性能,能够较好地捕捉到问题的核心,并且能够充分利用和结合多模态上下文信息,关联定位到其他模态中的相关内容,最终生成信息丰富准确,切合情境的对话用以回答问题。
附图说明
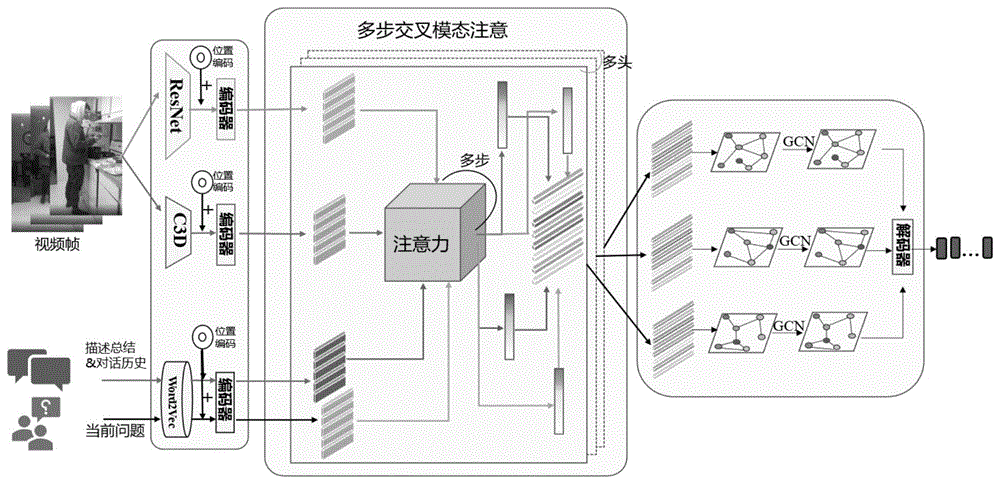
图1为本发明整体模型的系统架构图。
图2为本发明实施例的多模态对话流程图。
具体实施方式
下面结合附图和实施例对本发明进一步说明。
本发明提出一种融合视觉情境的富语义对话生成方法。基于以下原理:融合普适环境下视觉情境信息有助于对话系统深入理解对话上下文信息,进一步实现和谐自然的人机交互:(1)视觉情境内容中蕴含丰富对话语义关联信息,(2)提升智能系统学会自然交互的视听说能力,(3)通过多模态数据的融合和跨模态交互捕捉多角度细粒度渐进式特征交互和模态间语义关联,实现视觉-语言跨模态语义对齐,提升模型语义理解和推理能力,最终生成信息丰富且高质量的回复。
如图1所示,一种融合视觉情境的富语义对话生成方法,包括以下步骤:
步骤1:收集视频对话相关开源数据集,并对数据进行预处理,划分训练集、验证集与测试集,为后续模型的训练提供支持。
步骤2:数据预处理。由于视频内容在时间和空间维度上存在动态变化,不同的时间帧存在不同的空间特征(appearance feature)、相邻时间帧之间存在时空运动特征(motion feature);问题输入单词之间的语义特征(word feature),多轮对话历史间的共指关系与语义依赖特征(history feature),所以一共存在四种类型的多模态特征表示,即视频静态特征、视频动态特征、当前问题特征和历史对话与总结信息拼接的文本特征,需要采取相对应的方法和模型进行特征提取工作,并加入位置编码,如下:
其中PE(pos,2i)代表句子序列中第pos个单词的第2i个维度上的值,PE(pos,2i+1)代表句子序列中第pos个单词的第2i+1个维度上的值;得到最终模型的输入表示。
步骤3:模型构建。(1)首先构建基于编解码(Encoder-Decoder)架构的对话系统,通过对视频中的帧信息使用预训练模型进行特征提取,获取到静态和动态的视频语义信息,然后将其与对话文本内容分别进行编码,并建模细粒度的模态内上下文语义信息。(2)进一步使用基于交叉模态的多步注意力机制进行多模态数据的融合和跨模态交互,捕捉多角度细粒度渐进式特征交互和模态间语义关联,实现视觉-语言跨模态语义对齐,提升模型语义理解和推理能力。(3)最后将多模态特征表示联合构建成时空图结构,基于动态时空场景进行图推理得到跨模态融合特征后,解码生成信息丰富多样且切合情境的对话回复,实现与人类进行自然交互的目标。模型在视听场景感知数据集上与当前最先进的模型相比取得了比肩的效果。
步骤4:编码阶段。对于编码部分,使用4个标准Transformer编码器,对不同模态输入特征进行语义编码,包括视频静态特征,视频动态特征,历史对话与视频摘要特征和当前问题特征。其中,同属文本模态的两类特征所使用的编码器将共享权重。
首先通过多头注意力模块根据上下文对句子序列中的单词向量进行更新,如下:
MultiHead(Q,K,V)=Concat(head
head
其中Q,K,V分别由三个不同的权重矩阵与模型输入向量相乘得到,head
然后经过前馈神经网络层得到编码阶段的输出,如下:
FFN(Z)=max(0,Z,W
其中Z代表多头注意力层的输出内容。
编码阶段中的多头注意力层和前馈神经网络层后都附加有残差连接和层归一化过程,如下:
SubLayer
其中SubLayer指的是多头注意力层或前馈神经网络层。
步骤5:多步交叉模态注意机制。除了通过自注意力机制理解视频内容和问题的自身语义外,还需要挖掘不同模式之间的关系来进行跨模态的语义关联。但单步注意力仅能对部分相关信息进行提取,缺乏对复杂语义理解和答案推断的能力。因此本发明将注意力机制从单步扩展到多步,提出了一种多步交叉模态注意机制,利用多视角和渐进式注意力,使模型能够捕捉到不同模式之间更细粒度的关系,通过关注不同来源的序列之间的内容关联,以实现交叉模态的相互关注。具体来说,在不同的注意力计算中,查询向量依次来源于其中一个模态数据,其余三个模态数据分别用于计算键向量和值向量,以此实现其中一个特征维度与其余三个维度之间的交叉注意。“多步”指对于每一次的注意力机制计算,采用重复两次反复交互的策略,以三组六次的交叉模态注意力计算来捕捉跨模态数据之间的深层次关联,重点定位到不同模态之间的相关信息,帮助后续解码生成信息准确且丰富的回答。多步交叉注意计算的具体更新和操作公式如下。
a
M
其中,a
步骤6:跨模态推理。为了捕捉视频中深层次的动态场景变化信息,本发明采用图卷积网络(Graph Convolutional Network,GCN)进行跨模态推理工作。在先前的特征表示和融合步骤中得到了语言模态和视觉模态的交叉嵌入特征,后续在基础上对该特征构建无向异构图,即一个包含所有视觉和语言向量的异构输入矩阵,在异构图中进行基于图的对齐,得到基于语义相似度加权的跨模态对齐邻接矩阵,进一步使用GCN在图上执行关系推理。具体来说,通过图中相邻节点和自身节点的线性变换进行节点值的更新,图中边的权值由对齐的邻接矩阵指定,为了合并图的输入信号,本发明将一层GCN表示如下:
X
其中X
步骤7:解码阶段。经图推理后得到与当前问题最相关的部分信息用于后续的解码工作,解码部分的输入经过多头掩码注意力机制和相同结构的编-解码注意力机制,最后经过前馈神经网络层生成最终的回复序列。解码阶段每个子层后同样附加有残差连接和层归一化过程。使用最小化生成序列的负对数似然函数损失来学习模型的参数,得到多轮对话内容生成模型,如下:
其中t
具体实施例:
1、如图2所示,收集视频对话相关开源数据集,并对数据进行预处理,划分训练集、验证集与测试集,为后续模型的训练提供支持。以Audio Visual Scene-Aware Dialog(AVSD)数据集为例,将其进行划分为训练集7985轮,验证集1863轮,测试集1968轮,每轮对话包含10个问答对,共包含11816轮对话。
2、数据预处理,针对AVSD数据集中包含的视频和文本内容,进行特征提取得到视频静态特征、视频动态特征、当前问题特征和历史对话与总结信息拼接的文本特征四类特征向量。处理时,首先将每个视频划分为40个片段,每个片段中平均包含18帧,每个片段中采样一帧,每个视频则采样40帧输入到预训练ResNet模型中提取40个帧级别特征表示,提取特征后进行拼接(维度为40*2048)作为最终的视频静态特征V
对于文本模态的两类特征,本发明做统一处理,在这之前首先对所有的文本语料建立词库并进行id编号,其中将频率低于一定数值的词汇进行过滤。为了数据的丰富性,本发明对一组对话数据构建多轮对话对,例如第一轮对话是其本身,无历史信息;第二轮对话的历史信息则是第一轮对话,依次类推。以此方法构造的不同轮次因仍同属一组对话,所以对应的视频信息相同。然后将总结信息与多轮对话历史进行拼接,在词库中进行映射后得到一个单词id序列,进一步使用embedding嵌入层获得512维的词嵌入组成历史特征H,对于问题进行相同的操作获得词级别的问题嵌入Q
H={h
Q
3、编码阶段,模型编码部分采用四个标准transformer模型编码器分别对输入的四类特征进行语义编码,首先通过多头注意力模块根据上下文对四类特征向量进行更新,如下:
MultiHead(Q,K,V)=Concat(head
head
其中Q,K,V分别由三个不同的权重矩阵与模型输入向量相乘得到,head
然后经过前馈神经网络层得到编码阶段的输出,如下:
FFN(Z)=max(0,Z,W
其中Z代表多头注意力层的输出内容。
编码阶段中的多头注意力层和前馈神经网络层后都附加有残差连接和层归一化过程,如下:
SubLayer
其中SubLayer指的是多头注意力层或前馈神经网络层。
4、多步交叉模态注意机制。在完成四类特征自我关注和更新后,使用多步交叉模态注意力机制关注不同来源的序列之间的内容关联,以实现交叉模态的相互关注,如下:
a
M
其中,a
5、跨模态推理。在先前的特征表示和融合步骤中得到了语言模态和视觉模态的四类交叉嵌入特征,后续在基础上对该特征构建无向异构图,即一个包含所有视觉和语言向量的异构输入矩阵,在异构图中进行基于图的对齐,得到基于语义相似度加权的跨模态对齐邻接矩阵,进一步使用GCN在图上执行关系推理。具体来说,通过图中相邻节点和自身节点的线性变换进行节点值的更新,图中边的权值由对齐的邻接矩阵指定,为了合并图的输入信号,本发明将一层GCN表示如下:
X
其中X
6、解码阶段。模型解码部分与编码部分类似,解码阶段的输入同样首先经过词嵌入和是位置编码得到输入向量表示。输入向量经过多头掩码注意力机制进行向量更新,再和经跨模态图推理得到的最终特征表示共同经过相同结构的编-解码注意力机制,最后经过前馈神经网络层得到解码阶段的输出。解码阶段每个子层后同样附加有残差连接和层归一化过程。使用最小化生成序列的负对数似然函数损失来学习模型的参数,得到多轮对话内容生成模型,如下:
其中t
- 一种利用卷积对话生成模型解决对话生成任务的方法
- 基于语义对齐的视觉对话生成系统
- 基于激光雷达和视觉融合的语义点云生成方法和装置