一种检测web攻击的方法及系统
文献发布时间:2023-06-19 19:28:50
技术领域
本发明涉及信息安全技术领域,具体涉及一种检测web攻击的方法及系统。
背景技术
通常检测web攻击的系统叫做WEB应用防火墙,简称WAF(web applicationfirewall),可以防止WEB应用免受各种常见攻击,比如SQL注入,跨站脚本攻击(XSS),命令注入(OS命令,webshell等)。Waf会在流量抵达应用服务器之前检测可疑访问,对非法请求予以实时阻断,同时也能防止从web应用获取未经授权的数据。在Verizon数据泄露调查报告中将Web应用攻击列为最常见的攻击之后,web应用安全变的越来越重要。与传统防火墙不同,WAF工作在应用层,因此对Web应用防护具有先天的技术优势。
传统WAF对恶意流量的检测能力非常依赖规则库,规则越多识别率越高,并且这个识别率只是针对已知的攻击方式,对未知的攻击方式完全没有检测能力。通常传统的WAF想要提高检测能力,就得不断地添加新的规则到规则库,但随着规则库的不断庞大,检测性能会降低,因为每一条请求都需要跟规则库比对一遍。
发明内容
本发明的目的在于提供一种检测性能高的检测web攻击的方法及系统。
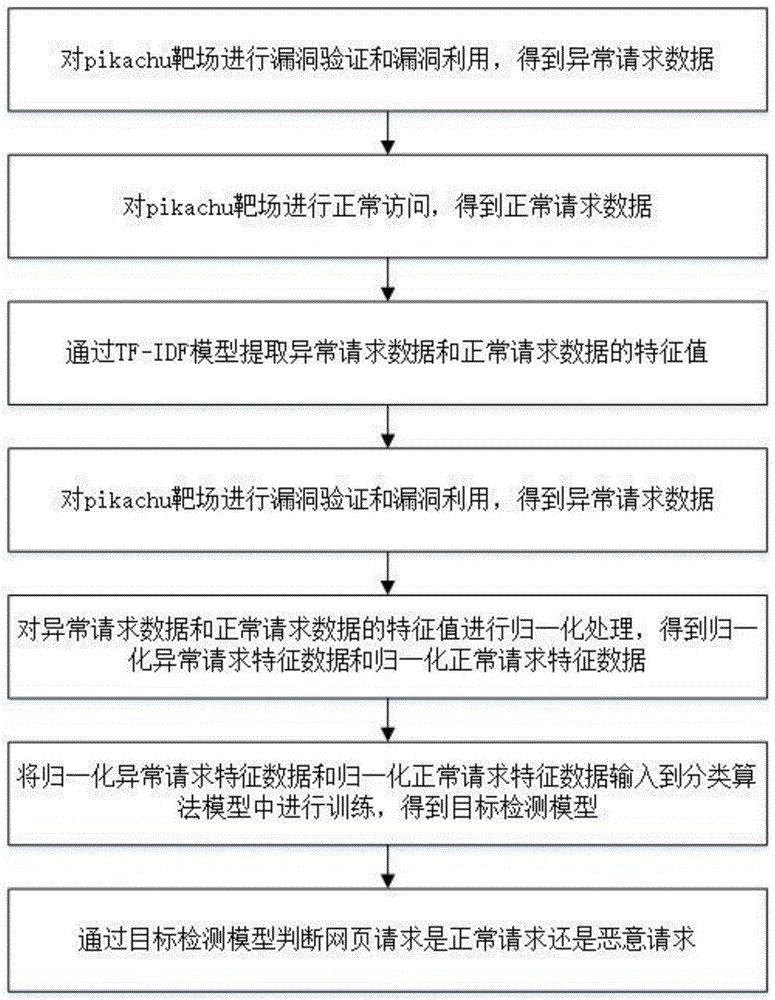
为解决上述技术问题,本发明提供一种检测web攻击的方法,包括以下步骤:
对pikachu靶场进行漏洞验证和漏洞利用,得到异常请求数据;
对pikachu靶场进行正常访问,得到正常请求数据;
通过TF-IDF模型提取异常请求数据和正常请求数据的特征值;
对异常请求数据和正常请求数据的特征值进行归一化处理,得到归一化异常请求特征数据和归一化正常请求特征数据;
将归一化异常请求特征数据和归一化正常请求特征数据输入到分类算法模型中进行训练,得到目标检测模型;
通过目标检测模型判断网页请求是正常请求或者恶意请求。
优选地,将归一化异常请求特征数据和归一化正常请求特征数据输入到分类算法模型中进行训练,得到目标检测模型,具体包括以下步骤:
将归一化异常请求特征数据和归一化正常请求特征数据输入到分类算法模型中进行训练;
在训练过程中,采用网格搜索方法选择合适的分类算法超参数,并通过十字交叉验证,得到目标检测模型。
优选地,所述分类算法模型为K近邻算法模型、逻辑回归算法模型、决策树算法模型、随机森林算法模型、支持向量机算法模型、xgboost算法模型或朴素贝叶斯算法模型。
优选地,所述分类算法模型为xgboost算法模型。
优选地,所述xgboost算法使用基于histogram的决策树算法,把连续的浮点特征值离散化成k个整数,同时构造一个宽度为k的直方图;在遍历数据的时候,根据离散化后的值作为索引在直方图中累积统计量,当遍历一次数据后,直方图累积了需要的统计量,然后根据直方图的离散值,遍历寻找最优的分割点。
优选地,对pikachu靶场进行漏洞验证和漏洞利用,得到异常请求数据;对pikachu靶场进行正常访问,得到正常请求数据;具体包括以下步骤:
对pikachu靶场进行漏洞验证和漏洞利用,获取pikachu靶场的请求日志,作为异常请求数据;
对pikachu靶场进行正常访问,获取pikachu靶场的请求日志,作为正常请求数据。
优选地,在TF-IDF模型中,IDF=log(m*N/n+0.01);
其中:IDF为逆文档频率;m为本类含特征词文档数;N为总文档数;n为所有含特征词文档数,各个特征词的逆文档频率作为异常请求数据和正常请求数据的特征值。
优选地,对pikachu靶场进行漏洞验证和漏洞利用,具体包括以下步骤:
使用sqlmap、xray、nuclei或metasploit对pikachu靶场进行漏洞验证和漏洞利用。
优选地,所述异常请求数据包括SQL注入、文件遍历、CRLF注入、XSS、SSI攻击样本数据。
本发明还提供一种检测web攻击的系统,包括:
漏洞验证模块,用于对pikachu靶场进行漏洞验证和漏洞利用,得到异常请求数据;
正常访问模块,用于对pikachu靶场进行正常访问,得到正常请求数据;
特征提取模块,用于通过TF-IDF模型提取异常请求数据和正常请求数据的特征值;
归一化处理模块,用于对异常请求数据和正常请求数据的特征值进行归一化处理,得到归一化异常请求特征数据和归一化正常请求特征数据;
模型训练模块,用于将归一化异常请求特征数据和归一化正常请求特征数据输入到分类算法模型中进行训练,得到目标检测模型;
检测模块,用于通过目标检测模型判断网页请求是正常请求或者恶意请求。
与现有技术相比,本发明的有益效果为:
本发明将web攻击检测问题转化为一个分类问题,使用标注过的网站访问日志作为训练样本,训练一个分类模型,使用该模型对新的网页请求预测属于正常请求或者恶意请求,并给出预测概率。模型的准确率跟训练样本和参数相关,参数可以使用网格搜索方法找到最优解,因此训练样本质量越高,模型越准确,但训练样本的多少只会影响模型的训练速度,而预测速度是恒定的,因此可以解决传统WAF规则库庞大导致检测性能低的问题。机器学习模型具有泛化能力,即算法对新鲜样本的适应能力,可以对没有包含在训练样本中的未知攻击方式也有一定的识别能力,从而解决了传统规则库的缺陷。
附图说明
下面结合附图对本发明的具体实施方式作进一步详细说明。
图1是本发明一种检测web攻击的方法的流程示意图;
图2是模型训练的流程示意图;
图3是十折交叉验证的示意图;
图4是决策树算法的示意图。
具体实施方式
在下面的描述中阐述了很多具体细节以便于充分理解本发明。但是本发明能够以很多不同于在此描述的其它方式来实施,本领域技术人员可以在不违背本发明内涵的情况下做类似推广,因此本发明不受下面公开的具体实施的限制。
在本说明书一个或多个实施例中使用的术语是仅仅出于描述特定实施例的目的,而非旨在限制本说明书一个或多个实施例。在本说明书一个或多个实施例和所附权利要求书中所使用的单数形式的“一种”、“所述”和“该”也旨在包括多数形式,除非上下文清楚地表示其他含义。还应当理解,本说明书一个或多个实施例中使用的术语“和/或”是指并包含一个或多个相关联的列出项目的任何或所有可能组合。
应当理解,尽管在本说明书一个或多个实施例中可能采用术语第一、第二等来描述各种信息,但这些信息不应限于这些术语。这些术语仅用来将同一类型的信息彼此区分开。例如,在不脱离本说明书一个或多个实施例范围的情况下,第一也可以被称为第二,类似地,第二也可以被称为第一。取决于语境,如在此所使用的词语“如果”可以被解释成为“在……时”或“当……时”或“响应于确定”。
下面结合附图1-4对本发明做进一步的详细描述:
如图1所示,本发明提供一种检测web攻击的方法,包括以下步骤:
对pikachu靶场进行漏洞验证和漏洞利用,得到异常请求数据;
对pikachu靶场进行正常访问,得到正常请求数据;
通过TF-IDF模型提取异常请求数据和正常请求数据的特征值;
对异常请求数据和正常请求数据的特征值进行归一化处理,得到归一化异常请求特征数据和归一化正常请求特征数据;
将归一化异常请求特征数据和归一化正常请求特征数据输入到分类算法模型中进行训练,得到目标检测模型;
通过目标检测模型判断网页请求是正常请求或者恶意请求。
优选地一个实施例,将归一化异常请求特征数据和归一化正常请求特征数据输入到分类算法模型中进行训练,得到目标检测模型,具体包括以下步骤:
将归一化异常请求特征数据和归一化正常请求特征数据输入到分类算法模型中进行训练;
在训练过程中,采用网格搜索方法选择合适的分类算法超参数,并通过十字交叉验证,得到目标检测模型。
优选的一个实施例,所述分类算法模型为K近邻算法模型、逻辑回归算法模型、决策树算法模型、随机森林算法模型、支持向量机算法模型、xgboost算法模型或朴素贝叶斯算法模型。
优选地一个实施例,所述分类算法模型为xgboost算法模型。
优选地一个实施例,所述xgboost算法使用基于histogram的决策树算法,把连续的浮点特征值离散化成k个整数,同时构造一个宽度为k的直方图;在遍历数据的时候,根据离散化后的值作为索引在直方图中累积统计量,当遍历一次数据后,直方图累积了需要的统计量,然后根据直方图的离散值,遍历寻找最优的分割点。
优选地一个实施例,对pikachu靶场进行漏洞验证和漏洞利用,得到异常请求数据;对pikachu靶场进行正常访问,得到正常请求数据;具体包括以下步骤:
对pikachu靶场进行漏洞验证和漏洞利用,获取pikachu靶场的请求日志,作为异常请求数据;
对pikachu靶场进行正常访问,获取pikachu靶场的请求日志,作为正常请求数据。
优选地一个实施例,在TF-IDF模型中,逆文档频率IDF=log(本类含特征词文档数m*总文档数N/所有含特征词文档数n+0.01)。
优选地一个实施例,对pikachu靶场进行漏洞验证和漏洞利用,具体包括以下步骤:
使用sqlmap、xray、nuclei或metasploit对pikachu靶场进行漏洞验证和漏洞利用。
优选地一个实施例,所述异常请求数据包括SQL注入、文件遍历、CRLF注入、XSS和SSI攻击样本数据。
优选地一个实施例,所述异常请求数据和正常请求数据的特征值包括各个特征词的逆文档频率;特征词包括URL长度、请求类型、参数部分长度、参数的个数、参数的最大长度、参数的数字个数、参数值中数字所占比例、参数值中字母所占比例、特殊字符个数、特殊字符所占比例、URL中包含第三方http域名的个数、URL中包含第三方https域名的个数、敏感字符的个数、敏感关键字的个数。
本发明将web攻击检测问题转化为一个分类问题,使用标注过的网站访问日志作为训练样本,训练一个分类模型,使用该模型对新的网页请求预测属于正常请求或者恶意请求,并给出预测概率。模型的准确率跟训练样本和参数相关,参数可以使用网格搜索方法找到最优解,因此训练样本质量越高,模型越准确,但训练样本的多少只会影响模型的训练速度,而预测速度是恒定的,因此可以解决传统WAF规则库庞大导致检测性能低的问题。机器学习模型具有泛化能力,即算法对新鲜样本的适应能力,可以对没有包含在训练样本中的未知攻击方式也有一定的识别能力,从而解决了传统规则库的缺陷。
为了更好的说明本发明的技术效果,本发明提供如下具体实例说明上述技术流程,包括以下步骤:
1.训练样本生成:
本发明将web攻击检测问题转化为分类问题,就可以使用机器学习的分类算法来解决。改造pikachu靶场,记录每次请求的日志,然后使用sqlmap,xray,nuclei,metasploit对靶场进行漏洞验证和漏洞利用,从而得到训练样本中的异常请求数据,再通过手工点击的方式对pikachu靶场进行正常访问,获得正常请求数据。然后将网站访问日志数据按照正常请求和异常请求分为两个文件作为标注好的训练样本数据,包含10万条正常请求和10万条攻击请求,攻击请求样本中包含SQL注入、文件遍历、CRLF注入、XSS、SSI等攻击样本;
2.特征工程:
从上面的数据样例可以看出原始数据都是文本型的,一个Web访问记录的成分是比较固定的,每个部分(方法、路径、参数、HTTP头、Cookie等)都有比较好的结构化特点,因此可以把Web攻击识别任务抽象为文本分类任务,但机器学习算法只能输入数值型和布尔型特征,原始数据还需要做个特征工程来提取特征才能作为训练样本。这里我们使用TF-IDF模型结合利用安全知识提取特征的方式,自定义特征如下:URL长度、请求类型、参数部分长度、参数的个数、参数的最大长度、参数的数字个数、参数值中数字所占比例、参数值中字母所占比例、特殊字符个数、特殊字符所占比例、URL中包含第三方http域名的个数、URL中包含第三方https域名的个数、敏感字符的个数(如>个数、<个数、,个数、”个数)、敏感关键字的个数(如alert个数、script=个数、onerror个数、onload个数、eval个数、src=个数)。提取出来的特征值可能有些列变化幅度较大,为了模型效果更好,对数据进行归一化操作。经过特征工程从样本中提取出可输入算法的特征之后,分别打上标签,0表示正常请求样本,1表示攻击请求样本。
3.模型训练,如图2所示;
常用的分类算法有K近邻算法、逻辑回归算法、决策树算法、随机森林算法、支持向量机算法、xgboost以及朴素贝叶斯算法。这里我们同时训练逻辑回归、随机森林、支持向量机和改进后的xgboost四种模型,然后从中调一个最好的,经实验数据比较改进后的xgboost模型的效果最好;如下表1所示。
表1
xgboost的全称是eXtreme Gradient Boosting,它是经过优化的分布式梯度提升库,旨在高效、灵活且可移植。XGBoost是大规模并行boosting tree的工具,它是目前最快最好的开源boosting tree工具包,比常见的工具包快10倍以上。在数据科学方面,有大量的Kaggle选手选用XGBoost进行数据挖掘比赛,是各大数据科学比赛的必杀武器;在工业界大规模数据方面,XGBoost的分布式版本有广泛的可移植性,支持在Kubernetes、Hadoop、SGE、MPI、Dask等各个分布式环境上运行,使得它可以很好地解决工业界大规模数据的问题。XGBoost的基本思想差不多可以理解成以损失函数的二阶泰勒展开式作为其替代函数,求解其最小化(导数为0)来确定回归树的最佳切分点和叶节点输出数值(这一点和cart回归树不同)。此外,XGBoost通过在损失函数中引入子树数量和子树叶节点数值等,充分考虑到了正则化问题,能够有效避免过拟合。在效率上,XGBoost通过利用独特的近似回归树分叉点估计和子节点并行化等方式,加上二阶收敛的特性,建模效率较一般的GBDT有了大幅的提升。
在进行模型训练时,采用网格搜索法(GridSearchCV)和十折交叉验证(ten-foldcross validation)结合的方式来评估超参数的所有可能的组合的最优解。
十折交叉验证是指将所有样本进行十等分,其中任意一等份均被当为验证集测试模型的好坏,另外9分数据作为训练集训练模型。如图3所示,9/10样本依次作为训练数据集训练模型,1/10样本依次被当做测试数据集测试模型,这样的方法被称为十折交叉验证。
算法具体可以使用RandomForestClassifier。
4、模型应用:
模型部署之后,对新来的网页请求经过同样的特征提取之后使用该模型预测属于正常请求或者恶意请求,并给出预测概率。
与现有技术相比,本发明的改进点为:
1)、训练样本数据的生成:本发明中改造pikachu靶场,让它记录访问日志,然后使用sqlmap,xray,nuclei,metasploit对靶场进行漏洞验证和漏洞利用,从而得到训练样本中的异常请求数据,再通过手工点击的方式获得正常请求数据。分类器在处理不平衡数据时往往会倾向于保护多数类的准确率而牺牲少数类的准确率,导致少数类的误分率较高,因此生成样本数据时尽可能均衡。
2)、对TF-IDF算法的改进:TF部分改进,将文档内的词频率更改为同一类文档内的词频率可以在一定程度上解决上面提到TF-IDF的第2项不足之处;IDF部分改进,传统的IDF通常可以写作:IDF=log(总文档数N/所有含特征词文档数n+0.01),该函数中只考虑了特征词与它出现的文本数之间的关系,而忽略了特征项在一个类别中不同的类别间的分布情况,我们对函数做改进来解决这个问题,IDF=log(本类含特征词文档数m*总文档数N/所有含特征词文档数n+0.01)。
3)、对xgboost算法的改进:使用基于histogram的决策树算法,把连续的浮点特征值离散化成k个整数,同时构造一个宽度为k的直方图。在遍历数据的时候,根据离散化后的值作为索引在直方图中累积统计量,当遍历一次数据后,直方图累积了需要的统计量,然后根据直方图的离散值,遍历寻找最优的分割点,改进后明显减少内存的使用,因为直方图不需要额外存储预排序的结果,而且可以只保存特征离散化后的值。
利用直方图做差加速,一个叶子的直方图可以由它的父亲节点的直方图与它兄弟的直方图做差得到。通常构造直方图,需要遍历该叶子上的所有数据,但直方图做差仅需遍历直方图的k个桶。利用这个方法,可以在构造一个叶子的直方图后,可以用非常微小的代价得到它兄弟叶子的直方图,在速度上可以提升一倍;如图4所示。
4)、xgboost算法在WEB攻击检测场景的应用:传统的WAF太依赖规则库,将机器学习算法应用到该场景中能够具备未知攻击发现能力和提高检测速率。
在本发明所提供的几个实施例中,应该理解到,所揭露的装置和方法,可以通过其它的方式实现。例如,以上所描述的装置实施例仅仅是示意性的,例如,所述模块、模组或单元的划分,仅仅为一种逻辑功能划分,实际实现时可以有另外的划分方式,例如多个单元、模组或组件可以结合或者可以集成到另一个装置,或一些特征可以忽略,或不执行。
所述单元可以是或者也可以不是物理上分开的,作为单元显示的部件可以是一个物理单元或多个物理单元,即可以位于一个地方,或者也可以分布到多个不同地方。可以根据实际的需要选择其中的部分或者全部单元来实现本实施例方案的目的。
另外,在本发明各个实施例中的各功能单元可以集成在一个处理单元中,也可以是各个单元单独物理存在,也可以两个或两个以上单元集成在一个单元中。上述集成的单元既可以采用硬件的形式实现,也可以采用软件功能单元的形式实现。
特别地,根据本发明公开的实施例,上文参考流程图描述的过程可以被实现为计算机软件程序。例如,本公开的实施例包括一种计算机程序产品,其包括承载在计算机可读介质上的计算机程序,该计算机程序包含用于执行流程图所示的方法的程序代码。在这样的实施例中,该计算机程序可以通过通信部分从网络上被下载和安装,和/或从可拆卸介质被安装。在该计算机程序被中央处理单元(CPU)执行时,执行本发明的方法中限定的上述功能。需要说明的是,本发明上述的计算机可读介质可以是计算机可读信号介质或者计算机可读存储介质或者是上述两者的任意组合。计算机可读存储介质例如可以是但不限于电、磁、光、电磁、红外线段、或半导体的系统、装置或器件,或者任意以上的组合。
附图中的流程图和框图,图示了按照本发明各种实施例的系统、方法和计算机程序产品的可能实现的体系架构、功能和操作。在这点上,流程图或框图中的每个方框可以代表一个模块、程序段、或代码的一部分,该模块、程序段、或代码的一部分包含一个或多个用于实现规定的逻辑功能的可执行指令。也应当注意,在有些作为替换的实现中,方框中所标注的功能也可以以不同于附图中所标注的顺序发生。例如,两个接连地表示的方框实际上可以基本并行地执行,它们有时也可以按相反的顺序执行,这依所涉及的功能而定。也要注意的是,框图和/或流程图中的每个方框、以及框图和/或流程图中的方框的组合,可以用执行规定的功能或操作的专用的基于硬件的系统来实现,或者可以用专用硬件与计算机指令的组合来实现。
以上所述,仅为本发明的具体实施方式,但本发明的保护范围并不局限于此,任何在本发明揭露的技术范围内的变化或替换,都应涵盖在本发明的保护范围之内。因此,本发明的保护范围应以所述权利要求的保护范围为准。
- 一种Web应用系统SessionID攻击的识别方法
- 一种基于文件服务系统的web攻击行为检测方法及系统
- 一种Java Web框架漏洞攻击通用检测与定位的方法及系统