用于产生逼真图像的生成器的训练方法
文献发布时间:2023-06-19 19:28:50
技术领域
本发明涉及对逼真图像的生成器的训练,所述逼真图像又可用于训练图像分类器。
背景技术
人类驾驶员在道路交通中驾驶车辆所需的信息中,大约90%是视觉信息。因此,对于车辆的至少部分自动化驾驶来说,重要的是正确地评估在监视车辆环境期间所记录的图像数据的内容,而不管是什么模态的图像数据。对于驾驶任务特别重要的是对图像数据进行分类,以确定所述图像数据中包含哪些交通相关的对象,例如其他交通参与者、车道标记、障碍物和交通标志。
对应的图像分类器必须使用在大量交通状况下记录的训练图像加以训练。训练图像的获取相对困难且昂贵。现实中很少发生的交通状况在具有训练图像的数据集中可能在数量上未能得到充分代表,从而图像分类器无法最佳地学习如何正确地对这些交通状况进行分类。此外,需要大量手动工作来使用相关联的目标类别分配(“地面实况”)“标记”训练图像或其像素。
因此,还使用了利用基于生成对抗网络(GAN)的生成器产生的综合产生的训练数据。这种雷达数据的生成器由DE 10 2018 204 494 B3已知。
发明内容
在本发明的范围中开发了一种用于训练图像的生成器的方法。
术语“图像”不限于静态相机图像,而是例如还包括视频图像、雷达图像、激光雷达图像和超声图像。
待产生的图像可以是逼真的,特别是例如在预给定的应用方面。在此情况下,“逼真”可以特别是意味着可以按照与用物理传感器记录的图像相同的方式将图像用于下游处理,例如在训练图像分类器时。逼真产生的图像可以特别是例如用于丰富用传感器记录并且然后为图像分类器“标记”的真实训练图像的存储库。因此,为了更好的可读性,待产生的图像在下文中称为“逼真图像”或“逼真产生的图像”。
所述生成器从语义图中产生逼真图像。该语义图向待产生的逼真图像的每个像素分配该像素所属对象的语义含义。因此,不是产生任何随机的逼真图像,而是产生反映语义图中预给定状况的逼真图像。从而例如所述语义图可以表示具有不同车道、车道边界、交通标志、交通参与者和另外的对象的交通状况。
针对该方法提供真实训练图像和相关联的语义训练图,所述语义训练图向相应训练图像的每个像素分配语义含义。因此,对于每个真实训练图像都存在语义训练图。相反,对于每个语义训练图都存在至少一个真实训练图像,因为例如可能已经使用不同曝光或其他成像参数记录了语义相同的状况。例如可以通过对真实训练图像进行手动标记来获得语义训练图。
使用待训练的生成器,从至少一个语义训练图中产生逼真图像。针对相同的至少一个语义训练图确定至少一个真实训练图像。为了训练生成器,使用鉴别器,所述鉴别器被构造为将生成器所产生的逼真图像与通过语义训练图预给定的场景的真实图像区分开来。
从生成器所产生的至少一个逼真图像和针对相同语义训练图确定的至少一个真实训练图像中产生混合图像。在该混合图像中,第一真实像素子集被生成器所产生的逼真图像的分别对应的像素值占据。其余的真实像素子集被真实训练图像的分别对应的像素值占据。因此,混合图像的每个像素都被生成器所产生的逼真图像的对应像素值或真实训练图像的对应像素值占据。
在此,特别是例如混合图像的像素的以下连续区域可以统一被生成器所产生的逼真图像的对应像素值或统一被真实训练图像的对应像素值占据,所述连续区域由所述语义训练图分配了相同的含义。因此,所述混合图像于是可以是例如一方面由生成器所产生的逼真图像中的对象表示和另一方面真实训练图像中的对象表示的“拼贴”。
将生成器所产生的逼真图像、至少一个真实训练图像以及至少一个混合图像输送到所述鉴别器。对表征生成器行为的生成器参数进行优化,目标是将生成器所产生的逼真图像由鉴别器错误分类为真实图像。
同时或交替地,对表征鉴别器行为的鉴别器参数进行优化,目标是在区分逼真产生的图像和真实图像时提高准确性。因此,所述鉴别器被训练为将逼真产生的图像分类为逼真产生的图像并且将真实训练图像分类为真实训练图像。
混合图像在该训练中应当扮演什么角色,即鉴别器应当输出哪个类别分配来响应混合图像,是该训练的可调整的自由度。这里存在多个动机良好的可能性。
例如可能期望的是,所述鉴别器将主要包含从逼真产生的图像中提取的像素和/或对象的混合图像分类为逼真产生的图像。同样例如可能期望的是,所述鉴别器将主要包含从真实训练图像中提取的像素和/或对象的混合图像分类为真实图像。中间还可以任意分级。因此可以将鉴别器的参数优化为,使得所述鉴别器响应于所述混合图像输出分别期望的目标分配。
在此还可以任意分级。例如,可以对鉴别器参数附加地进行优化,目标是将所述混合图像在一定程度上分类为真实图像,该程度对应于从真实训练图像接管到混合图像中的像素和/或对象的数量比例。因此,如果例如混合图像的60%的图像内容是从真实训练图像接管的,而该混合图像的40%的图像内容是从逼真产生的图像接管的,则可能期望的是鉴别器以0.6的分数将混合图像分类为真实图像,以0.4的分数将混合图像分类为逼真产生的图像。
已经认识到,添加混合图像来训练鉴别器具有双重效果。一方面,可以通过这种方式对训练进行正则化,从而使鉴别器更好地学习逼真产生的图像与真实图像之间在内容和结构上的差异。另一方面,可以通过产生大量混合图像来类似地增加训练图像的现有存储库。即使仅将一个真实训练图像与一个逼真产生的图像组合,也存在大量选项可以将混合图像组装为来自两个图像的对象的“拼贴”。
特别地,例如可以选择PatchGAN鉴别器作为鉴别器。这种鉴别器确定在图像的具有预给定大小(“块”)的子区域处是存在逼真产生的图像还是存在真实图像的区别。然后将在此过程中分别获得的结果组合成总结果。这种鉴别器特别能够定量检测混合图像中真实的图像内容与逼真产生的图像内容的混合比。
所述鉴别器例如也可以具有编码器-解码器装置,其具有编码器结构和解码器结构。编码器结构将输入图像在多个处理层中转换为信息减少的表示。解码器结构进一步将所述信息减少的表示转换为将输入图像的每个像素评估为真实像素或逼真产生的像素的评估。因此,这种鉴别器的输出不仅仅是对输入图像进行整体评估的分数。取而代之的是,所述评估是空间分辨的,因此也可以详细检测混合图像的哪些像素或对象来自真实图像以及混合图像的哪些像素或对象来自逼真产生的图像。
在另一有利的设计中,所述鉴别器在编码器结构的处理层和解码器结构的处理层之间具有至少一个直接连接,以绕过所述信息减少的表示。于是可以将来自编码器结构的信息的特别相关部分选择性地传输到解码器结构中,而不必经过最大信息减少的表示的“瓶颈”。由此鉴别器获得了“U-Net”架构。
在另一特别有利的设计中,所述鉴别器附加地被训练为使得其从根据预给定规则从真实训练图像和逼真产生的图像中确定的混合图像中产生空间分辨的输出,所述空间分辨的输出根据相同的预给定规则尽可能接近于一方面为真实训练图像获得的输出而另一方面为逼真产生的图像获得的输出的混合。于是鉴别器在将图像混合为混合图像的情况下是等效的。
这通过以下示例来说明,在该示例中根据语义图的场景在图像的左上角具有车辆,而在该图像的右下角具有树。所述预给定规则指出,混合图像应当将从逼真产生的图像中提取的车辆与从真实训练图像中提取的树组合起来。因此,由鉴别器为所述混合图像确定的空间分辨的输出会将具有车辆的区域分类为逼真产生的图像部分,将具有树的区域分类为真实图像部分。
当鉴别器应用于真实图像时,该鉴别器的空间分辨的输出应当将该真实图像完全分类为真实图像。当鉴别器应用于逼真产生的图像时,该鉴别器的空间分辨的输出应当将该逼真产生的图像完全分类为逼真产生的图像。如果这两个空间分辨的输出现在以与混合图像相同的方式组合,则结果应当是左上角被分类为真实图像部分,而右下角被分类为逼真产生的图像部分。这是在首先形成混合图像然后确定空间分辨的输出时也获得的结果。
例如,可以扩展鉴别器的成本函数(损失函数)以包括以下形式的一致性项L
这里D是鉴别器的空间分辨的输出,M表示对应于预给定规则进行的组合操作。x是真实图像,
一致性项L
通过这里描述的正则化,鉴别器需要注意自然的语义类别边界。因此,产生的图像不仅在单个像素层面上是逼真的,而且还考虑了根据语义图分别具有分配给不同对象类型的图像区域的形状。
空间分辨的输出可以特别是包括例如来自鉴别器的神经网络最后一层的输出,从中产生输入图像是真实图像还是逼真图像的分类并且得出两种分类的概率。最后一层特别是可以包含例如“多元逻辑(logit)”,即尚未使用Softmax函数标准化的分类分数。
如上所述,这里描述的训练方法的一个重要应用是扩大图像分类器的训练数据集,从而从具有真实训练图像和相关联的向语义含义的目标分配的预给定训练数据集出发整体上更好地训练图像分类器。因此,本发明还涉及一种用于训练图像分类器的方法,所述图像分类器将语义含义分配给输入图像和/或所述输入图像的像素。
在该方法中,根据上述方法训练生成器。使用经过训练的生成器可以从语义图中产生逼真图像。于是这些语义图不再局限于曾用于训练生成器的语义图,而是可以描述任何期望的场景。
从语义图中确定语义目标含义,经过训练的图像分类器应当分别将逼真图像映射到所述语义目标含义。目标含义特别是可以包括例如属于预给定分类的一个或多个类别的所属性。例如,如果在语义图中的特定位置绘制了车辆,则逼真产生的图像将在该位置包含车辆。因此,图像分类器至少应当将该图像区域分配给“车辆”类别。
扩展图像分类器的包含真实训练图像和相关联的语义目标含义的训练数据集以包括逼真产生的图像和相关联的语义目标含义。使用经过扩展的训练数据集来训练所述图像分类器。
如上所述,可以通过这种方式丰富训练数据集,特别是增加以前在所述训练数据集中代表性不足的状况的逼真图像。通过这种方式,图像分类器就可以更好地处理这些状况。
例如,罕见但危险的交通状况的训练图像通常很难获得。例如,作为所述状况的重要组成部分的雾、极端降雪或冻雨可能很少出现。所述状况的其他部分,例如碰撞过程中的两个车辆,可能太危险而无法用真实车辆复制。
因此,本发明还涉及另一种方法。在这种方法中,如前所述使用由经过训练的生成器产生的逼真图像来训练图像分类器。使用这种经过训练的图像分类器,向使用车辆携带的至少一个传感器记录的图像分配语义含义。从图像分类器所确定的语义含义中确定操控信号。用所述操控信号来控制所述车辆。
通过改进的训练,有利地改进了图像分类器所提供的语义含义的准确性。因此,有利地提高了由所述操控信号触发的车辆反应适合于图像中所显示的交通状况的概率。
这些方法特别是可以完全或部分地由计算机实现。因此,本发明还涉及一种具有机器可读指令的计算机程序,所述机器可读指令当在一个或多个计算机上执行时促使所述一个或多个计算机执行所描述的方法之一。从这个意义上说,同样能够执行机器可读指令的车辆控制设备和技术设备的嵌入式系统也应被视为计算机。
本发明还涉及具有所述计算机程序的机器可读数据载体和/或下载产品。下载产品是可经由数据网络传输的数字产品,即可由所述数据网络的用户下载,所述数字产品例如可以在在线商店中销售以供立即下载。
此外,计算机可以配备有所述计算机程序、所述机器可读数据载体或所述下载产品。
下面与基于附图对本发明优选实施例的描述一起更详细地呈现改进本发明的进一步措施。
附图说明
图1示出了用于训练生成器1的方法100的实施例;
图2示出了混合图像6的形成的图示;
图3示出了用于训练图像分类器9的方法200的实施例;
图4示出了方法300的实施例,具有直到车辆50的操控的完整效果链。
具体实施方式
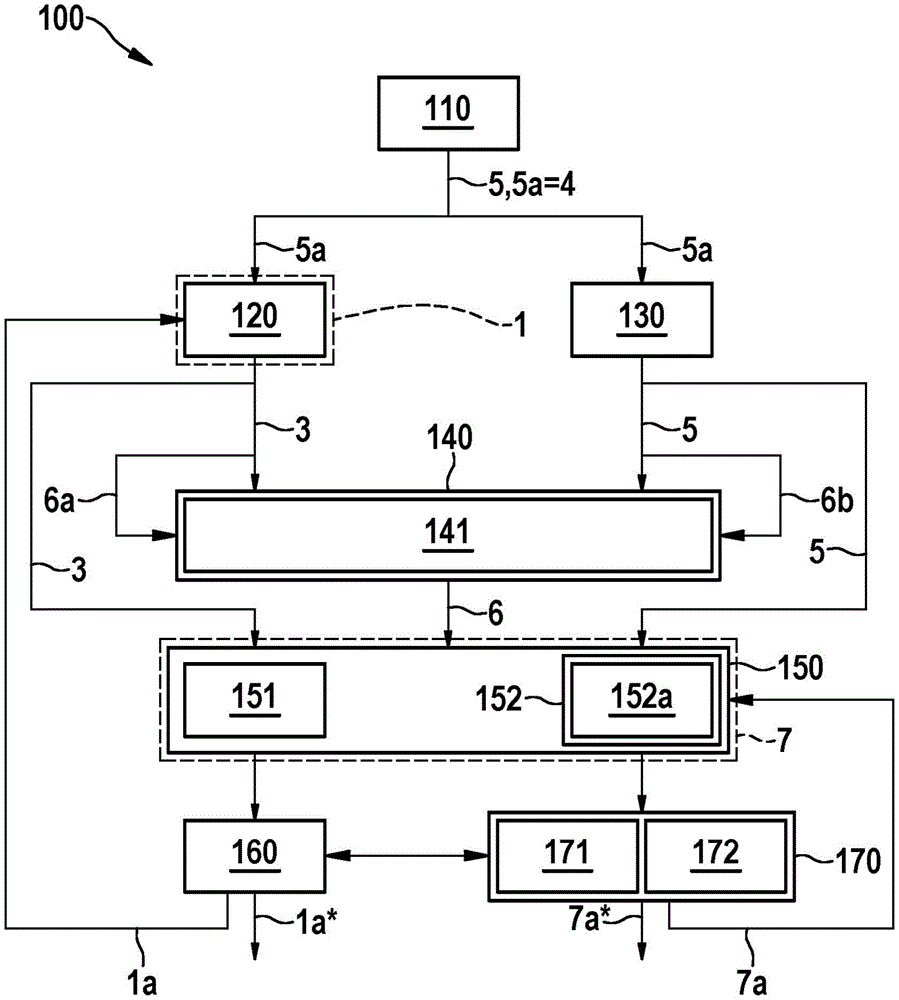
图1是方法100的实施例的示意性流程图。在步骤110中,提供真实训练图像5和相关联的语义训练图5a。语义训练图5a向相应训练图像5的每个像素分配语义含义4。
在步骤120中,使用待训练的生成器1从至少一个语义训练图5a中产生逼真图像3。在步骤130中,为相同的至少一个语义训练图5a确定至少一个真实训练图像5。这可以例如是通过其“标记”而首先创建了语义训练图5a的训练图像5。
在步骤140中,从生成器1所产生的至少一个逼真图像3和在步骤130中确定的至少一个真实训练图像5中产生混合图像6。在该混合图像6中,第一真实像素子集6a被生成器1所产生的逼真图像3的分别对应的像素值占据。其余的真实像素子集6b被真实训练图像5的分别对应的像素值占据。
根据块141,混合图像6的像素的以下连续区域61、62可以统一被生成器1所产生的逼真图像3的对应像素值或统一被真实训练图像5的对应像素值占据,所述连续区域由语义训练图5a分配了相同的语义含义4。
混合图像6的形成在图2中详细说明。
在步骤150中,将生成器1所产生的逼真图像3、至少一个真实训练图像5和至少一个混合图像6输送给鉴别器7,这些图像全都属于相同的语义训练图5a。鉴别器7被构造为将生成器1所产生的逼真图像3与通过语义训练图5a预给定的场景的真实图像5区分开来。鉴别器7仅在训练时需要。在稍后使用完成训练的生成器1时,不再需要鉴别器7。
根据块151,可以选择PatchGAN鉴别器作为鉴别器7。PatchGAN鉴别器确定逼真产生的图像3与真实图像5之间在图像3、5、6的具有预给定大小的子区域处的区别,并且将在此过程中分别获得的结果组合成总结果。
根据块152,可以选择具有编码器-解码器装置的鉴别器7。该编码器-解码器装置中的编码器结构将输入图像在多个连续的处理层中转换为信息减少的表示。该编码器-解码器装置中的解码器结构进一步将所述信息减少的表示转换为将输入图像的每个像素评估为真实像素或逼真产生的像素的评估。根据块152a,可以特别是例如在鉴别器7中设置编码器结构的处理层与解码器结构的处理层之间的至少一个直接连接,以绕过所述信息减少的表示。
在步骤160中,对表征生成器1行为的生成器参数1a进行优化,目标是将生成器1所产生的逼真图像3由鉴别器7错误分类为真实图像5。同时或替换地,在步骤170中,对表征鉴别器7行为的鉴别器参数7a进行优化,目标是在区分逼真产生的图像3和真实图像5时提高准确性。
在此,根据块171可以对鉴别器参数7a附加地进行优化,目标是将混合图像6在一定程度上(即例如具有分数)分类为真实图像5,该程度对应于从真实训练图像5接管到混合图像6中的像素和/或对象的数量比例。
根据块172,鉴别器7可以附加地被训练为使得其从根据预给定规则从真实训练图像5和逼真产生的图像3中确定的混合图像6中产生空间分辨的输出,所述空间分辨的输出根据相同的预给定规则尽可能接近于一方面为真实训练图像5获得的输出而另一方面为逼真产生的图像3获得的输出的混合。
生成器参数la的完成训练的状态用附图标记la*表示。鉴别器参数7a的完成训练的状态用附图标记7a*表示。
图2以一个简单的示例说明了混合图像6是如何形成的。在该示例中预给定了语义图2。该语义图2向第一区域21分配以下语义含义4,即所使用的图像3、5应当在那里显示书。语义图2向第二区域22分配以下语义含义4,即所使用的图像3、5应当在那里显示桌子。
与语义图2一致地,用生成器1产生的逼真图像3显示了桌子32,书31位于该桌子上。真实训练图像5显示了另一张桌子52,另一本书51位于该另一张桌子上。
在混合图像6中,形成连续区域61的像素6a被生成器1所产生的逼真图像3的对应像素值占据,所述对应像素值涉及桌子32。形成连续区域62的像素6b被真实训练图像5的涉及书51的对应像素值占据。因此,混合图像6是生成器1所产生的逼真图像3中的桌子32和真实训练图像5中的书51的拼贴。
图3是用于训练图像分类器9的方法200的实施例的示意性流程图。在步骤210中,使用上述方法100来训练生成器1。在步骤220中,使用经过训练的生成器1从语义图2中产生逼真图像3。在步骤230中,从分别使用的语义图2中确定语义目标含义,图像分类器9应当将逼真图像3或其像素分别映射到所述语义目标含义。
在步骤240中,将生成器1所产生的逼真图像3和相关联的目标含义4添加到训练数据集9a,所述训练数据集已经包含真实训练图像5′和相关联的目标含义4′。在步骤250中将以这种方式扩展的训练数据集9a*用于训练图像分类器9。
图4是方法300的实施例的示意性流程图。在步骤310中,使用上述方法200来训练图像分类器9。使用该图像分类器9,在步骤320中向使用车辆50携带的至少一个传感器50a记录的图像5分配语义含义4。在步骤330中,从图像分类器9所确定的语义含义4中确定操控信号330a。在步骤340中,使用操控信号330a来操控车辆50。