一种基于多维度混合GPCM模型的学生多水平核心素养分析方法
文献发布时间:2023-06-19 19:30:30
技术领域
本发明涉及学生核心素养分析领域,更具体的,涉及一种基于多维度混合GPCM模型的学生多水平核心素养分析方法。
背景技术
教育测量的目的是为了量化教育相关的数据,以此来实现不同的教育策略帮助学生的教育以及成长。科学可靠地保证测验的质量,让教育测量数据更加的精确,致力于学生的考试成绩更加合理与公平。由此诞生出经典教育测验理论(CTT,Classical TestTheory),但是CTT不可避免的有很多局限性,于是在此之上,项目反应理论(IRT,ItemResponse Theory)应运而生。对比于CTT,IRT不依赖于实操难度大的平行测验,参数也不过度依赖样本,同时还不局限于同一测验,并且试卷难度量表关联于学术能力量表。IRT结合了学生能力与试卷题目的情况(难度、区分度、猜测度等)这些有关联的数据综合进行考虑,而不是单独处理这些数据,丢失了数据的关联性,从而使得结果更加的精确。但是,IRT并不是完美的,传统的IRT需要建立在单维性、非速度性、局部独立性等多个假设之上。其中,单维性将潜在特质理想化为单一特质,并未考虑外显变量对潜在特质水平的影响,即学生潜在特质的类别属性,从而导致了IRT只能处理连续测验数据,在解决实际问题中有很大缺陷。
为了解决这个问题,本发明采用多维度广义分布评分模型(Generalized PartialCredit Model,GPCM),并结合可以连续处理非连续潜在变量的潜在类别分析(LCA),以及阶层线性模型(HLM),工具变量法,形成了可以同时处理连续潜在变量和非连续潜在变量、解决了变量因子内生性问题的多维度混合GPCM模型。
发明内容
为了解决上述至少一个技术问题,本发明提出了一种基于多维度混合GPCM模型的学生多水平核心素养分析方法。
本发明第一方面提供了一种基于多维度混合GPCM模型的学生多水平核心素养分析方法,包括如下步骤:
S1,获取学生考试数据与题目数据,并将学生考试数据与题目数据进行整合并对整合后的数据进行清洗,得到新的数据;
S2,将新的数据输入多维度混合GPCM模型,并输出学生能力信息与项目功能差异信息;
S3,根据项目功能差异信息进行分析,并预测学生素养。
作为本发明一实施方式的进一步改进,步骤S1中的“学生考试数据与题目数据整合与清洗”包括:
S111,学生测验试题设置维度标签;
S112,根据教育院考试方针细化每道题目对应的多维度能力及其占比;
S113,收集到考试数据后,将影响结果输出的无用数据进行剔除;
其中无用数据包括:全部正确或错误的题目数据、含大量缺失值的学生数据。
作为本发明一实施方式的进一步改进,步骤S1中学生考试数据通过历年度学生考试练习的结果进行得到,题目数据通过历年度考试题目进行获取,并将历年度考试题目进行标识题目纬度,得到题库自训练数据。
作为本发明一实施方式的进一步改进,多维度混合GPCM模型通过双参数Logistic模型与LCA模型拟合形成。
作为本发明一实施方式的进一步改进,双参数Logistic模型包括:
其中,i为项目,j为被试学生,θ
作为本发明一实施方式的进一步改进,通过双参数Logistic模型引入潜在变量拟合形成LCA模型,公式如下:
其中c为所属类型的潜在类别(c=1,2,...,C),π
作为本发明一实施方式的进一步改进,多维度混合GPCM模型的公式如下:
其中y=1,2,...,xi,
作为本发明一实施方式的进一步改进,协变量是一个不可控但会影响结果的独立解释变量由于混合比例π
其中π
作为本发明一实施方式的进一步改进,采用马尔可夫链蒙特卡洛(Markov ChainCarlo,MCMC)方法,对参数进行估计,采用MCMC方法主要基于贝叶斯统计理论框架,是用来在概率空间,通过随机采样估算兴趣参数的后验分布。而多维度混合GPCM模型一般就是在该框架下进行的。
定义一个满足遍历定理的马尔可夫链,使其平稳分布π就是抽样的目标分布p(x),然后在这个马氏链上游走,每个时刻得到一个样本。当时间足够长(T>m),在之后的时间里随机游走的样本集合x
作为本发明一实施方式的进一步改进,由于被试的实际作答结果往往与模型并不一定完美吻合,所以需要通过Akaike信息指标(Akaike Information Criterion,AIC)、贝叶斯信息指标(Bayesian Information Criterion,BIC)及连续Akaike信息指标(Consistent Akaike Information Criterion,CAIC)测量拟合度指标,以用于校准、评价最优模型。
AIC=-2logL+2t
BIC=-2logL+(logN)t
CAIC=-2logL+[1+(logN)]t
其中,AIC表示Akaike信息指标,BIC表示贝叶斯信息指标,CAIC表示连续Akaike信息指标,t表示参数个数,N表示被试人数或有效样本个数,L为最大似然函数值,依据结果值越小,拟合度越好,模型性能越高。
与现有技术相比,本发明所获得的有益技术效果:
(1)本申请通过多维度混合GPCM模型,解决了样本依赖度,避免了实操难度大的平行测验,将试卷难度量表关联于学术能力量表,通过阶层线性模型进行多维度计算,潜在类别分析,多因子综合考虑,并消除其内生性。
(2)本发明结合题目难度参数以及教育测量理论中项目区分度(一种将水平不同的被测者区分开来的项目特征)、猜测度(被测者猜测出题目答案的概率)、时间维度等多个方面对学生的各种知识层面掌握能力进行多维度、多分级式剖析。
(3)本发明进行项目功能DIF差异检测,检测不同班级学校、年龄性别等因素的学生的项目反应以及测验的公平性,根据能力分析结合测验完成情况、题目难度参数以及教育测量理论中项目区分度、猜测度、时间维度等多个方面对学生学习情况进行深度剖析,通过设立预警值检查学生能力数据发生异常时,可能存在的学生考试粗心、作弊、成绩明显下滑等问题,帮助用户通过数据变化来有时效性地观测到学生异常情况,协助学生改善粗心、贪玩等学习影响因素,为教育赋能智能。
附图说明
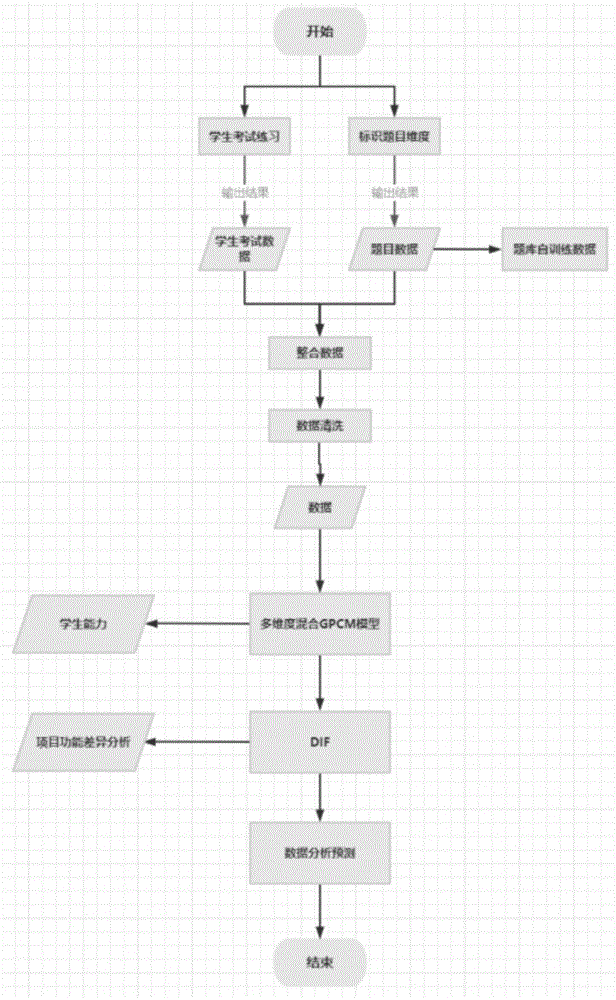
图1示出了本发明基于多维度混合GPCM模型的学生多水平核心素养分析方法流程图。
具体实施方式
为了能够更清楚地理解本发明的上述目的、特征和优点,下面结合附图和具体实施方式对本发明进行进一步的详细描述。需要说明的是,在不冲突的情况下,本申请的实施例及实施例中的特征可以相互组合。
在下面的描述中阐述了很多具体细节以便于充分理解本发明,但是,本发明还可以采用其他不同于在此描述的其他方式来实施,因此,本发明的保护范围并不受下面公开的具体实施例的限制。
如图1所示,本发明第一方面提供了一种基于多维度混合GPCM模型的学生多水平核心素养分析方法,包括如下步骤:
S1,获取学生考试数据与题目数据,并将学生考试数据与题目数据进行整合并对整合后的数据进行清洗,得到新的数据;
其中,步骤S1中的“学生考试数据与题目数据整合与清洗”包括:
S111,学生测验试题设置维度标签;
S112,根据教育院考试方针细化每道题目对应的多维度能力及其占比;
S113,收集到考试数据后,将影响结果输出的无用数据进行剔除;
其中无用数据包括:全部正确或错误的题目数据、含大量缺失值的学生数据。
S2,将新的数据输入多维度混合GPCM模型,并输出学生能力信息与项目功能差异信息;
S3,根据项目功能差异信息进行分析,并预测学生素养。
进一步的,学生多水平核心素养包括学习能力,在学生能力分析基础上,利用AI智能描绘学生人物画像,基于LSTM神经网络预测学生成长走向,帮助用户群体更加关注学生的学习能力上的变化、以及预测学生今后的学习发展,辅助学生健康成长。
具体的,步骤S1中学生考试数据通过历年度学生考试练习的结果进行得到,题目数据通过历年度考试题目进行获取,并将历年度考试题目进行标识题目纬度,得到题库自训练数据。
在一种具体实施方式中,多维度混合GPCM模型通过双参数Logistic模型与LCA模型拟合形成。
作为本发明一实施方式的进一步改进,双参数Logistic模型包括:
其中,i为项目,j为被试学生,θ
进一步的,通过双参数Logistic模型引入潜在变量拟合形成LCA模型,公式如下:
其中c为所属类型的潜在类别(c=1,2,...,C),π
进一步的,多维度混合GPCM模型的公式如下:
其中y=1,2,...,xi,
协变量是一个不可控但会影响结果的独立解释变量由于混合比例π
其中π
作为本发明一实施方式的进一步改进,采用马尔可夫链蒙特卡洛(Markov ChainCarlo,MCMC)方法,对参数进行估计,采用MCMC方法主要基于贝叶斯统计理论框架,是用来在概率空间,通过随机采样估算兴趣参数的后验分布。而多维度混合GPCM模型一般就是在该框架下进行的。
定义一个满足遍历定理的马尔可夫链,使其平稳分布π就是抽样的目标分布p(x),然后在这个马氏链上游走,每个时刻得到一个样本。当时间足够长(T>m),在之后的时间里随机游走的样本集合x
根据本发明实施例,由于被试的实际作答结果往往与模型并不一定完美吻合,所以需要通过Akaike信息指标(Akaike Information Criterion,AIC)、贝叶斯信息指标(Bayesian Information Criterion,BIC)及连续Akaike信息指标(Consistent AkaikeInformation Criterion,CAIC)测量拟合度指标,以用于校准、评价最优模型,公式如下:
AIC=-2logL+2t
BIC=-2logL+(logN)t
CAIC=-2logL+[1+(logN)]t
其中,AIC表示Akaike信息指标,BIC表示贝叶斯信息指标,CAIC表示连续Akaike信息指标,t表示参数个数,N表示被试人数或有效样本个数,L为最大似然函数值,依据结果值越小,拟合度越好,模型性能越高。
可以理解的是,本发明基于多维度混合GPCM模型分析,使用MAP算法估算出题目难度,考虑到题目答对率的先验概率,并且优化传统估算方式,考虑到了题目难度的权值,计算观察值的概率,深度滤化异常值与脏数据。再通过阶层线性模型(HLM)分析学生的实际作答情况,解决多层次数据和多水平数据的统计分析问题,结合题目难度参数以及教育测量理论中项目区分度、猜测度、时间维度等多个方面对学生的各种知识层面掌握能力进行多维度、多分级式剖析。采用QMCEM(准蒙特卡罗)算法,缩减算法取样范围,从低差异数据序列选取样本,而不是传统MC的庞大假随机数,优化了算法的准确度,并且通过潜在类别分析(LCA)与工具变量法(Instrumental Variables,IV),计算变量因子与误差项的相关性得到了系数一致估计量的一般性方法,将变量因子与随机干扰项相关与无关的部分分离,可以集中研究这些与随机干扰项无关的变动,从而使得数据因子更加的精确,提供更科学客观的教育教学评价信息。
综上所述,本申请通过多维度混合GPCM模型,解决了样本依赖度,避免了实操难度大的平行测验,将试卷难度量表关联于学术能力量表,通过阶层线性模型进行多维度计算,潜在类别分析,多因子综合考虑,并消除其内生性,本发明结合题目难度参数以及教育测量理论中项目区分度、猜测度、时间维度等多个方面对学生的各种知识层面掌握能力进行多维度、多分级式剖析,本发明进行项目功能DIF差异检测,检测不同班级学校、年龄性别等因素的学生的项目反应以及测验的公平性,帮助用户去改善学生粗心、贪玩等学习影响因素。
在本发明各实施例中的各功能单元可以全部集成在一个处理单元中,也可以是各单元分别单独作为一个单元,也可以两个或两个以上单元集成在一个单元中;上述集成的单元既可以采用硬件的形式实现,也可以采用硬件加软件功能单元的形式实现。
本领域普通技术人员可以理解:实现上述方法实施例的全部或部分步骤可以通过程序指令相关的硬件来完成,前述的程序可以存储于计算机可读取存储介质中,该程序在执行时,执行包括上述方法实施例的步骤;而前述的存储介质包括:移动存储设备、只读存储器(ROM,Read-OnlyMemory)、随机存取存储器(RAM,RandomAccessMemory)、磁碟或者光盘等各种可以存储程序代码的介质。
或者,本发明上述集成的单元如果以软件功能模块的形式实现并作为独立的产品销售或使用时,也可以存储在一个计算机可读取存储介质中。基于这样的理解,本发明实施例的技术方案本质上或者说对现有技术做出贡献的部分可以以软件产品的形式体现出来,该计算机软件产品存储在一个存储介质中,包括若干指令用以使得一台计算机设备(可以是个人计算机、服务器、或者网络设备等)执行本发明各个实施例所述方法的全部或部分。而前述的存储介质包括:移动存储设备、ROM、RAM、磁碟或者光盘等各种可以存储程序代码的介质。
以上所述,仅为本发明的具体实施方式,但本发明的保护范围并不局限于此,任何熟悉本技术领域的技术人员在本发明揭露的技术范围内,可轻易想到变化或替换,都应涵盖在本发明的保护范围之内。因此,本发明的保护范围应以所述权利要求的保护范围为准。
- 一种基于核心素养的学生综合素质评价系统及方法
- 一种基于卷积神经网络的多维度能耗数据分析方法与企业能耗预测模型