基于肺部CT与5mC标志物融合的肺结节分类方法及产品
文献发布时间:2023-06-19 19:28:50
技术领域
本发明涉及医疗影像处理技术、基因甲基化标志物检测技术与人工智能技术,特别涉及一种基于肺部CT与5mC标志物融合的肺结节分类方法及产品。
背景技术
肺癌是所有恶性肿瘤中最常见最致命的一种。早期肺癌检出率低于25%,但是早期肺癌5年生存率达到70%,不过由于肺癌的早期特征不明显,采用影像学手段(如低剂量CT),存在假阳性率过高的问题,只有通过定期随访比较肺结节的外部特征和内部特征,才能够提高准确率;但是,CT 检查毕竟含有一定量的辐射,高频率多次的检查可能会对身体造成额外的损伤。
由于肿瘤细胞会主动(分泌)或被动(细胞凋亡或坏死)地将核酸分子释放到血液中,即循环肿瘤 DNA (circulating tumor DNA, ctDNA)。由于ctDNA 能更全面地反映肿瘤细胞的全局;所以,近年来,基于血液的液态活检逐渐成为癌症早筛和早诊的一种重要手段;同时,已有很多研究指出,DNA 甲基化与癌症的发生密切相关,将DNA甲基化相关的生物标志物用于癌症的早期筛查和诊断具有较好的前景,但目前尚缺乏高灵敏度和特异性的肿瘤标志物。
随着人工智能的广泛应用,利用人工智能技术辅助临床高效且准确鉴别肺结节,能够很大程度地降低临床医生的工作强度,并改善漏诊和误诊情况。然而目前,单维度的肺结节良恶性分类模型的灵敏度和准确率很难显著提高,比如基于CT影像的肺结节良恶性分类方法,主要通过不同的分类模型和不同的特征提取方式的改进,来提高分类灵敏度和准确率;比如基于影像组学和生物组学的肺结节良恶性分类模型已被认为是进一步提高分类灵敏度和准确率的有力手段,但仍处于研究探索阶段。
发明内容
本发明实施例中提供了一种基于肺部CT与5mC标志物融合的肺结节分类方法,能够结合基于肺部CT影像而获得的影像特征与基于5mC(5-methylcytosine,即5-甲基胞嘧啶)测序结果而获得的标志物特征共同作用于肺结节分类预测,可提高肺结节分类预测准确率。
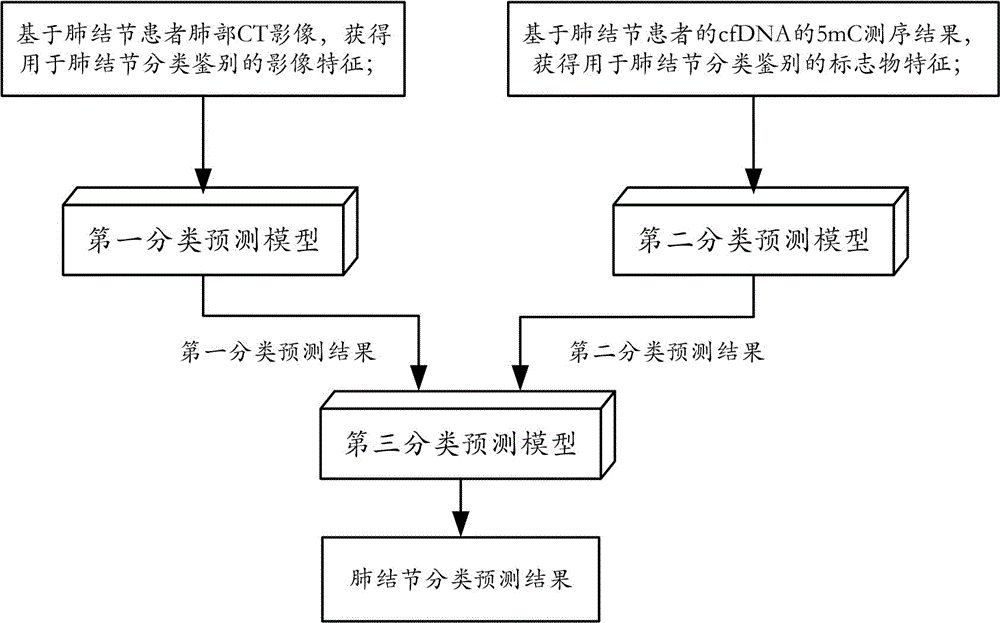
本发明的第一方面,提供一种基于肺部CT与5mC标志物融合的肺结节分类方法,该方法包括以下步骤:
基于肺结节患者肺部CT影像而获得用于肺结节分类鉴别的影像特征,并将所述影像特征输入第一分类预测模型,得到第一分类预测结果;
基于所述肺结节患者的血浆cfDNA(circulating free DNA或循环游离DNA)的5mC测序结果而获得用于肺结节分类鉴别的标志物特征,并将所述标志物特征输入第二分类预测模型,得到第二分类预测结果;
将所述第一分类预测结果和所述第二分类预测结果输入至第三分类预测模型,得到肺结节分类预测结果。
在一些可能的实施例中,基于肺结节患者肺部CT影像而获得用于肺结节分类鉴别的影像特征包括以下步骤:
S1:基于肺部CT影像中肺结节的完整空间信息,生成用于包含对应肺结节的完整空间信息的正方体空间;
S2:将所述正方体空间切分为若干个同等大小的正方体子空间,并获取经过每个所述正方体子空间中心的横切面、纵切面以及矢状切面;
S3:对所述正方体空间内各个所述正方体子空间对应的横切面、纵切面以及矢状切面进行向量化,得到具有连贯性的浅特征;
S4:将所述浅特征输入至具有至少一个注意力池化模块的第一神经网络进行特征提取,得到用于肺结节分类鉴别的影像特征。
在本实施例中,通过将肺部CT影像中每个肺结节的完整空间信息进行分块处理,并将肺结节的各个分块的不同切面信息进行向量化,再利用具有注意力机制的池化模块的神经网络进行特征提取,从而提取到更多具有代表性的用于肺结节分类鉴别的影像特征,应用在第一分类预测模型的训练过程中能够增强学习到信息的有效性,并降低模型的训练难度。
在一些可能的实施例中,基于所述肺结节患者的血浆cfDNA的5mC测序结果而获得用于肺结节分类鉴别的标志物特征包括以下步骤:
基于所述肺结节患者的血浆cfDNA的5mC测序结果,获得被选定作为5mC标志物的多个标志物的测序信号的峰值信息;
基于所述多个标志物的测序信号的峰值信息,对所述多个标志物的测序信号峰值位置进行读段计数;
根据每个标志物的测序信号峰值位置的读段数值,构建出作为所述标志物特征的多维向量。
进一步地,选定作为5mC标志物的多个标志物包括以下步骤:
基于多个良性肺结节样本和多个恶性肺结节样本的血浆cfDNA的5mC测序结果,生成对应BED文件;
对所述BED文件执行Callpeak命令,获取每个样本的测序信号的Peak信息,并生成每个样本对应的测序信号峰值位置集合;
对每个样本的测序信号峰值位置集合进行去重处理,使测序信号峰值位置集合内的测序信号峰值位置无重叠;
合并所有样本的测序信号峰值位置集合,得到第一测序信号峰值位置集合,并对所述第一测序信号峰值位置集合进行去重处理,得到第二测序信号峰值位置集合;
筛除所述第二测序信号峰值位置集合中与全部良性肺结节样本或全部恶性肺结节样本对应的样本测序信号峰值集合存在交集的比例未达到设定阈值的测序信号峰值位置,得到第三测序信号峰值集合;
对所述第三测序信号峰值集合中的测序信号峰值位置进行读段计数,并对测序信号峰值位置的读段数值进行标准化后,对每个测序信号峰值位置的读数数量进行秩和检验,得到每个测序信号峰值位置的q-value;
基于q-value 排名靠前多个的测序信号峰值位置构建第四测序信号峰值集合,并以所述第四测序信号峰值集合中各个测序信号峰值位置的读段数值为自变量,以肺结节的良性或恶性为因变量,筛选出所有与因变量具有相关性的测序信号峰值位置作为5mC标志物。
在本实施例中,通过选定高灵敏度和特异性的标志物,能够提高第二分类预测模型的肺结节分类预测准确率。
如此,本发明结合基于肺部CT影像而获得的影像特征与基于5mC测序结果而获得的标志物特征共同作用于肺结节分类预测,可提高肺结节分类预测准确率。
本发明的第二方面,提供一种肺结节分类装置,其包括:
一个或多个处理器;以及,用于存储可执行指令的存储器;
所述一个或多个处理器,用于从所述存储器中读取所述可执行指令,并执行所述可执行指令以实现本发明的第一方面提供的基于肺部CT与5mC标志物融合的肺结节分类方法。
本发明的第三方面,提供一种计算机可读介质,其上存储有计算机程序,该计算机程序被一个或多个处理器执行时实现本发明第一方面提供的基于肺部CT与5mC标志物融合的肺结节分类方法。
附图说明
图1为本发明实施例提供的肺结节分类方法的流程示意图;
图2为本发明实施例提供的获取影像特征的流程示意图;
图3为本发明实施例提供的获得第一分类预测结果的工作过程的示意图;
图4为本发明实施例提供的第一神经网络的工作过程的示意图;
图5为本发明实施例提供的第一神经网络进行特征提取的流程示意图;
图6为本发明实施例提供的Transformer模块的工作流程示意图;
图7为本发明实施例提供的获取标志物特征的流程示意图;
图8为本发明实施例提供的n个样本的测序信号峰值位置示意图;
图9为本发明实施例提供的第一分类预测模型、第二分类预测模型以及第三分类预测模型在220例独立验证集的ROC曲线的对比图;
图10为本发明实施例提供的肺结节分类装置的结构示意图。
具体实施方式
下面结合附图及具体实施例对本发明作进一步的详细描述。但不应将此理解为本发明上述主题的范围仅限于以下的实施例,凡基于本发明内容所实现的技术均属于本发明的范围。
如图1所示,本发明实施例提供的基于肺部CT与5mC标志物融合的肺结节分类方法,包括以下步骤:
基于肺结节患者肺部CT影像而获得用于肺结节分类鉴别的影像特征,并将所述影像特征输入第一分类预测模型,得到第一分类预测结果;
基于所述肺结节患者的血浆cfDNA的5mC测序结果而获得用于肺结节分类鉴别的标志物特征,并将所述标志物特征输入第二分类预测模型,得到第二分类预测结果;
将所述第一分类预测结果和所述第二分类预测结果输入至第三分类预测模型,得到肺结节分类预测结果。
具体的,如图2和3所示,本发明实施例中基于肺结节患者肺部CT影像而获得用于肺结节分类鉴别的影像特征包括以下步骤:
S1:基于肺部CT影像中肺结节的完整空间信息,生成用于包含对应肺结节的完整空间信息的正方体空间;具体的,在步骤S1中,需要通过计算机断层扫描技术获取病患的肺部CT影像,再由放射科医师浏览肺部CT影像并操作软件标记出肺部CT影像内的肺结节,生成该肺部CT影像的标记文件,通过读取该肺部CT影像的标记文件,即可得到该肺部CT影像中肺结节的完整空间信息;然后,通过块状化处理,将肺结节的区域通过标注坐标定位在统一大小的正方体空间内,如此可以保证信息处理的维度一致性。
S2:将所述正方体空间切分为若干个同等大小的正方体子空间,并获取经过每个所述正方体子空间中心的横切面、纵切面以及矢状切面;具体的,由于包含肺结节的完整空间信息的正方体空间相当于是一个空间实体,通过切块处理,将该正方体空间切分成多个正方体子空间后,使每个正方体子空间内都具有部分肺结节的三维空间信息,再通过切面处理,将每个正方体子空间具有的部分肺结节的三维空间信息转换为二维信息。
S3:对所述正方体空间内各个所述正方体子空间对应的横切面、纵切面以及矢状切面进行向量化,得到具有连贯性的浅特征;具体的,在步骤S3中,采用第二神经网络对所述正方体空间内各个所述正方体子空间对应的横切面、纵切面以及矢状切面进行向量化;其中,所述浅特征的表达式为:
S4:将所述浅特征输入至具有至少一个注意力池化模块的第一神经网络进行特征提取,得到用于肺结节分类鉴别的影像特征。具体的,注意力池化模块是在池化模块中引入了注意力机制,能够避免直接平局池化处理而造成信息丢失。
在实施时,如图4所示,第一神经网络100的架构包括:第一注意力池化模块101、多层感知机102、第二注意力池化模块103以及Transformer模块104。进一步地,如图5所示,第一神经网络100进行特征提取包括以下步骤:
S401:将浅特征输入至第一注意力池化模块进行注意力池化操作,而得到第一状态浅特征;
S402:将所述第一状态浅特征输入至多层感知机对进行特征映射,而得到第二状态浅特征;
S403:将所述第二状态浅特征输入至第二注意力池化模块进行注意力池化操作,而得到第三状态浅特征;
S404:将所述第三状态浅特征输入至Transformer模块进行特征提取,得到用于肺结节分类鉴别的影像特征。
其中,第一注意力池化模块和第二注意力池化模块可根据实际应用需求配置包括多个基于注意力机制的池化层;而且,注意力池化操作包括:计算输入的特征中每个特征向量的注意力得分,并将输入的特征中每个特征向量与其注意力的乘积求和,得到输出的特征。其中,注意力池化操作通过以下公式表达:
如图6所示,在步骤S404中,所述Transformer模块进行特征提取的方式为:对输入的所述第三状态浅特征分别进行Patch Embedding和Position Embedding,并将经PatchEmbedding和Position Embedding处理的结果相叠加后输入至Transformer Encoder,得到用于肺结节分类鉴别的特征。
在第一神经网络进行特征提取之前,在三维层面,通过将包含肺结节的完整空间信息的正方体切分为若干个同等大小的正方体子空间,丰富肺结节的特征信息,但也会使具有相关性的正方体子空间之间产生一定空间距离;在二维层面,通过在每个正方体子空间的基础上进行切面,获取经过每个正方体子空间中心的横切面、纵切面以及矢状切面,进一步丰富肺结节的特征信息,同样也会进一步扩大具有相关性的切面特征的距离;那么,所述正方体空间内各个正方体子空间对应的横切面、纵切面以及矢状切面进行向量化后获得的浅特征,其在不同位置的特征信息也必然有关联性。
由于Transformer模块的基础单元是attention神经元,由于attention神经元的特点在于:能够无视两个特征点在空间上的距离长短而计算它们相互之间的关联性。因此,采用Transformer模块对浅特征进行提取,能够观察到不同位置的特征信息的关联性,进而提取出更多具有代表性的用于肺结节分类鉴别的影像特征。
再结合图3所示,通过上述步骤S1~S4,获取用于肺结节分类鉴别的影像特征后,将获取的影像特征输入至第一分类预测模型中,即可得到第一分类预测结果。在实施时,第一分类预测模型为多层感知机,且通过配置多层感知机的输出层输出特征矩阵或预测概率作为第一分类预测结果。
具体的,如图7所示,基于所述肺结节患者的血浆cfDNA的5mC测序结果而获得用于肺结节分类鉴别的标志物特征包括以下步骤:
第一步,基于所述肺结节患者的血浆cfDNA的5mC测序结果,获得被选定作为5mC标志物的多个标志物的测序信号的峰值信息;
第二步,基于所述多个标志物的测序信号的峰值信息,对所述多个标志物的测序信号峰值位置进行读段计数;
第三步,根据每个标志物的测序信号峰值位置的读段数值,构建出作为所述标志物特征的多维向量。
其中,由于cfDNA是细胞凋亡后进入血液中裂解释放出来的DNA,而癌症患者血浆中cfDNA的某些成分是由肿瘤细胞释放的,即ctDNA;由于已有很多研究指出,DNA 甲基化与癌症的发生密切相关,因此,本发明实施例利用血浆cfDNA的5mC标志物来实现肺癌的早期筛查。
在实施时,为了获取肺结节患者的血浆cfDNA的5mC测序结果,首先,需要通过对肺结节患者的血浆样本进行一系列处理,提取出血浆中的cfDNA,然后依次进行对cfDNA末端修复、接头连接、5mC片段富集、5mC片段纯化、文库扩增、上机测序等步骤获得高通量的5mC测序结果。由于5mC测序结果包含了大量的不同片段的测序结果,同时,也掺杂了背景信号,这些背景信号对标志物的筛选造成了很大的干扰。因此,为了降低第二分类预测模型的训练难度以及提高分类预测的准确性,需要进一步筛选出高灵敏度和特异性的标志物。
在实施时,选定作为5mC标志物的多个标志物包括以下步骤:
第一步,基于多个良性肺结节样本和多个恶性肺结节样本的血浆cfDNA的5mC测序结果,生成对应BED文件;其中,生成BED文件的过程具体为:利用Illumina 自带的数据拆分工具 bcl2fastq 工具包将测序得到的原始结果转换为 fastq 文件,接着采用fastp 软件去除接头和低质量的序列,获得清洗后的fastq文件,然后,再采用 bwa mem 算法将经过清洗后的测序数据比对至参考基因组上 (hg19),获得 SAM 格式的比对文件,并采用SAMTOOLS 工具包将 SAM 格式转换为 BAM 格式,最后,采用 picard 软件对文库扩增过程引入的重复序列和测序过程中形成的光学重复序列进行标识,并采用 bedtools 将 BAM文件按照染色体及位置生成 BED 文件。
第二步,对所述BED文件执行Callpeak命令,获取每个样本的测序信号的Peak信息,并生成每个样本对应的测序信号峰值位置集合;具体的,采用 MACS2 软件对BED 文件进行 Callpeak 命令,获取如图8所示的每个样本 Peak 及 Summit 位置信息(测序信号峰值位置信息),接着,对每个 Summit 位置的上下游分别延伸 100bp,使每个Summit 位置信息获得固定宽度,最后,对每个固定宽度的 Summit 位置的分值进行标准化处理。
第三步,对每个样本的测序信号峰值位置集合进行去重处理,使测序信号峰值位置集合内的测序信号峰值位置无重叠;具体的,去重处理的方式为同一个样本中有重叠的Summit 位置,仅保留分值最高的 Summit 位置。
第四步,合并所有样本的测序信号峰值位置集合,得到第一测序信号峰值位置集合,并对所述第一测序信号峰值位置集合进行去重处理,得到第二测序信号峰值位置集合;具体的,去重处理的方式为按照染色体及位置进行排序,将有重叠的 Summit 位置,仅保留分值最高的 Summit 位置。
第五步,筛除所述第二测序信号峰值位置集合中与全部良性肺结节样本或全部恶性肺结节样本对应的样本测序信号峰值集合存在交集的比例未达到设定阈值的测序信号峰值位置,得到第三测序信号峰值集合;如此,使第三测序信号峰值集合中的测序信号峰值位置具有更好肺结节良恶性分类性能。
第六步,对所述第三测序信号峰值集合中的测序信号峰值位置进行读段计数,并对测序信号峰值位置的读段数值进行标准化后,对每个测序信号峰值位置的读数数量进行秩和检验,得到每个测序信号峰值位置的q-value。具体的,采用bedtools 软件对第三测序信号峰值集合中的测序信号峰值位置进行读段计数;采用 edgeR包中的 CPM (Counts permillion)方法对每一个 Summit 中的读段数量进行标准化。
第七步,基于q-value 排名靠前多个的测序信号峰值位置构建第四测序信号峰值集合,并以所述第四测序信号峰值集合中各个测序信号峰值位置的读段数值为自变量,以肺结节的良性或恶性为因变量,筛选出所有与因变量具有相关性的测序信号峰值位置作为5mC标志物;具体的,采用 Boruta 算法筛选得到所有与因变量具有相关性的特征集合。
进一步地,为了提高所选定的5mC标志物的泛化性能,在第七步中,筛选出所有与因变量具有相关性的测序信号峰值位置包括:
基于所述多个良性肺结节样本和所述多个恶性肺结节样本构建若干个不同的种子,得到基于每个种子所筛选出所有与因变量具有相关性的测序信号峰值位置;
统计所述第四测序信号峰值集合中各个测序信号峰值位置筛选为与因变量具有相关性的测序信号峰值位置的频次,并将所述第四测序信号峰值集合中频次达到设定阈值的测序信号峰值位置作为5mC标志物。
在实施时,通过收集 200 例早期肺癌患者(原位肺腺癌48例,微浸润性肺腺癌62例和浸润性肺腺癌90例)和80例良性结节患者的血浆样本,进而构建数据集A,再基于本发明实施例中提供的筛选标志物方式,并构建100个种子,设定阈值为30次,最终得到的标志物(Biomarker)及其频次统计结果如见表1所示。
表1:标志物及其频次统计结果
。
此外,为了减少多维向量的维度,还可以采用弹性网络回归(Elastic-NetRegression)、岭回归(Ridge Regression)、支持向量机回归(Support VectorRegression)等机器学习算法对表1中所得的标志物进行重要性排序,并根据实际应用的需要选择一定数量排序靠前的标志物作为最终5mC标志物。
对于第二分类预测模型的模型的构建可选择弹性网络回归(Elastic-NetRegression)、岭回归(Ridge Regression)、支持向量机回归(Support VectorRegression)、Lasso (Lasso Regression)、随机森林(Forests of randomized trees)、Adaboost和XGboost等常见的机器学习算法;而为了获得最优的分类器,将弹性网络回归、岭回归、支持向量机回归、Lasso、随机森林、Adaboost和XGboost均作为备选分类预测模型分别进行设定次数的训练,获取每种备选分类预测模型每次训练成功后的AUC得分,并选择AUC得分的平均值和标准差满足相应条件的备选分类预测模型作为第二分类预测模型。
在实施时,利用本发明实施例中提供一系列处理方法对数据集A进行处理,获得全部血浆样本对应的标志物特征。再采用 5 折交叉验证,对每种分类算法,每一次按照肺结节良恶性等比例方式将训练集划分成 5 等份(阳性样本和阴性样本在每一折中的比例相同),随机选择其中的 4 份作为训练集用于分类模型的构建,其余的 1 份作为测试集数据进行验证。重复上述过程 20 次,总共得到 100 个模型的 AUC 得分,并分别计算每一个模型的平均 AUC 得分和 AUC标准偏差,统计结果如表2所示。
表2:不同分类器的AUC平均值和 AUC标准差统计结果
。
根据表2所示的统计结果,选择AUC 得分最大且AUC标准偏差小的分类模型作为最终的分类器,即选择支持向量机回归算法作为第二分类预测模型的分类算法;然后,基于数据集A进行第二分类预测模型的构建和超参数的优化。
具体的,第三分类预测模型为logistic回归模型,当然,本领域技术人员还可以选择弹性网络回归(Elastic-Net Regression)、岭回归(Ridge Regression)、支持向量机回归(Support Vector Regression)等机器学习算法;而对于第三分类预测模型的训练和验证,首先,通过收集320例早期肺癌患者(原位肺腺癌76例,微浸润性肺腺癌100例和浸润性肺腺癌144例)和120例良性结节患者的血浆样本以及CT图像,构成数据集B。
接着,基于每个患者肺部CT影像而获得用于肺结节分类鉴别的影像特征,并将所述影像特征输入第一分类预测模型,得到第一分类预测结果;基于每个患者的血浆cfDNA的5mC测序结果而获得用于肺结节分类鉴别的标志物特征,并将所述标志物特征输入第二分类预测模型,得到第二分类预测结果;从而得到440例肺结节样本的数据集。进一步将数据集B分为220例肺结节 (160例恶性,60例良性)样本的独立验证集以及220例肺结节 (160例恶性,60例良性)样本的训练集。
在实施时,第一分类预测结果和第二分类预测结果为特征矩阵或预测分值。以第一分类预测结果和第二分类预测结果为预测分值为例,第三分类预测模型以5mC标志物风险预测分值和 CT 影像预测分值为自变量,肺结节的良恶性作为因变量,并基于logistic回归模型构建多维度联合诊断模型,并利用上述步骤中得到的数据集进行训练。
训练完成后,采用 220例肺结节 (160例恶性,60例良性)样本的独立验证集对训练完成的第三分类预测模型进行验证,同时,以AUC分值、灵敏度、特异性和准确度为评价指标,分别评价第一分类预测模型(简称为CT AI)、第二分类预测模型(简称为5mC)和第三分类预测模型(简称CT AI+5mC)的分类效果,具体的数据统计结果如表3所示。
表3:CT AI、5mC以及CT AI+5mC的分类性能数据统计结果
。
根据表3所示的统计结果,以及图9所示的ROC 曲线对比图,在肺结节良恶性的分类性能上,第三分类预测模型(CT AI+5mC)明显优于第二分类预测模型(5mC)或第一分类预测模型(CT AI)。
其中,受试者工作特征曲线 (Receiver Operating Characteristic Curve,ROC曲线) 是根据一系列不同的二分类方式(分界值),以真阳性率(敏感性)为纵坐标,假阳性率(1-特异性)为横坐标绘制的曲线。
受试者曲线下面积(Area Under Curve),被定义为 ROC 曲线下的面积。AUC值常用来评价分类的分类效果。AUC 数值越大,则对应的分类器效果越好;反之,则对应的分类器效果越差。
灵敏度(Sensitivity),指所有正例中被分对的比例,衡量了分类器对正例的识别能力。其计算公式为:
特异性(Specificity),指所有负例中被正确识别为负例的比例,衡量了分类器对负例的识别能力。其计算公式为:
其中,真阳性(True Positives,TP),样本为正,预测结果为正;假阳性(FalsePositivies,FP),样本为负,预测结果为正;真阴性(True Negatives,TN),样本为负,预测结果为负;假阴性(False Negatives,FN),样本为正,预测结果为负。
如图10所示,该电子装置包括处理器,其可以根据存储在只读存储器(Read-OnlyMemory,ROM)中的计算机程序或者从存储单元加载到随机访问存储器(Random AccessMemory,RAM)中的计算机程序,来执行各种运算操作。在RAM中,还可存储电子设备操作所需的各种程序和数据。处理器、ROM 以及RAM通过总线彼此相连。输入/输出(I/O)接口也连接至总线,通信单元、输入单元和输出单元通过I/O接口连接至总线,从而实现电子设备与外部设备的数据交互。因此,在该电子装置中的只读存储器(ROM)或者存储单元中存储用于实现本发明实施例提供的基于肺部CT与5mC标志物融合的肺结节分类方法的计算机程序或可执行指令,即可得到一种肺结节分类装置。
进一步地,本发明还提供一种计算机可读介质,其上存储有计算机程序,该计算机程序被一个或多个处理器执行时实现本发明实施例中提供的基于肺部CT与5mC标志物融合的肺结节分类方法。
应该理解到,本发明所揭露的装置或设备,可通过其它的方式实现。例如所述模块的划分,仅仅为一种逻辑功能划分,实际实现时可以有另外的划分方式,例如多个单元或组件可以结合或者可以集成到另一个系统,或一些特征可以忽略,或不执行。另一点,模块之间的通信连接可以是通过一些接口,装置或单元的间接耦合或通信连接,可以是电性或其它的形式。
另外,在本发明各个实施例中的各功能模块可以集成在一个处理单元中,也可以是各个模块单独物理存在,也可以两个或两个以上模块集成在一个处理单元中。上述集成的单元既可以采用硬件的形式实现,也可以采用软件功能单元的形式实现。
所述集成的单元如果以软件功能单元的形式实现并作为独立的产品销售或使用时,可以存储在一个计算机可读取存储介质中。基于这样的理解,本发明的技术方案本质上或者说对现有技术做出贡献的部分或者该技术方案的全部或部分可以以软件产品的形式体现出来,该计算机软件产品存储在一个存储介质中,包括若干指令用以使得一台计算机设备(可为个人计算机、服务器或者网络设备等)执行本发明各个实施例所述方法的全部或部分步骤。而前述的存储介质包括:U盘、只读存储器(ROM)、随机存取存储器(RAM)、移动硬盘、磁碟或者光盘等各种可以存储程序代码的介质。
以上所述仅为本发明的较佳实施例而已,并不用以限制本发明,凡在本发明的精神和原则之内所作的任何修改、等同替换和改进等,均应包含在本发明的保护范围之内。