一种基于固定型单目摄像头的多目标行人实时检测定位方法
文献发布时间:2023-06-19 19:28:50
技术领域
本发明涉及人工智能视觉算法及室内定位技术领域,具体涉及一种基于固定型单目摄像头的多目标行人实时检测定位方法。
背景技术
近年来,随着卷积神经网络技术的发展、开源数据集的兴起以及硬件设备计算力的提升,基于卷积神经网络的目标检测算法得到突破性发展。
基于深度学习的一阶段Anchor base方法,其基本原理是将输入图像输入到特征提取网络之中,得到一定大小的特征图,然后将特征图划分成多个网格单元,为每一个网格同时预测边界框并给出相应概率,最后通过非极大值抑制技术去除冗余窗口,从而检测出最终的目标。这种方法将目标检测任务转换成一个回归问题,从而大大加快了检测的速度,但同时会降低检测精度。
目前,国内大型公共交通场景安装有大量摄像头设备,其采集的视觉数据可应用于多种行人识别和态势分析。然而目前基于视觉的行人检测技术大多关注行人的识别和分类,并没有同时对行人进行精确的空间定位。即便是区域入侵、绊线入侵等检测技术,也是基于屏幕坐标系下的行人位置进行判断,而非基于行人真实空间位置,无法应用于基于真实地理位置的可视化GIS平台。
现有基于单目摄像头的行人定位算法,大多需要对目标场景的多个参考点进行提前标定,实施流程复杂,对空间平整度要求高,可行性较低。
发明内容
本发明要解决的技术问题在于:现有通用目标检测技术中摄像头采集的视频数据的检测结果只能标识行人所在区域,无法准确定位行人所在位置;而现有的基于单目摄像头的行人定位技术,又需要对摄像头和场地进行繁杂的标定。本发明提供一种简单实用的基于固定型单目摄像头的多目标行人实时检测定位方法,所需内参易于获得,无需复杂的标定流程,也不需要如双目测距方法进行特征点匹配,算法实时性强,定位精确,环境适应性强。
为实现上述目的,本发明提供了如下技术方案:
一种基于固定型单目摄像头的多目标行人实时检测定位方法,其中,所述基于固定型单目摄像头的多目标行人实时检测定位方法包括:
通过固定型单目摄像头的设备参数,获取摄像头的水平广角、垂直广角,并通过测量获取摄像头的安装高度及世界坐标系下的变换矩阵;
下载行人相关图像,使用标注工具制作标定人体头部的专用数据集,并将此数据集送入深度学习神经网络进行训练,得到一个用于行人头部检测的模型并部署于服务器端;
采集摄像头拍摄的视频图像序列并实时传输至服务器;
通过基于深度学习神经网络的目标检测算法,将图像缩放为固定像素图像,并检测出行人头部,获得头部检测框中心点像素坐标及头部检测框的像素宽度和高度,根据上述信息,计算出检测框在镜头视野中的夹角以及检测框中心点横向偏离镜头光轴的角度;
根据先验知识设定人体头部宽度和高度数值的平方均值,根据上一步骤得出的数据,计算出行人在以摄像头为坐标原点的坐标系下的坐标;
根据上一步计算出的行人坐标和摄像头的世界坐标,通过线性变换计算出行人的世界坐标。
此外,本发明还提供了一种基于固定型单目摄像头的多目标行人实时检测定位系统,其中,所述的基于固定型单目摄像头的多目标行人实时检测定位系统包括:
训练部署模块,用于训练行人头部检测模型,并将所述模型部署于服务器;
数据传输模块,用于将摄像头获取的实时视频数据传输至服务器;
视频推理模块,用于读取摄像头传输至服务器的视频流,并将视频流按帧分解为图像信息,将图像缩放为固定像素,并检测出行人头部,获得头部检测框中心点像素坐标及头部检测框的像素宽度和高度信息;
角度计算模块,用于将所述行人头部检测模型获得的头部检测框中心点像素坐标及头部检测框的像素宽度和高度信息,计算出检测框在镜头视野中的夹角以及检测框中心点横向偏离镜头光轴的角度;
距离计算模块,用于将检测框在镜头视野中的夹角以及检测框中心点横向偏离镜头光轴的角度,结合根据先验知识设定的人体头部宽度和高度数值的平方均值和摄像头的安装高度,计算出行人距摄像头的水平距离,以及行人距摄像头光轴的垂直距离;
坐标计算模块,用于通过所述行人距摄像头的水平距离和行人距摄像头光轴的垂直距离,以及所述摄像头世界坐标系下的变换矩阵,通过线性变换计算出行人在世界坐标系下的坐标。
有益效果
采用本发明提供的技术方案,与已知的公有技术相比,具有如下有益效果:
(1)本发明基于固定型单目摄像头的多目标行人实时检测定位方法,解决了视觉检测任务中对目标进行分类检测的同时,如何获得行人真实空间位置的问题,可应用于多目标轨迹跟踪等领域;
(2)本发明方法实践效果较好,运行速度快,算法鲁棒性好,可适用于多样性高的复杂场景,可以实时、快速、准确的实现对目标行人的定位和跟踪,适用于视频监控、智能小区、特定场所监管等众多领域;
(3)本发明用于实现行人定位的技术路线落地方便,相较于现有的其他定位技术,可直接利用现有摄像头设施,无需额外施工,易于推广普及。
附图说明
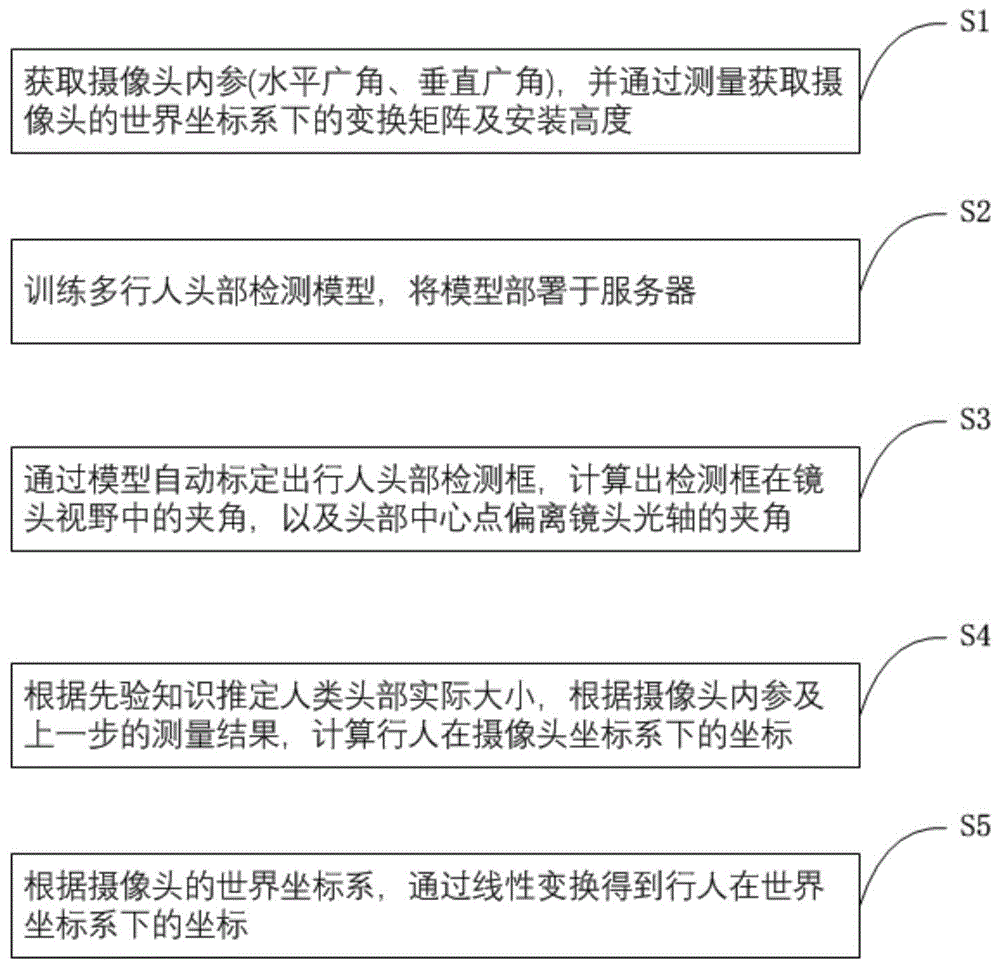
图1是本发明基于固定型单目摄像头的多目标行人实时检测定位方法的流程图;
图2是本发明基于固定型单目摄像头的多目标行人实时检测定位方法的较佳实施例的流程图;
图3是本发明基于固定型单目摄像头的多目标行人实时检测定位方法的较佳实施例中步骤S4的角度计算方法示意图;
图4是本发明基于固定型单目摄像头的多目标行人实时检测定位方法的较佳实施例中步骤S5和步骤S6的行人坐标计算示意图。
具体实施方式
为使本发明实施例的目的、技术方案和优点更加清楚,下面将对本发明实施例中的技术方案进行清楚、完整地描述。显然,所描述的实施例是本发明一部分实施例,而不是全部的实施例。基于本发明中的实施例,本领域普通技术人员在没有作出创造性劳动前提下所获得的所有其他实施例,都属于本发明保护的范围。
下面结合实施例对本发明作进一步的描述。
实施例:
本发明提供了一种基于固定型单目摄像头的多目标行人实时检测定位方法。
如图1-2所示,根据本发明实施例的基于固定型单目摄像头的多目标行人实时检测定位方法,包括以下步骤:
步骤S1,通过固定型单目摄像头的设备参数,获取摄像头的水平广角A、垂直广角B,并通过测量获取摄像头的安装高度H及世界坐标系下的变换矩阵P;
步骤S2,下载行人相关图像,使用标注工具制作标定人体头部的专用数据集,并将此数据集送入深度学习神经网络进行训练,得到一个用于行人头部检测的模型并部署于服务器端;
步骤S3,采集摄像头拍摄的视频图像序列并实施传输至服务器;
步骤S4,通过基于深度学习神经网络的目标检测算法,将图像缩放为固定像素(M*N)图像,并检测出行人头部,获得头部检测框中心点像素坐标(x,y)及头部检测框的像素宽度和高度(w,h),根据上述信息,计算出检测框在镜头视野中的夹角β以及检测框中心点横向偏离镜头光轴的角度α;
具体的,如图3所示,所述的检测框在镜头视野中的夹角β以及检测框中心点横向偏离镜头光轴的角度α的计算方法如式(1):
α=arctan(x*tan(A)/M)(1)
所述的检测框在镜头视野中的夹角β的计算方法如式(2):
由于人体头部所占像素比例通常只占画面中极小部分,式(2)采用了近似算法,并取人体头部检测框的宽和高的平方均值进行计算,以消除不同人体头型及姿势带来的误差。
步骤S5,根据先验知识设定人体头部宽度和高度数值的平方均值为f=0.225米,根据上一步骤得出的数据,计算出行人距离摄像头的直线距离R;
具体的,如图4所示,所述的行人距离摄像头的直线距离R的计算方法如式(3);
R≈f/β(3)
步骤S6,根据先验知识,设定行人头部距离地面的平均高度为d=1.5米,并根据步骤S5中计算得到的行人距离摄像头的直线距离R,和摄像头的安装高度H,计算出行人在以摄像头为坐标原点的坐标系下的坐标P
具体的,如图4所示,所述的行人在以摄像头为坐标原点的坐标P
在式(4)中,安装高度H存在测量误差,并且行人头部距离地面的高度d也会由于个体不同存在误差,令σ=H-d,可求得式
由式(5)可见在R远大于σ时,由σ所带来的误差会被稀释到极小的程度。
步骤S7,根据步骤S6中计算出的行人坐标和摄像头的世界坐标,通过线性变换计算出行人的世界坐标P
具体的,所述的行人在以摄像头为坐标原点的坐标系下的坐标P
P
其中,P为摄像头坐标系在世界坐标系下的变换矩阵。
综上所述,本发明提供一种基于固定型单目摄像头的多目标行人实时检测定位方法,所述方法包括:通过固定型单目摄像头的设备参数,获取摄像头的水平广角、垂直广角,并通过测量获取摄像头的安装高度及世界坐标系下的平面坐标;下载行人相关图像,使用标注工具制作标定人体头部的专用数据集,并将此数据集送入深度学习神经网络进行训练,得到一个用于行人头部检测的模型并部署于服务器端;采集摄像头拍摄的视频图像序列并实施传输至服务器;通过基于深度学习神经网络的目标检测算法,将图像缩放为固定像素图像,并检测出行人头部,获得头部检测框中心点像素坐标及头部检测框的像素宽度和高度,根据上述信息,计算出检测框在镜头视野中的夹角以及检测框中心点横向偏离镜头光轴的角度;根据先验知识设定人体头部宽度和高度数值的平方均值,根据上一步骤得出的数据,计算出行人在以摄像头为坐标原点的坐标系下的坐标;根据上一步计算出的行人坐标和摄像头坐标系在世界坐标系下的变换矩阵,通过线性变换计算出行人的世界坐标。
以上实施例仅用以说明本发明的技术方案,而非对其限制;尽管参照前述实施例对本发明进行了详细的说明,本领域的普通技术人员应当理解:其依然可以对前述各实施例所记载的技术方案进行修改,或者对其中部分技术特征进行等同替换;而这些修改或者替换,并不会使相应技术方案的本质脱离本发明各实施例技术方案的精神和范围。