内存故障的预测方法、电子设备和计算机可读存储介质
文献发布时间:2023-06-19 19:30:30
技术领域
本发明涉及大数据分析和人工智能技术领域,特别涉及一种内存故障的预测方法、电子设备和计算机可读存储介质。
背景技术
在服务器等大数据应用领域,非预期的内存故障导致计算机宕机频繁发生,情况严重的甚至导致服务器业务中断。因此,对于内存进行实时的故障预测和健康度评估对于维持业务的可靠性及稳定性具有重要的实用意义。
目前工业界对于内存故障风险的感知,采用的是对内存上报日志的进行简单加和统计:即错误检查和纠正(Error Checking and Correcting,简称:ECC)次数达到设定的阈值时,上报告警到网管。然而,实际上发生ECC次数和内存故障不存在极高的相关关系,仅靠对ECC计数来预测内存故障准确率很低。
发明内容
本申请实施例的主要目的在于提出一种内存故障的预测方法、电子设备和计算机可读存储介质,使得可以提高预测内存故障的准确性。
为实现上述目的,本申请实施例提供了一种内存故障的预测方法,包括:获取待测内存的多种日志数据;其中,所述多种日志数据至少包括:内存错误信息地址数据;根据所述多种日志数据进行特征工程构造,得到所述多种日志数据分别对应的特征数据表;对所述多种日志数据分别对应的特征数据表进行拼接,得到特征拼接数据表;根据所述特征拼接数据表和预训练的故障预测模型,得到所述待测内存的故障预测结果;其中,所述故障预测模型根据预先采集的训练数据集训练得到,所述训练数据集中的样本包括多种内存的多种日志数据。
为实现上述目的,本申请实施例还提供了一种电子设备,包括:至少一个处理器;以及,与所述至少一个处理器通信连接的存储器;其中,所述存储器存储有可被所述至少一个处理器执行的指令,所述指令被所述至少一个处理器执行,以使所述至少一个处理器能够执行上述的内存故障的预测方法。
为实现上述目的,本申请实施例还提供了一种计算机可读存储介质,存储有计算机程序,其特征在于,所述计算机程序被处理器执行时实现上述的内存故障的预测方法。
本申请实施例中,获取待测内存的多种日志数据,多种日志数据至少包括:内存错误信息地址数据,多种日志数据能够从多方面来衡量待测内存的状态,从而对故障预测提供更加全面的参考,以提高故障预测的准确性,多种日志数据至少包括内存错误信息地址数据,确保能够为故障预测提供必备的参考信息。通过对多种日志数据分别进行的特征工程构造,并对特征工程构造后的各种日志数据分别对应的特征数据表进行拼接,使得能够得到适合故障预测模型的输入的特征拼接数据表,从而可以根据特征拼接数据表和预训练的故障预测模型,得到待测内存的故障预测结果。由于故障预测模型的训练数据集中的样本包括多种内存的多种日志数据,因此故障预测模型的泛化能力和稳定性更强,从而基于该故障预测模型得到的预测结果也更加准确,即提高了预测内存故障的准确性。
附图说明
一个或多个实施例通过与之对应的附图中的图片进行示例性说明,这些示例性说明并不构成对实施例的限定,附图中具有相同参考数字标识的元件表示为类似的元件,除非有特别的申明,附图中的图不构成比例限制。
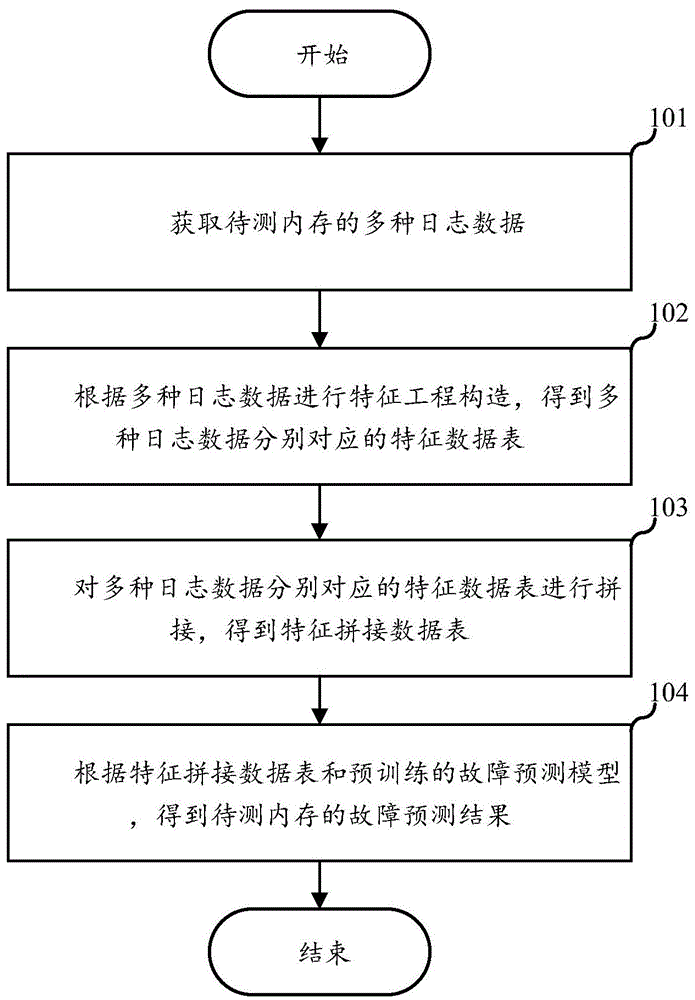
图1是根据本发明的一个实施例提供的一种内存故障的预测方法流程图;
图2是根据本发明的一个实施例提供的待测内存的架构图;
图3是根据本发明的一个实施例提供的获取多种日志数据的示意图;
图4是根据本发明的一个实施例提供的数据预处理流程图;
图5是根据本发明的一个实施例提供的获取内存错误信息地址数据对应的特征数据表的流程图;
图6是根据本发明的一个实施例提供的训练故障预测模型的流程图;
图7是根据本发明的一个实施例提供的二分类与回归方法的打标示意图;
图8是根据本发明的一个实施例提供的电子设备的结构图。
具体实施方式
为使本申请实施例的目的、技术方案和优点更加清楚,下面将结合附图对本申请的各实施例进行详细的阐述。然而,本领域的普通技术人员可以理解,在本申请各实施例中,为了使读者更好地理解本申请而提出了许多技术细节。但是,即使没有这些技术细节和基于以下各实施例的种种变化和修改,也可以实现本申请所要求保护的技术方案。以下各个实施例的划分是为了描述方便,不应对本申请的具体实现方式构成任何限定,各个实施例在不矛盾的前提下可以相互结合相互引用。
本申请的一个实施例涉及一种内存故障的预测方法,应用于电子设备,该电子设备可以为用于进行故障预测的服务器(简称预测服务器),比如,需要进行内存故障预测的待测设备采集自身的数据后,发送给预测服务器,然后由预测服务器进行待测设备的内存故障的预测。其中,待测设备可以为服务器、大数据中心集群、通讯基站、PC机等包含内存器件的设备。本实施例中,内存故障的预测方法的具体流程图可以如图1所示,包括:
步骤101:获取待测内存的多种日志数据;其中,多种日志数据至少包括:内存错误信息地址数据。
步骤102:根据多种日志数据进行特征工程构造,得到多种日志数据分别对应的特征数据表。
步骤103:对多种日志数据分别对应的特征数据表进行拼接,得到特征拼接数据表。
步骤104:根据特征拼接数据表和预训练的故障预测模型,得到待测内存的故障预测结果;其中,故障预测模型根据预先采集的训练数据集训练得到,训练数据集中的样本包括多种内存的多种日志数据。
在本实施例中,获取待测内存的多种日志数据,多种日志数据至少包括:内存错误信息地址数据,多种日志数据能够从多方面来衡量待测内存的状态,从而对故障预测提供更加全面的参考,以提高故障预测的准确性,多种日志数据至少包括内存错误信息地址数据,确保能够为故障预测提供必备的参考信息。通过对多种日志数据分别进行的特征工程构造,并对特征工程构造后的各种日志数据分别对应的特征数据表进行拼接,使得能够得到适合故障预测模型的输入的特征拼接数据表,从而可以根据特征拼接数据表和预训练的故障预测模型,得到待测内存的故障预测结果。由于故障预测模型的训练数据集中的样本包括多种内存的多种日志数据,因此故障预测模型的泛化能力和稳定性更强,从而基于该故障预测模型得到的预测结果也更加准确,即提高了预测内存故障的准确性。
下面对本实施方式的内存故障的预测方法的实现细节进行具体的说明,以下内容仅为方便理解提供的实现细节,并非实施本方案的必须。
在步骤101中,待测内存所在的服务器可以从待测内存中获取多种日志数据,并将多种日志数据发送给预测服务器,从而预测服务器可以获取到待测内存的多种日志数据。其中,多种日志数据至少包括:内存错误信息地址数据,确保能够为内存故障预测提供必备的参考信息。
其中,待测内存的架构图如图2所示,图2中左侧为待测内存中多个内存颗粒(chip)的示意图,图2中右侧为待测内存中的一个chip的示意图,一个chip在物理结构上分为8层,一层为一个bank。比如,图2中的bank 1可以表示该层为chip中的第一层,row为bank1上的一行,column为bank 1上的一列,row与column交汇的点为一个内存单元(cell)。
其中,获取的内存错误信息地址数据包括:内存序列号、内存制造商、日志上报时间、内存的双列直插式存储模块(Dual-Inline-Memory-Modules,简称“DIMM”)、内存rank号、内存chip号、内存bank信息、内存单元所在的行号、内存单元所在的列号。其中,内存错误信息地址数据还可以包括内存故障日志中解析出的发生内存故障的详细物理位置。
在一个实施例中,获取的多种日志数据在包括内存错误信息地址数据的情况下,还包括以下之一或多种组合:内存日志数据,操作系统内核日志、错误检测与纠正EDAC日志、性能数据、环境及位置信息数据。
其中,内存日志数据包括:寄存器组编号字段、事务transaction字段、内存序列号、内存制造商以及日志上报时间。
在一个例子中,内存日志数据为用mcelog工具采集mcelog上报的动态随机存储器(Dynamic Random Access Memory,DRAM)故障日志,mcelog工具是Linux系统基于Intel的机器检查架构(Machine Check Architecture,MCA)记录DRAM故障的标准工具,即内存日志数据可以为mcelog数据。
在一个例子中,操作系统内核日志可以记录从Linux内核日志中获取到的与内存故障相关的信息。操作系统内核日志包括:内存序列号、内存制造商、日志上报时间以及和内存错误相关的各类字段。
在一个例子中,错误检测与纠正(Error Detection and Correction,EDAC)日志包括:内存序列号、日志上报时间、内存控制器(Memory Controller,MC)字段、page字段和offset字段。其中,EDAC和ECC都是错误检测和纠正,ECC是内存硬件上的错误检测和纠正;EDAC是linux内核里面的软件上的错误检测和纠正。
在一个例子中,性能数据记录了待测内存所在的服务器相关的物理性能数据,包括:每秒将数据从磁盘传输到内存的次数page in、每秒将数据从内存传输到磁盘的次数page out、最低电压、最高电压、配置电压以及内存运行速度。
在一个例子中,环境及位置信息数据记录了待测内存所在的服务器的环境和位置信息,包括:温度、湿度、待测内存所在服务器的所在站点site、待测内存所在服务器的所在房间room以及待测内存所在服务器的所在机架rack。
在本实施例中,根据研究发现内存日志数据、操作系统内核日志、EDAC日志、性能数据、环境及位置信息数据均对内存故障有重要影响,这些数据的加入能提升故障预测模型的泛化能力的稳定性,有利于提高故障预测的准确率。
在一个实施例中,在实现步骤101时,待测内存所在的服务器可以同时获取待测内存中的6种日志数据,如图3所示,包括:mcelog数据、Linux内核日志数据、EDAC日志数据、性能数据、环境及位置信息数据、内存错误信息地址数据。
在步骤102中,在根据多种日志数据进行特征工程构造,得到多种日志数据分别对应的特征数据表之前,预测服务器可以对获取到的待测内存中的多种日志数据进行预处理,其中,预处理的内容可以包括:对多种日志数据中没有获取到的字段进行均值填充或0值填充;丢弃与内存故障不相关的字段;若多种日志数据中有某几列字段的相关性很强,则只留下其中一列字段,删除其他列的字段。
在一个例子中,对预处理后的多种日志数据还可以进行数据校验,具体为:校验数据的时间长度和采样点个数是否能够满足故障预测或故障预测所需数据量的最低条件要求,即数据采集时间是否满足特征工程构造所需时间长度,以及采集的多种日志数据中是否至少包括了内存错误信息地址数据。
在一个实施例中,步骤102对多种日志数据进行处理和特征工程构造,以得到多种日志数据分别对应的特征数据表的执行过程,可以通过以下子步骤实现,具体流程如图4所示,包括:
子步骤1021,对多种日志数据进行预处理。
其中,预处理可以包括:对空值进行“0”填充;对于采集到的多种日志数据用Pearson相关系数进行分析,删除掉字段间相关性强的列和数据没有变化或全为“0”的列,丢弃与内存故障不相关的字段。
子步骤1022,数据校验。
其中,数据校验可以包括:对预处理后的多种日志数据的时间长度和采样点个数进行校验。校验数据时间长度和采样点个数是否能够满足故障检测和预测的数据量最低条件要求:即数据采集时间是否满足特征工程构造所需时间长度,多种日志数据中是否至少包括内存错误信息地址数据。
子步骤1023,根据校验后的多种日志数据,分别进行特征工程构造。
在一个实施例中,预测服务器根据预处理后的内存错误信息地址数据进行特征构造,得到内存错误信息地址数据对应的特征数据表。参考图5,得到内存错误信息地址数据对应的特征数据表包括:
步骤501:统计第一数量和第一次数。其中,预测服务器根据内存错误信息地址数据,统计当前时间点前的第一预设时间段内出现的第一目标的第一数量以及每个第一目标上出现ECC的第一次数;其中,第一目标为过去第二预设时间段内,待测内存的各内存单元中累计出现过2次或2次以上ECC的内存单元,第二预设时间段的持续时长大于第一预设时间段的持续时长。
步骤502:统计第二数量和第二次数。其中,预测服务器根据内存错误信息地址数据,统计当前时间点之前的第三预设时间段内出现的第二目标的第二数量以及每个第二目标上出现ECC的第二次数;其中,第二目标为过去第四预设时间段内,待测内存的各列内存单元中在同一时刻累计出现2次或2次以上ECC的列,第四预设时间段的持续时长大于第三预设时间段的持续时长。其中,同一时刻可以是同一秒,也可以是同一分钟。
步骤503:统计第三数量和第三次数。其中,预测服务器根据内存错误信息地址数据,统计当前时间点之前的第五预设时间段内出现的第三目标的第三数量以及每个第三目标上出现ECC的第三次数;其中,第三目标为过去第六预设时间段内,待测内存的各行内存单元中在同一时刻累计出现2次或2次以上ECC的行,第六预设时间段的持续时长大于所述第五预设时间段的持续时长。
步骤504:统计第四数量。其中,预测服务器根据内存错误信息地址数据,统计当前时间点之前的第七预设时间段内出现的第四目标的第四数量;其中,第四目标为所述待测内存中由至少3个位于同一列的内存单元组成的内存单元块,至少3个位于同一列的内存单元在过去第八预设时间段内的同一时刻均出现ECC,且至少3个位于同一列的内存单元相互之间最多间隔1个内存单元,第八预设时间段的持续时长大于第七预设时间段的持续时长。
步骤505:统计第五数量。其中,预测服务器根据内存错误信息地址数据,统计当前时间点之前的第九预设时间段内出现的第五目标的第五数量;其中,第五目标为所述待测内存中由至少3个位于同一行的内存单元组成的内存单元块,至少3个位于同一行的内存单元在过去第十预设时间段内的同一时刻均出现ECC,且至少3个位于同一行的内存单元相互之间最多间隔1个内存单元,第十预设时间段的持续时长大于所述第九预设时间段的持续时长。
步骤506:获取内存错误信息地址数据对应的特征数据表。
根据以下之一或其任意组合,得到内存错误信息地址数据对应的特征数据表:第一数量、第一次数、第二数量、第二次数、第三数量、第三次数、第四数量、第五数量。
在步骤501中,第一预设时间段为当前时间点之前的一段时间,第一目标可以记为ERROR CELL,第一数量为当前时间点前的第一预设时间段内出现的第一目标ERROR CELL的数量,第一次数为当前时间点前的第一预设时间段内每个ERROR CELL上出现ECC的总次数,第二预设时间段为构造第一目标时所需的内存错误信息地址数据的采集时间长度。
在一个例子中,第二预设时间段可以为3个月,为了方便数据的拼接对齐,第一预设时间段可以取当前时间点前的整分钟粒度时间段,比如,第一预设时间段可以取当前时间点之前的8min、4min、2min、1min,即分别统计当前时间点之前的8min、4min、2min、1min内ERROR CELL上出现ECC的总次数(即上述的第一次数)及ECC对应的ERROR CELL个数(即上述的第一数量)。
在步骤502中,第二目标可以记为ERROR COLUMN,第二数量为当前时间点前的第三预设时间段内出现的第二目标ERROR COLUMN的数量,第二次数为当前时间点前的第三预设时间段内每个ERROR COLUMN上出现ECC的总次数,第四预设时间段为构造第二目标时所需的内存错误信息地址数据的采集时间长度。
在一个例子中,第四预设时间段可以为3个月,第三预设时间段可以取当前时间点之前的8min、4min、2min、1min,即分别统计当前时间点之前的8min、4min、2min、1min内ERROR COLUMN上出现ECC的总次数(即上述的第二次数)及ECC对应的ERROR COLUMN个数(即上述的第二数量)。
在步骤503中,第三目标可以记为ERROR ROW,第三数量为当前时间点前的第五预设时间段内出现的第三目标ERROR ROW的数量,第三次数为当前时间点前的第五预设时间段内每个ERROR ROW上出现ECC的总次数,第六预设时间段为构造第三目标时所需的内存错误信息地址数据的采集时间长度。
在一个例子中,第六预设时间段可以为3个月,第五预设时间段可以取当前时间点之前的8min、4min、2min、1min,即分别统计当前时间点之前的8min、4min、2min、1min内ERROR ROW上出现ECC的总次数(即上述的第三次数)及ECC对应的ERROR ROW个数(即上述的第三数量)。
在步骤504中,第四目标可以记为ERRORCOL BLOCK,第四数量为当前时间点前的第七预设时间段内出现的第四目标ERRORCOL BLOCK的数量,第八预设时间段为构造第四目标时所需的内存错误信息地址数据的采集时间长度。
在一个例子中,第八预设时间段可以为3个月,比如,在同一时刻如果同一列连续的5个内存单元中,有3个出现过ECC,即5个内存单元中,第1,3,5个内存单元出现过ECC,则这5个内存单元为一个ERRORCOL BLOCK。或者,在同一时刻如果同一列连续的3个内存单元均出现过ECC,则这3个内存单元为一个ERRORCOL BLOCK。第七预设时间段可以取当前时间点之前的8min、4min、2min、1min,即分别统计当前时间点之前的8min、4min、2min、1min内ERRORCOL BLOCK的数量(即上述的第四数量)。其中,同一时刻可以为同一秒或同一分钟。
在步骤505中,第五目标可以记为ERRORROW BLOCK,第五数量为当前时间点前的第九预设时间段内出现的第五目标ERRORROW BLOCK的数量,第十预设时间段为构造第五目标时所需的内存错误信息地址数据的采集时间长度。
在一个例子中,第十预设时间段可以为3个月,比如,在同一时刻如果同一行连续的5个内存单元中,有3个出现过ECC,即5个内存单元中,第1,3,5个内存单元出现过ECC,则这连续的5个内存单元为一个ERRORROW BLOCK。或者,在同一时刻如果同一行连续的3个内存单元均出现过ECC,则这3个内存单元为一个ERRORROW BLOCK。第九预设时间段可以取当前时间点之前的8min、4min、2min、1min,即分别统计当前时间点之前的8min、4min、2min、1min内ERRORROW BLOCK的数量(即上述的第五数量)。
需要说明的是,在上述步骤中,第一、三、五、七、九预设时间段可以相同,也可以不相同,第二,四、六、八、十预设时间段可以相同,也可以不相同。
在本实施例中,由于内存的故障在内存的行与列上具有传染性,通过构造第一目标ERROR CELL、第二目标ERROR COLUMN、第三目标ERROR ROW、第四目标ERROR COL BLOCK、第五目标ERROR ROW BLOCK等和内存缺陷相关的概念并进行相关数量和次数的统计,有利于准确的衡量内存故障,提升内存故障预测的准确率。
在一个实施例中,预测服务器根据多种日志数据进行特征构造,得到多种日志数据分别对应的特征数据表。其中,多种日志数据在包括内存错误信息地址数据的情况下,还包括以下之一或多种组合:内存日志数据,操作系统内核日志、错误检测与纠正EDAC日志、性能数据、环境及位置信息数据。通过对内存日志数据、操作系统内核日志、错误检测与纠正EDAC日志、性能数据、环境及位置信息数据等进行的精细化处理,得到每种日志数据分别对应的特征数据表,有利于提高故障预测的准确率。下面对获取多种日志数据分别对应的特征数据表进行具体说明:
在一个例子中,在多种日志数据还包括内存日志数据的情况下,根据内存日志数据,对当前时间点之前的第十一预设时间段内的事务transaction字段进行求和,得到transaction字段的求和结果,并对当前时间点之前的第十一预设时间段内的寄存器组编号字段进行计数,得到寄存器组编号字段的计数结果,然后根据transaction字段的求和结果和寄存器组编号字段的计数结果,得到内存日志数据对应的特征数据表。
在一个例子中,寄存器组编号字段可以为mca_bank字段,第十一预设时间段可以取8min、4min、2min、1min,即预测服务器可以对当前时间点之前的8min、4min、2min、1min内的mca_bank进行计数并对transaction字段进行求和作为新的特征列,该新的特征列即为内存日志数据对应的特征数据表中的特征列。
比如,当前时间为10:27,则当前时间点之前的1min内的数据为10:26-10:27这段时间内采集的数据,然后对10:26-10:27这段时间内采集的mca_bank字段进行计数、transaction字段进行求和;当前时间点之前的2min内的数据为10:25-10:27这段时间内采集的数据;当前时间点之前的4min内的数据为10:23-10:27这段时间内采集的数据;当前时间点之前的8min内的数据为10:19-10:27这段时间内采集的数据。
具体实现中,由于寄存器组编号字段为mcelog工具从内存中抓取的寄存器组编号,其数据类型为字符串类型,因此可以进行计数;而transaction字段为CPU和内存互相传送的一组操作,包含读事务和写事务,其数据类型为整型,对transaction字段进行求和更能够反映出该字段的数据特征,只进行计数会丢掉transaction字段中的数据信息,因此,需要对transaction字段进行求和。
在一个例子中,在多种日志数据还包括操作系统内核日志的情况下,统计操作系统内核日志中和内存错误相关的各类字段,对当前时间点之前的第十二预设时间段内的各类字段进行计数,得到各类字段分别对应的计数结果,然后根据各类字段分别对应的计数结果,得到操作系统内核日志对应的特征数据表。
其中,可以按照整分钟粒度对第十二预设时间段内和内存错误相关的各类字段进行统计,比如,第十二预设时间段取8min、4min、2min、1min时,即预测服务器可以对当前时间点前8min、4min、2min、1min内和内存错误相关的各类字段进行计数作为新的特征列,该新的特征列即为操作系统内核日志对应的特征数据表中的特征列。
具体实现中,由于在操作系统内核日志中有24类字段,其中有8类字段与内存错误相关,因此,只需对当前时间点之前的第十二预设时间段内的8类与内存错误相关的字段进行计数,得到8类与内存错误相关字段的计数结果,然后根据这8类与内存错误相关字段分别对应的计数结果,得到操作系统内核日志对应的特征数据表。
在一个例子中,在多种日志数据还包括EDAC日志的情况下,根据EDAC日志,对当前时间点之前的第十三预设时间段内的MC字段、page字段、offest字段进行计数,得到MC字段的计数结果、page字段的计数结果、offset字段的计数结果,然后根据MC字段的计数结果、page字段的计数结果、offset字段的计数结果,得到EDAC日志对应的特征数据表。其中,MC字段表示内存控制器的编号,page表示虚拟内存的页,offset表示偏移量,page+offset可以计算出内存的物理地址。
其中,可以按照整分钟粒度对第十三预设时间段内的字段(MC、page、offset)进行统计,比如,第十三预设时间段取8min、4min、2min、1min,即预测服务器可以对当前时间点前8min、4min、2min、1min内的字段(MC、page、offset)进行计数作为新的特征列。该新的特征列即为EDAC日志对应的特征数据表中的特征列。
在一个例子中,在多种日志数据还包括性能数据的情况下,根据性能数据,对当前时间点之前的第十四预设时间段内影响内存故障的各类性能数据进行平均计算,得到各类性能数据的平均值,根据各类性能数据的平均值,得到性能数据对应的特征数据表。
其中,可以按照整分钟粒度对第十四预设时间段内的字段(Page_in、page_out、最低电压、最高电压、配置电压、内存运行速度)进行统计,比如,第十四预设时间段取8min、4min、2min、1min,即预测服务器可以对当前时间点前8min、4min、2min、1min内和性能数据相关的字段进行平均计算作为新的特征列。
具体实现中,对当前时间点之前的第十四预设时间段内的page in、page out、最低电压、最高电压、配置电压以及内存运行速度进行平均计算,分别得到page in、pageout、最低电压、最高电压、配置电压以及内存运行速度的平均值,然后根据这些平均值,得到性能数据对应的特征数据表。
在一个例子中,在多种日志数据还包括环境及位置信息数据的情况下,根据环境及位置信息数据,对当前时间点之前的第十五预设时间段内的温度和湿度进行平均计算,得到温度的平均值和所述湿度的平均值,根据温度的平均值和所述湿度的平均值,得到环境及位置信息数据对应的特征数据表。
其中,可以按照整分钟粒度对第十五预设时间段内的字段(比如温度、湿度)进行统计,比如第十五预设时间段取8min、4min、2min、1min,即预测服务器可以将对前时间点前8min、4min、2min、1min内温度、湿度等和环境数据相关的字段进行平均计算作为新的特征列,该新的特征列即为环境及位置信息数据对应的特征数据表中的特征列。然后该待测内存再对应上所在服务器的site、room、rack等位置信息。
需要说明的是,在具体实现中,上述第十一、十二、十三、十四、十五预设时间段可以相同也可以不同,本实施例对此不作具体限定。
在一个实施例中,步骤101中预测服务器可以按整分钟粒度获取待测内存的多种日志数据,步骤102中进行特征工程构造可以包括:当获取到距离当前时间点最近的m分钟内的多种日志数据,将m分钟内的多种日志数据和m分钟之前的n分钟之内的多种日志数据进行合并,并将合并后的多种日志数据作为在当前时间点进行故障预测所需的日志数据;其中,n+m分钟为预设的进行故障预测所需的最短时长。根据在当前时间点进行故障预测所需的日志数据进行分钟粒度的特征工程构造,得到多种日志数据分别对应的特征数据表。比如,m的取值可以为1、10、0.1等。以分钟粒度获取日志数据,有利于完成分钟级的预测,做到对内存状态的实时监控,提高内存的故障预测的实时性。
在一个例子中,m的取值为1,n可以取值为7,具体地,若获取到距离当前时间点最近的1分钟内的多种日志数据,而满足8分钟的多种日志数据才能进行故障预测,即8分钟为预设的进行故障预测所需的最短时长,则在到达第9分钟时可以将获取到的第9分钟的多种日志数据与前7分钟之内获取的多种日志数据合并,并将合并后的多种日志数据作为在第9分钟进行故障预测所需的多种日志数据。比如,当前的时间为10:27,若获取到10:27之前的1分钟内的多种日志数据,即10:26-10:27之间的多种日志数据,而需要10:19-10:27这8分钟内的多种日志数据才能进行故障预测,则将10:26-10:27这1分钟与10:19-10:26这7分钟获取到的多种日志数据合并,并将合并后的8分钟的数据作为在10:27进行故障预测所需的多种日志数据。
在步骤103中,对待测内存的多种日志数据进行特征构造,分别得到对应的特征数据表后,对内存错误信息地址数据对应的特征数据表和以下特征数据表之一或多个任意组合按照内存序列号、整分钟粒度进行拼接:内存日志数据对应的特征数据表、操作系统内核日志对应的特征数据表、性能数据对应的特征数据表、环境及位置信息数据对应的特征数据表,得到特征拼接数据表。
在步骤104中,多种内存所在的服务器预先会采集多种内存的多种日志数据,预测服务器根据多种日志数据进行特征工程构造,得到多种日志数据分别对应的特征数据表,并拼接多种日志数据分别对应的特征数据表得到特征拼接数据表,以特征拼接数据表作为训练数据集中的样本进行模型训练,得到预训练的故障预测模型。训练得到故障预测模型后,则可以根据该故障预测模型对待测内存进行故障预测。
在一个实施例中,故障预测模型根据预先采集的训练数据集和LightGBM机器学习方法训练得到,其中,LightGBM机器学习方法的损失函数为Focal Loss,Focal Loss公式为:
其中,α为平衡因子,γ为调制参数,y′为样本预测值,y为样本标签,L
具体实现中,由于内存的故障预测会面临正负样本不均衡的问题,正常的内存数据远大于发生故障的内存数据,而Focal Loss损失函数是专门用于处理正负样本不均衡的问题的函数,因此,采用LightGBM机器学习方法建立训练模型时,采用Focal Loss损失函数,能够有效的解决故障预测模型的训练数据集中正负样本不均衡的问题,保证了在进行内存故障预测时的准确率。
在一个实施例中,训练数据集中的样本均标注有标签值,标签值通过二值方式确定,比如,如果某个时间点的样本为内存故障的样本,则从该时间点往前推T分钟,这T分钟内的样本标注为“1”,T分钟之前的样本标注为“0”;其中,T的取值可以为30-100,比如可以取90。也就是说,虽然这是一个故障内存,但90分钟前还没有达到风险的界点,认为还算是正常的数据。基于采用二值方式标注的样本训练得到的故障预测模型,如果该故障预测模型的输出结果为“1”,则表示待测内存在未来T段时间内可能会发生故障;若故障预测模型的输出结果为“0”,则表示待测内存为正常内存。
在一个实施例中,训练数据集中的样本均标注有标签值,标签值通过回归方式确定,比如:计算每个样本对应的时间点距离发生内存故障的样本对应的时间点之间的时间间隔;根据时间间隔和用于将时间间隔映射到[0,1]区间内的计算公式,计算每个样本的标签值;其中,计算公式为:
其中,label为计算的标签值,X为时间间隔,a为第一预设系数,T为预设的故障影响时长。采用回归方式进行打标签,避免采用二值方式打标签这种一刀切的情况造成的数据损失,标签值可以体现数据距离发生故障的远近程度,更加贴近真实性。
具体实现中,训练数据集中的样本会采用变型的sigmiod函数将时间间隔映射到[0,1]区间内,计算每个样本的标签值,使用sigmiod函数可以预测出待测内存发生故障的时间点,以判断标签距离故障的时间点的程度。其中,第一预设系数a为一个经验值,取值范围为[1,10],比如可以取8;X/T的取值范围为[0,1]。
在一个实施例中,根据特征拼接数据表和预训练的故障预测模型,得到故障预测模型的输出结果后,可以根据输出结果和用于预测故障发生时间点的时间公式,得到待测内存发生故障的时间点的预测结果;
其中,时间公式为:
其中,t为待测内存发生故障的时间点,b为第二预设系数,output为输出结果,T为预设的故障影响时长。不仅能预测未来是否会发生故障,还能预测具体在什么时间发生故障,预测的精准性更高。
其中,故障预测模型的输出结果的取值范围为[0,1],第二预设系数为一个经验值,取值范围为[1,20],比如可以取11.25。
在一个例子中,a*b=T,比如,当a=8,b=11.25,即a*b=8*11.25=90,则预设的故障影响时长T=90。
在一个实施例中,步骤104中故障预测模型可以通过如图6所示的方式得,包括:
步骤601,对训练数据集中的样本进行标注,得到各样本的标签值。
步骤602,根据标注有标签值的各样本,进行模型训练得到故障预测模型。
步骤603,对故障预测模型进行评估。
其中,训练数据集的形成方式可以为:
S1:采集不同数据中心、厂商、型号的内存相关日志数据(比如上述的6种日志数据);
S2:对日志数据进行特征工程构造,得到多种日志数据分别对应的特征数据表;
S3:将多种日志数据分别对应的特征数据表拼接,形成训练数据集。
在S2中,多种日志数据包括内存错误信息地址数据的情况下,为了获取内存错误信息地址数据对应的特征数据表,使其作为故障预测模型的训练数据集样本,供预测服务器建立故障预测模型,可以根据S1中得到的内存错误信息地址数据这一种日志数据进行特征工程构造。其中,根据内存错误信息地址数据进行特征工程构造的方式,可以参考图5中的方式,为避免重复,此处不再赘述。
在S2中,多种日志数据还包括内存日志数据、操作系统内核日志、性能数据、环境及位置信息数据的情况下,为了获取内存日志数据对应的特征数据表、操作系统内核日志对应的特征数据表、性能数据对应的特征数据表、环境及位置信息数据对应的特征数据表,使其作为故障预测模型的训练数据集样本,供预测服务器建立故障预测模型,因此,可以根据S1中得到的内存日志数据,操作系统内核日志、错误检测与纠正EDAC日志、性能数据、环境及位置信息数据等日志数据进行特征工程构造。其中,特征工程构造的方式在上文已经描述过,为避免重复,此处不再赘述。
在一个例子中,步骤601可以采用二分类法(即上述的二值方式)对训练数据集中的样本进行标注,具体地,二分类的标签-时间关系图如图7中的虚线Classification所示,横坐标为待测内存发生故障前的一段时间,纵坐标为利用二分类方法标注的标签值。其中,若预设的故障影响时长T为90分钟,则对于二分类方法,预测服务器会将训练数据集中的样本中发生故障的前90分钟内的样本的标签值都标注为“1”,90分钟之前的样本的标签值标注为“0”。
在另一个例子中,步骤601可以采用回归方式对训练数据集中的样本进行标注,具体地,回归模型的标签-时间关系图如图7中的实线Regression所示,横坐标为待测内存发生故障前的一段时间,纵坐标为利用回归方法标注的标签值。其中,若预设的故障影响时长T为90分钟,则对于回归方法,预测服务器会通过如下变型的sigmoid函数将时间间隔映射到[0,1]区间内:
其中,label为计算的标签值,X为时间间隔。对于正常的内存数据X定为+∞,label则为0。
在一个例子中,步骤602可以采用LightGBM对标注有标签值的各样本进行训练建模,损失函数可以使用均方误差(Mean Square Error,MSE)损失函数或Focal Loss损失函数。
在另一个例子中,步骤602可以采用随机森林对标注有标签值的各样本进行训练建模。
在步骤603中,在训练数据集中随机抽取30%的样本数据作为验证集,剩下样本数据作为训练集。
在一个例子中,模型的评价指标可以采用F1-Score指标,即使用F1-Score指标在验证集上进行评估。其中,F1-Score指标的定义相关术语和详细指标如下,其中precision为精准率,recall为召回率:
n
n
n
其中,可以对模型相关参数采用网格搜索使得模型评分F1达到最高点。
在一个实施例中,根据特征拼接数据表和预训练的故障预测模型,得到待测内存的故障预测结果,包括:根据特征拼接数据表和预训练的故障预测模型,得到将待测内存分类为1的置信度;根据置信度,确定待测内存的健康度;其中,健康度为1-置信度,健康度越低,待测内存越容易发生故障。也就是说,如果采用二分类法对训练数据集中的样本进行标注,则通过图6中的方式得到的故障预测模型的输出结果为:机器学习算法将待测内存分类为“1”的置信度(范围为0-100%),从而可以根据置信度,确定待测内存的健康度,最后将健康度指标上报到监控中心。
在一个实施例中,根据特征拼接数据表和预训练的故障预测模型,得到待测内存的故障预测结果,包括:根据特征拼接数据表和预训练的故障预测模型,得到对待测内存的预测值;其中,预测值为0-1之间的浮点数;根据预测值,确定待测内存的健康度;其中,健康度为1-预测值,健康度越低,待测内存越容易发生故障。也就是说,如果采用回归法对训练数据集中的样本进行标注,预测服务器会通过如下变型的sigmoid函数将时间间隔映射到[0,1]区间内:
其中,label为计算的标签值,X为时间间隔。对于正常的内存数据X定为+∞,label则为0。通过图6中的方式得到的故障预测模型的输出结果为:[0,1]之间的浮点数。一般地,如果输出结果大于0.5,则代表在未来T时间内会发生内存故障;否则,代表未来T时间内会不发生内存故障。将输出结果转换为0-100%的健康度。其中,输出结果即为通过机器学习算法对待测内存进行故障预测的预测值(范围为0-1),待测内存的健康度为1-预测值。健康度越低,代表内存发生在T时间内发生故障的概率越高,最后将健康度指标上报到监控中心。
在一个实施例中,如果采用回归法对训练数据集中的样本进行标注,则通过图6中的方式得到的故障预测模型的预测结果可以为:将会发生内存故障的时间点。比如在建立故障预测模型时,损失函数使用MSE损失函数,通过如下公式可以得到将会发生内存故障的时间点:
最后,预测服务器可以将计算得到的发生内存故障的时间点上报到监控中心,以便监控中心采取相应操作。
需要说明的是,本实施方式中的上述各示例均为为方便理解进行的举例说明,并不对本发明的技术方案构成限定。
上面各种方法的步骤划分,只是为了描述清楚,实现时可以合并为一个步骤或者对某些步骤进行拆分,分解为多个步骤,只要包括相同的逻辑关系,都在本专利的保护范围内;对算法中或者流程中添加无关紧要的修改或者引入无关紧要的设计,但不改变其算法和流程的核心设计都在该专利的保护范围内。
本发明的另一个实施例涉及一种电子设备,如图8所示,包括至少一个处理器801;以及,与至少一个处理器801通信连接的存储器802;其中,存储器802存储有可被至少一个处理器801执行的指令,指令被至少一个处理器801执行,以使至少一个处理器801能够执行上述实施例的内存故障的预测方法。
其中,存储器802和处理器801采用总线方式连接,总线可以包括任意数量的互联的总线和桥,总线将一个或多个处理器801和存储器802的各种电路连接在一起。总线还可以将诸如外围设备、稳压器和功率管理电路等之类的各种其他电路连接在一起,这些都是本领域所公知的,因此,本文不再对其进行进一步描述。总线接口在总线和收发机之间提供接口。收发机可以是一个元件,也可以是多个元件,比如多个接收器和发送器,提供用于在传输介质上与各种其他装置通信的单元。经处理器801处理的数据通过天线在无线介质上进行传输,进一步,天线还接收数据并将数据传送给处理器801。
处理器801负责管理总线和通常的处理,还可以提供各种功能,包括定时,外围接口,电压调节、电源管理以及其他控制功能。而存储器802可以被用于存储处理器801在执行操作时所使用的数据。
本发明的另一个实施例涉及一种计算机可读存储介质,存储有计算机程序。计算机程序被处理器执行时实现上述方法实施例。
即,本领域技术人员可以理解,实现上述实施例方法中的全部或部分步骤是可以通过程序来指令相关的硬件来完成,该程序存储在一个存储介质中,包括若干指令用以使得一个设备(可以是单片机,芯片等)或处理器(processor)执行本申请各个实施例所述方法的全部或部分步骤。而前述的存储介质包括:U盘、移动硬盘、只读存储器(ROM,Read-OnlyMemory)、随机存取存储器(RAM,Random Access Memory)、磁碟或者光盘等各种可以存储程序代码的介质。
本领域的普通技术人员可以理解,上述各实施方式是实现本发明的具体实施例,而在实际应用中,可以在形式上和细节上对其作各种改变,而不偏离本发明的精神和范围。
- 预测方法、装置、电子设备及计算机可读存储介质
- 一种基于机器学习预测内存故障的方法,设备及可读存储介质
- 模态框构建方法、装置、电子设备、计算机可读存储介质
- 电子设备、音量调节方法及装置、计算机可读存储介质
- 数据库同步恢复方法、装置、计算机可读存储介质和电子设备
- 内存故障处理方法和装置、电子设备及计算机可读存储介质
- 故障预测方法、装置、电子设备及计算机可读存储介质