一种恒温恒湿空调系统预测优化控制算法及装置
文献发布时间:2023-06-19 19:30:30
技术领域
本发明涉及人工智能技术领域,具体为一种恒温恒湿空调系统预测优化控制算法及装置。
背景技术
在实际生产生活中,许多场所对环境的温度和湿度有着非常高的要求,需要严格控制温度和湿度的波动范围,恒温恒湿空调系统被广泛应用在这类场所中。
在传统的控制方法中,恒温恒湿空调系统通常定风量运行,而在定风量系统中,送风量以最大负荷计算,当系统处于部分负荷工况下,必然导致送风温度过低,因此需要额外对空气进行加热,造成不必要的能耗。而变风量系统虽然可以克服上述问题,但是对于非线性、温湿度高度耦合的恒温恒湿空调系统而言,仅使用传统控制方法不能满足室内的温湿度要求,因此需要找到更优的控制方法满足变风量恒温恒湿空调系统的要求。
目前常用的控制方法有PID控制和智能控制,智能控制包括神经网络控制、遗传算法控制、模型预测控制等。采用PID控制策略,通过PID控制器比较室内的温度和湿度与目标设定值的偏差,输出控制信号调节冷水阀、热水阀及加湿阀,使得室内温湿度保持在设定范围内,具有滞后性,且无法建立系统模型,很难达到较高的控制要求。采用神经网络模型,通过已知数据预测出未来时刻室内的温湿度,然后对不同的空调操作控制进行遍历,选择出最优的控制参数以满足室内温湿度的要求,用神经网络建立系统模型,对室内温度和湿度提前预控,但是控制效果不好。
而模型预测控制在建立系统模型进行预测的基础上,融入了滚动优化器,结合优化算法对系统实现了最优的控制。目前模型预测控制中所采用的优化算法通常具有收敛精度低、稳定性差、容易陷入局部最优的问题,有待进一步改进和优化。
发明内容
(一)解决的技术问题
针对现有技术的不足,本发明提供了一种恒温恒湿空调系统预测优化控制算法及装置,解决了上述背景技术中提出的恒温恒湿空调系统预测优化控制效果不好的问题。
(二)技术方案
为实现以上目的,本发明通过以下技术方案予以实现:
本发明提供一种恒温恒湿空调系统预测优化控制装置,包括:控制模块、空气处理机组、温湿度传感器、太阳辐射传感器、水阀开度采集器、风机频率采集器、第一水阀控制器、第二水阀控制器、风机变频器、初效过滤器;其中,控制模块包括存储单元、CPU、信号输入接口、RS485通讯接口;空气处理机组包括:表冷器、再热器、变频风机、初效过滤器;
控制模块内存储着一种恒温恒湿空调系统预测优化控制算法程序;在室外放置温湿度传感器和太阳辐射传感器,采集室外空气干球温度、室外空气相对湿度和太阳辐射照度;在送风口处放置温湿度传感器,采集送风干球温度、送风相对湿度;在室内放置温湿度传感器,采集室内空气干球温度、室内空气相对湿度;在表冷器和再热器的盘管水阀处放置水阀开度采集器,获得冷盘管水阀开度、热盘管水阀开度;在风机变频器内放置风机频率采集器,获得风机频率;所有采集的数据由信号输入接口传入到存储单元中;经过控制模块的优化计算后,将控制信号由RS485通讯接口输送到第一水阀控制器和第二水阀控制器中,由第一水阀控制器调节冷盘管水阀开度,第二水阀控制器调节热盘管水阀开度,由风机变频器调节风机频率。
本发明还提供一种恒温恒湿空调系统预测优化控制算法,控制如前所述的一种恒温恒湿空调系统预测优化控制装置,包括:
采集获取数据,将采集的数据输入到神经网络模型中,训练神经网络系统预测模型;
设计滚动优化器,确定系统预测模型控制器的预测域和控制域,设置目标函数;
控制模块通过各传感器获得系统运行时的预测模型输入参数,输入神经网络系统预测模型,通过基于国家演变过程的智能优化算法调整控制参数、最小化目标函数,输出最优控制参数;
控制模块将输出的最优控制参数以数字信号的形式传入表冷器水阀控制器、再热器水阀控制器和风机变频器,从而实现风机频率和冷水流量、热水流量的调节,改变送风量、送风温度及送风湿度。
优选地,所述预测模型输入参数,包括:当前时刻室内空气温度T
优选地,所述采集获取数据,包括:室外空气温度及含湿量、送风温度及含湿量、室内空气温度及含湿量、风机频率、冷盘管水阀开度、热盘管水阀开度、房间冷负荷、房间湿负荷;
获取数据中的房间冷负荷和房间湿负荷可由下式计算得到,其中太阳辐射照度由太阳辐射传感器采集获得;
式中:
在所述神经网络的训练过程中,采用均方误差(MSE)评估训练效果:
式中:
优选地,所述设计滚动优化器,确定系统预测模型控制器的预测域和控制域,设置目标函数,包括:
所述目标函数由预测室内空气温度和室内空气含湿量的跟踪误差、设备能耗构成,其中,设备能耗由风机能耗、表冷器电耗、再热器电耗组成;
F
f
L
L
式中:N
所述恒温恒湿空调系统,采用全新风工况,送风量和风机频率之间、水流量和水阀开度之间均为线性关系;
所述目标函数中,冷盘管的当量能耗由下式表示,即通过调节冷水阀门开度,调节冷冻水流量,从而改变经过冷盘管处理后空气的焓值,调节冷盘管当量能耗;
s.t.T
=T
β
β
W
=W
γ
γ
h
式中:下标cc表示冷盘管,sa表示送风空气,oa表示室外空气,ca表示经过冷盘管处理后的空气,cw表示经过冷盘管的冷冻水;h
所述目标函数中,热盘管的当量能耗由下式表示,即通过调节热水阀门开度,调节热水流量,从而改变经过热盘管处理后空气的温度,调节热盘管当量能耗:
s.t.T
=T
β
β
式中:下标hc表示热盘管,hw表示经过热盘管的热水;η
目标函数(5)可以经过归一化后得到下式:
式中:F
所述模型预测控制中,参考轨迹由下式得到:
式中:
优选地,所述通过基于国家演变过程的智能优化算法调整控制参数、最小化目标函数,输出最优控制参数,包括:
S1:初始化国家
为初始建立的国家确定政策参数,设定政策参数
初始政策的参数可表示为:
式中:x
S2:国家确定初步政策调整
采用大幅度或小幅度调整参数,生成(0,1)之间均匀分布的随机数R,若R>0.8,进行大幅度调整,否则将进行小幅度调整,政策参数调整后计算新参数的适应度值;
大幅度调整:采用Levy flight随机生成新的参数,方法如下:
式中:u~N(0,σ
新的参数计算如下:
若x′
x″
式中:x″
小幅度调整:本实施例以大国对应维度的参数为基准,增加满足x~N(0,1)的正态分布的随机数,以此作为新的参数,即:
x′
式中:x′
若x′
式中,x″为第d维新参数,x
S3:判断初步调整后的政策参数适应度是否变好
若初步调整后参数适应度变好,则执行步骤S2,继续进行政策调整,否则执行步骤S4;
S4:国家更新政策参数
国家以初步政策调整中适应度最好的参数作为新的国家政策;
S5:国家分裂成小国
大国分裂成n个小国,各小国随机保留大国的部分参数,其余参数在本实施例中作小幅度调整,方法同S2中小幅度调整的方法,小国确立的政策参数可表示为:
X
s.t.d∈[1,D],i∈[1,n]
式中:x
若生成的新参数适应度和大国适应度相比变得更差,则小国参数不进行调整,保留大国所有参数。
S6:各小国设官分职
各小国均设立m个官员,其中40%为普通朝臣,40%为探子,20%为丞相;
为各官员规定职责:普通朝臣提出建议,进行政策调整,探子随机前往其他小国,向他国的朝臣或丞相学习较优的政策,丞相广泛听取本国朝臣和探子的建议,向朝臣和探子中较优的政策进行学习,最终获得最佳政策参数作为小国新的政策参数;
每位官员对各小国的政策参数都要进行调整,即每位官员初始参数均为式(29)所示;
S7:朝臣提出建议进行政策调整
各小国的各位朝臣都开始提出建议,对各小国的政策自行调整,每位朝臣生成(0,1)之间均匀分布的随机数R,若R>0.8,进行大幅度调整,否则将进行小幅度调整,计算每次调整后参数的适应度值;
大幅度调整方式采用Levy flight生成新参数,小幅度调整方式采用正态分布生成新的随机数,计算步骤同S2,每位朝臣进行c次政策调整,记录每位朝臣政策调整中适应度最好的参数;
S8:探子初次前往他国学习
各小国的每个探子随机选择一个其他小国,以某种方式向他国朝臣提出的政策参数学习,计算学习后的参数适应度值;
采用PSO粒子群算法进行学习,探子选择他国朝臣中的最佳参数作为学习对象,即在PSO算法粒子进行初始化时,每个粒子有80%的概率将学习对象参数作为粒子初始位置,20%的概率随机初始位置,再进行PSO迭代计算。输出优化后的最佳粒子位置作为探子学习后可采纳的新政策参数,将该参数的适应度与探子原先参数适应度进行对比,若变差则探子不采纳他国朝臣的建议,政策参数不作改变;
上述过程重复s次,即探子随机选择了s个小国进行政策学习,记录各小国探子初次学习后的最佳参数集合;
S9:丞相初次收集百官意见
各小国的每位丞相选择所在小国的朝臣和探子中前30%最佳政策参数作为学习对象,以某种方式向其学习、调整小国初始政策参数;
采用同S8步骤相同的PSO粒子群算法进行学习,每位丞相随机选择本国朝臣和探子中前30%最佳政策参数中的某个参数作为学习对象,进行PSO迭代计算,输出优化后的最佳粒子位置作为丞相学习后的新政策参数,该过程重复p次,将p次学习过程中所得的最佳参数作为该丞相的新参数。记录各小国丞相初次学习的最佳参数集合。
S10:探子二次前往他国学习
各小国的每个探子随机选择一个其他小国,以某种方式向他国丞相的政策参数学习,计算学习后的参数适应度值;
采用PSO粒子群算法进行学习,具体步骤同S8,不同的是,探子随机选择他国丞相中的最佳参数作为学习对象。记录各小国探子二次学习的最佳参数集合;
S11:丞相二次收集百官意见
每位丞相选择所在小国的朝臣和探子中前30%最佳政策参数的集合,以某种方式向其学习、调整政策参数;
采用PSO粒子群算法进行学习,具体步骤同S9,记录各小国丞相二次学习的最佳参数集合;
S12:获得所有小国中的最佳政策参数
各小国更新政策参数:通过各小国丞相初次、二次学习的最佳参数集合,比较参数的适应度值,得到各小国丞相中的最佳政策参数,将其作为各小国新的政策参数;
比较各小国的新政策参数,获得所有小国中适应度最好的参数,可表示为:
X
s.t.d∈[1,D]
式中:x
S13:拥有最佳政策参数的小国统一各国
拥有最佳政策参数
S14:判断是否达到迭代终止条件
该算法迭代终止条件为达到最大迭代次数或达到规定收敛精度,若达到迭代终止条件则执行步骤S15,否则执行S2;
S15:输出最佳政策参数
经过国家不断的演变,最终拥有最佳政策参数
(三)有益效果
本发明提供了一种恒温恒湿空调系统预测优化控制算法及装置。具备以下有益效果:
本发明提供的一种恒温恒湿空调系统预测优化控制算法及装置,能够实现温度和湿度的高精度控制,同时降低了系统能耗,实现了节能优化,基于国家演变过程的智能优化算法使用小国内互相学习、国与国之间相互学习的方式,使得算法在迭代前期就具有很好的全局搜索能力;通过选择优秀学习对象的方法,使得样本能向较优群体学习,避免了陷入局部最优的问题;具有包容现有多种智能优化算法的能力,可以根据实际问题选择合适的算法,让丞相和探子以现有的智能优化算法向优秀学习对象靠近,能够在循环次数较少的情况下实现快速收敛,解决了现有技术中的恒温恒湿系统预测优化控制效果不好的问题。
附图说明
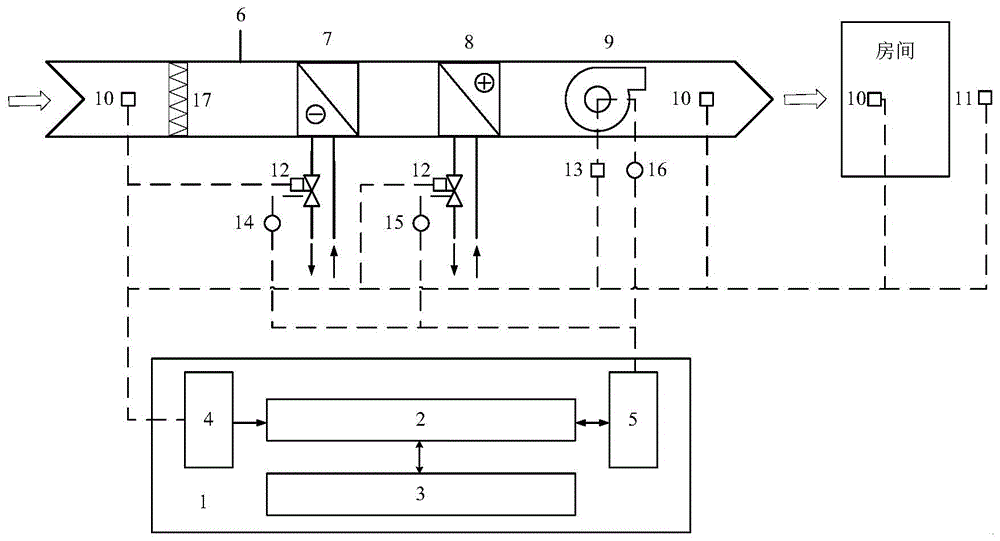
图1为本发明实施例提供的一种恒温恒湿空调系统预测优化控制装置结构图;
图2为本发明实施例提供的一种恒温恒湿空调系统预测优化控制算法及装置中神经网络结构示意图;
图3为本发明实施例提供的一种恒温恒湿空调系统预测优化控制过程示意图;
图4为本发明实施例提供的一种恒温恒湿空调系统预测优化控制算法流程示意图
图5为本发明实施例提供的一种恒温恒湿空调系统预测优化控制算法中基于国家演变过程的智能优化算法流程示意图;
图6为本发明实施例提供基于国家演变过程的一种恒温恒湿空调系统预测优化控制算法-CEA和PSO、SBO、SSA算法在不同测试函数下的收敛曲线图;
图7和图8是本发明实施例提出的一种恒温恒湿空调系统预测优化控制下室内温度及相对湿度的变化图;
图9是本发明实施例提出的一种恒温恒湿空调系统预测优化控制系统功率图;
图中:
控制模块1、存储单元2、CPU 3、信号输入接口4、RS485通讯接口5、空气处理机组6、表冷器7、再热器8、变频风机9、温湿度传感器10、太阳辐射传感器11、水阀开度采集器12、风机频率采集器13、第一水阀控制器14、第二水阀控制器15、风机变频器16、初效过滤过滤器17。
具体实施方式
下面将结合本发明实施例中的附图,对本发明实施例中的技术方案进行清楚、完整地描述。
如图1所示,本发明实施例提供一种恒温恒湿空调系统预测优化控制装置,包括:控制模块1、空气处理机组6、温湿度传感器10、太阳辐射传感器11、水阀开度采集器12、风机频率采集器13、第一水阀控制器14、第二水阀控制器15、风机变频器16、初效过滤器17;
其中,控制模块1包括存储单元2、CPU3、信号输入接口4、RS485通讯接口5;空气处理机组6包括:表冷器7、再热器8、变频风机9、初效过滤器17;
控制模块1内存储着一种恒温恒湿空调系统预测优化控制算法程序;在室外放置温湿度传感器10和太阳辐射传感器11,采集室外空气干球温度、室外空气相对湿度和太阳辐射照度;在送风口处放置温湿度传感器10,采集送风干球温度、送风相对湿度;在室内放置温湿度传感器10,采集室内空气干球温度、室内空气相对湿度;在表冷器和再热器的盘管水阀处放置水阀开度采集器12,获得冷盘管水阀开度、热盘管水阀开度;在风机变频器内放置风机频率采集器13,获得风机频率;所有采集的数据由信号输入接口4传入到存储单元2中;
经过控制模块1的优化计算后,将控制信号由RS485通讯接口5输送到第一水阀控制器14和第二水阀控制器15中,由第一水阀控制器14调节冷盘管水阀开度,第二水阀控制器15调节热盘管水阀开度,由风机变频器16调节风机频率。
如图2-4所示,本发明还提供一种恒温恒湿空调系统预测优化控制算法,控制如前所述的一种恒温恒湿空调系统预测优化控制装置,包括:
401采集获取数据,将采集的数据输入到神经网络模型中,训练神经网络系统预测模型;
402设计滚动优化器,确定系统预测模型控制器的预测域和控制域,设置目标函数;
403控制模块通过各传感器获得系统运行时的预测模型输入参数,输入神经网络系统预测模型,通过基于国家演变过程的智能优化算法调整控制参数、最小化目标函数,输出最优控制参数;
404控制模块将输出的最优控制参数以数字信号的形式传入表冷器水阀控制器、再热器水阀控制器和风机变频器,从而实现风机频率和冷水流量、热水流量的调节,改变送风量、送风温度及送风湿度。
优选地,所述预测模型输入参数,包括:当前时刻室内空气温度T
优选地,系统实际输出的状态参数为
优选地,所述采集获取数据,包括:室外空气温度及含湿量、送风温度及含湿量、室内空气温度及含湿量、风机频率、冷盘管水阀开度、热盘管水阀开度、房间冷负荷、房间湿负荷;
获取数据中的房间冷负荷和房间湿负荷可由下式计算得到,其中太阳辐射照度由太阳辐射传感器采集获得;
式中:
在所述神经网络的训练过程中,采用均方误差(MSE)评估训练效果:
式中:
优选地,所述设计滚动优化器,确定系统预测模型控制器的预测域和控制域,设置目标函数,包括:
所述目标函数由预测室内空气温度和室内空气含湿量的跟踪误差、设备能耗构成,其中,设备能耗由风机能耗、表冷器电耗、再热器电耗组成;
F
f
L
L
式中:N
所述恒温恒湿空调系统,采用全新风工况,送风量和风机频率之间、水流量和水阀开度之间均为线性关系;
所述目标函数中,冷盘管的当量能耗由下式表示,即通过调节冷水阀门开度,调节冷冻水流量,从而改变经过冷盘管处理后空气的焓值,调节冷盘管当量能耗;
s.t.T
=T
β
β
W
=W
γ
γ
h
式中:下标cc表示冷盘管,sa表示送风空气,oa表示室外空气,ca表示经过冷盘管处理后的空气,cw表示经过冷盘管的冷冻水;h
所述目标函数中,热盘管的当量能耗由下式表示,即通过调节热水阀门开度,调节热水流量,从而改变经过热盘管处理后空气的温度,调节热盘管当量能耗:
s.t.T
=T
β
β
式中:下标hc表示热盘管,hw表示经过热盘管的热水;η
目标函数(5)可以经过归一化后得到下式:
式中:F
所述模型预测控制中,参考轨迹由下式得到:
式中:
如图5所示,优选地,所述通过基于国家演变过程的智能优化算法调整控制参数、最小化目标函数,输出最优控制参数,包括:
S1:初始化国家
为初始建立的国家确定政策参数,设定政策参数
初始政策的参数可表示为:
式中:x
S2:国家确定初步政策调整
采用大幅度或小幅度调整参数,生成(0,1)之间均匀分布的随机数R,若R>0.8,进行大幅度调整,否则将进行小幅度调整,政策参数调整后计算新参数的适应度值;
大幅度调整:采用Levy flight随机生成新的参数,方法如下:
式中:u~N(0,σ
新的参数计算如下:
若x′
x″
式中:x″
小幅度调整:本实施例以大国对应维度的参数为基准,增加满足x~N(0,1)的正态分布的随机数,以此作为新的参数,即:
x′
式中:x′
若x′
式中,x″为第d维新参数,x
S3:判断初步调整后的政策参数适应度是否变好
若初步调整后参数适应度变好,则执行步骤S2,继续进行政策调整,否则执行步骤S4;
S4:国家更新政策参数
国家以初步政策调整中适应度最好的参数作为新的国家政策;
S5:国家分裂成小国
大国分裂成n个小国,各小国随机保留大国的部分参数,其余参数在本实施例中作小幅度调整,方法同S2中小幅度调整的方法,小国确立的政策参数可表示为:
X
s.t.d∈[1,D],i∈[1,n]
式中:x
若生成的新参数适应度和大国适应度相比变得更差,则小国参数不进行调整,保留大国所有参数。
S6:各小国设官分职
各小国均设立m个官员,其中40%为普通朝臣,40%为探子,20%为丞相;
为各官员规定职责:普通朝臣提出建议,进行政策调整,探子随机前往其他小国,向他国的朝臣或丞相学习较优的政策,丞相广泛听取本国朝臣和探子的建议,向朝臣和探子中较优的政策进行学习,最终获得最佳政策参数作为小国新的政策参数;
每位官员对各小国的政策参数都要进行调整,即每位官员初始参数均为式(29)所示;
S7:朝臣提出建议进行政策调整
各小国的各位朝臣都开始提出建议,对各小国的政策自行调整,每位朝臣生成(0,1)之间均匀分布的随机数R,若R>0.8,进行大幅度调整,否则将进行小幅度调整,计算每次调整后参数的适应度值;
大幅度调整方式采用Levy flight生成新参数,小幅度调整方式采用正态分布生成新的随机数,计算步骤同S2,每位朝臣进行c次政策调整,记录每位朝臣政策调整中适应度最好的参数;
S8:探子初次前往他国学习
各小国的每个探子随机选择一个其他小国,以某种方式向他国朝臣提出的政策参数学习,计算学习后的参数适应度值;
采用PSO粒子群算法进行学习,探子选择他国朝臣中的最佳参数作为学习对象,即在PSO算法粒子进行初始化时,每个粒子有80%的概率将学习对象参数作为粒子初始位置,20%的概率随机初始位置,再进行PSO迭代计算。输出优化后的最佳粒子位置作为探子学习后可采纳的新政策参数,将该参数的适应度与探子原先参数适应度进行对比,若变差则探子不采纳他国朝臣的建议,政策参数不作改变;
上述过程重复s次,即探子随机选择了s个小国进行政策学习,记录各小国探子初次学习后的最佳参数集合;
S9:丞相初次收集百官意见
各小国的每位丞相选择所在小国的朝臣和探子中前30%最佳政策参数作为学习对象,以某种方式向其学习、调整小国初始政策参数;
采用同S8步骤相同的PSO粒子群算法进行学习,每位丞相随机选择本国朝臣和探子中前30%最佳政策参数中的某个参数作为学习对象,进行PSO迭代计算,输出优化后的最佳粒子位置作为丞相学习后的新政策参数,该过程重复p次,将p次学习过程中所得的最佳参数作为该丞相的新参数。记录各小国丞相初次学习的最佳参数集合。
S10:探子二次前往他国学习
各小国的每个探子随机选择一个其他小国,以某种方式向他国丞相的政策参数学习,计算学习后的参数适应度值;
采用PSO粒子群算法进行学习,具体步骤同S8,不同的是,探子随机选择他国丞相中的最佳参数作为学习对象。记录各小国探子二次学习的最佳参数集合;
S11:丞相二次收集百官意见
每位丞相选择所在小国的朝臣和探子中前30%最佳政策参数的集合,以某种方式向其学习、调整政策参数;
采用PSO粒子群算法进行学习,具体步骤同S9,记录各小国丞相二次学习的最佳参数集合;
S12:获得所有小国中的最佳政策参数
各小国更新政策参数:通过各小国丞相初次、二次学习的最佳参数集合,比较参数的适应度值,得到各小国丞相中的最佳政策参数,将其作为各小国新的政策参数;
比较各小国的新政策参数,获得所有小国中适应度最好的参数,可表示为:
X
s.t.d∈[1,D]
式中:x
S13:拥有最佳政策参数的小国统一各国
拥有最佳政策参数
S14:判断是否达到迭代终止条件
该算法迭代终止条件为达到最大迭代次数或达到规定收敛精度,若达到迭代终止条件则执行步骤S15,否则执行S2;
S15:输出最佳政策参数
经过国家不断的演变,最终拥有最佳政策参数
为验证本发明所提出的基于国家演变过程(CEA)的智能优化算法的一种恒温恒湿系统优化控制方法的优越性,采用10个测试函数进行测试,并将其与粒子群算法(PSO)、缎蓝园丁鸟算法(SBO)、麻雀搜索算法(SSA)进行对比验证。
在AMD Ryzen 7 5800H with Radeon Graphics 3.20GHz,内存16.0GB,windows11操作系统下,使用Pycharm2022.1.3作为编译器对本发明进行测试。
测试函数如表1所示,其中函数F1-F8是单峰函数,函数F9-F12是多峰函数。每个测试函数的变量维度为30维,最大迭代次数为300次。各算法对每个测试函数独立运行30次,取平均值作为优化结果,标准差作为鲁棒性评价指标,从而降低误差。
各算法的群体规模均为30,PSO、SBO、SSA、CEA-(本发明提供的控制方法)所涉及到的具体参数如表2所示。
将各算法分别对测试函数进行单独运算,计算结果的均值和标准差如表3所示。
表1测试函数
/>
表2算法具体参数
/>
表3各算法测试结果
由表3可知,本发明提出的基于国家演变过程的一种恒温恒湿系统预测智能优化控制方法-CEA算法与其他3个算法相比具有明显的优越性。
CEA算法在单峰函数F1-F8的收敛精度上高出其他3个算法4~49个数量级,均在1e-10以下;在多峰函数F9和F10的优化结果为函数的最优值;在多峰函数F11和F12的收敛精度上高出其他3个算法5~24个数量级,且均在1e-11以下。可见,CEA算法具有良好的寻优精度。
CEA算法的标准差数量级均等于或小于其优化结果的数量级,同时远高于其他算法的标准差数量级,特别是在多峰函数F9和F10寻优过程中的标准差为0,表现出了CEA算法具有良好的鲁棒性。
各算法的收敛曲线如图6所示。由图6可知,CEA算法的收敛速度很快,除了F5和F9,其他测试函数在迭代25次以内,都能达到较高的收敛精度,特别是在多峰函数F10的迭代过程中,迭代5次以内即能寻到全局最优值。CEA在单峰函数F5迭代100次以内也能达到较高的收敛精度,同时在迭代后期仍有良好的搜索能力,在多峰函数F9迭代50次左右能找到全局最优值。与其他3个算法相比,CEA在迭代初期能够跳出局部最优,收敛速度快,表现出了较高的寻优能力。
综上所述,CEA算法对表2所列出的测试函数都取得了良好的结果,体现出了优秀的全局搜索能力和鲁棒性。分析可知,各朝臣随机提出建议,避免国家的政策单一化,有更大可能获得更好的政策,即朝臣的随机献策避免了算法陷入局部最优;探子随机前往其他小国,学习他国朝臣或丞相所提出来的较好的国家政策,使得探子得到最有可能为最佳的政策方案,提高探子所在国的政策水平,即探子的学习行为提高了算法的全局搜索能力;丞相听取本国朝臣和探子所得到的较优政策,在此基础上思考出最佳的政策,即丞相采纳百官谏言找寻更优政策的行为使得算法能够在较优解附近进行精细寻优。
在本实施例中,分别使用结合CEA算法的模型预测控制方法和PI控制方法对某房间进行恒温恒湿控制,设定房间温度为23±2℃,相对湿度为60±10%。
附图7和附图8给出了两种方案下房间的温度和相对湿度变化趋势图,可见在结合CEA算法的模型预测控制下,房间温度波动范围均在2℃以内,最大偏差为2℃,满足室内温度设定要求;房间相对湿度波动范围在10%以内,最大偏差为8%,满足室内相对湿度设定要求。而在PI控制策略下,室内温度和相对湿度的波动范围均较大,其中室内温度偏差最大达到2.5℃,而相对湿度的偏差最大达到20%,均不满足设定要求。
附图9给出了两种方案下系统的功率随时间变化图,在PI控制策略下,系统功率在750kW左右波动;而在结合CEA算法的模型预测控制下,系统功率在700kW左右波动,降低了系统能耗。
尽管已经示出和描述了本发明的实施例,对于本领域的普通技术人员而言,可以理解在不脱离本发明的原理和精神的情况下可以对这些实施例进行多种变化、修改、替换和变型,本发明的范围由所附权利要求及其等同物限定。