基于深度学习和改进证据融合理论的船用柴油机故障诊断方法
文献发布时间:2023-06-19 19:28:50
技术领域
本发明涉及柴油机故障诊断技术领域,具体为一种基于深度学习和证据融合理论的船用柴油机故障诊断方法。
背景技术
船用柴油机的热效率高、经济性好、起动容易、对各类船舶有很大适应性,问世以后很快就被用作船舶推进动力。目前船用柴油机在使用时,当出现故障时,往往无法及时被发现,当船用柴油机发生故障时,船用柴油机会出现停止运行、无法正常工作、运行异响和运行迟缓等现象,这些现象一旦出现会加大柴油机自身的损耗,降低自身的使用寿命。故障诊断技术指根据机械设备运行状态,判断其是否正常运行并及时发现故障的技术,是机械设备安全生产和高效运行的有力保障。在自动化生产中,对机械设备进行更准确、更智能的故障诊断对于提高工业生产效率和经济效益具有非常重要的意义。随着工业的快速发展,各种生产设备的结构越来越复杂,功能也日趋多样化,设备的故障率也不可避免地随之增加。由于这些复杂设备的故障通常具有多源性、复杂性以及隐蔽性的特点,因此,通过传统的故障诊断方法寻找故障原因变得越来越困难。机械设备发生故障时,会反应出各种征兆,诸如振动、温度、噪声等信号的变化,现有的故障诊断方法多是基于单一的振动信号做出评判,没有考虑设备其他信号对于诊断结果的影响,诊断结果缺乏准确性。
发明内容
本发明所要解决的技术问题是:提供一种使诊断结果更为科学、合理的基于多信号融合的船用柴油机故障诊断方法。
为解决上述技术问题,本发明所采用的技术方案为:基于证据融合理论和深度学习的船用柴油机故障诊断方法,包括以下步骤:
步骤1、建立运行信号集U和运行状态集V;
船用柴油机运行的监测数据包括柴油机的转速、油箱温度、振动信号,以监测参数以及其变化作为运行信号,建立运行信号集U={柴油机的转速、油箱温度、振动信号、柴油机的转速变化率、油箱温度变化率、油箱振动信号变化率};
船用柴油机可能出现的故障包括单缸失火、排气管泄露、压气机污阻、空滤器堵塞和润滑不良,建立运行状态集V={正常状态、单缸失火、排气管泄露、压气机污阻、空滤器堵塞、润滑不良};
步骤2:根据运行信号的自身特点,确定采样频率,采样频率不小于2倍的运行信号频率;
步骤3:对运行信号处理,构造样本集;
振动信号从采集起始点开始,连续若干个数据作为一个样本;
柴油机的转速采用重叠采样的方法来扩增数据样本数量,移动步长不小于单个样本数据数的10%;
油箱温度采用重叠采样的方法来扩增数据样本数量,移动步长不大于单个样本数据数的1%;
柴油机的转速变化率、油箱温度变化率、油箱振动信号变化率分别采用相邻两个数据的差值;
步骤4、对柴油机的转速、油箱温度、振动信号、柴油机的转速变化率、油箱温度变化率、油箱振动信号变化率分别构建以下故障诊断模型,设置故障诊断模型参数:
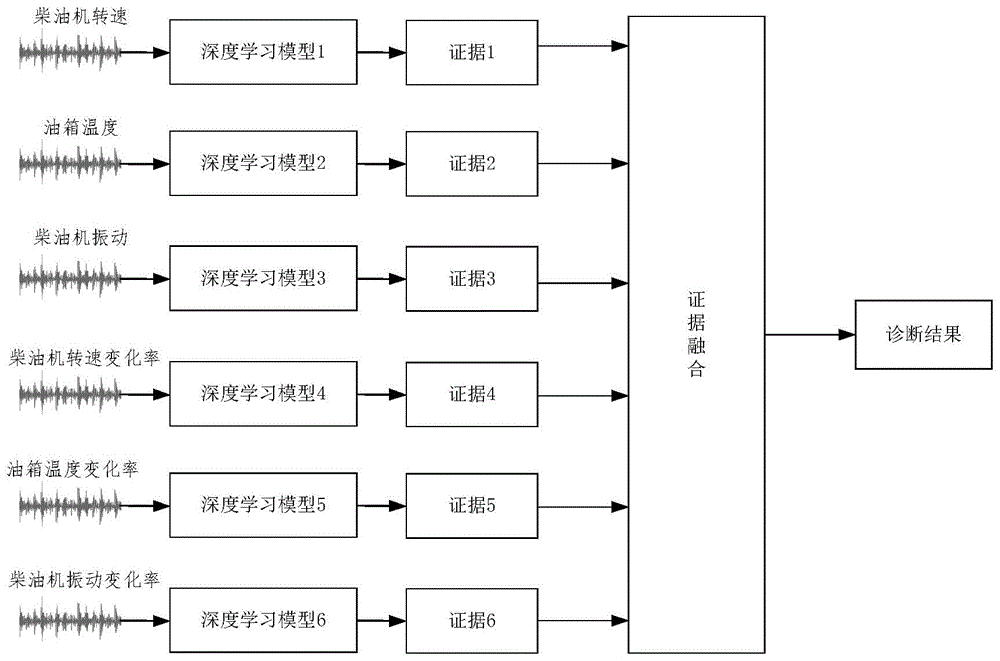
故障诊断模型包括结构相同的6个深度学习模型,柴油机的转速、油箱温度、振动信号、柴油机的转速变化率、油箱温度变化率、油箱振动信号变化率分别作为其中一个深度学习模型的输入;6个深度学习模型的输出分别为证据1至证据6,证据1至证据6作为证据融合模块的输入,证据融合的即为故障诊断的结果;
步骤5、训练故障诊断模型;
S5-1按照一定比例将数据样本划分成训练集与测试集;
S5-2设置训练参数;
采用Adam优化器来更新网络参数,设定模型训练时的Epoch、批次大小以及Adam算法的学习率;
S5-3模型训练;
采用随机方式,对故障诊断模型参数进行初始化,将训练集样本按批次输入故障诊断模型中进行模型训练,将测试样本输入训练好的故障诊断模型中进行测试,输出故障诊断准确率,以此来判断所提模型可行性;训练结束后保存训练好的故障诊断模型;
步骤6、构造证据;
每个深度学习模型的输出作为一条证据,针对每个诊断,六个深度学习模型产生六个输出结果,即构造出六条证据记作E
步骤7、证据融合;
S7.1证据权重的构建
证据E
其中,
其中,i,j,k=1,2,…,6。
证据E
其中,i,j,k=1,2,…,6;
证据E
证据E
将其归一化处理后,得到各证据归一化后的总体相似度为:
S7-2新证据的构建
根据各个证据的权重系统,将各个证据进行加权求和形成新证据;即新证据E
S7-3冲突证据的解决策略
用新证据E
4)证据融合
利用D-S证据理论合成规则融合替代后的证据,融合次数较证据数量少一次;
步骤8、输出结果
证据融合后的结果,即为故障诊断的结果。
作为一种优选的方案,所述柴油机的转速采样频率均为10Hz,油箱温度采样频率为1Hz,振动信号采样频率均为100Hz。
作为一种优选的方案,所述步骤3中对运行信号处理构造样本集时,针对船用柴油机的每种工作状态,振动信号从起始点开始取1024个数据作为一个样本,再取下1024个数据作为下一个样本,以此类推直至取到600个样本,对应船用柴油机的6种工作状态共取3600个样本;
针对船用柴油机的每种工作状态,柴油机的转速从起始点开始取1024个数据作为一个样本,移动步长t=100,再取1024个点作为下一个样本,以此类推直至取到600个样本,对应船用柴油机的6种工作状态共取3600个样本;
针对船用柴油机的每种工作状态,油箱温度从起始点开始取1024个数据作为一个样本,移动步长t=10,再取1024个点作为下一个样本,以此类推直至取到600个样本,对应船用柴油机的6种工作状态共取3600个样本;
针对船用柴油机的每种工作状态,柴油机的转速变化率、油箱温度变化率、油箱振动信号变化率每个样本取1024个数据,分别取3600个样本。
作为一种优选的方案,所述柴油机的转速、油箱温度、振动信号、柴油机的转速变化率、油箱温度变化率、油箱振动信号变化率的样本划分都采用样本训练集样本数:测试集样本数=7:3的比例。
作为一种优选的方案,所述深度学习模型包括输入层input1d、一维卷积层conv1d、一维最大池化层max_pooling1d、一维卷积层conv1d_1、一维最大池化层max_pooling1d_1、注意力机制模块层attention_layer、一维卷积层conv1d_2、一维最大池化层max_pooling1d_2、平铺层flatten_1。
输入层input1d尺寸大小为1024×1;一维卷积层conv1d的卷积核大小为7×1,卷积核数量为2,激活函数为ReLU,步长为1,填充方式为same;一维最大池化层max_pooling1d池化核大小为2×1,步长为2;一维卷积层conv1d_1的卷积核大小为5×1,卷积核数量为4,激活函数为ReLU,步长为1,填充方式为same;一维最大池化层max_pooling1d_1池化核大小为2×1,步长为2;注意力机制模块层attention_layer采用BahdanauAttention,一维卷积层conv1d_2的卷积核大小为3×1,卷积核数量为8,激活函数为ReLU,步长为1,填充方式为same;一维最大池化层max_pooling1d_2池化核大小为4×1,步长为4。
作为一种优选的方案,所述平铺层神经元数目为1016,丢弃层dropout的丢弃率为0.5,稠密层dense神经元数目为128,激化函数为ReLU,输出层output神经元数目为6,激活函数为Softmax。
本发明的有益效果是:
1.本发明在对船用柴油机故障诊断过程中,考虑了柴油机转速、油箱温度、柴油机振动、柴油机转速变化率、油箱温度变化率、柴油机振动变化率六种信号对于船用柴油机故障诊断准确率的影响,避免了目前船用柴油机故障诊断基于单一振动信号导致故障诊断准确率不高的缺陷。
2.本发明在采集柴油机转速、油箱温度、柴油机振动、柴油机转速变化率、油箱温度变化率、柴油机振动变化率六种信号,考虑了六种变量对时间变化的敏感性,采用不同的采样频率,既保证了采集数据的完整性,又减少了计算量。
3.本发明在进行船用柴油机故障诊断时,考虑时序数据的真实值,又考虑时序数据的变化量,相对于传统的仅基于时序数据的真实值,结果更准确。
4.本发明在进行船用柴油机故障诊断时,对基于每种信号的诊断结果进行证据融合,提高了故障诊断的准确率。
附图说明
图1是本实例的故障诊断步骤流程图
图2是深度学习模型1的结构图
具体实施方式
下面结合附图,详细描述本发明的具体实施方案。
如图1-2所示,本发明提出的基于证据融合理论和深度学习的船用柴油机故障诊断方法,其流程图如图1所示:
步骤1、建立运行信号集U和运行状态集V。
船用柴油机运行的监测数据包括柴油机的转速、油箱温度、振动信号,以监测参数以及其变化作为运行信号,建立运行信号集U={柴油机的转速、油箱温度、振动信号、柴油机的转速变化率、油箱温度变化率、油箱振动信号变化率};
船用柴油机可能出现的故障包括单缸失火、排气管泄露、压气机污阻、空滤器堵塞和润滑不良,建立运行状态集V={正常状态、单缸失火、排气管泄露、压气机污阻、空滤器堵塞和润滑不良};
步骤2:根据运行信号的自身特点,确定采样频率,采样频率不小于2倍的运行信号频率。这样对时间变化敏感的运行信号得到较大的采样频率,对时间变化不敏感的运行信号得到相对较小的采样频率。
对于本实施例船用柴油机的故障诊断,柴油机的转速对时间变化敏感,其采样频率均为10Hz,油箱温度对时间变化不敏感,其采样频率为1Hz,振动信号对时间变化特别,其采样频率均为100Hz。
步骤3:对运行信号处理,构造样本集;
振动信号,采样频率较大,采样的数据多,从采集起始点开始,连续512或1024个数据作为一个样本;柴油机的转速对时间变化敏感,其采样的数据多,采用重叠采样的方法来扩增数据样本数量,移动步长较大,取单个样本数据数的10%;油箱温度对时间变化不敏感,其采样的数据较少,采用重叠采样的方法来扩增数据样本数量,移动步长较小,取单个样本数据数的1%;柴油机的转速变化率、油箱温度变化率、油箱振动信号变化率分别采用相邻两个数据的差值。
对于本实施例船用柴油机的故障诊断,针对每种状态,振动信号从起始点开始取1024个数据作为一个样本,再取下1024个数据作为下一个样本,以此类推,每种状态下分别取600个样本,船用柴油机有6种状态,振动信号共取3600个样本;
柴油机的转速从起始点开始取1024个数据作为一个样本,移动步长t=100,再取1024个点作为下一个样本,以此类推,每种状态下分别取600个样本,船用柴油机有6种状态,共取3600个样本;
油箱温度从起始点开始取1024个数据作为一个样本,移动步长t=10,再取1024个点作为下一个样本,以此类推,每种状态下分别取600个样本,船用柴油机有6种状态,共取3600个样本;
柴油机的转速变化率、油箱温度变化率、油箱振动信号变化率每个样本取1024个数据,分别取3600个样本。
步骤4、对柴油机的转速、油箱温度、振动信号、柴油机的转速变化率、油箱温度变化率、油箱振动信号变化率分别构建以下故障诊断模型,设置故障诊断模型参数:
如图1所示,故障诊断模型包括结构相同的6个深度学习模型,柴油机的转速、油箱温度、振动信号、柴油机的转速变化率、油箱温度变化率、油箱振动信号变化率分别作为其中一个深度学习模型的输入;6个深度学习模型的输出分别为证据1至证据6,证据1至证据6作为证据融合模块的输入,证据融合的即为故障诊断的结果;
如图2所示,深度学习模型包括输入层input1d、一维卷积层conv1d、一维最大池化层max_pooling1d、一维卷积层conv1d_1、一维最大池化层max_pooling1d_1、注意力机制模块层attention_layer、一维卷积层conv1d_2、一维最大池化层max_pooling1d_2、平铺层flatten_1。
本实施例中,输入层input1d尺寸大小为1024×1;一维卷积层conv1d的卷积核大小为7×1,卷积核数量为2,激活函数为ReLU,步长为1,填充方式为same;一维最大池化层max_pooling1d池化核大小为2×1,步长为2;一维卷积层conv1d_1的卷积核大小为5×1,卷积核数量为4,激活函数为ReLU,步长为1,填充方式为same;一维最大池化层max_pooling1d_1池化核大小为2×1,步长为2;注意力机制模块层attention_layer采用BahdanauAttention,一维卷积层conv1d_2的卷积核大小为3×1,卷积核数量为8,激活函数为ReLU,步长为1,填充方式为same;一维最大池化层max_pooling1d_2池化核大小为4×1,步长为4。
本实施例中,平铺层神经元数目为1016,丢弃层dropout的丢弃率为0.5,稠密层dense神经元数目为128,激化函数为ReLU,输出层output神经元数目为6,激活函数为Softmax。
步骤5、训练故障诊断模型;
S5-1按照一定比例将数据样本划分成训练集与测试集;
在本实例中,每种状态有600个样本,共有6种状态,3600个样本以7:3比例划分,训练集样本数为2520,测试集样本数为180。
S5-2设置训练参数;
本实例中采用了Adam优化器来更新网络参数,模型训练时的Epoch、批次大小以及Adam算法的学习率分别为60、64、0.001。
S5-3模型训练;
采用随机方式,对故障诊断模型参数进行初始化,将训练集样本按批次输入故障诊断模型中进行模型训练,将测试样本输入训练好的故障诊断模型中进行测试,输出故障诊断准确率,以此来判断所提模型可行性。训练结束后保存训练好的故障诊断模型。
步骤6、构造证据;
每个深度学习模型的输出作为一条证据,本实施例共用六个深度学习模型,针对每个诊断,产生六个输出结果,即构造出六条证据记作E
步骤7、证据融合;
S7.1证据权重的构建
不同证据之间的欧氏距离越大,说明证据之间的差异度越大,证据之间的数值相似度越小,证据E
其中,
其中,i,j,k=1,2,…,6。
证据E
其中,i,j,k=1,2,…,6。
证据E
证据E
将其归一化处理后,得到各证据归一化后的总体相似度为
新的权重系数由证据间的数值相似度和方向相似度共同决定,可以有效避免当只采用数值相似度进行融合时可能会出现与实际情况不符的弊端,减小单一因素对证据权重判定产生的误差。
S7-2新证据的构建
根据各个证据的权重系统,将各个证据进行加权求和形成新证据。
即新证据E
S7-3冲突证据的解决策略
用新证据E
4)证据融合
利用D-S证据理论合成规则融合替代后的证据,本实施例共用6条证据,需要融合5次。
步骤8、输出结果
证据融合后的结果,即为故障诊断的结果。
本发明的效果可以通过以下对比实验进一步说明:
针对某船用柴油机长期运行的监测数据,分别针对柴油机转速、油箱温度、柴油机振动、柴油机转速变化率、油箱温度变化率、柴油机振动变化率的单一信号运用深度学习模型进行实验,以及分别采用传统的证据融合理论和本发明公开的证据融合理论进行融合,各个方法针对测试样本故障诊断准确率如下表1所示:
表1各个方法针对测试样本故障诊断准确率
上述的实施例仅例示性说明本发明创造的原理及其功效,以及部分运用的实施例,而非用于限制本发明;应当指出,对于本领域的普通技术人员来说,在不脱离本发明创造构思的前提下,还可以做出若干变形和改进,这些都属于本发明的保护范围。
- 基于调和贴近度和DS证据理论相结合的故障诊断决策融合方法
- 基于调和贴近度和DS证据理论相结合的故障诊断决策融合方法