基于平均教师模型的半监督肺叶分割方法
文献发布时间:2023-06-19 19:30:30
技术领域
本发明涉及一种基于平均教师模型的半监督肺叶分割方法,属于医学图像处理领域。
背景技术
人类的肺分为五个叶,五个肺叶中的每一个叶功能独立,分别为血管和气道提供不同的供应分支。这些叶的识别在疾病评估和治疗计划中具有重要应用。许多肺部疾病在肺叶水平起作用。五个肺叶的准确分割对于COPD和纤维化等肺部疾病的诊断、治疗计划和监测都非常重要。因此在肺叶水平测量肺部疾病对于疾病表型和评估其严重程度具有重要的临床意义,肺叶分割在手术治疗计划中有进一步的应用。确定肺叶的位置、形状和体积对于规划调查和外科手术非常重要。
计算机断层扫描(CT)在肺部疾病的诊断中起着十分重要的作用。随着深度学习的不断发展,研究者们开始借助深度学习,实现对CT图像中的肺叶进行自动分割。基于卷积运算的神经网络系统,即卷积神经网络是深度学习中最常用的方法之一。
卷积神经网络(Convolutional Neural Network,CNN)是一种前馈型的神经网络,由于其网络结构特征,在图像处理特别是大型图像处理方面的性能优越,因此,在图像识别、目标检测等应用中,卷积神经网络得到了大规模的使用。卷积神经网络在计算量上相较于其他网络结构有着明显优势,也因此得到了广泛的应用。本发明选用的是U-Net网络,适合我们对CT图像进行处理,是一个全卷积神经网络,能够实现端到端的3D图像分割。
监督式深度学习为了训练具有良好泛化能力的模型,需要大量的像素级注释数据集,这是医学图像分析中难以满足的条件。因此我们决定利用未标记的数据对比学习全局和局部特征,进行自我监督学习(Self-supervised learning)对神经网络进行预训练,然后利用有限的注释并通过知识蒸馏微调预训练的网络,提高准确度。
对比学习是自监督学习的一种方法,用于在没有标签的情况下,通过让模型学习哪些数据点相似或不同来学习数据集的一般特征。对比学习方法使用对比损失来强制表示对于相似的对是相似的,对于不同的对是不同的。图像的不同变换应该具有相似的表示,并且这些表示应该与不同图像的表示不同。利用医学图像之间的结构相似性和局部对比损失,来学习对像素分割有用的局部区域的独特表示。
知识蒸馏(Knowledge Distillation)是指通过引入与教师网络相关的软目标作为总损失的一部分,以诱导学生网络的训练,实现知识迁移。教师网络(Teacher network)复杂、但预测精度优越;而学生网络(Student network)精简、低复杂度,更适合推理部署。
发明内容
为了克服现有研究的不足,为了设计先进的平均教师模型来更好的利用未标记数据,以完成有效的半监督学习图像编解码工作。将U-Net作为平均教师模型中的教师网络和学生网络的主干。首先,利用对比学习使网络学习到未标记数据的全局和局部特征结构信息,通过最小化对比损失来预训练平均教师模型中的教师网络和学生网络。接着,通过给定不同小扰动的样本,迫使来自两个网络的预测趋于一致。最后利用有限的标记数据微调平均教师模型。本发明提供了一种基于平均教师模型的半监督肺叶分割方法。
一种基于半监督平均教师模型的肺叶分割方法,具体包括:
获取少部分三维肺部CT图像以及对应的肺叶掩膜以及大量未标记肺部CT图像;
使用对比学习获取未标记的数据的医学图像结构相似性和局部区域的独特表示,以此对主干网络,即对U-Net网络进行预训练;再利用有限的注释对分割网络结构进行微调;
使用平均教师模型,通过知识蒸馏提高网络分割准确性,以便进一步优化网络结构,降低损失;
该框架由教师网络和学生网络组成,在小扰动下鼓励两个网络在特征和语义层面上保持一致。未标记数据经过数据增强之后输入教师模型,所有样本的预测结果求取平均之后作为这批未标记数据的伪标签输入学生模型。强制学生模型和教师模型在语义层面趋于一致。所述基于平均教师模型的半监督肺叶分割网络包括:
采用U-Net作为教师网络和学生网络的实例分割模型主干。数据增广后的未标记数据经过教师模型得到的平均预测作为伪标签再次送入学生网络,以达到利用未标记数据中的隐藏信息来提高网络性能的目的。标记数据也用于学生网络,微调网络参数来优化网络模型。
获取大量三维CT图像,分别标记好部分数据中每个叶的标签,从而得到一个用于肺叶分割任务的含有少量标记数据以及大量未标记数据的CT图像作为肺叶掩膜的数据集。
搭建基于平均教师模型的肺叶分割网络,教师网络和学生网络均以单个CT实例图像为输入,输出与输入相同分辨率大小的肺叶掩膜图像。利用对比学习预训练U-Net编码器-解码器架构并将此作为教师网络和学生网络的主干。
优选地,所述平均教师模型肺叶分割网络具体包括一下特征:
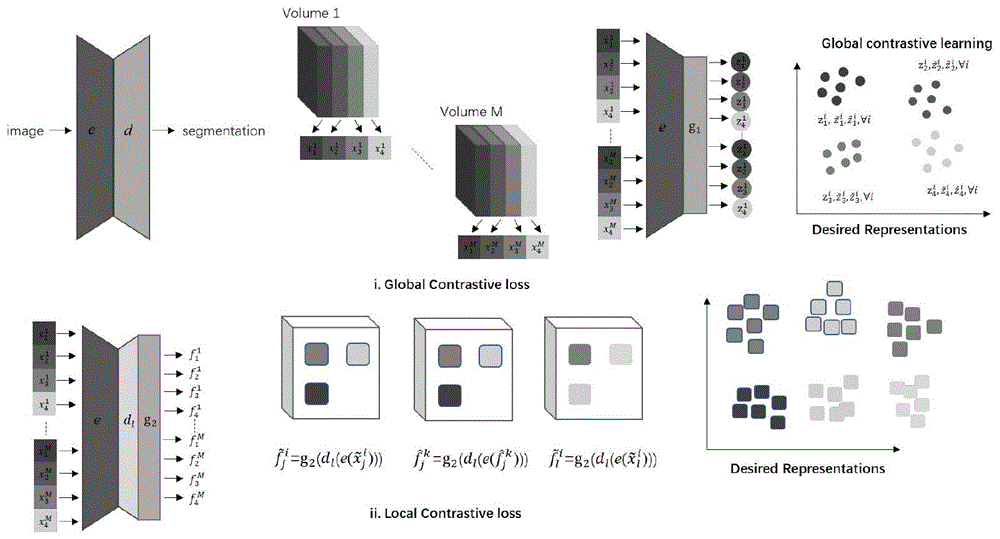
1.利用全局和局部对比损失进行总体预训练。先使用全局对比损失L
2.使用全局对比损失对编码器e进行训练。
对于给定的编码器网络e(·),对比损失定义为:
最小化损失
使用上述损失,将全局对比损失定义为:
其中,Λ
使用局部对比损失L
给定相似对的局部对比损失定义为:
一组图像的总局部对比损失可以定义为:
3.所述U-Net结构由编码器和解码器构成,编码器有四个块。解码器网络建立在从编码器网络获得的表示上,具有编码器网络的转置架构。在最后一层,输出维度等于CT图像的输入空间分辨率,通道数等于分割类别的数量。预训练过的U-Net结构作为平均教师模型中教师网络和学生网络的主干。
4.教师模型的输入只有未标记数据,未标记数据经过数据增强之后,所有样本的预测结果求取平均之后作为这批未标记数据的伪标签输入学生模型。
计算K个扩增样本的平均预测,以在教师网路中生成伪标签:
锐化函数
5.通过掩膜引导的蒸馏损失来最小化特征距离,从而提高一致性:
6.计算总损失:
L
λt是一个分段权重函数,它保证在开始时由L
其中T是总迭代次数。
通过使全局和局部对比损失最小化来对U-Net网络进行预训练。先使用全局对比损失L
利用不同体积块中相应切片之间的相似性,捕获相似区域的全局损失;再利用不同的局部表示来区分相邻区域,表示为局部损失。先利用未标记数据通过最小化全局损失和局部损失来预训练U-Net中的编码器以及l个解码块,剩余的解码块由标记数据来调整。
U-Net分割网络,用于端到端地对CT图像进行分割处理,得到一张与输入大小一致的分割掩膜图像。
将预训练的网络模型作为平均教师模型中教师网络和学生网络的主干,取教师模型对未标记数据的平均预测作为学生模型的伪标签,通过掩膜引导的蒸馏损失来最小化特征距离,从而提高学生模型和教师模型的一致性。
利用学生网络中的指数移动平均(EMA)权重来更新教师模型的网络参数。
与现有技术相比,本发明的有益效果在于:
本发明是一种结合了对比损失、平均教师模型的半监督肺叶分割方法。首先,利用全局和局部对比损失进行总体预训练。使用全局对比损失L
附图说明
为了更清楚地说明本发明实施例或现有技术中的技术方案,下面将对实施例或现有技术描述中所需要使用的附图作简单地介绍,显而易见地,下面描述中的附图仅仅是本发明的一些实施例,对于本领域普通技术人员来讲,在不付出创造性劳动的前提下,还可以根据这些附图获得其他的附图。
图1为本发明基于对比损失的U-Net预训练方法的流程图;
图2为本发明U-Net的网络结构图;
图3为本发明基于平均教师模型的半监督肺叶分割方法的流程图。
具体实施方式
下面将结合本发明实施例中的附图,对本发明实施例中的技术方案进行清楚、完整地描述,显然,所描述的实施例仅仅是本发明一部分实施例,而不是全部的实施例。基于本发明中的实施例,本领域普通技术人员在没有做出创造性劳动前提下所获得的所有其他实施例,都属于本发明保护的范围。
本发明基于平均教师模型的半监督肺叶分割网络的流程图,参见图3,具体包括以下步骤:
步骤S1:准备三维肺部CT图像数据集,包括少量CT图以及对应的肺叶分割掩膜和大量没有数据标注的CT图;
步骤S11:所有的标记数据和未标记数据的CT图都预先使用线性配准工具,是所有的数据粗略对齐;
步骤S12:将获取肺叶标签的CT图像作为标记数据,按一定比例划分训练集和验证集,建立标注文件用于存放图像分类数据;
步骤S13:本实施例将所有CT图像中单个切片的图像尺寸都是512*512,无需进行预处理裁剪;不同CT图的切片数会有一些差别,对实验结果不会有太大影响。
步骤S2:利用全局和局部对比损失进行总体预训练。
步骤S21:对于给定的编码器网络e(·),对比损失定义为:
这里,
使用上述损失,将全局对比损失定义为:
其中,Λ
步骤S22:使用局部对比损失L
对的集合Ω
其中sim(.,.)是前面定义的余弦相似度,u,v索引特征图中的局部区域。一组图像的总局部对比损失可以定义为:
其中,
步骤S23:首先,使用全局对比损失L
步骤S3:预训练后的编码器-解码器网络U-Net,分别作为平均教师模型中教师网络和学生网络的主干。具体步骤如下:
步骤S31:CT图像为天然的三维扫描图像,可以看成是由若干二维图像的堆叠而成,将此处的二维图像定义为切片,在CT图像中,单张CT切片类似于自然图像中的灰度图像,属于单通道图像。采用U-Net全卷积神经网络作为二维图像分类网络;
步骤S32:平均教师模型的结构图如图3所示,在此对网络结构进一步进行说明:
U-Net分为压缩路径(contracting path)和扩展路径(expansive path)。压缩路径也就是编码器由4个block组成,每个block使用了多个有效卷积和1个Max Pooling降采样,有的block采用2个卷积有的block采用3个卷积,每次降采样之后Feature Map的个数乘2。扩展路径也就是解码器同样由4个block组成,每个block开始之前通过反卷积将FeatureMap的尺寸乘2,同时将其个数减半(最后一层略有不同),然后和左侧对称的压缩路径的Feature Map合并,由于左侧压缩路径和右侧扩展路径的Feature Map的尺寸不一样,U-Net是通过将压缩路径的Feature Map裁剪到和扩展路径相同尺寸的Feature Map进行归一化的(即图2中灰色箭头部分),称之为concatenation操作。由于该任务是一个多分类任务,所以网络最后的输出根据最终所得的分类数决定,在这里应该是6(五个肺叶加上背景)。
步骤S4:教师模型的输入只有未标记数据,未标记数据经过数据增强之后,所有样本的预测结果求取平均之后作为这批未标记数据的伪标签输入学生模型。强制学生模型和教师模型在语义层面趋于一致。
步骤S41:计算K个扩增样本的平均预测,以在教师网路中生成伪标签:
其中,f
锐化函数
步骤S42:通过掩膜引导的蒸馏损失来最小化特征距离,从而提高一致性:
/>
M
步骤S43:使用学生网络中的指数移动平均(EMA)权重来更新教师模型的网络参数,表示如下:
θ′
步骤S5:计算总损失:
L
λ(t)是一个分段权重函数,它保证在开始时由L
其中T是总迭代次数;
以上结合附图对本发明的实施方式作了详细说明,但本发明不限于所描述的实施方式。对于本领域的技术人员而言,在不脱离本发明原理和精神的情况下,对这些实施方式进行多种变化、修改、替换和变型,仍落入本发明的保护范围内。
- 基于半监督平均教师模型的冠脉造影血管图像分割方法
- 一种基于平均教师模型的半监督视频段落定位方法