一种基于即插即用异构模型的联邦学习方法
文献发布时间:2023-06-19 19:30:30
技术领域
本申请涉及联邦学习技术领域,特别涉及一种基于即插即用异构模型的联邦学习方法。
背景技术
联邦学习在保证一组客户端不上传本地数据集的前提下协同训练一个全局模型,每个用户只能访问自己的数据,从而保护了参与训练用户的隐私。联邦学习因其保护隐私的优势在医学、金融和人工智能等行业有着广泛的应用前景,是最近几年的研究热点。然而联邦学习侧重于通过学习所有参与客户机的本地数据来获得高质量的全局模型,但由于现实场景中每个客户端的数据是异质的,当面临数据异质性问题,它无法训练出一个适用于所有客户端的全局模型,同时隐私保护,通信效率的约束,个性化模型的需求也成为了联邦学习研究的主要方向。
在近些年的联邦学习研究中,大多数方法使用迁移学习,元学习,强化学习等方法解决联邦学习中的数据异构和模型异构性问题,同时利用差分隐私,同态加密等方法与联邦学习相结合保护用户的隐私也是一个主流方向。但是上面的方法中大多数方法都存在不能同时实现对模型异构和数据异构的优化,或是在隐私保护方面存在些许问题,以及不能解决联邦学习的通信开销等问题。
发明内容
本申请提供了一种基于即插即用异构模型的联邦学习方法,可用于解决现有技术无法同时实现对模型异构和数据异构的优化的技术问题。
本申请提供一种基于即插即用异构模型的联邦学习方法,方法包括:
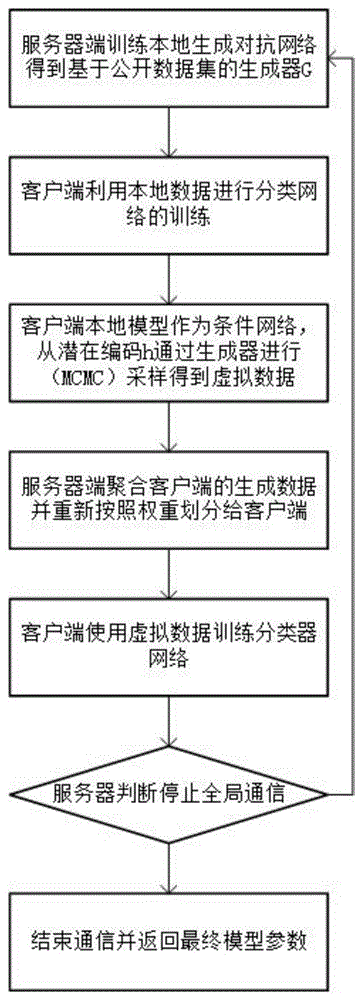
步骤1:训练生成模型:在服务器端初始化生成模型G和判别模型C,使用生成对抗网络的训练方法训练生成模型G和判别模型C,其中;G用于生成数据集D
步骤2:初始化模型:
步骤3:在各个客户端中训练客户端模型M
步骤4:服务器聚合:在服务器端聚合来自客户端i的采样数据
步骤5:服务器端数据分配:将采样数据集d
步骤6:模型测试:在每轮通信中,在所有客户端用本轮更新参数后的分类模型M
步骤7:服务器端判断是否继续下一次通信,如果继续下一次通信,则返回步骤3,若否,则结束通信,保存全局网络模型参数。
可选的,生成模型G包含全连接层,批标准化层,激活函数层,反卷积层;
生成模型G的输入为隐藏编码h,目标输出为来自公共数据集D
判别模型C包含全连接层,激活函数层,反卷积层;
生成模型G和判别模型C均使用Adam作为优化器。
可选的,初始化模型,包括:
将数据集D依据狄利克雷分布划分为私有数据集D
初始化目标分类模型M,并把目标分类模型M传播给各个客户端作为其本地分类模型M
可选的,在各个客户端中训练客户端模型M
步骤3-1:客户端使用私有数据D
步骤3-2:从第二轮通信起,使用从服务器端接收的图片d
步骤3-3:从一个随机生成的隐藏编码h开始,通过大都会朗之万算法,定义马尔可夫链蒙特卡罗采样器;
采样器使用客户端模型M
步骤3-4:将采样数据
可选的,所述步骤3-3中采样规则如下:
其中p()表示对应分布出现的概率,
可选的,分类模型的模型结构包括lenet,cnn和mobilenet_v3,其中使用分类模型M
可选的,采样器有两种工作模式:
对于每一个客户端,采样器对于私有数据集D的不同类别的生成样本均进行相同数量的采样;
对于每一个客户端采样对于不同目标类别的生成样本按照当前客户端私有数据集D
本发明提供了一种联邦学习的实现方法,较之于现有技术,优点包括:1、构建了一个在服务器端训练的生成模型作为采样器,利用即插即用生成模型的可替换性,将服务器模型作为条件网络,将采样得到的生成数据代替传统联邦平均算法中的模型梯度进行客户端和服务器端之间的传递,相比之前方法的梯度传递,图片传输的方式传输开销可控且更小,提高了模型训练的效果和效率,同时节省了通信的开销;2、PPGN在一个共有数据集的基础上可以提取到客户端本地分类模型的的模型特征,因为采样过程中没有本地私有数据的参与,所以采样得到的数据并不会暴露用户本地数据细节,实现了联邦学习中的隐私保护原则,与其他基于生成或蒸馏网络的联邦学习方法相比更具有安全性;3、由于不需要传递模型参数,所以可以在客户端使用不同结构的个性化模型进行训练,实现了联邦学习的个性化模型需求。
附图说明
图1为本申请实施例提供的流程示意图;
图2为本申请实施例提供的模型示意图;
图3为本申请实施例提供的MCMC采样器生成图片与原始数据集图片的对比图。
具体实施方式
为使本申请的目的、技术方案和优点更加清楚,下面将结合附图对本申请实施方式作进一步地详细描述。
于是本方法提出了将即插即用生成网络(PPGN)与联邦学习相结合的思路,用以解决联邦学习中的异构性问题,同时本方法在安全性方面也要高于其他的生成网络相关联邦学习方法。PPGN的具体思想是通过在生成器网络的潜在空间中进行梯度上升,以最大限度地激活一个单独的分类器网络中的一个或多个神经元,通俗来说PPGN由一个生成网络G,它能够生成广泛的图像类型的范围和一个可替换的“条件”网络C组成,它告诉生成器要生成什么。联邦学习中数据的隐私保护是对于模型训练很重要的约束和准则,由于即插即用网络不需要使用客户端的私有数据集进行训练也可以生成激活目标数据集对应类别的数据,所以可以将其与联邦学习相结合,从而提高了联邦学习的泛化能力,提高了其训练和通信效率。同时最有用的特性是“即插即用”的能力——允许人们进入一个可替换的条件网络,并根据在测试时指定的条件生成图像,所以通过本方法,可以实现联邦多模态学习和个性化联邦模型学习。
下面首先结合附图对本申请实施例进行介绍。
本申请提供一种基于即插即用异构模型的联邦学习方法,包括:
步骤1:训练生成模型:在服务器端初始化生成模型G和判别模型C,使用生成对抗网络的训练方法训练生成模型G和判别模型C,其中;G用于生成数据集D
其中,生成模型G包含全连接层,批标准化层,激活函数层,反卷积层;
生成模型G的输入为隐藏编码h,目标输出为来自公共数据集D
判别模型C包含全连接层,激活函数层,反卷积层;
生成模型G和判别模型C均使用Adam作为优化器。
步骤2:初始化模型:
将数据集D依据狄利克雷分布划分为私有数据集D
初始化目标分类模型M,并把目标分类模型M传播给各个客户端作为其本地分类模型M
分类模型的模型结构包括lenet,cnn和mobilenet_v3,其中使用分类模型M
步骤3:在各个客户端中训练客户端模型M
步骤3-1:客户端使用私有数据D
步骤3-2:从第二轮通信起,使用从服务器端接收的图片d
步骤3-3:从一个随机生成的隐藏编码h开始,通过大都会朗之万算法(MALA),定义马尔可夫链蒙特卡罗(MCMC)采样器;
采样器使用客户端模型M
步骤3-3中采样规则如下:
其中p()表示对应分布出现的概率,
采样器有两种工作模式:
平均采样,对于每一个客户端,采样器对于私有数据集D的不同类别的生成样本均进行相同数量的采样;
加权采样,对于每一个客户端采样对于不同目标类别的生成样本按照当前客户端私有数据集D
步骤3-4:将采样数据
步骤4:服务器聚合:在服务器端聚合来自客户端i的采样数据
步骤5:服务器端数据分配:将采样数据集d
步骤6:模型测试:在每轮通信中,在所有客户端用本轮更新参数后的分类模型M
步骤7:服务器端判断是否继续下一次通信,如果继续下一次通信,则返回步骤3,若否,则结束通信,保存全局网络模型参数。
本申请提供的方法因为客户端i与服务器间的通信不传递参数而是直接传递数据样本,所以与联邦平均算法相比,各个客户端可以根据本地设备算力和计算环境的不同使用不同的模型结构作为其客户端模型,从而实现了联邦学习中的个性化模型需求
本发明提供了一种联邦学习的实现方法,较之于现有技术,优点包括:1、构建了一个在服务器端训练的生成模型作为采样器,利用即插即用生成模型的可替换性,将服务器模型作为条件网络,将采样得到的生成数据代替传统联邦平均算法中的模型梯度进行客户端和服务器端之间的传递,相比之前方法的梯度传递,图片传输的方式传输开销可控且更小,提高了模型训练的效果和效率,同时节省了通信的开销;2、PPGN在一个共有数据集的基础上可以提取到客户端本地分类模型的的模型特征,因为采样过程中没有本地私有数据的参与,所以采样得到的数据并不会暴露用户本地数据细节,实现了联邦学习中的隐私保护原则,与其他基于生成或蒸馏网络的联邦学习方法相比更具有安全性;3、由于不需要传递模型参数,所以可以在客户端使用不同结构的个性化模型进行训练,实现了联邦学习的个性化模型需求。
以上所述的本申请实施方式并不构成对本申请保护范围的限定。
- 一种基于联邦学习的多物联网设备异构模型高效互学习方法
- 一种基于联邦学习的多物联网设备异构模型高效互学习方法